ProactiveLLM: Learning Active Interaction for Streaming Large Language Models
Pith reviewed 2026-06-28 19:06 UTC · model grok-4.3
The pith
ProactiveLLM trains streaming LLMs to sense when partial input is semantically sufficient using only their own evolving states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
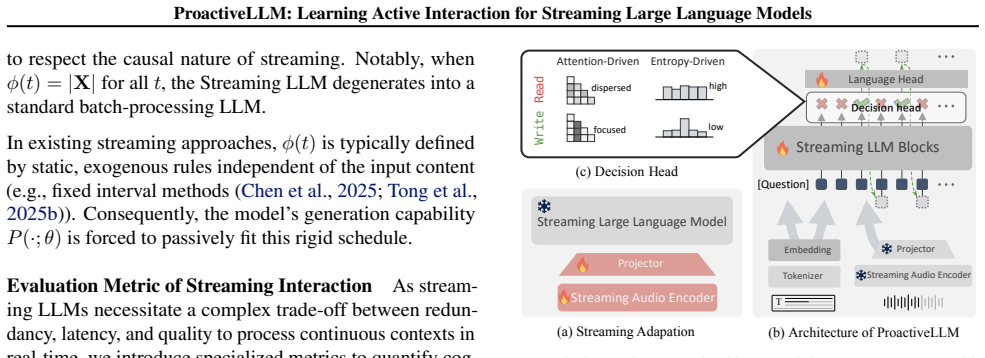
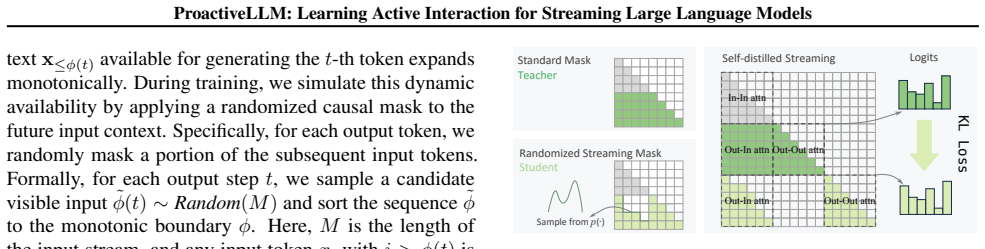
ProactiveLLM achieves active interaction by training the model to perceive semantic sufficiency from partial inputs through mask-based streaming modeling, which applies monotonic random masking to simulate streaming revelation, and synchronized privileged self-distillation, which aligns the partial-context student view with a full-context teacher view produced by the same evolving model, thereby inducing endogenous sufficiency cues that guide interaction decisions without external signals or annotations.
What carries the argument
Synchronized privileged self-distillation (SPSD), which aligns partial-context and full-context views within the same model to extract endogenous sufficiency signals from incomplete observations.
If this is right
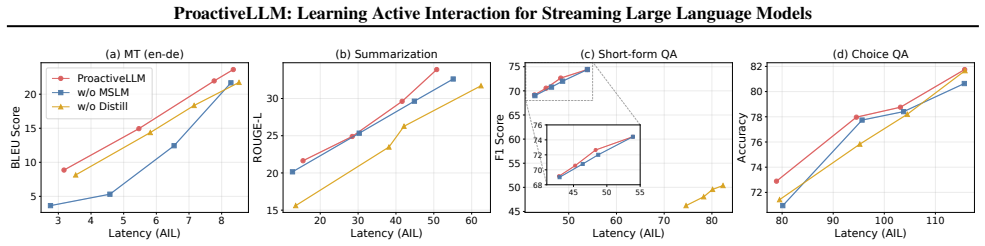
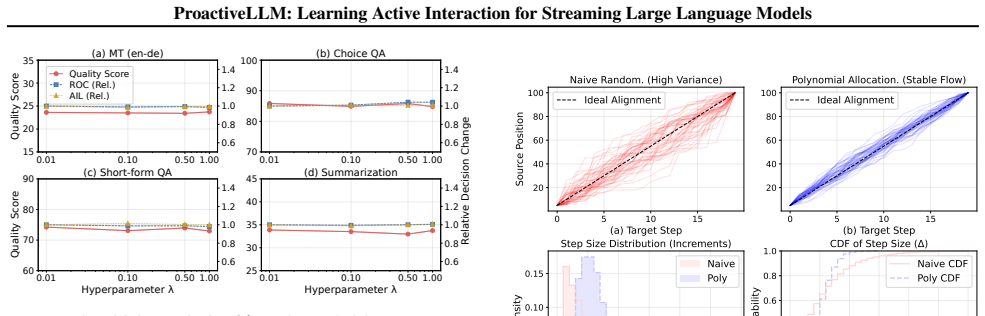
- Interaction latency drops on both text and speech streaming tasks while output quality is preserved.
