Richer Representations for Neural Algorithmic Reasoning via Auxiliary Reconstruction
Pith reviewed 2026-06-28 19:25 UTC · model grok-4.3
The pith
An auxiliary reconstruction task added to the encoder improves performance of neural networks on algorithmic reasoning benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
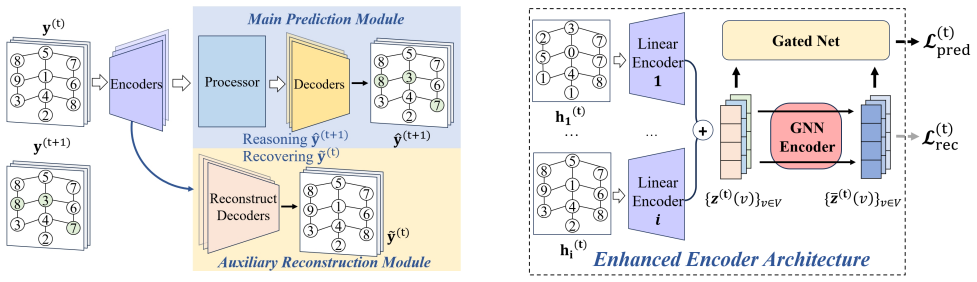
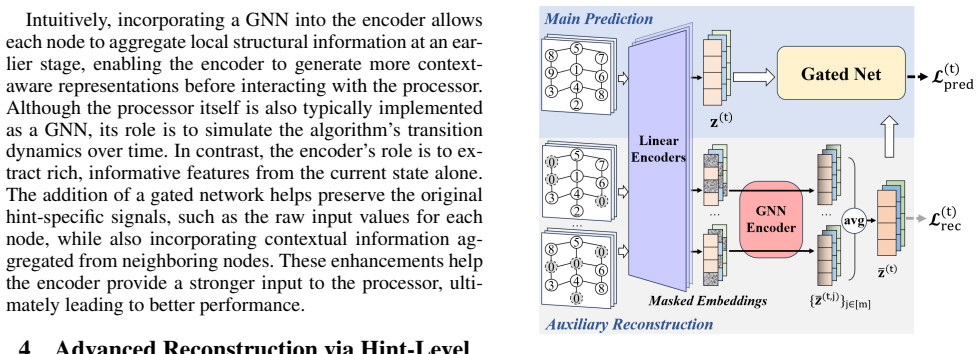
The central claim is that adding an auxiliary reconstruction task during training, which recovers the input state from its encoded representation, encourages the encoder to retain critical information about the input. An enhanced variant further captures intra-state feature dependencies. Experimental results show that this enables the encoder to learn richer representations and thereby improves the performance of existing processors on algorithmic reasoning tasks.
What carries the argument
The reconstruction module attached to the encoder that recovers the input state from the encoded representation.
If this is right
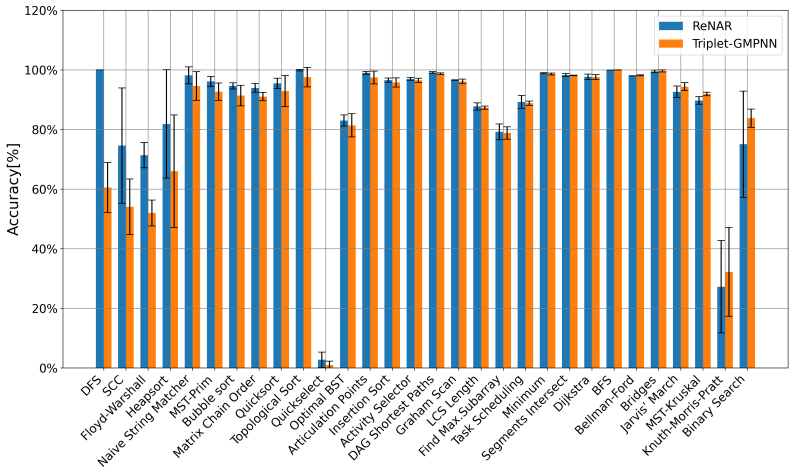
- Existing neural architectures achieve higher performance on standard benchmarks when the auxiliary task is incorporated.
- The encoder learns to capture correlations among features within a state under the enhanced variant.
