Saliency-Aware Model Merging
Pith reviewed 2026-06-28 19:01 UTC · model grok-4.3
The pith
Task-vector saliency scores allow iterative, data-free merging of multiple fine-tuned models by discarding non-informative parameter updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
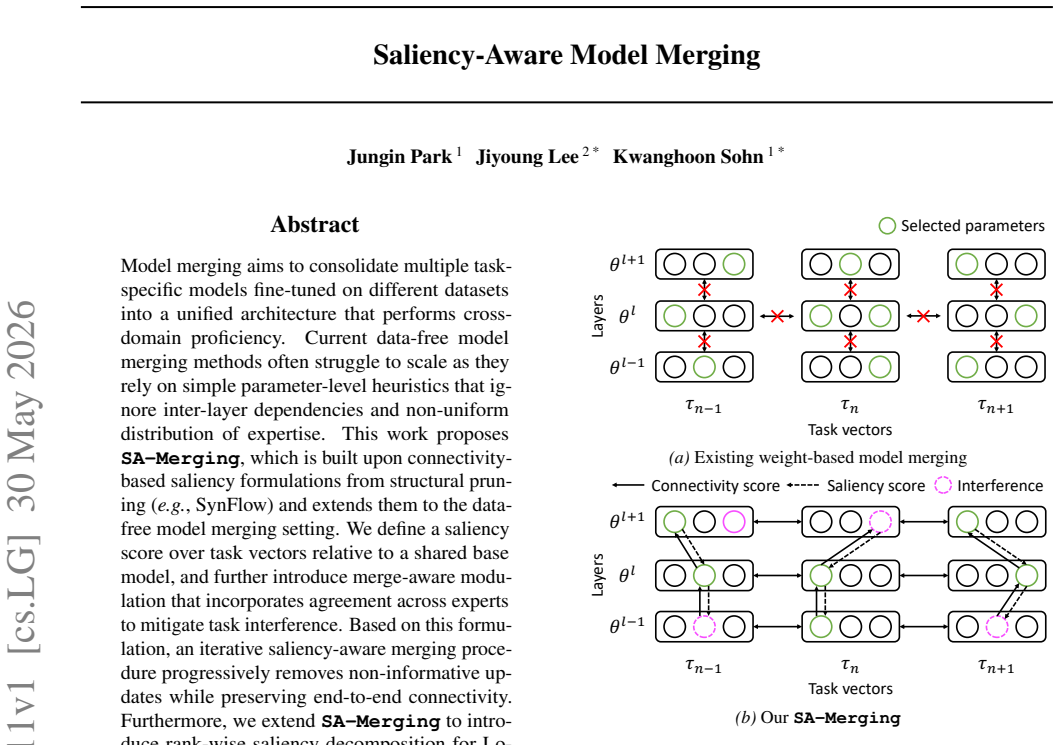
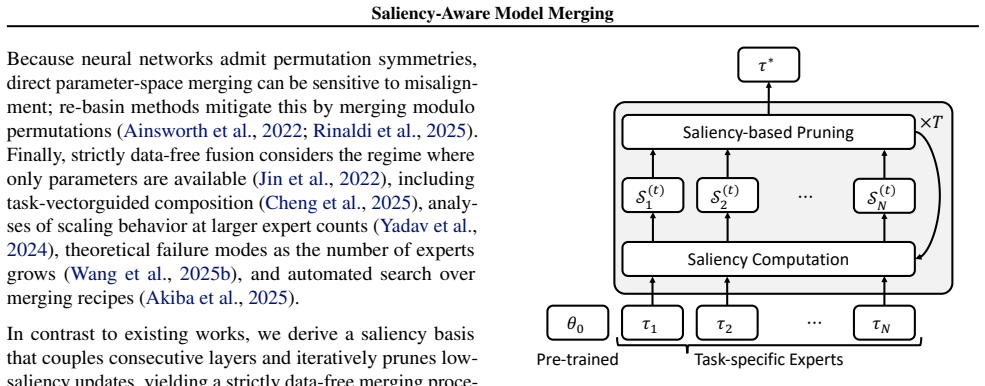
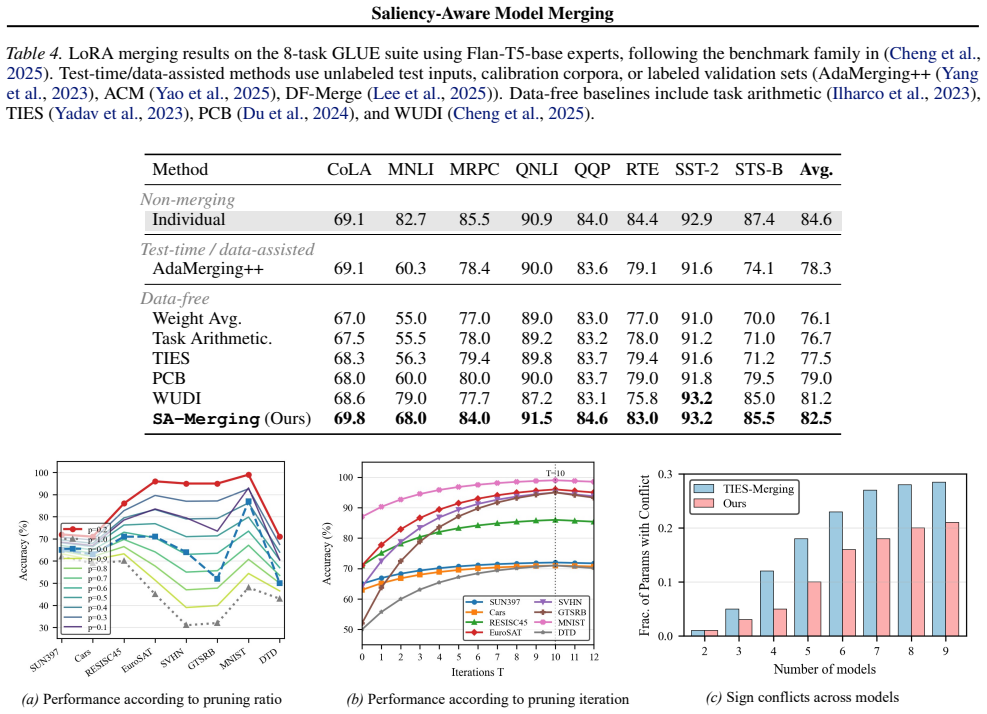
SA-Merging defines a saliency score over task vectors relative to a shared base model using connectivity-based formulations, incorporates merge-aware modulation based on expert agreement, and applies an iterative removal procedure to eliminate non-informative updates while preserving end-to-end connectivity; the same framework extends to rank-wise decomposition for LoRA adapters.
What carries the argument
connectivity-based saliency score computed on task vectors with merge-aware modulation
Load-bearing premise
Connectivity-based saliency scores derived solely from task vectors can correctly identify which updates are non-informative without reference to any data.
What would settle it
Demonstrating on a held-out benchmark that random removal of updates matches or exceeds the saliency-guided removal in final merged model accuracy.
Figures
read the original abstract
Model merging aims to consolidate multiple task-specific models fine-tuned on different datasets into a unified architecture that performs cross-domain proficiency. Current data-free model merging methods often struggle to scale as they rely on simple parameter-level heuristics that ignore inter-layer dependencies and non-uniform distribution of expertise. This work proposes SA-Merging, which is built upon connectivity-based saliency formulations from structural pruning (e.g., SynFlow) and extends them to the data-free model merging setting. We define a saliency score over task vectors relative to a shared base model, and further introduce merge-aware modulation that incorporates agreement across experts to mitigate task interference. Based on this formulation, an iterative saliency-aware merging procedure progressively removes non-informative updates while preserving end-to-end connectivity. Furthermore, we extend SA-Merging to introduce rank-wise saliency decomposition for LoRAs without compromising their structural integrity. Extensive experiments on vision and language tasks demonstrate the effectiveness of our saliency-based approach, further reducing the gap between data-free and test-time adaptation methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SA-Merging, a data-free model merging technique that extends connectivity-based saliency scores (in the style of SynFlow) to task vectors relative to a shared base model. It adds merge-aware modulation to incorporate cross-expert agreement, an iterative saliency-aware removal procedure that eliminates non-informative updates while preserving end-to-end connectivity, and a rank-wise saliency decomposition for LoRA adapters. The central claim is that this approach improves merging performance on vision and language tasks and narrows the gap to test-time adaptation methods.