- Diverse decision heads can be attached in plug-and-play fashion once the base sufficiency cues are learned.
- No external timing labels, reasoning trajectories, or stronger teacher models are required during training.
- The same training produces a foundation usable across multiple streaming domains without task-specific annotations.
Where Pith is reading between the lines
- The approach removes dependence on costly human or model-generated supervision, which may enable training on much larger unlabeled streams than label-dependent methods allow.
- Because cues are derived internally, the same model could in principle adjust interaction timing to new domains or user preferences by fine-tuning only the decision head.
- The method may extend naturally to other sequential generation settings where early commitment carries a cost, such as incremental code completion or live translation.
Load-bearing premise
The alignment between a partial-context student view and a full-context teacher view generated by the same evolving model reliably produces unbiased sufficiency cues without external teachers or annotations.
What would settle it
A controlled streaming evaluation in which models using the learned endogenous cues produce measurably higher latency or lower quality than baselines that receive explicit timing labels on the same inputs.
Figures

read the original abstract
Standard Large Language Models (LLMs) follow a read-then-generate paradigm, causing unnecessary latency and computation. Streaming LLMs alleviate this issue by generating while receiving inputs, but still struggle to decide when to interact with the stream. Existing methods either hard-code interaction timing or rely on costly external alignment signals, such as timing labels, reasoning trajectories, or stronger teachers. In this paper, we propose ProactiveLLM, which achieves active interaction by leveraging the model's endogenous states to guide interaction decisions. The model first learns to perceive semantic sufficiency from partial inputs through two complementary training mechanisms: mask-based streaming modeling and synchronized privileged self-distillation (SPSD). The former applies monotonic random masking to the input during training, simulating progressively revealed streaming inputs and enabling the model to learn local semantic dependencies from partial-input views. The latter aligns the partial-context student view with a full-context teacher view generated by the same evolving model, allowing privileged full-context evidence to guide the student's understanding under incomplete observations. Together, these mechanisms induce endogenous sufficiency cues without requiring external teachers or annotations, providing a versatile foundation for the plug-and-play integration of diverse decision heads. Extensive evaluation across text and speech streaming tasks confirms that ProactiveLLM significantly reduces interaction latency while maintaining quality, validating its capacity for dynamic and active interaction. Code is publicly available at https://github.com/EIT-NLP/StreamingLLM/tree/main/ProactiveLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProactiveLLM for streaming LLMs, which learns active interaction decisions by perceiving semantic sufficiency from partial inputs. It uses two mechanisms: mask-based streaming modeling (monotonic random masking to simulate streaming inputs) and synchronized privileged self-distillation (SPSD), where a partial-context student view aligns with a full-context teacher view from the same evolving model. This is claimed to induce endogenous sufficiency cues without external teachers, annotations, or labels, enabling plug-and-play decision heads and reduced latency on text/speech tasks while maintaining quality. Code is released publicly.
