Improving Visual Grounding in Remote Sensing via Cluster-Guided Refinement and Model Ensemble Voting
Pith reviewed 2026-06-28 18:45 UTC · model grok-4.3
The pith
Two refinement pipelines and an ensemble voting strategy improve visual grounding accuracy in remote sensing by combining RemoteSAM and SAM3.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The proposed pipelines and ensemble approach outperform individual models by leveraging the complementary strengths of a remote-sensing-specialized grounding model and a general-purpose segmentation model, producing more accurate and spatially consistent visual grounding predictions.
What carries the argument
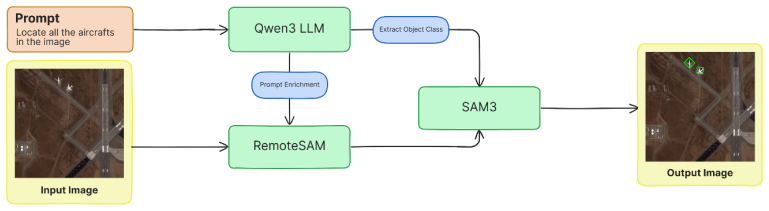
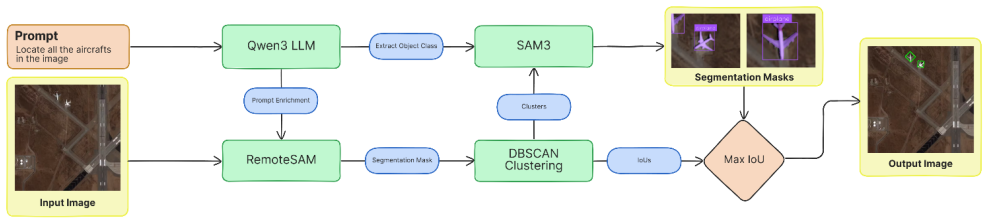
The Cluster-Aware Grounding Refinement (CGR) pipeline and majority-voting ensemble across multiple grounding pipelines, which integrate initial estimates from RemoteSAM with refinements from SAM3.
Load-bearing premise
RemoteSAM's initial estimates are accurate enough that SAM3 can refine them consistently without adding new errors or scale mismatches.
What would settle it
Running the ensemble on a benchmark remote sensing visual grounding dataset and finding that its accuracy is not higher than that of the single best pipeline.
Figures



read the original abstract
Visual grounding aims to locate image regions that correspond to natural language descriptions and is a key component of interpretable vision systems. In remote sensing imagery, grounding is particularly challenging due to complex scenes, small objects, and large variations in scale. Relying on a single model is often insufficient to address these diverse challenges. In this work, we propose two grounding pipelines, Sequential Grounding Refinement (SGR) and Cluster-Aware Grounding Refinement (CGR), that combine the complementary strengths of RemoteSAM, a visual grounding model specialized for remote sensing, and SAM3, a powerful general-purpose segmentation model. Our approach first uses RemoteSAM to obtain an initial estimate of object location, which is then refined using SAM3 to produce more accurate and spatially consistent segmentations. Additionally, we explore an ensemble strategy based on majority voting across six diverse grounding pipelines, each with distinct capabilities. This multi-model framework improves robustness and significantly enhances localization accuracy. Experimental results demonstrate that the proposed pipelines and ensemble approach outperform individual models, leading to more reliable and precise visual grounding predictions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes two pipelines, Sequential Grounding Refinement (SGR) and Cluster-Aware Grounding Refinement (CGR), which use RemoteSAM to generate an initial estimate of object location in remote sensing images and then refine it using SAM3 for more accurate segmentations. It additionally describes an ensemble method using majority voting across six grounding pipelines and claims that these methods outperform individual models in visual grounding tasks.
Significance. If the claimed improvements are substantiated, the work could offer a useful approach for enhancing visual grounding in remote sensing by combining a domain-specific model with a general segmentation model and using ensembles for robustness, addressing challenges like small objects and scale variations.
major comments (2)
- [Abstract] Abstract: The abstract states that 'Experimental results demonstrate that the proposed pipelines and ensemble approach outperform individual models' but provides no quantitative metrics, specific baselines, dataset details, or error analysis. This absence prevents evaluation of the magnitude and reliability of the claimed improvements, which is central to the paper's contribution.
- [Abstract] Abstract: The proposed refinement pipelines rely on the assumption that RemoteSAM's initial estimates are accurate enough for SAM3 to consistently improve spatial consistency. However, no quantitative condition (e.g., minimum initial IoU or scale tolerance) is stated, and given the abstract's mention of small objects and large scale variation, this assumption risks being violated, potentially leading to degraded performance rather than improvement.
minor comments (1)
- [Abstract] Abstract: The description of the ensemble as 'across six diverse grounding pipelines' does not specify what the six pipelines are or how they differ.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the underlying assumptions of our refinement pipelines. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that 'Experimental results demonstrate that the proposed pipelines and ensemble approach outperform individual models' but provides no quantitative metrics, specific baselines, dataset details, or error analysis. This absence prevents evaluation of the magnitude and reliability of the claimed improvements, which is central to the paper's contribution.
Authors: We agree that the abstract would benefit from including key quantitative results to allow readers to assess the improvements immediately. In the revised manuscript, we will expand the abstract to report specific metrics (e.g., mean IoU gains on the evaluated remote sensing datasets), name the primary baselines (RemoteSAM and SAM3), and reference the datasets used. The full paper already contains detailed tables and error analysis; these will be summarized concisely in the abstract. revision: yes
-
Referee: [Abstract] Abstract: The proposed refinement pipelines rely on the assumption that RemoteSAM's initial estimates are accurate enough for SAM3 to consistently improve spatial consistency. However, no quantitative condition (e.g., minimum initial IoU or scale tolerance) is stated, and given the abstract's mention of small objects and large scale variation, this assumption risks being violated, potentially leading to degraded performance rather than improvement.