- The processor can simulate algorithmic steps more accurately when given richer representations from the encoder.
- The approach applies directly to the common encoder-processor-decoder architecture without modifying the processor.
Where Pith is reading between the lines
- The reconstruction idea could be tested on the decoder or processor to see if similar gains appear in other parts of the architecture.
- The method points to representation quality as a potential bottleneck worth addressing in other neural reasoning setups.
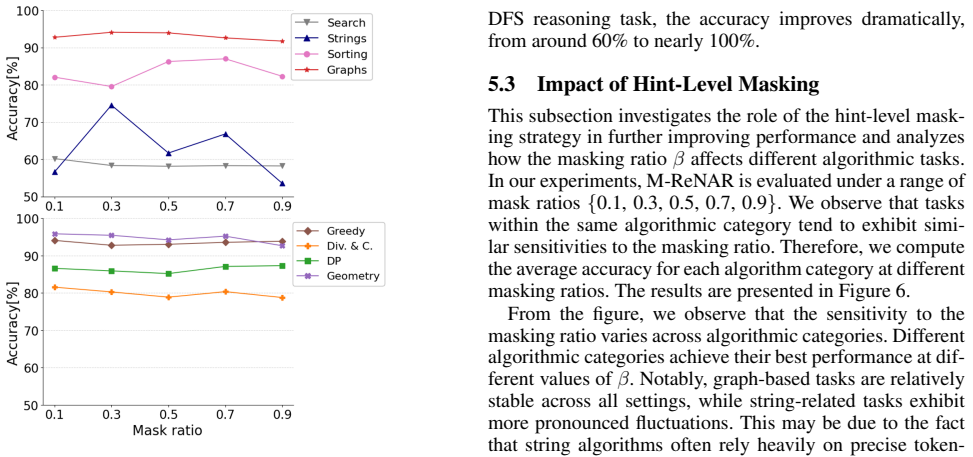
- One extension would be to measure whether the benefit scales to algorithms whose states have richer internal structure.
Load-bearing premise
The reconstruction objective aids rather than competes with the main algorithmic reasoning loss.
What would settle it
Running the reported experiments with the reconstruction module added and finding no improvement or a drop in accuracy on the standard benchmarks would falsify the claim.
Figures

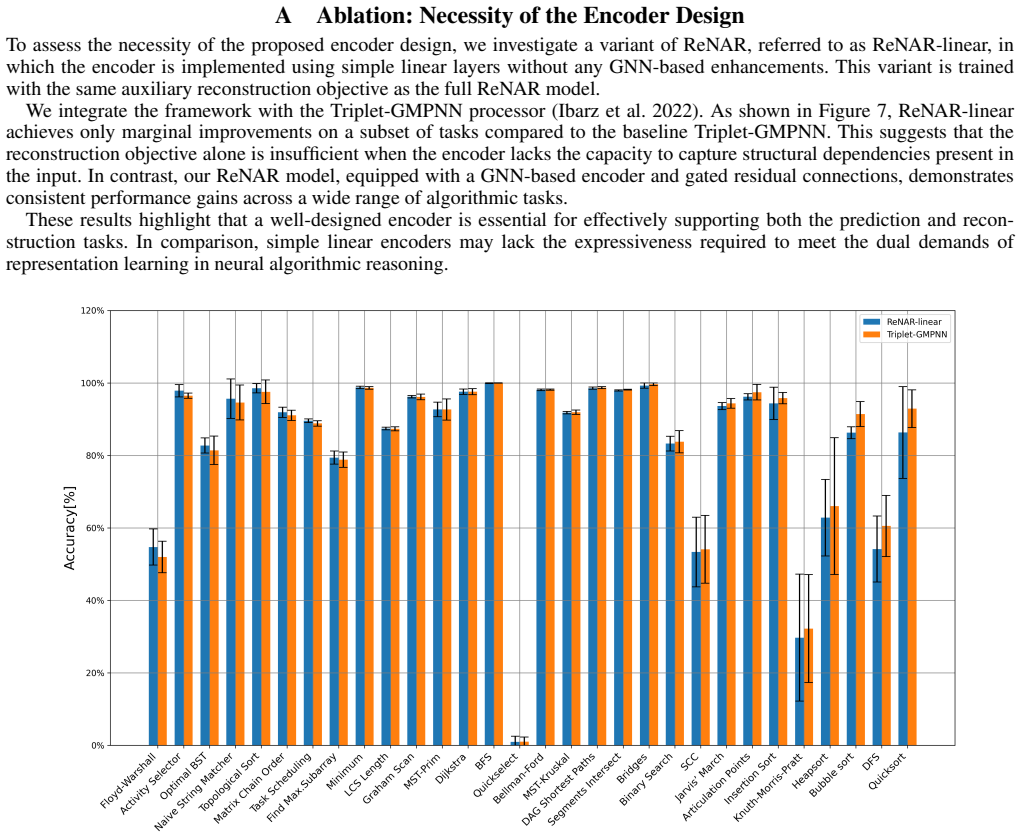
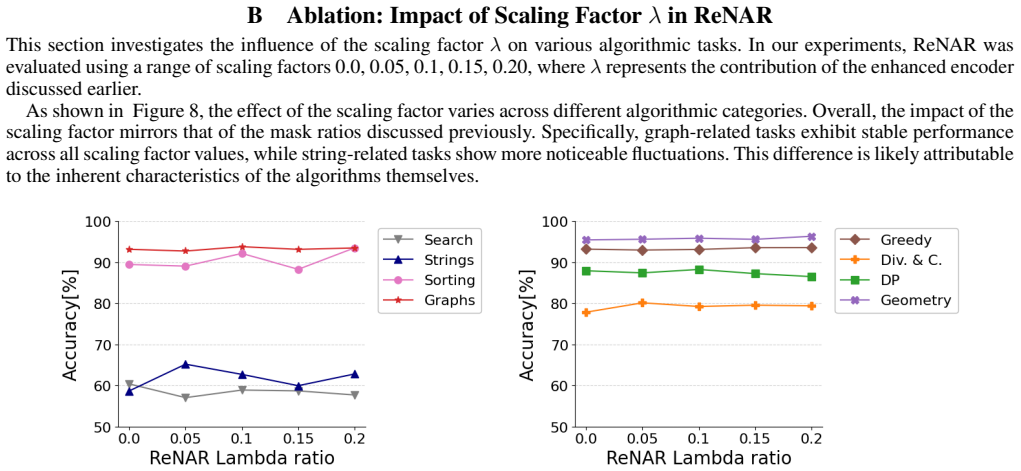
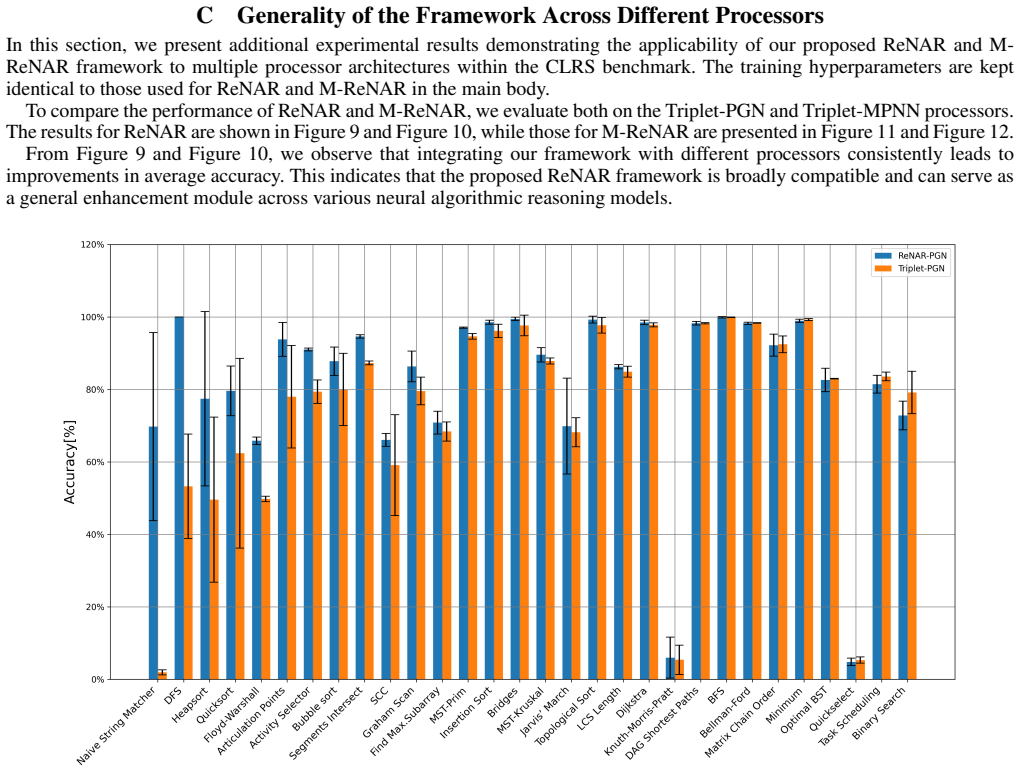
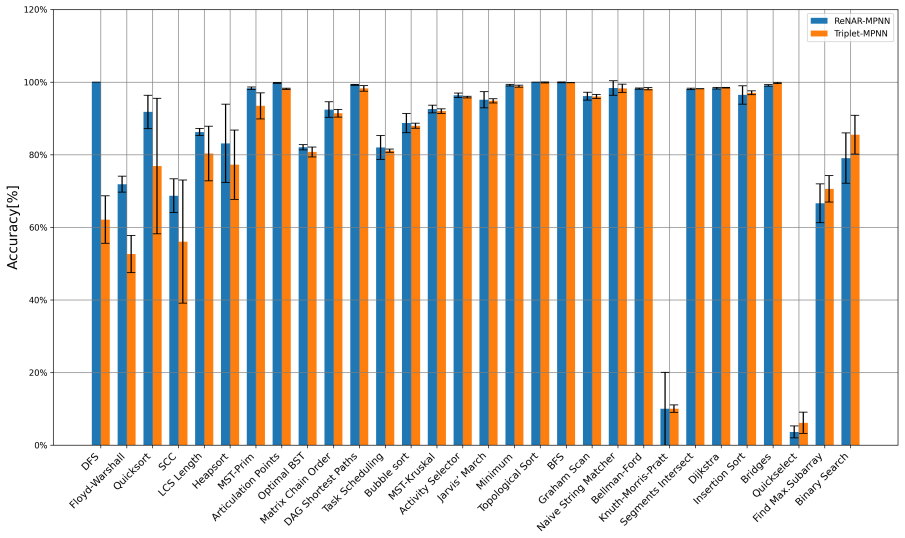
