A Practical Upper Bound on Selection Bias Effects in Medical Prediction Models
Pith reviewed 2026-06-28 19:19 UTC · model grok-4.3
The pith
A new upper bound estimates worst-case performance drop from selection bias in medical models even with only partial information on the bias mechanism and target data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
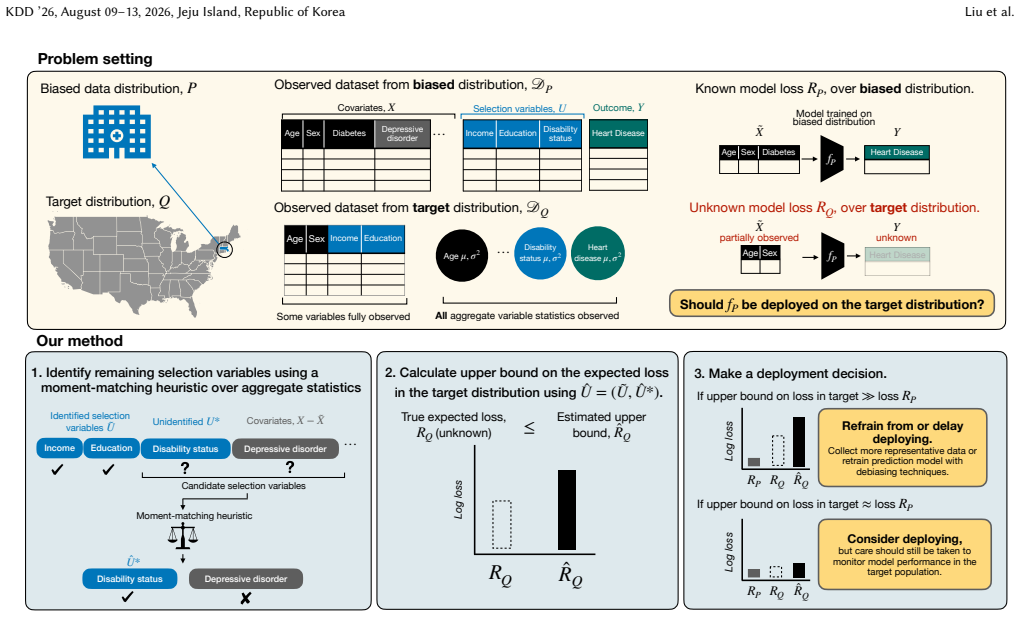
The paper proposes a novel upper bound on the worst-case model performance on the target population under the realistic setting where the selection mechanism and the target population data are only partially observed.
What carries the argument
The upper bound on worst-case target-population performance, computed from partial observations of the selection mechanism and target data.
Load-bearing premise
The bound remains computable and valid when only partial information is available about the selection mechanism and target population data.
What would settle it
A case in which actual model performance on a fully observed target population exceeds the computed upper bound would show the bound does not hold.
Figures

read the original abstract
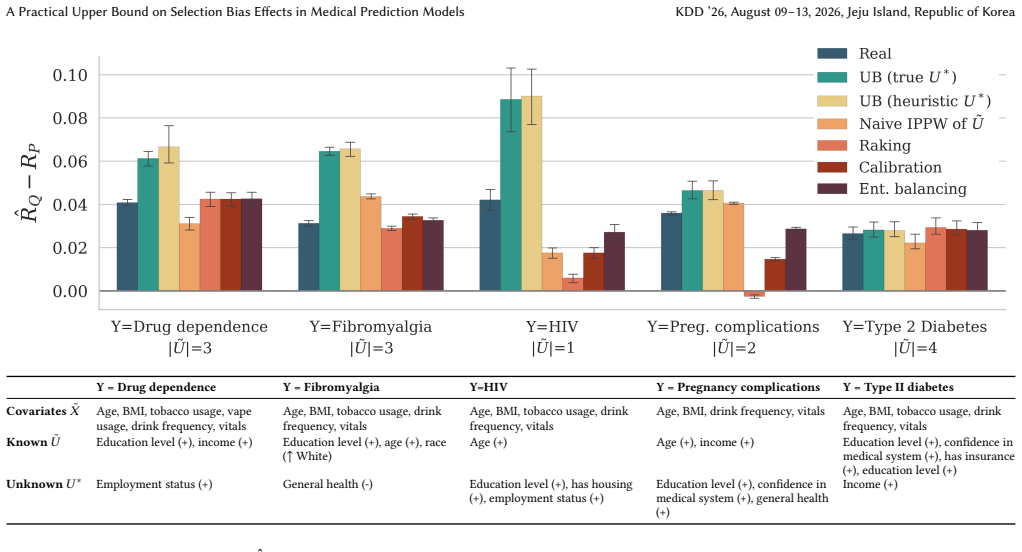
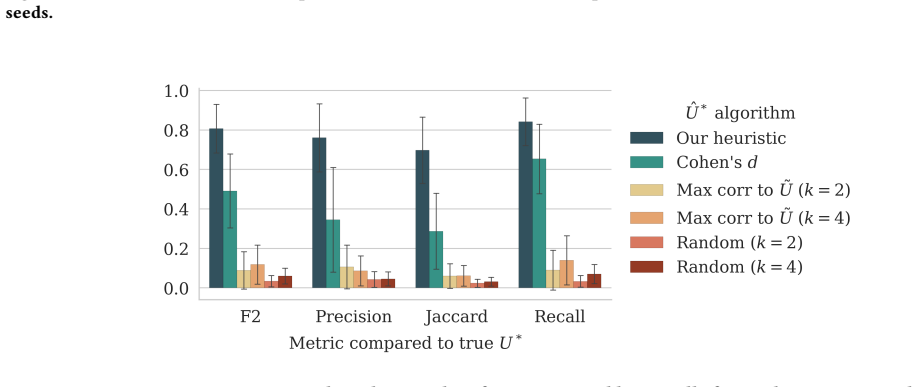
Selection bias is a common and often unavoidable aspect of real-world data that challenges the generalizability of machine learning models. When models trained on biased data are deployed in the broader target population, poor model generalization may lead to real harm, particularly in high-risk settings such as healthcare. This risk highlights the need for practitioners to reliably assess model generalizability prior to deployment. However, existing methods for predicting model performance rely on unrealistic access to the target distribution or knowledge of the selection mechanism causing bias. To address these limitations, we propose a novel upper bound on the worst-case model performance on the target population under the realistic setting where the selection mechanism and the target population data are only partially observed. We demonstrate the validity and practical utility of our method through experiments on fully synthetic data, semi-synthetic data derived from the All of Us Research Program, and real-world selection bias in MIMIC-IV. Our work offers a principled and practical tool to estimate the impact of selection bias in an otherwise intractable setting, thereby enabling practitioners to build safer and more generalizable models in healthcare and beyond.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel upper bound on the worst-case performance of a prediction model on the target population, derived under a partial-observation model of both the selection mechanism (inducing bias) and the target data distribution. The bound is claimed to be computable without full knowledge of either, and its validity and utility are demonstrated via experiments on fully synthetic data, semi-synthetic data from the All of Us program, and real selection bias in MIMIC-IV.