Authors: This is a fair and important point. While our experiments demonstrate net gains across the test sets (including challenging small-object cases), we did not explicitly define failure-mode thresholds for the refinement step. In the revision we will add a short paragraph in the method section stating the practical conditions under which SGR/CGR are applied (e.g., minimum initial box area and a coarse IoU check with the language prompt) and will include a brief analysis of cases where refinement may not help or could degrade results. This will make the assumptions transparent. revision: yes
Circularity Check
No circularity: purely empirical pipeline combination with no derivations or fitted predictions
full rationale
The paper describes two refinement pipelines (SGR, CGR) that chain RemoteSAM initial estimates into SAM3 refinement plus a majority-vote ensemble across six pipelines. All claims rest on experimental outperformance versus individual models; the abstract and provided text contain no equations, no parameter fitting presented as prediction, and no self-citation chains invoked to justify uniqueness or ansatzes. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2503.11070 (2025)
Falcon: A remote sensing vision-language foundation model , author=. arXiv preprint arXiv:2503.11070 , year=
-
[2]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Remotesam: Towards segment anything for earth observation , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[3]
SAM 3: Segment Anything with Concepts
SAM 3: Segment Anything with Concepts , author=. arXiv preprint arXiv:2511.16719 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Advances in Neural Information Processing Systems , volume=
Vrsbench: A versatile vision-language benchmark dataset for remote sensing image understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
A survey on object detection in optical remote sensing images , volume=
Cheng, Gong and Han, Junwei , year=. A survey on object detection in optical remote sensing images , volume=. doi:10.1016/j.isprsjprs.2016.03.014 , journal=
-
[6]
IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium , pages=
Object detection and instance segmentation in remote sensing imagery based on precise mask R-CNN , author=. IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium , pages=. 2019 , organization=
2019
-
[7]
IEEE Transactions on Geoscience and Remote Sensing , volume =
Exploring Models and Data for Remote Sensing Image Caption Generation , author=. IEEE Transactions on Geoscience and Remote Sensing , volume =
-
[8]
Nouman Ali and Bushra Zafar. UCM image dataset. 2018. doi:10.6084/m9.figshare.6085976.v2
-
[9]
2016 International conference on computer, information and telecommunication systems (Cits) , pages=
Deep semantic understanding of high resolution remote sensing image , author=. 2016 International conference on computer, information and telecommunication systems (Cits) , pages=. 2016 , organization=
2016
-
[10]
reben: Refined bigearthnet dataset for remote sensing image analysis , author=. arXiv preprint arXiv:2407.03653 , year=
-
[11]
IEEE Transactions on Geoscience and Remote Sensing , volume=
Rsvg: Exploring data and models for visual grounding on remote sensing data , author=. IEEE Transactions on Geoscience and Remote Sensing , volume=. 2023 , publisher=
2023
-
[12]
RS5M and GeoRSCLIP: A Large Scale Vision-Language Dataset and A Large Vision-Language Model for Remote Sensing , year=
Zhang, Zilun and Zhao, Tiancheng and Guo, Yulong and Yin, Jianwei , journal=. RS5M and GeoRSCLIP: A Large Scale Vision-Language Dataset and A Large Vision-Language Model for Remote Sensing , year=
-
[13]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Xlrs-bench: Could your multimodal llms understand extremely large ultra-high-resolution remote sensing imagery? , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[14]
Segment Anything , author=. arXiv:2304.02643 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
SAM 2: Segment Anything in Images and Videos
SAM 2: Segment Anything in Images and Videos , author=. arXiv preprint arXiv:2408.00714 , url=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Grounding dino: Marrying dino with grounded pre-training for open-set object detection , author=. arXiv preprint arXiv:2303.05499 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
International conference on machine learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[18]
2022 , booktitle=
Grounded Language-Image Pre-training , author=. 2022 , booktitle=
2022
-
[19]
Visual Instruction Tuning , author=
-
[20]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[22]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[23]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
The IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
GeoChat: Grounded Large Vision-Language Model for Remote Sensing , author=. The IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[25]
International Journal of Applied Earth Observation and Geoinformation , volume=
GeoGPT: An assistant for understanding and processing geospatial tasks , author=. International Journal of Applied Earth Observation and Geoinformation , volume=. 2024 , publisher=
2024
-
[26]
ISPRS Journal of Photogrammetry and Remote Sensing , volume=
Rsgpt: A remote sensing vision language model and benchmark , author=. ISPRS Journal of Photogrammetry and Remote Sensing , volume=. 2025 , publisher=
2025
-
[27]
IEEE Transactions on Geoscience and Remote Sensing , year=
Earthgpt: A universal multi-modal large language model for multi-sensor image comprehension in remote sensing domain , author=. IEEE Transactions on Geoscience and Remote Sensing , year=
-
[28]
2025 , eprint=
EarthMind: Leveraging Cross-Sensor Data for Advanced Earth Observation Interpretation with a Unified Multimodal LLM , author=. 2025 , eprint=
2025
-
[29]
Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling , author=. arXiv preprint arXiv:2412.05271 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Florence-2: Advancing a unified representation for a variety of vision tasks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[31]
European conference on computer vision , pages=
End-to-end object detection with transformers , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rotated multi-scale interaction network for referring remote sensing image segmentation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
arXiv preprint arXiv:2407.06095 , year=
Accelerating diffusion for sar-to-optical image translation via adversarial consistency distillation , author=. arXiv preprint arXiv:2407.06095 , year=
-
[34]
Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96) , pages=
A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise , author=. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96) , pages=
-
[35]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.