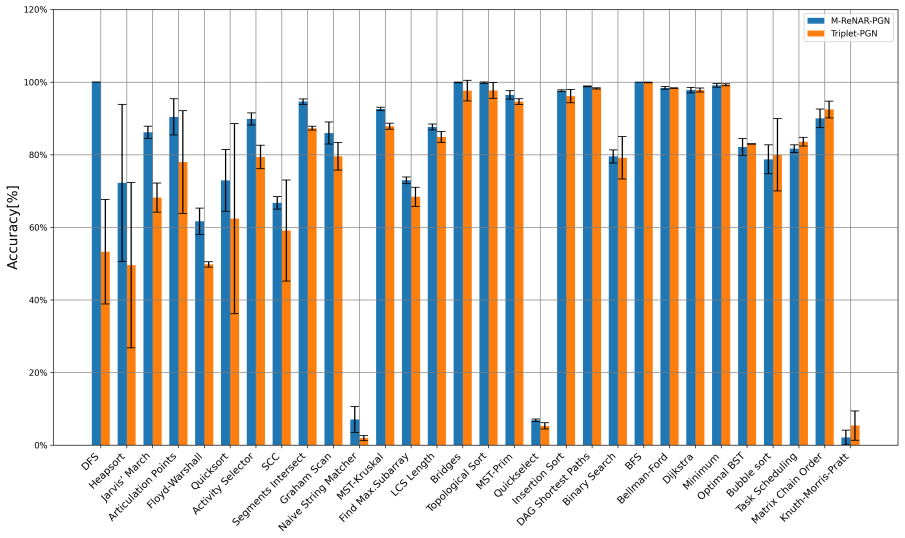
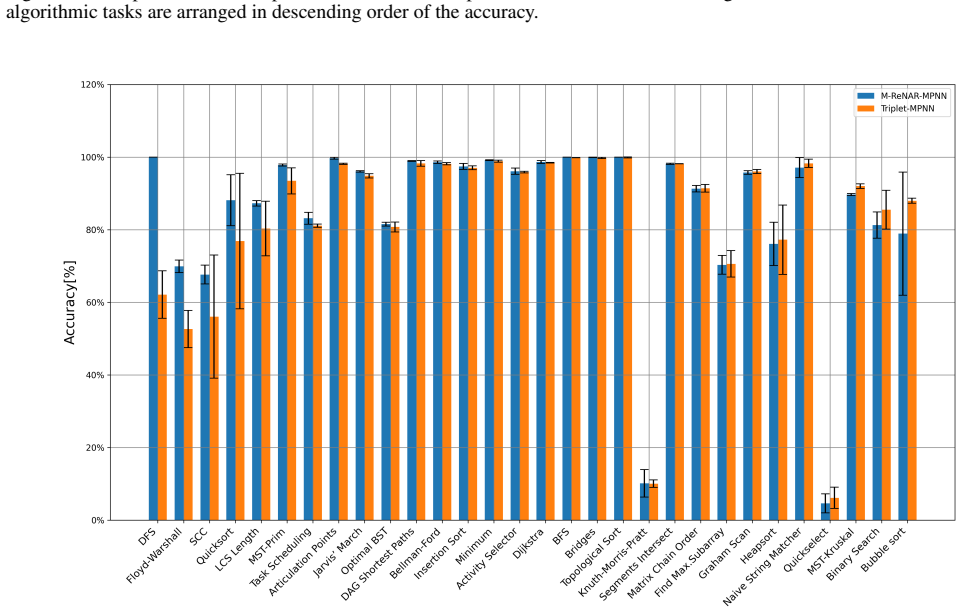
read the original abstract
Neural algorithmic reasoning has emerged as a popular research direction. It aims to train neural networks to mimic the step-by-step behavior of classical rule-based algorithms. More specifically, the execution of such algorithms can be abstracted as a sequence of states, where each state represents the intermediate outcome after an execution step. The training objective is to generate state sequences that replicate the underlying algorithmic process. A common framework for this task adopts an encoder-processor-decoder architecture, where the encoder learns representations of states, the processor simulates algorithmic steps, and the decoder reconstructs output states. While prior work has focused on improving the processor, the role of the encoder in representation learning has received little attention. Most methods rely on simple MLP encoders, raising the question of whether such representations are sufficiently informative for supporting algorithmic reasoning. This paper investigates how to improve encoder representations for neural algorithmic