Significance. If the experimental results are reproducible and the saliency formulation is shown to be robust, the work would supply a principled, connectivity-aware alternative to heuristic parameter averaging in data-free merging. The explicit link to structural pruning and the LoRA extension are constructive contributions that could influence both merging and parameter-efficient fine-tuning research.
minor comments (2)
- The abstract states that the method 'further reduc[es] the gap' but supplies no quantitative deltas, baseline names, or dataset identifiers; adding these would strengthen the summary.
- Notation for the saliency score, merge-aware modulation factor, and the iterative removal threshold is introduced without an accompanying table of symbols or explicit definitions in the visible text.
Simulated Author's Rebuttal
We thank the referee for their summary of SA-Merging and for noting its potential as a connectivity-aware alternative in data-free merging. The report lists no specific major comments, so we provide no point-by-point rebuttals. We remain available to supply further details on experimental reproducibility or saliency robustness if the referee requests them.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper extends an external technique (SynFlow connectivity saliency from structural pruning) to task vectors in model merging, defining saliency scores relative to a shared base model and adding merge-aware modulation plus iterative removal. No equations or steps in the provided text reduce by construction to fitted inputs, self-definitions, or self-citation chains; the method is presented as building on independent prior work rather than renaming or smuggling an ansatz. Central claims are supported by asserted experiments, with no load-bearing internal reductions evident.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Connectivity-based saliency scores defined on task vectors relative to a base model identify informative updates without access to training data.
Reference graph
Works this paper leans on
-
[1]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[2]
Describing textures in the wild , author=
-
[3]
Proceedings of the IEEE , volume=
Gradient-based learning applied to document recognition , author=. Proceedings of the IEEE , volume=. 2002 , publisher=
2002
-
[4]
computer: Benchmarking machine learning algorithms for traffic sign recognition , author=
Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition , author=. Neural networks , volume=. 2012 , publisher=
2012
-
[5]
NIPS workshop on deep learning and unsupervised feature learning , volume=
Reading digits in natural images with unsupervised feature learning , author=. NIPS workshop on deep learning and unsupervised feature learning , volume=
-
[6]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2019 , publisher=
2019
-
[7]
Proceedings of the IEEE , volume=
Remote sensing image scene classification: Benchmark and state of the art , author=. Proceedings of the IEEE , volume=. 2017 , publisher=
2017
-
[8]
3d object representations for fine-grained categorization , author=
-
[9]
International Journal of Computer Vision , volume=
Sun database: Exploring a large collection of scene categories , author=. International Journal of Computer Vision , volume=. 2016 , publisher=
2016
-
[10]
2010 , organization=
Sun database: Large-scale scene recognition from abbey to zoo , author=. 2010 , organization=
2010
-
[11]
Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models , author=
-
[12]
arXiv preprint arXiv:2601.11659 , year=
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes , author=. arXiv preprint arXiv:2601.11659 , year=
-
[13]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[14]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
-
[15]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Qwen2 technical report , author=. arXiv preprint arXiv:2407.10671 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Pruning Neural Networks without any Data by Iteratively Conserving Synaptic Flow , author=
-
[20]
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time , author=
-
[21]
Editing Models with Task Arithmetic , author=
-
[22]
TIES-Merging: Resolving Interference When Merging Models , author=
-
[23]