Significance. If the SPSD mechanism reliably supplies independent privileged signals, the approach offers a self-supervised route to active streaming without costly external alignment data, which could be broadly useful. The public code release supports reproducibility.
major comments (1)
- [Abstract] Abstract (SPSD description): the claim that SPSD 'aligns the partial-context student view with a full-context teacher view generated by the same evolving model' and thereby supplies 'privileged full-context evidence' without external teachers is load-bearing for the central claim of endogenous cues. No stabilization (momentum, stop-gradient, delayed teacher, or separate initialization) is mentioned, so early in training the teacher possesses the same incomplete representations as the student; this risks the distillation target simply reinforcing partial-input biases rather than injecting independent full-context evidence.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and detailed feedback, which helps us strengthen the presentation of the SPSD mechanism. We address the concern point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (SPSD description): the claim that SPSD 'aligns the partial-context student view with a full-context teacher view generated by the same evolving model' and thereby supplies 'privileged full-context evidence' without external teachers is load-bearing for the central claim of endogenous cues. No stabilization (momentum, stop-gradient, delayed teacher, or separate initialization) is mentioned, so early in training the teacher possesses the same incomplete representations as the student; this risks the distillation target simply reinforcing partial-input biases rather than injecting independent full-context evidence.
Authors: We appreciate the referee highlighting the need for greater clarity on this point. In SPSD, the student and teacher views are produced by identical model parameters at the current training step, but they receive different inputs: the student processes the monotonically masked partial input, while the teacher always processes the complete, unmasked full input. The input asymmetry is what supplies the privileged full-context signal; the teacher’s output is conditioned on the entire sequence even though the weights are shared. The alignment objective therefore trains the partial-input pathway to reproduce the richer computation that the same model performs on the full input. Because the target is always derived from complete data, the mechanism does not simply echo partial-input biases; it explicitly pulls the student representation toward the full-context behavior. Early in training the full-context outputs are still noisy, yet they remain strictly more informative than the partial ones, and the loss continues to enforce this information gap. No momentum, stop-gradient, or separate teacher is required precisely because the supervision signal originates from the input difference rather than from a temporally lagged or architecturally distinct model. We will revise both the abstract and Section 3.2 to state the input asymmetry explicitly and to include a short paragraph explaining why additional stabilization is unnecessary in this formulation. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's central mechanisms (mask-based streaming modeling and SPSD) are described as training procedures that induce endogenous sufficiency cues from partial inputs. No equations are provided that reduce any claimed prediction or result to its inputs by construction. SPSD is presented as aligning student and teacher views from the evolving model, but this does not constitute self-definition or a fitted input renamed as prediction; it is a standard self-distillation setup without load-bearing self-citation or uniqueness claims imported from prior author work. The derivation chain remains self-contained against external benchmarks and does not meet the strict criteria for flagging circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Monotonic random masking during training simulates progressively revealed streaming inputs and enables learning of local semantic dependencies from partial views.
- domain assumption The partial-context student view can be aligned with a full-context teacher view generated by the same evolving model to induce endogenous sufficiency cues without external signals.
Reference graph
Works this paper leans on
-