reasoning. We propose a reconstruction module that aims to recover the input state from its encoded representation. This auxiliary reconstruction task encourages the encoder to retain critical information about the input. We demonstrate that incorporating this task during training improves the performance of existing neural architectures on standard benchmarks. Furthermore, we observe that current encoders often underutilize the correlations among features within a state. To address this, we draw inspiration from self-supervised learning and design an enhanced variant of the auxiliary task that encourages the encoder to capture intra-state feature dependencies. Experimental results show that our method enables the encoder to learn richer representations, thereby enhancing the performance of existing processors on algorithmic reasoning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes adding an auxiliary reconstruction task (and an enhanced intra-state feature dependency variant) to the encoder in standard encoder-processor-decoder architectures for neural algorithmic reasoning. The reconstruction objective recovers the input state from its latent representation to encourage retention of critical information; the enhanced variant draws from self-supervised learning to capture feature correlations within states. The central claim is that these auxiliary tasks produce richer encoder representations that improve downstream performance of existing processors on algorithmic reasoning benchmarks.
Significance. If the empirical gains hold under controlled conditions, the work usefully shifts attention to the encoder (previously under-examined relative to the processor) and offers a lightweight, architecture-agnostic way to improve representation quality in NAR. The approach is simple to implement and could be broadly applicable if the auxiliary objective proves complementary rather than competitive.
major comments (2)
- [Experimental results] The manuscript provides no ablations on the relative weighting of the main algorithmic reasoning loss versus the auxiliary reconstruction loss, nor any comparison of processor accuracy with versus without the auxiliary term at matched compute. This is load-bearing for the claim that the auxiliary task yields richer representations rather than incidental regularization effects.