Significance. If the bound is non-vacuous and correctly derived from the stated partial-observability assumptions, the result would be significant for medical ML: it supplies a practical diagnostic for generalization risk in the common regime where neither the full target distribution nor the exact selection process is known. The use of both semi-synthetic and real clinical data (MIMIC-IV) strengthens the practical claim.
major comments (2)
- [§3] §3 (Partial Observability Model): the precise information assumed available about the selection mechanism is not stated explicitly. Without a formal definition of what is observed versus unobserved (e.g., which moments, which conditional distributions, or which parameters of the selection probability), it is impossible to verify that the bound remains non-trivial and does not implicitly require quantities that are unavailable under the stated partial-observation regime.
- [§4] §4 (Derivation of the Upper Bound): the proof sketch does not identify the key inequality or relaxation step that converts the worst-case target risk into a quantity computable from the partial observations alone. If this step relies on an additional distributional assumption not listed in the partial-observability model, the bound may be tighter than claimed or may require information that is not actually available.
minor comments (2)
- [§2] Notation for the observed and unobserved components of the selection mechanism should be introduced once in §2 and used consistently thereafter; current usage mixes P(S=1|X) and P(S=1) without clear distinction.
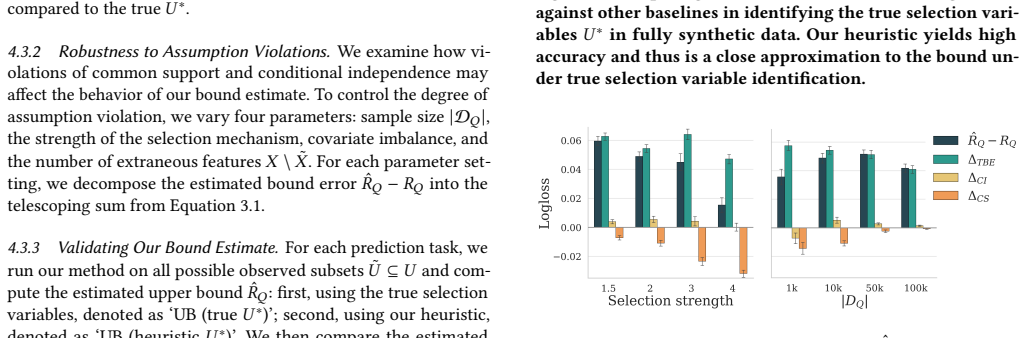
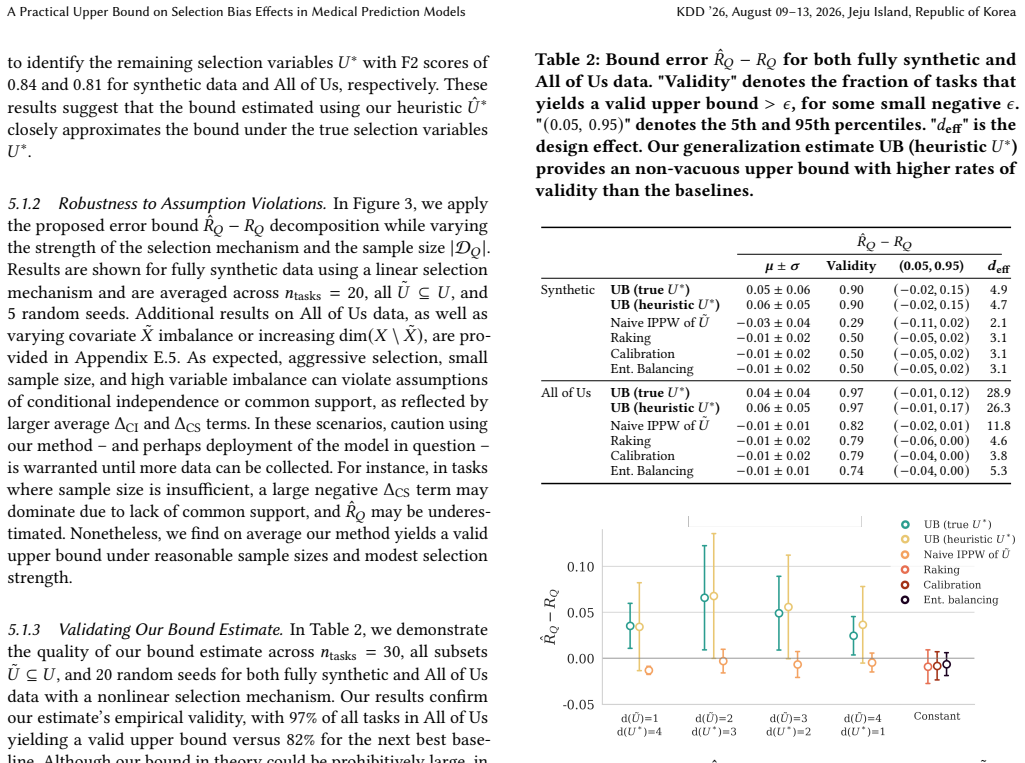
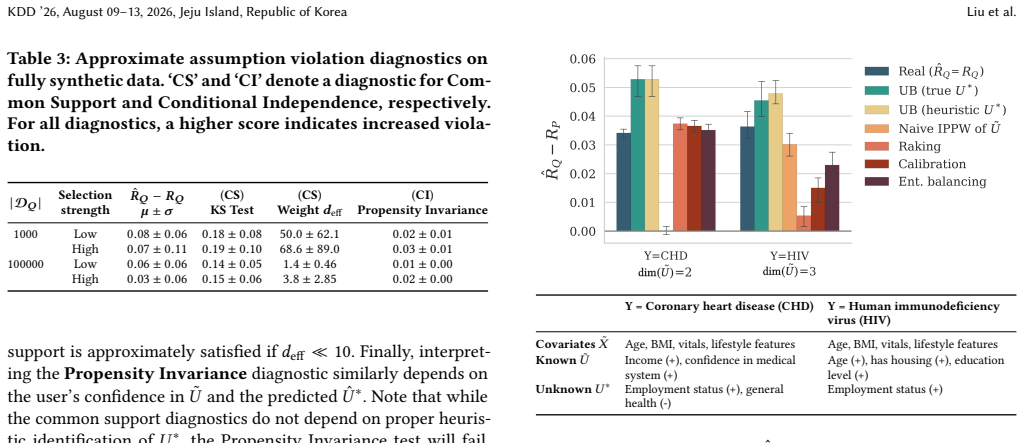
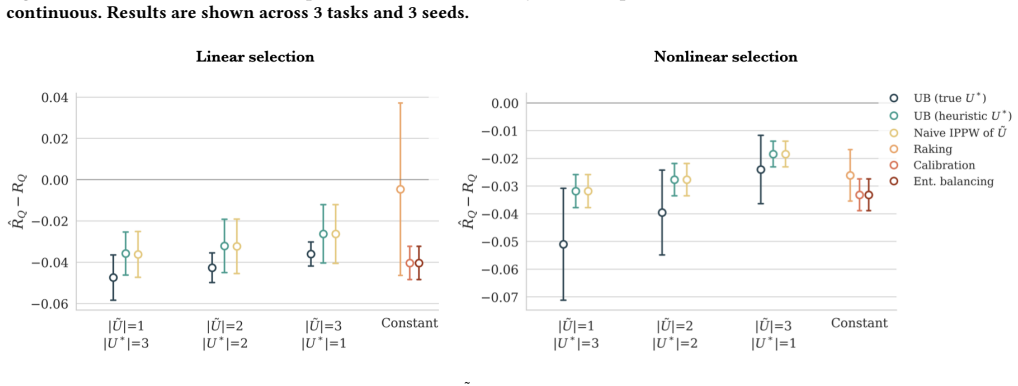
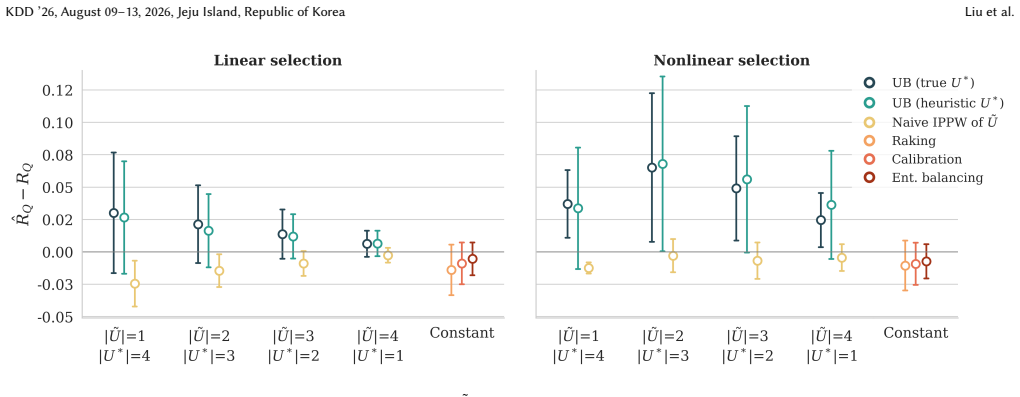
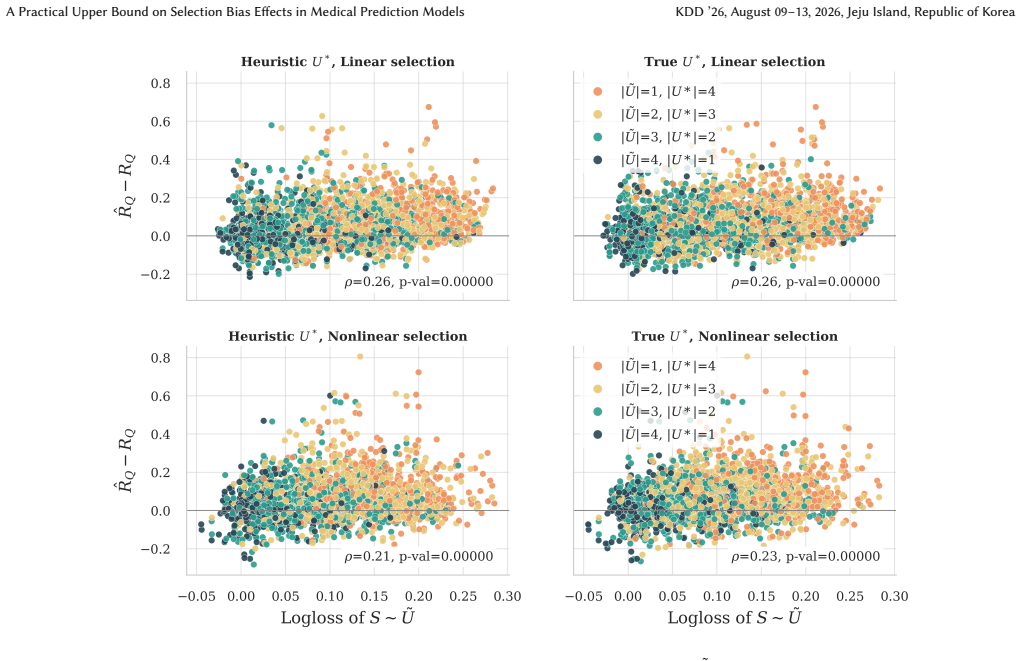
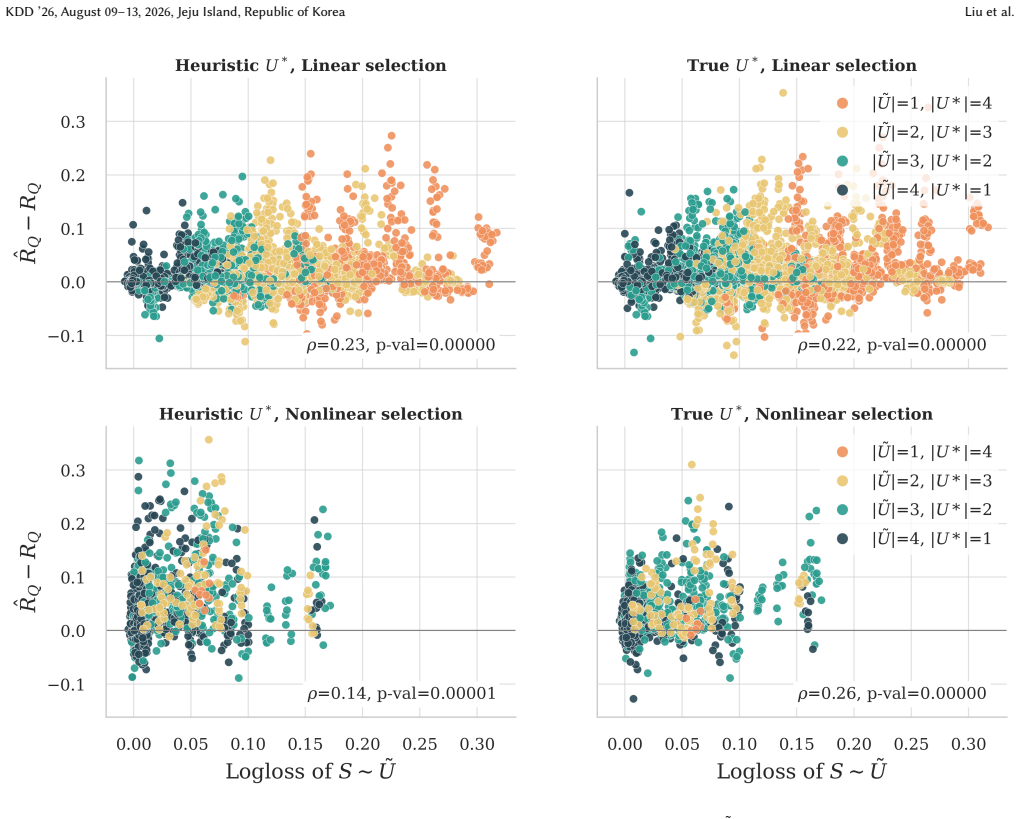
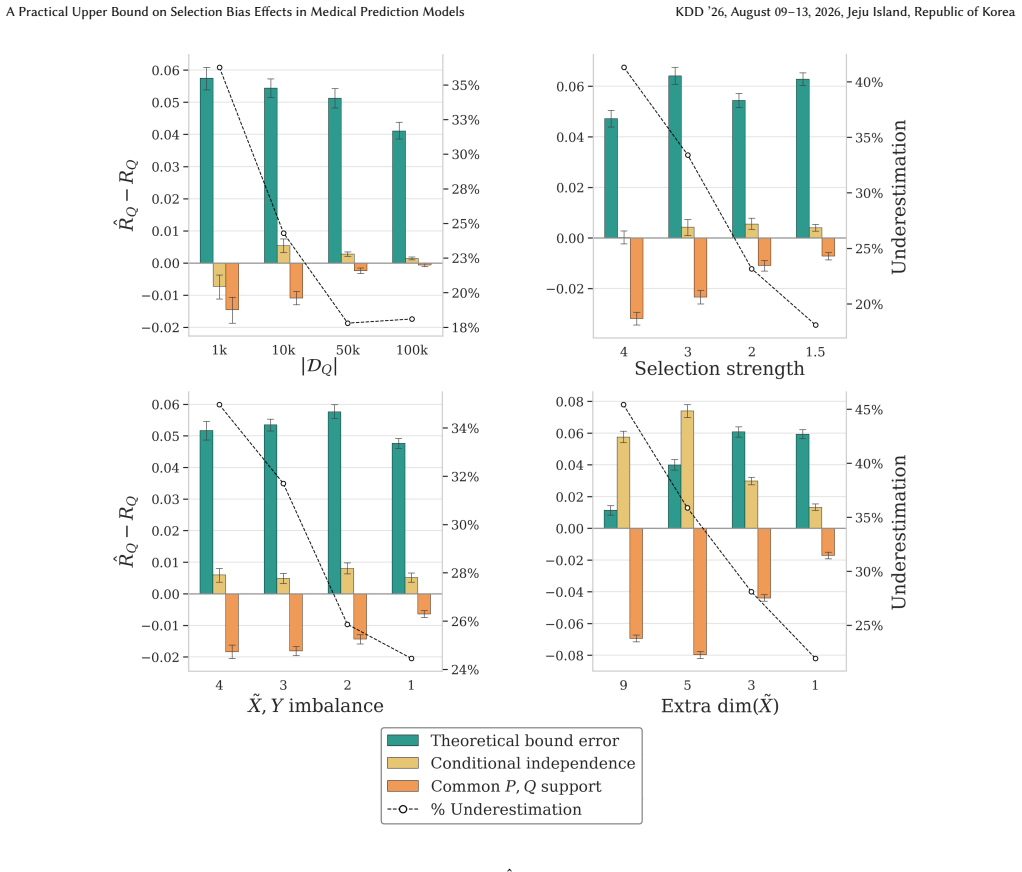
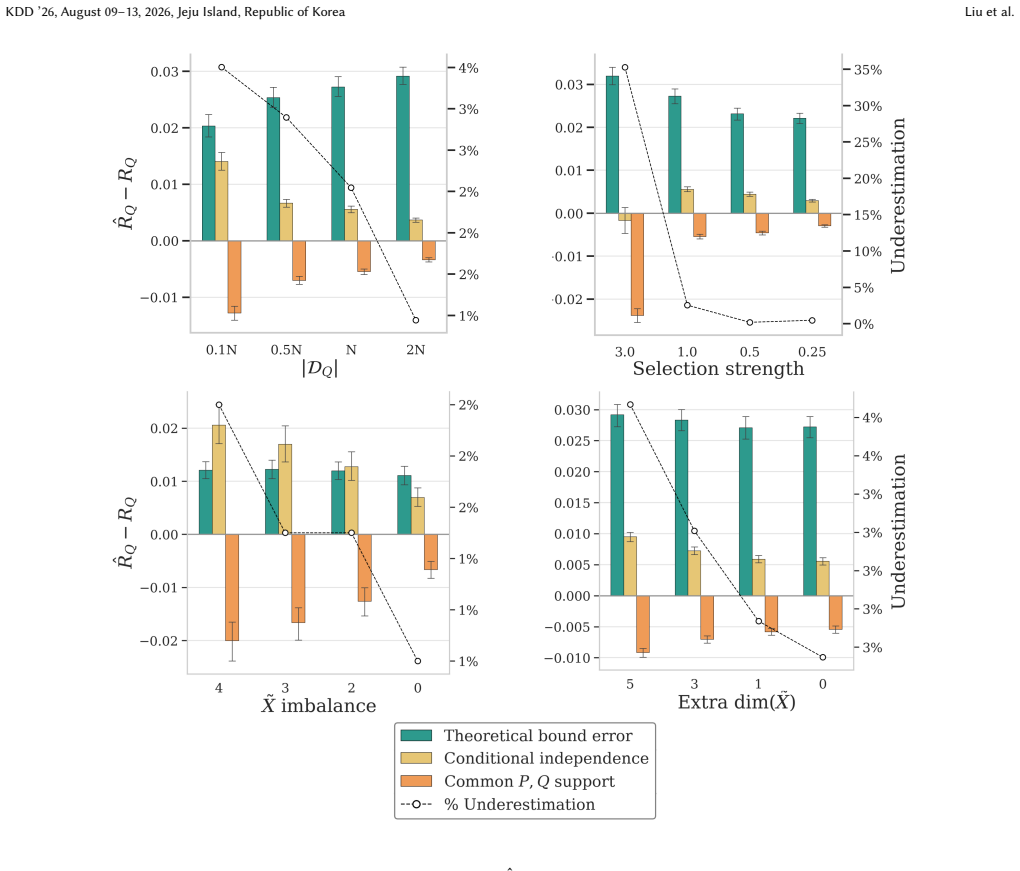