[5]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Livecc: Learning video llm with streaming speech transcription at scale , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[8]
2025 , journal=
Qwen2.5 Technical Report , author=. 2025 , journal=
2025
-
[10]
International conference on machine learning , pages=
Robust speech recognition via large-scale weak supervision , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[11]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[12]
Proceedings of the 14th International Workshop on Spoken Language Translation , pages=
Overview of the iwslt 2017 evaluation campaign , author=. Proceedings of the 14th International Workshop on Spoken Language Translation , pages=
2017
-
[13]
2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
Librispeech: an asr corpus based on public domain audio books , author=. 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=. 2015 , organization=
2015
-
[15]
Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
Mctest: A challenge dataset for the open-domain machine comprehension of text , author=. Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
2013
-
[18]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019) , pages=
STACL: Simultaneous Translation with Implicit Anticipation and Controllable Latency using Prefix-to-Prefix Framework , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019) , pages=
2019
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
VisiPruner: Decoding Discontinuous Cross-Modal Dynamics for Efficient Multimodal LLMs , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[24]
2026 , publisher=
From Data to Model: A Survey of the Compression Lifecycle in MLLMs , author=. 2026 , publisher=
2026
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Videollm-online: Online video large language model for streaming video , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[29]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
SynC-LLM: Generation of Large-Scale Synthetic Circuit Code with Hierarchical Language Models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[38]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
DrFrattn: Directly Learn Adaptive Policy from Attention for Simultaneous Machine Translation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[39]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Divergence-guided simultaneous speech translation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[42]
Advances in Neural Information Processing Systems (NeurIPS) , year=
QLoRA: Efficient Finetuning of Quantized LLMs , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[43]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Advances in Neural Information Processing Systems , volume=
Exploiting llm quantization , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
International conference on machine learning , pages=
Sparsegpt: Massive language models can be accurately pruned in one-shot , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[52]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Llms can achieve high-quality simultaneous machine translation as efficiently as offline , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[54]
International Conference on Learning Representations , volume=
Minillm: Knowledge distillation of large language models , author=. International Conference on Learning Representations , volume=
-
[55]
International Conference on Learning Representations , volume=
On-policy distillation of language models: Learning from self-generated mistakes , author=. International Conference on Learning Representations , volume=
-
[58]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , pages=
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , pages=
-
[59]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[60]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Distilling Reasoning Capabilities into Smaller Language Models , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[61]
On-policy distillation of language models: Learning from self-generated mistakes
Agarwal, R., Vieillard, N., Zhou, Y., Stanczyk, P., Ramos Garea, S., Geist, M., and Bachem, O. On-policy distillation of language models: Learning from self-generated mistakes. In International Conference on Learning Representations, volume 2024, pp.\ 21246--21263, 2024
2024
-
[62]
L., Choudhary, S., Moon, S., Zhang, X., Sagar, A., Appini, S