- [Method and Experiments] No analysis is given of potential interference between reconstruction accuracy and processor accuracy on state transitions, nor of whether reconstruction metrics correlate with or trade off against reasoning metrics. The central assumption that the auxiliary objective is complementary therefore remains untested.
minor comments (2)
- [Abstract and Experiments] The abstract refers to 'standard benchmarks' without naming them or reporting quantitative deltas, baselines, or error bars; the experimental section should include these details for reproducibility.
- [Method] Notation for the reconstruction module and its enhanced variant should be introduced with explicit equations rather than descriptive text only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical validation. We agree that the suggested ablations and analyses are important to support the central claims and will incorporate them in the revised manuscript.
read point-by-point responses
-
Referee: [Experimental results] The manuscript provides no ablations on the relative weighting of the main algorithmic reasoning loss versus the auxiliary reconstruction loss, nor any comparison of processor accuracy with versus without the auxiliary term at matched compute. This is load-bearing for the claim that the auxiliary task yields richer representations rather than incidental regularization effects.
Authors: We agree that these ablations are necessary to isolate the contribution of the auxiliary task. In the revised manuscript we will add experiments that sweep the relative weighting between the primary algorithmic reasoning loss and the auxiliary reconstruction loss. We will also report processor accuracy with and without the auxiliary term under matched compute budgets (e.g., equalized training steps or FLOPs) to distinguish representation quality improvements from incidental regularization. revision: yes
-
Referee: [Method and Experiments] No analysis is given of potential interference between reconstruction accuracy and processor accuracy on state transitions, nor of whether reconstruction metrics correlate with or trade off against reasoning metrics. The central assumption that the auxiliary objective is complementary therefore remains untested.
Authors: We acknowledge the absence of this analysis. The revised version will include a dedicated section examining the relationship between reconstruction accuracy and downstream reasoning metrics. This will comprise correlation plots and tables across tasks, as well as checks for interference or trade-offs between the two objectives, directly testing the complementarity assumption. revision: yes
Circularity Check
No circularity: empirical augmentation validated on external benchmarks
full rationale
The paper proposes an auxiliary reconstruction loss added to an encoder-processor-decoder architecture for neural algorithmic reasoning. The central claim is that this addition yields richer encoder representations and improved benchmark performance. No derivation chain is presented that reduces a claimed prediction or uniqueness result to a fitted parameter or self-citation; the method is an empirical training modification whose benefit is asserted via standard benchmark comparisons rather than by algebraic identity or self-referential definition. The provided text contains no equations, no self-citation load-bearing steps, and no renaming of known results as new derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NeurIPS , year =
Gleb Rodionov and Liudmila Prokhorenkova , title =. NeurIPS , year =
-
[2]
How to transfer algorithmic reasoning knowledge to learn new algorithms? , booktitle =
Louis. How to transfer algorithmic reasoning knowledge to learn new algorithms? , booktitle =
-
[3]
Hamrick and Larisa Markeeva and Alex Vitvitskyi and Razvan Pascanu and Petar Velickovic , title =
Wilfried Bounsi and Borja Ibarz and Andrew Dudzik and Jessica B. Hamrick and Larisa Markeeva and Alex Vitvitskyi and Razvan Pascanu and Petar Velickovic , title =. CoRR , volume =