- [Figure 2] Figure 2 (synthetic experiments) lacks error bars or confidence intervals on the reported bound tightness; this makes it difficult to assess whether the bound is reliably above the true target risk across random seeds.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments below and have made revisions to improve the clarity of the partial observability model and the derivation of the upper bound.
read point-by-point responses
-
Referee: §3 (Partial Observability Model): the precise information assumed available about the selection mechanism is not stated explicitly. Without a formal definition of what is observed versus unobserved (e.g., which moments, which conditional distributions, or which parameters of the selection probability), it is impossible to verify that the bound remains non-trivial and does not implicitly require quantities that are unavailable under the stated partial-observation regime.
Authors: We agree that a more explicit formal definition is needed. In the revised manuscript, we have expanded Section 3 to include a formal definition of the partial observability model. Specifically, we define the observed quantities as the selection probabilities conditional on a subset of covariates, the distribution of the outcome in the observed sample, and the marginal covariate distribution in the target population. This ensures the bound is derived solely from these partial observations without requiring full knowledge of the selection mechanism or target data. revision: yes
-
Referee: §4 (Derivation of the Upper Bound): the proof sketch does not identify the key inequality or relaxation step that converts the worst-case target risk into a quantity computable from the partial observations alone. If this step relies on an additional distributional assumption not listed in the partial-observability model, the bound may be tighter than claimed or may require information that is not actually available.