Arora, S., Khan, H., Sun, K., Dong, X. L., Choudhary, S., Moon, S., Zhang, X., Sagar, A., Appini, S. T., Patnaik, K., et al. Stream rag: Instant and accurate spoken dialogue systems with streaming tool usage. arXiv preprint arXiv:2510.02044, 2025
-
[63]
Ashkboos, S., Croci, M. L., Nascimento, M. G. d., Hoefler, T., and Hensman, J. Slicegpt: Compress large language models by deleting rows and columns. arXiv preprint arXiv:2401.15024, 2024
-
[64]
Overview of the iwslt 2017 evaluation campaign
Cettolo, M., Federico, M., Bentivogli, L., Niehues, J., St \"u ker, S., Sudoh, K., Yoshino, K., and Federmann, C. Overview of the iwslt 2017 evaluation campaign. In Proceedings of the 14th International Workshop on Spoken Language Translation, pp.\ 2--14, 2017
2017
-
[65]
Q., Song, C., Gao, D., Liu, J.-W., Gao, Z., Mao, D., and Shou, M
Chen, J., Lv, Z., Wu, S., Lin, K. Q., Song, C., Gao, D., Liu, J.-W., Gao, Z., Mao, D., and Shou, M. Z. Videollm-online: Online video large language model for streaming video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 18407--18418, 2024 a
2024
-
[66]
Chen, J., Zeng, Z., Lin, Y., Li, W., Ma, Z., and Shou, M. Z. Livecc: Learning video llm with streaming speech transcription at scale. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 29083--29095, 2025
2025
-
[67]
Divergence-guided simultaneous speech translation
Chen, X., Fan, K., Luo, W., Zhang, L., Zhao, L., Liu, X., and Huang, Z. Divergence-guided simultaneous speech translation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp.\ 17799--17807, 2024 b
2024
-
[68]
D ialog S um: A real-life scenario dialogue summarization dataset
Chen, Y., Liu, Y., Chen, L., and Zhang, Y. D ialog S um: A real-life scenario dialogue summarization dataset. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp.\ 5062--5074, Online, August 2021. Association for Computational Linguistics. doi:10.18653/v1/2021.findings-acl.449. URL https://aclanthology.org/2021.findings-acl.449
-
[69]
Seed liveinterpret 2.0: End-to-end simultaneous speech-to-speech translation with your voice
Cheng, S., Bao, Y., Huang, Z., Lu, Y., Peng, N., Xu, L., Yu, R., Cao, R., Du, Y., Han, T., et al. Seed liveinterpret 2.0: End-to-end simultaneous speech-to-speech translation with your voice. arXiv preprint arXiv:2507.17527, 2025
-
[70]
Stitch: Simultaneous thinking and talking with chunked reasoning for spoken language models
Chiang, C.-H., Wang, X., Li, L., Lin, C.-C., Lin, K., Liu, S., Wang, Z., Yang, Z., Lee, H.-y., and Wang, L. Stitch: Simultaneous thinking and talking with chunked reasoning for spoken language models. arXiv preprint arXiv:2507.15375, 2025
-
[71]
Chu, Y., Xu, J., Yang, Q., Wei, H., Wei, X., Guo, Z., Leng, Y., Lv, Y., He, J., Lin, J., et al. Qwen2-audio technical report. arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[72]
Bert: Pre-training of deep bidirectional transformers for language understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp.\ 4171--4186, 2019
2019
-
[73]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Du, Z., Wang, Y., Chen, Q., Shi, X., Lv, X., Zhao, T., Gao, Z., Yang, Y., Gao, C., Wang, H., et al. Cosyvoice 2: Scalable streaming speech synthesis with large language models. arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Exploiting llm quantization
Egashira, K., Vero, M., Staab, R., He, J., and Vechev, M. Exploiting llm quantization. Advances in Neural Information Processing Systems, 37: 0 41709--41732, 2024
2024
-
[75]
Visipruner: Decoding discontinuous cross-modal dynamics for efficient multimodal llms
Fan, Y., Zhao, A., Fu, J., Tong, J., Su, H., Pan, Y., Zhang, W., and Shen, X. Visipruner: Decoding discontinuous cross-modal dynamics for efficient multimodal llms. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 18896--18913, 2025
2025
-
[76]
Fan, Y., Tong, J., Zhao, A., and Shen, X. What do visual tokens really encode? uncovering sparsity and redundancy in multimodal large language models. arXiv preprint arXiv:2603.00510, 2026
-
[77]
and Alistarh, D
Frantar, E. and Alistarh, D. Sparsegpt: Massive language models can be accurately pruned in one-shot. In International conference on machine learning, pp.\ 10323--10337. PMLR, 2023
2023
-
[78]
Llms can achieve high-quality simultaneous machine translation as efficiently as offline
Fu, B., Liao, M., Fan, K., Li, C., Zhang, L., Chen, Y., and Shi, X. Llms can achieve high-quality simultaneous machine translation as efficiently as offline. In Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 20372--20395, 2025
2025
-
[79]
Lazyllm: Dynamic token pruning for efficient long context llm inference