-
[4]
Li Xu and Jimmy S. J. Ren and Ce Liu and Jiaya Jia , title =
-
[5]
Alsaadi , title =
Weibo Liu and Zidong Wang and Xiaohui Liu and Nianyin Zeng and Yurong Liu and Fuad E. Alsaadi , title =. Neurocomputing , volume =
-
[6]
Neurocomputing , volume =
Ivano Lauriola and Alberto Lavelli and Fabio Aiolli , title =. Neurocomputing , volume =
-
[7]
Patterns , volume =
Petar Velickovic and Charles Blundell , title =. Patterns , volume =
-
[8]
Petar Velickovic and Rex Ying and Matilde Padovano and Raia Hadsell and Charles Blundell , title =
-
[9]
CoRR , volume =
Yujia Li and Felix Gimeno and Pushmeet Kohli and Oriol Vinyals , title =. CoRR , volume =
-
[10]
Danilo Numeroso and Davide Bacciu and Petar Velickovic , title =
-
[11]
Petar Velickovic and Adri. The
-
[12]
A Generalist Neural Algorithmic Learner , booktitle =
Borja Ibarz and Vitaly Kurin and George Papamakarios and Kyriacos Nikiforou and Mehdi Bennani and R. A Generalist Neural Algorithmic Learner , booktitle =
-
[13]
Gomez and Thomas Rainforth and Yarin Gal , title =
Jannik Kossen and Neil Band and Clare Lyle and Aidan N. Gomez and Thomas Rainforth and Yarin Gal , title =. NeurIPS , pages =
-
[14]
Advanced Lectures on Machine Learning , series =
Carl Edward Rasmussen , title =. Advanced Lectures on Machine Learning , series =
-
[15]
Bing Shuai and Gang Wang and Zhen Zuo and Bing Wang and Lifan Zhao , title =
-
[16]
NeurIPS , year =
Zhiying Jiang and Yiqin Dai and Ji Xin and Ming Li and Jimmy Lin , title =. NeurIPS , year =
-
[17]
Schoenholz and Patrick F
Justin Gilmer and Samuel S. Schoenholz and Patrick F. Riley and Oriol Vinyals and George E. Dahl , title =
-
[18]
Hamrick and Kelsey R
Jessica B. Hamrick and Kelsey R. Allen and Victor Bapst and Tina Zhu and Kevin R. McKee and Josh Tenenbaum and Peter W. Battaglia , title =. CogSci , publisher =
-
[19]
Sadegh Mahdavi and Kevin Swersky and Thomas Kipf and Milad Hashemi and Christos Thrampoulidis and Renjie Liao , title =. Trans. Mach. Learn. Res. , volume =
-
[20]
Beatrice Bevilacqua and Kyriacos Nikiforou and Borja Ibarz and Ioana Bica and Michela Paganini and Charles Blundell and Jovana Mitrovic and Petar Velickovic , title =
-
[21]
Cormen and Charles E
Thomas H. Cormen and Charles E. Leiserson and Ronald L. Rivest and Clifford Stein , title =
-
[22]
Neural Priority Queues for Graph Neural Networks , booktitle =
Rishabh Jain and Petar Velickovic and Pietro Li. Neural Priority Queues for Graph Neural Networks , booktitle =. 2023 , publisher =
2023
-
[23]
The Second Learning on Graphs Conference , year=
Recursive Algorithmic Reasoning , author=. The Second Learning on Graphs Conference , year=
-
[24]
BigData , series =
Shisheng Deng and Dongping Liao and Xitong Gao and Juanjuan Zhao and Kejiang Ye , title =. BigData , series =
-
[25]
Expert Syst
Wongyung Nam and Beakcheol Jang , title =. Expert Syst. Appl. , volume =
-
[26]
Neural Algorithmic Reasoners are Implicit Planners , booktitle =
Andreea Deac and Petar Velickovic and Ognjen Milinkovic and Pierre. Neural Algorithmic Reasoners are Implicit Planners , booktitle =
-
[27]
LoG , series =
Petar Velickovic and Matko Bosnjak and Thomas Kipf and Alexander Lerchner and Raia Hadsell and Razvan Pascanu and Charles Blundell , title =. LoG , series =
-
[28]
Cameron Diao and Ricky Loynd , title =
-
[29]
CommNet , pages =
Mohammed Amine El Mrabet and Khalid El Makkaoui and Ahmed Faize , title =. CommNet , pages =
-
[30]
Abeer Aljuaid and Mohd Anwar , title =
-
[31]
NeurIPS , year =
Andrew Joseph Dudzik and Petar Velickovic , title =. NeurIPS , year =
-
[32]
Graph Attention Networks , booktitle =
Petar Velickovic and Guillem Cucurull and Arantxa Casanova and Adriana Romero and Pietro Li. Graph Attention Networks , booktitle =
-
[33]
Gomez and Lukasz Kaiser and Illia Polosukhin , title =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , title =
-
[34]
Shuo Shi and Chao Peng and Chenyang Xu and Zhengfeng Yang , title =
-
[35]
Girshick , title =