Merging Models with Fisher-Weighted Averaging , author=
-
[24]
2022 , note=
Dataless Knowledge Fusion by Merging Weights of Language Models , author=. 2022 , note=
2022
-
[25]
2023 , note=
ZipIt! Merging Models from Different Tasks without Training , author=. 2023 , note=
2023
-
[26]
2022 , note=
Git Re-Basin: Merging Models modulo Permutation Symmetries , author=. 2022 , note=
2022
-
[27]
2023 , note=
AdaMerging: Adaptive Model Merging for Multi-Task Learning , author=. 2023 , note=
2023
-
[28]
Representation Surgery for Multi-Task Model Merging , author=
-
[29]
Model Breadcrumbs: Scaling Multi-Task Model Merging with Sparse Masks , author=
-
[30]
Parameter Competition Balancing for Model Merging , author=
-
[31]
Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging , author=
-
[32]
Localize-and-Stitch: Efficient Model Merging via Sparse Task Arithmetic , author=
-
[33]
2024 , note=
Beyond Task Vectors: Selective Task Arithmetic Based on Importance Metrics , author=. 2024 , note=
2024
-
[34]
Knowledge Composition using Task Vectors with Learned Anisotropic Scaling , author=
-
[35]
2024 , note=
What Matters for Model Merging at Scale? , author=. 2024 , note=
2024
-
[36]
2024 , note=
LiNeS: Post-training Layer Scaling Prevents Forgetting and Enhances Model Merging , author=. 2024 , note=
2024
-
[37]
2025 , note=
SeWA: Selective Weight Average via Probabilistic Masking , author=. 2025 , note=
2025
-
[38]
2024 , note=
DELLA-Merging: Reducing Interference in Model Merging through Magnitude-Based Sampling , author=. 2024 , note=
2024
-
[39]
Whoever Started the Interference Should End It: Guiding Data-Free Model Merging via Task Vectors , author=
-
[40]
2025 , note=
Why Do More Experts Fail? A Theoretical Analysis of Model Merging , author=. 2025 , note=
2025
-
[41]
CAT Merging: A Training-Free Approach for Resolving Conflicts in Model Merging , author=
-
[42]
FREE-Merging: Fourier Transform for Efficient Model Merging , author=
-
[43]
LoRA: Low-Rank Adaptation of Large Language Models , author=
-
[44]
Unraveling LoRA Interference: Orthogonal Subspaces for Robust Model Merging , author=
-
[45]
Activation-Guided Consensus Merging for Large Language Models , author=
-
[46]
2025 , note=
Update Your Transformer to the Latest Release: Re-Basin of Task Vectors , author=. 2025 , note=
2025
-
[47]
2025 , journal=
Evolutionary Optimization of Model Merging Recipes , author=. 2025 , journal=
2025
-
[48]
2023 , note=
Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch , author=. 2023 , note=
2023
-
[49]
2025 , note=
Dynamic Fisher-weighted Model Merging via Bayesian Optimization , author=. 2025 , note=
2025
-
[50]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=
-
[51]
Learning Transferable Visual Models From Natural Language Supervision , author=
-
[52]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=
-
[53]
2018 , booktitle=
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding , author=. 2018 , booktitle=
2018
-
[54]
2024 , note=
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators , author=. 2024 , note=
2024
-
[55]
2021 , note=
Training Verifiers to Solve Math Word Problems , author=. 2021 , note=
2021
-
[56]
Measuring Mathematical Problem Solving With the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , year=. Measuring Mathematical Problem Solving With the
-
[57]
2021 , note=
Evaluating Large Language Models Trained on Code , author=. 2021 , note=
2021
-
[58]
2021 , note=
Program Synthesis with Large Language Models , author=. 2021 , note=
2021
-
[59]
2020 , note=
Measuring Massive Multitask Language Understanding , author=. 2020 , note=
2020
-
[60]
2021 , note=
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. 2021 , note=
2021
-
[61]
2021 , note=
BBQ: A Hand-Built Bias Benchmark for Question Answering , author=. 2021 , note=
2021
-
[62]
Teaching Machines to Read and Comprehend , author=
-
[63]
, author=
Lora: Low-rank adaptation of large language models. , author=
-
[64]
An image is worth 16x16 words: Transformers for image recognition at scale , author=
-
[65]
Exploring the limits of transfer learning with a unified text-to-text transformer , author=
-
[66]
Path-sgd: Path-normalized optimization in deep neural networks , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.