Fu, Q., Cho, M., Merth, T., Mehta, S., Rastegari, M., and Najibi, M. Lazyllm: Dynamic token pruning for efficient long context llm inference. arXiv preprint arXiv:2407.14057, 2024
-
[80]
Minillm: Knowledge distillation of large language models
Gu, Y., Dong, L., Wei, F., and Huang, M. Minillm: Knowledge distillation of large language models. In International Conference on Learning Representations, volume 2024, pp.\ 32694--32717, 2024
2024
-
[81]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[82]
Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes
Hsieh, C.-Y., Li, C.-L., Yeh, C.-k., Nakhost, H., Fujii, Y., Ratner, A., Krishna, R., Lee, C.-Y., and Pfister, T. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. In Findings of the Association for Computational Linguistics: ACL 2023, pp.\ 8003--8017, 2023
2023
-
[83]
StreamGaze: Gaze-Guided Temporal Reasoning and Proactive Understanding in Streaming Videos
Lee, D., Mukherjee, S., Kveton, B., Rossi, R. A., Lai, V. D., Yoon, S., Bui, T., Dernoncourt, F., and Bansal, M. Streamgaze: Gaze-guided temporal reasoning and proactive understanding in streaming videos. arXiv preprint arXiv:2512.01707, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[84]
Li, C.-H., Wu, S.-L., Liu, C.-L., and Lee, H.-y. Spoken squad: A study of mitigating the impact of speech recognition errors on listening comprehension. arXiv preprint arXiv:1804.00320, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[85]
Lin, J., Tong, J., Wu, H., Zhang, J., Liu, J., Jin, X., and Shen, X. Speak while watching: Unleashing true real-time video understanding capability of multimodal large language models. arXiv preprint arXiv:2601.06843, 2026
- [86]
-
[87]
Sync-llm: Generation of large-scale synthetic circuit code with hierarchical language models
Liu, S., Lu, Y., Fang, W., Wang, J., and Xie, Z. Sync-llm: Generation of large-scale synthetic circuit code with hierarchical language models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 17361--17376, 2025
2025
-
[88]
SpinQuant: LLM quantization with learned rotations
Liu, Z., Zhao, C., Fedorov, I., Soran, B., Choudhary, D., Krishnamoorthi, R., Chandra, V., Tian, Y., and Blankevoort, T. Spinquant: Llm quantization with learned rotations. arXiv preprint arXiv:2405.16406, 2024 b
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[89]
Stacl: Simultaneous translation with implicit anticipation and controllable latency using prefix-to-prefix framework
Ma, M., Huang, L., Xiong, H., Zheng, R., Liu, K., Zheng, B., Zhang, C., He, Z., Liu, H., Li, X., et al. Stacl: Simultaneous translation with implicit anticipation and controllable latency using prefix-to-prefix framework. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019), pp.\ 3025--3036, 2019
2019
-
[90]
OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[91]
Librispeech: an asr corpus based on public domain audio books
Panayotov, V., Chen, G., Povey, D., and Khudanpur, S. Librispeech: an asr corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp.\ 5206--5210. IEEE, 2015
2015
-
[92]
W., Xu, T., Brockman, G., McLeavey, C., and Sutskever, I
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., and Sutskever, I. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pp.\ 28492--28518. PMLR, 2023
2023
-
[93]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[94]
J., and Renshaw, E
Richardson, M., Burges, C. J., and Renshaw, E. Mctest: A challenge dataset for the open-domain machine comprehension of text. In Proceedings of the 2013 conference on empirical methods in natural language processing, pp.\ 193--203, 2013
2013
-
[95]
Distilling reasoning capabilities into smaller language models
Shridhar, K., Stolfo, A., and Sachan, M. Distilling reasoning capabilities into smaller language models. In Findings of the Association for Computational Linguistics: ACL 2023, pp.\ 7059--7073, 2023
2023
-
[96]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[97]
Team, Q. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[98]
Streamingthinker: Large language models can think while reading
Tong, J., Fan, Y., Zhao, A., Ma, Y., and Shen, X. Streamingthinker: Large language models can think while reading. arXiv preprint arXiv:2510.17238, 2025 a
-
[99]
Tong, J., Fu, J., Lin, Z., Fan, Y., Zhao, A., Su, H., and Shen, X. Llm as effective streaming processor: Bridging streaming-batch mismatches with group position encoding. arXiv preprint arXiv:2505.16983, 2025 b
-
[100]
From Static Inference to Dynamic Interaction: A Survey of Streaming Large Language Models