Authors: Thank you for highlighting this. The original proof sketch was abbreviated. The key step is the use of a relaxation based on the observed selection rates to bound the difference between the selected and target distributions, followed by an application of the triangle inequality to separate the risk terms. We have revised Section 4 to provide a complete proof with each step labeled, confirming that no additional assumptions beyond the partial observability model are used. This revision ensures the bound is correctly derived from the available information. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and provided context describe a novel upper bound on worst-case model performance derived under partial observation of the selection mechanism and target population data. No equations, self-citations, or fitted parameters are referenced that would reduce the bound to its inputs by construction. Validation relies on experiments across synthetic, semi-synthetic, and real datasets (All of Us, MIMIC-IV), indicating the central claim has independent empirical content and is not forced by definition or prior self-referential results. This is the expected outcome for a paper whose derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
David Acuna, Guojun Zhang, Marc T Law, and Sanja Fidler. 2021. f-domain adversarial learning: Theory and algorithms. InInternational Conference on Machine Learning. PMLR, 66–75
2021
-
[2]
Amar Ahmad, Yvonne Vallès, and Youssef Idaghdour. 2025. Bias in AI systems: integrating formal and socio-technical approaches.Frontiers in Big Data8 (2025)
2025
-
[3]
Elias Bareinboim, Jin Tian, and Judea Pearl. 2014. Recovering from selection bias in causal and statistical inference. InProbabilistic and causal inference: The works of Judea Pearl. 433–450
2014
-
[4]
Shai Ben-David, John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman Vaughan. 2010. A theory of learning from different domains.Machine learning79, 1 (2010), 151–175
2010
-
[5]
Shai Ben-David, John Blitzer, Koby Crammer, and Fernando Pereira. 2006. Anal- ysis of representations for domain adaptation.Advances in neural information processing systems19 (2006)
2006
-
[6]
Aharon Ben-Tal, Dick Den Hertog, Anja De Waegenaere, Bertrand Melenberg, and Gijs Rennen. 2013. Robust solutions of optimization problems affected by uncertain probabilities.Management Science59, 2 (2013), 341–357
2013
-
[7]
Richard A Berk. 1983. An introduction to sample selection bias in sociological data.American sociological review(1983), 386–398
1983
-
[8]
Joseph Berkson. 1946. Limitations of the application of fourfold table analysis to hospital data.Biometrics Bulletin2, 3 (1946), 47–53
1946
-
[9]
Kirsten Bibbins-Domingo and Alex Helman. 2022. Improving representation in clinical trials and research.Washington DC: National Academies of Sciences, Engineering, and MedicinePolicy and Global Affairs(2022)
2022
-
[10]
Kirsten Bibbins-Domingo, Alex Helman, National Academies of Sciences Engi- neering, Medicine, et al. 2022. Why diverse representation in clinical research matters and the current state of representation within the clinical research ecosystem.Improving representation in clinical trials and research: Building research equity for women and underrepresented g...
2022
-
[11]
Carl Bonander, Anton Nilsson, Jonas Björk, Göran ML Bergström, and Ulf Strömberg. 2019. Participation weighting based on sociodemographic register data improved external validity in a population-based cohort study.Journal of clinical epidemiology108 (2019), 54–63
2019
-
[12]
Andrew D Boyd, Rosa Gonzalez-Guarda, Katharine Lawrence, Crystal L Patil, Miriam O Ezenwa, Emily C O’Brien, Hyung Paek, Jordan M Braciszewski, Oluwaseun Adeyemi, Allison M Cuthel, et al. 2023. Potential bias and lack of generalizability in electronic health record data: reflections on health equity from the National Institutes of Health Pragmatic Trials C...
2023
-
[13]
Valerie Bradley and Thomas E Nichols. 2022. Addressing selection bias in the UK Biobank neurological imaging cohort.MedRxiv(2022), 2022–01
2022
-
[14]
R.P. Brent. 1971. An algorithm with guaranteed convergence for finding a zero of a function.Comput. J.(1971)
1971
-
[15]
Golshid Chatrchi, Marie-Claude Duval, François Brisebois, and Steven Thomas
-
[16]
The impact of typical survey weighting adjustments on the design effect: A case study.Survey Methods: Insights from the Field(2015), 15
2015
-
[17]
Tianqi Chen and Carlos Guestrin. 2016. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 785–794
2016
-
[18]
Kristy Choi, Aditya Grover, Trisha Singh, Rui Shu, and Stefano Ermon. 2020. Fair generative modeling via weak supervision. InInternational Conference on Machine Learning. PMLR, 1887–1898
2020
-
[19]
Rumi Chunara, Jessica Gjonaj, Eileen Immaculate, Iris Wanga, James Alaro, Lori AJ Scott-Sheldon, Judith Mangeni, Ann Mwangi, Rajesh Vedanthan, and Joseph Hogan. 2024. Social determinants of health: the need for data science methods and capacity.The Lancet Digital Health6, 4 (2024), e235–e237
2024
-
[20]
Stephen R Cole and Miguel A Hernán. 2008. Constructing inverse probability weights for marginal structural models.American journal of epidemiology168, 6 (2008), 656–664
2008
-
[21]
Andrew Copas, Sarah Burkill, Fred Conrad, Mick P Couper, and Bob Erens
-
[22]
An evaluation of whether propensity score adjustment can remove the self-selection bias inherent to web panel surveys addressing sensitive health behaviours.BMC medical research methodology20, 1 (2020), 251
2020
-
[23]
Corinna Cortes, Yishay Mansour, and Mehryar Mohri. 2010. Learning bounds for importance weighting.Advances in neural information processing systems23 (2010)
2010
-
[24]