Kaiming He and Haoqi Fan and Yuxin Wu and Saining Xie and Ross B. Girshick , title =
-
[36]
Jacob Devlin and Ming
-
[37]
Hangbo Bao and Li Dong and Songhao Piao and Furu Wei , title =
-
[38]
NeurIPS , year =
Yuning You and Tianlong Chen and Yongduo Sui and Ting Chen and Zhangyang Wang and Yang Shen , title =. NeurIPS , year =
-
[39]
Pande and Jure Leskovec , title =
Weihua Hu and Bowen Liu and Joseph Gomes and Marinka Zitnik and Percy Liang and Vijay S. Pande and Jure Leskovec , title =
-
[40]
Li , title =
Jun Xia and Lirong Wu and Jintao Chen and Bozhen Hu and Stan Z. Li , title =
-
[41]
Zhenyu Hou and Xiao Liu and Yukuo Cen and Yuxiao Dong and Hongxia Yang and Chunjie Wang and Jie Tang , title =
-
[42]
Kipf and Max Welling , title =
Thomas N. Kipf and Max Welling , title =
-
[43]
CoRR , volume =
Kaijia Xu and Petar Velickovic , title =. CoRR , volume =
-
[44]
Montgomery Bohde and Meng Liu and Alexandra Saxton and Shuiwang Ji , title =
-
[45]
Du and Ken
Keyulu Xu and Jingling Li and Mozhi Zhang and Simon S. Du and Ken. What Can Neural Networks Reason About? , booktitle =
-
[46]
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , title =
-
[47]
Extracting and composing robust features with denoising autoencoders , booktitle =
Pascal Vincent and Hugo Larochelle and Yoshua Bengio and Pierre. Extracting and composing robust features with denoising autoencoders , booktitle =
-
[48]
Kingma and Max Welling , title =
Diederik P. Kingma and Max Welling , title =
-
[49]
Kipf and Max Welling , title =
Thomas N. Kipf and Max Welling , title =. CoRR , volume =
-
[50]
Yuxiang Wang and Xiao Yan and Chuang Hu and Quanqing Xu and Chuanhui Yang and Fangcheng Fu and Wentao Zhang and Hao Wang and Bo Du and Jiawei Jiang , title =
-
[51]
Zhenyu Hou and Yufei He and Yukuo Cen and Xiao Liu and Yuxiao Dong and Evgeny Kharlamov and Jie Tang , title =
-
[52]
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =
-
[53]
Masked Autoencoders Are Scalable Vision Learners , booktitle =
Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Doll. Masked Autoencoders Are Scalable Vision Learners , booktitle =
-
[54]
CoRR , volume =
Qiaoyu Tan and Ninghao Liu and Xiao Huang and Rui Chen and Soo. CoRR , volume =
-
[55]
Hinton , title =
Ting Chen and Simon Kornblith and Mohammad Norouzi and Geoffrey E. Hinton , title =
-
[56]
NeurIPS , year =
Yu Rong and Yatao Bian and Tingyang Xu and Weiyang Xie and Ying Wei and Wenbing Huang and Junzhou Huang , title =. NeurIPS , year =
-
[57]
Efros , title =
Carl Doersch and Abhinav Gupta and Alexei A. Efros , title =
-
[58]
Battaglia and Jessica B
Peter W. Battaglia and Jessica B. Hamrick and Victor Bapst and Alvaro Sanchez. Relational inductive biases, deep learning, and graph networks , journal =
-
[59]
Peters and Mark Neumann and Mohit Iyyer and Matt Gardner and Christopher Clark and Kenton Lee and Luke Zettlemoyer , title =
Matthew E. Peters and Mark Neumann and Mohit Iyyer and Matt Gardner and Christopher Clark and Kenton Lee and Luke Zettlemoyer , title =. CoRR , volume =
-
[60]
Jintang Li and Ruofan Wu and Wangbin Sun and Liang Chen and Sheng Tian and Liang Zhu and Changhua Meng and Zibin Zheng and Weiqiang Wang , title =
-
[61]
Overlan and Razvan Pascanu and Oriol Vinyals and Charles Blundell , title =
Petar Velickovic and Lars Buesing and Matthew C. Overlan and Razvan Pascanu and Oriol Vinyals and Charles Blundell , title =. NeurIPS , year =
-
[62]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[63]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[64]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[65]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[66]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[67]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[68]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[69]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[70]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[71]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[72]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.