Tong, J., Wang, Z., Ren, Y., Yin, P., Wu, H., Zhang, W., and Shen, X. From static inference to dynamic interaction: A survey of streaming large language models. arXiv preprint arXiv:2603.04592, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[101]
A., Khashabi, D., and Hajishirzi, H
Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., and Hajishirzi, H. Self-instruct: Aligning language models with self-generated instructions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pp.\ 13484--13508, 2023
2023
-
[102]
Mmduet2: Enhancing proactive interaction of video mllms with multi-turn reinforcement learning
Wang, Y., Liu, S., Wang, D., Xu, N., Wan, G., Zhang, H., and Zhao, D. Mmduet2: Enhancing proactive interaction of video mllms with multi-turn reinforcement learning. arXiv preprint arXiv:2512.06810, 2025
-
[103]
Wu, H., Fan, Y., Dai, J., Tong, J., Ma, Y., and Shen, X. Hidrop: Hierarchical vision token reduction in mllms via late injection, concave pyramid pruning, and early exit. arXiv preprint arXiv:2602.23699, 2026 a
-
[104]
From data to model: A survey of the compression lifecycle in mllms
Wu, H., Tong, J., Wang, X., Tan, Y., Zeng, C., Antsiferova, A., and Shen, X. From data to model: A survey of the compression lifecycle in mllms. 2026 b
2026
-
[105]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y., Chen, B., Han, S., and Lewis, M. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[106]
Interleaved reasoning for large language models via reinforcement learning
Xie, R., Qiu, D., Gopinath, D., Lin, D., Sun, Y., Wang, C., Potdar, S., and Dhingra, B. Interleaved reasoning for large language models via reinforcement learning. arXiv preprint arXiv:2505.19640, 2025
-
[107]
Xu, J., Guo, Z., Hu, H., Chu, Y., Wang, X., He, J., Wang, Y., Shi, X., He, T., Zhu, X., Lv, Y., Wang, Y., Guo, D., Wang, H., Ma, L., Zhang, P., Zhang, X., Hao, H., Guo, Z., Yang, B., Zhang, B., Ma, Z., Wei, X., Bai, S., Chen, K., Liu, X., Wang, P., Yang, M., Liu, D., Ren, X., Zheng, B., Men, R., Zhou, F., Yu, B., Yang, J., Yu, L., Zhou, J., and Lin, J. Qw...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[108]
StreamingVLM: Real-Time Understanding for Infinite Video Streams
Xu, R., Xiao, G., Chen, Y., He, L., Peng, K., Lu, Y., and Han, S. Streamingvlm: Real-time understanding for infinite video streams. arXiv preprint arXiv:2510.09608, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[109]
Seqpo-simt: Sequential policy optimization for simultaneous machine translation
Xu, T., Huang, Z., Sun, J., Cheng, S., and Lam, W. Seqpo-simt: Sequential policy optimization for simultaneous machine translation. arXiv preprint arXiv:2505.20622, 2025 c
-
[110]
Asynchronous Reasoning: Training-Free Interactive Thinking LLMs
Yakushev, G., Babina, N., Dastgerdi, M. V., Zhdanovskiy, V., Shutova, A., and Kuznedelev, D. Asynchronous reasoning: Training-free interactive thinking llms. arXiv preprint arXiv:2512.10931, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[111]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[112]
Pyramidinfer: Pyramid kv cache compression for high-throughput llm inference
Yang, D., Han, X., Gao, Y., Hu, Y., Zhang, S., and Zhao, H. Pyramidinfer: Pyramid kv cache compression for high-throughput llm inference. arXiv preprint arXiv:2405.12532, 2024
-
[113]
Think-as-you-see: Streaming chain-of-thought reasoning for large vision-language models
Zhang, J., Tong, J., Lin, J., Wu, H., Sun, Y., Ma, Y., and Shen, X. Think-as-you-see: Streaming chain-of-thought reasoning for large vision-language models. arXiv preprint arXiv:2603.02872, 2026
-
[114]
H2o: Heavy-hitter oracle for efficient generative inference of large language models
Zhang, Z., Sheng, Y., Zhou, T., Chen, T., Zheng, L., Cai, R., Song, Z., Tian, Y., R \'e , C., Barrett, C., et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems, 36: 0 34661--34710, 2023
2023
-
[115]
Skipgpt: Dynamic layer pruning reinvented with token awareness and module decoupling
Zhao, A., Ye, F., Fan, Y., Tong, J., Fei, Z., Su, H., and Shen, X. Skipgpt: Dynamic layer pruning reinvented with token awareness and module decoupling. arXiv preprint arXiv:2506.04179, 2025 a
-
[116]
On-policy supervised fine-tuning for efficient reasoning
Zhao, A., Chen, Z., Tong, J., Fan, Y., Ye, F., Li, S., Ma, Y., Li, W., and Shen, X. On-policy supervised fine-tuning for efficient reasoning. arXiv preprint arXiv:2602.13407, 2026 a
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.