Nicolas Courty, Rémi Flamary, Devis Tuia, and Alain Rakotomamonjy. 2016. Optimal transport for domain adaptation.IEEE transactions on pattern analysis and machine intelligence39, 9 (2016), 1853–1865
2016
-
[25]
Antoine de Mathelin, Francois Deheeger, Mathilde Mougeot, and Nicolas Vayatis
-
[26]
In Joint European Conference on Machine Learning and Knowledge Discovery in Databases
Fast and accurate importance weighting for correcting sample bias. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 659–674
-
[27]
All of Us
Joshua C. Denny, Joni L Rutter, David B Goldstein, Anthony Philippakis, Jor- dan W Smoller, Gwynne Jenkins, and Eric Dishman. 2019. The “All of Us” research program.New England Journal of Medicine381, 7 (2019), 668–676
2019
-
[28]
Jean-Claude Deville and Carl-Erik Särndal. 1992. Calibration estimators in survey sampling.Journal of the American statistical Association87, 418 (1992), 376–382
1992
-
[29]
Peng Ding and Tyler J VanderWeele. 2016. Sensitivity analysis without assump- tions.Epidemiology27, 3 (2016), 368–377
2016
-
[30]
Jonas H Ellenberg. 1994. Selection bias in observational and experimental studies.Statistics in medicine13, 5-7 (1994), 557–567
1994
-
[31]
Michael R Elliott and Richard Valliant. 2017. Inference for nonprobability samples. (2017). KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Liu et al
2017
-
[32]
Jennifer Lalitha Flaubert, Suzanne Le Menestrel, David R Williams, and Mary K Wakefield. 2021. Social determinants of health and health equity. InThe Future of Nursing 2020-2030: Charting a path to achieve health equity. National Academies Press (US)
2021
-
[33]
Anna Fry, Thomas J Littlejohns, Cathie Sudlow, Nicola Doherty, Ligia Adamska, Tim Sprosen, Rory Collins, and Naomi E Allen. 2017. Comparison of sociode- mographic and health-related characteristics of UK Biobank participants with those of the general population.American journal of epidemiology186, 9 (2017), 1026–1034
2017
-
[34]
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. 2016. Domain-Adversarial Training of Neural Networks. arXiv:1505.07818 [stat.ML] https://arxiv.org/abs/1505.07818
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
Salvatore Giorgi, Veronica E Lynn, Keshav Gupta, Farhan Ahmed, Sandra Matz, Lyle H Ungar, and H Andrew Schwartz. 2022. Correcting sociodemographic selection biases for population prediction from social media. InProceedings of the International AAAI Conference on Web and Social Media, Vol. 16. 228–240
2022
-
[36]
Lea Goetz, Nabeel Seedat, Robert Vandersluis, and Mihaela van der Schaar. 2024. Generalization—a key challenge for responsible AI in patient-facing clinical applications.NPJ Digital Medicine7, 1 (2024), 126
2024
-
[37]
Goldberger, Luis A
Ary L. Goldberger, Luis A. N. Amaral, Leon Glass, Jeffrey M. Hausdorff, Pla- men Ch. Ivanov, Roger G. Mark, Joseph E. Mietus, George B. Moody, Chung- Kang Peng, and H. Eugene Stanley. 2000. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals.Circulation [Online]101, 23 (2000), e215–e220
2000
-
[38]
Benjamin A Goldstein, Nrupen A Bhavsar, Matthew Phelan, and Michael J Pencina. 2016. Controlling for informed presence bias due to the number of health encounters in an electronic health record.American journal of epidemiol- ogy184, 11 (2016), 847–855
2016
-
[39]
Chris Graham, Jenny King, Clare Lerway, and Alan J Poots. 2025. All the voices we cannot hear: a taxonomy of why some populations’ experiences are missing from health and care quality evidence and the Toolkit for Assessing Under Representation in User Surveys (TAURUS).BMJ open15, 2 (2025)
2025
-
[40]
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. 2012. A kernel two-sample test.The journal of machine learning research13, 1 (2012), 723–773
2012
-
[41]
Yufei Guo, Muzhe Guo, Juntao Su, Zhou Yang, Mengqiu Zhu, Hongfei Li, Mengyang Qiu, and Shuo Shuo Liu. 2024. Bias in large language models: Origin, evaluation, and mitigation.arXiv preprint arXiv:2411.10915(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Mehak Gupta, Brennan Gallamoza, Nicolas Cutrona, Pranjal Dhakal, Raphael Poulain, and Rahmatollah Beheshti. 2022. An Extensive Data Processing Pipeline for MIMIC-IV. InProceedings of the 2nd Machine Learning for Health symposium (Proceedings of Machine Learning Research, Vol. 193). PMLR, 311–325. https: //proceedings.mlr.press/v193/gupta22a.html
2022
-
[43]
Jens Hainmueller. 2012. Entropy balancing for causal effects: A multivariate reweighting method to produce balanced samples in observational studies. Political analysis20, 1 (2012), 25–46
2012
-
[44]
Larry Han. 2025. Addressing Distribution Shift for Robust and Trustworthy Prediction and Causal Inference in Clinical AI Settings.JAMA Network Open8, 6 (2025)
2025
-
[45]
Sebastien Haneuse. 2016. Distinguishing selection bias and confounding bias in comparative effectiveness research.Medical care54, 4 (2016), e23–e29
2016
-
[46]
James Heckman. 1990. Varieties of selection bias.The American Economic Review 80, 2 (1990), 313–318
1990
-
[47]
James J Heckman. 1979. Sample selection bias as a specification error.Econo- metrica: Journal of the econometric society(1979), 153–161
1979
-
[48]
James J Heckman, Hidehiko Ichimura, Jeffrey A Smith, and Petra E Todd. 1998. Characterizing selection bias using experimental data
1998
-
[49]
Miguel A Hernán, Sonia Hernández-Díaz, and James M Robins. 2004. A structural approach to selection bias.Epidemiology15, 5 (2004), 615–625
2004
-
[50]
Miguel A Hernán and James M Robins. 2020. Causal inference: What If
2020
-
[51]
Jiayuan Huang, Arthur Gretton, Karsten Borgwardt, Bernhard Schölkopf, and Alex Smola. 2006. Correcting sample selection bias by unlabeled data.Advances in neural information processing systems19 (2006)
2006
-
[52]
Yousif M Hydoub, Andrew P Walker, Robert W Kirchoff, Hossam M Alzu’bi, Patricia Y Chipi, Danielle J Gerberi, M Caroline Burton, M Hassan Murad, and Sagar B Dugani. 2023. Risk Prediction Models for Hospital Mortality in General Medical Patients: A Systematic Review.American journal of medicine open10 (2023), 100044
2023
-
[53]
Claire Infante-Rivard and Alexandre Cusson. 2018. Reflection on modern meth- ods: selection bias—a review of recent developments.International journal of epidemiology47, 5 (2018), 1714–1722
2018
-
[54]
Alistair Johnson, Luca Bulgarelli, Tom Pollard, Benjamin Gow, Benjamin Moody, Steven Horng, Leo Anthony Celi, and Roger Mark. 2024. MIMIC-IV (version 3.1). doi:10.13026/kpb9-mt58 RRID:SCR_007345
-
[55]
Alistair E. W. Johnson, Luca Bulgarelli, Li-wei Shen, and et al. 2023. MIMIC-IV, a freely accessible electronic health record dataset.Scientific Data10, 1 (2023). doi:10.1038/s41597-022-01899-x
-
[56]
Takafumi Kanamori, Shohei Hido, and Masashi Sugiyama. 2009. A least-squares approach to direct importance estimation.The Journal of Machine Learning Research10 (2009), 1391–1445
2009
-
[57]
Justin B Kaye, Lauren E Schultz, Heidi E Steiner, Rick A Kittles, Larisa H Cavallari, and Jason H Karnes. 2017. Warfarin pharmacogenomics in diverse populations. Pharmacotherapy: The Journal of Human Pharmacology and Drug Therapy37, 9 (2017), 1150–1163
2017
-
[58]
Jiyu Kim, Rebecca Anthopolos, and Judy Zhong. 2024. Bias correction models for electronic health records data in the presence of non-random sampling. Biometrics80, 1 (2024), ujae014
2024
- [59]
-
[60]
Leslie Kish. 1992. Weighting for unequal Pi.Journal of Official Statistics8, 2 (1992), 183
1992
-
[61]
Wouter M Kouw and Marco Loog. 2019. A review of domain adaptation without target labels.IEEE transactions on pattern analysis and machine intelligence43, 3 (2019), 766–785
2019
-
[62]
Ritoban Kundu, Xu Shi, Jean Morrison, Jessica Barrett, and Bhramar Mukherjee
-
[63]
A framework for understanding selection bias in real-world healthcare data.Journal of the Royal Statistical Society Series A: Statistics in Society187, 3 (2024), 606–635
2024
-
[64]
Catherine R Lesko, Ashley L Buchanan, Daniel Westreich, Jessie K Edwards, Michael G Hudgens, and Stephen R Cole. 2017. Generalizing study results: a potential outcomes perspective.Epidemiology28, 4 (2017), 553–561
2017
-
[65]
Jonathan Q Li and A Barron. 1999. Mixture Density Estimation.Neural Inf Process Syst(Nov. 1999), 279–285
1999
-
[66]
2019.Statistical analysis with missing data
Roderick JA Little and Donald B Rubin. 2019.Statistical analysis with missing data. John Wiley & Sons
2019
-
[67]
Song Liu, Makoto Yamada, Nigel Collier, and Masashi Sugiyama. 2013. Change- point detection in time-series data by relative density-ratio estimation.Neural Networks43 (2013), 72–83
2013
-
[68]
Haidong Lu, Stephen R Cole, Chanelle J Howe, and Daniel Westreich. 2022. Toward a clearer definition of selection bias when estimating causal effects. Epidemiology33, 5 (2022), 699–706
2022
-
[69]
Patrick G Lyons, Mackenzie R Hofford, Sean C Yu, Andrew P Michelson, Philip RO Payne, Catherine L Hough, and Karandeep Singh. 2023. Factors associated with variability in the performance of a proprietary sepsis prediction model across 9 networked hospitals in the US.JAMA internal medicine183, 6 (2023), 611–612
2023
-
[70]
Charles F Manski. 1989. Anatomy of the selection problem.Journal of Human resources(1989), 343–360
1989
-
[71]
2003.Partial identification of probability distributions
Charles F Manski. 2003.Partial identification of probability distributions. Springer
2003
-
[72]
Andreas Markoulidakis, Khadijeh Taiyari, Peter Holmans, Philip Pallmann, Monica Busse, Mark D Godley, and Beth Ann Griffin. 2023. A tutorial comparing different covariate balancing methods with an application evaluating the causal effects of substance use treatment programs for adolescents.Health Services and Outcomes Research Methodology23, 2 (2023), 115–148
2023
-
[73]
Louise AC Millard, Alba Fernández-Sanlés, Alice R Carter, Rachael A Hughes, Kate Tilling, Tim P Morris, Daniel Major-Smith, Gareth J Griffith, Gemma L Clayton, Emily Kawabata, et al. 2023. Exploring the impact of selection bias in observational studies of COVID-19: a simulation study.International Journal of Epidemiology52, 1 (2023), 44–57
2023
-
[74]
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mo- hamed, and Balaji Lakshminarayanan. 2021. Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research22, 57 (2021), 1–64
2021
-
[75]
Emanuel Parzen. 1962. On estimation of a probability density function and mode.The annals of mathematical statistics33, 3 (1962), 1065–1076
1962
-
[76]
Oriel Perets, Emanuela Stagno, Eyal Ben Yehuda, Megan McNichol, Leo Anthony Celi, Nadav Rappoport, and Matilda Dorotic. 2024. Inherent bias in electronic health records: a scoping review of sources of bias.ACM Transactions on Intelligent Systems and Technology(2024)
2024
-
[77]
Maya L Petersen, Kristin E Porter, Susan Gruber, Yue Wang, and Mark J Van Der Laan. 2012. Diagnosing and responding to violations in the positivity assumption.Statistical methods in medical research21, 1 (2012), 31–54
2012
-
[78]
James M Robins and Dianne M Finkelstein. 2000. Correcting for noncompliance and dependent censoring in an AIDS clinical trial with inverse probability of censoring weighted (IPCW) log-rank tests.Biometrics56, 3 (2000), 779–788
2000
-
[79]
Paul R Rosenbaum. 2005. Sensitivity analysis in observational studies.Encyclo- pedia of statistics in behavioral science4 (2005), 1809–1814
2005
-
[80]
Murray Rosenblatt. 1956. Remarks on some nonparametric estimates of a density function.Ann. Math. Stat.27, 3 (Sept. 1956), 832–837
1956
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.