FlowNar: Scalable Streaming Narration for Long-Form Videos
Pith reviewed 2026-06-28 19:07 UTC · model grok-4.3
The pith
FlowNar uses dynamic visual context removal and a CLAM module to keep memory and computation bounded for streaming narration of arbitrarily long videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
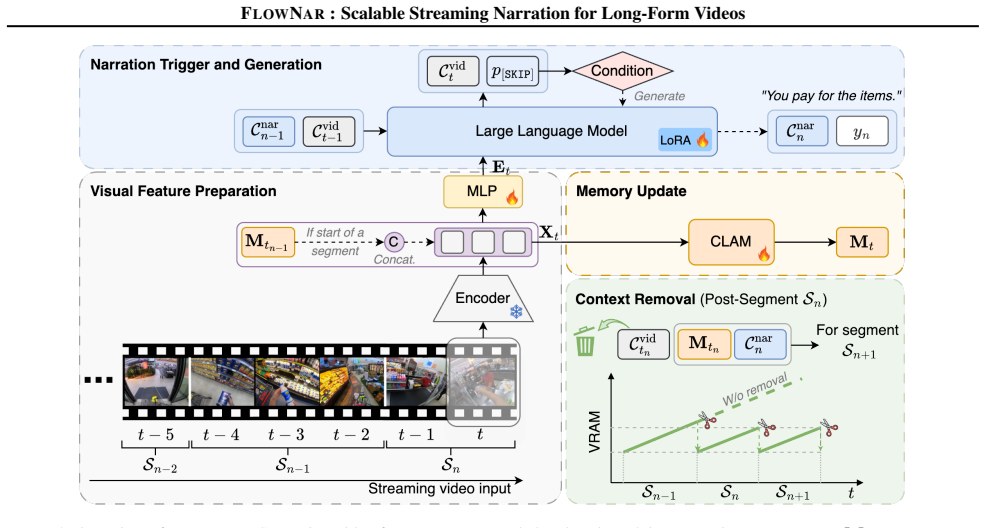
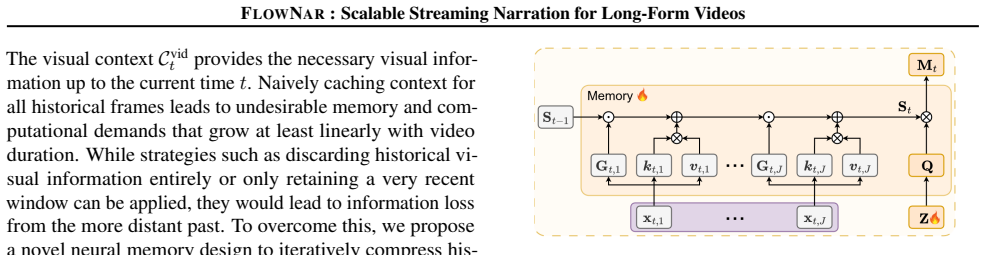
FlowNar achieves scalable streaming video narration through a dynamic context management strategy that removes historical visual context and a CLAM module for retaining streaming visual history, resulting in bounded visual memory usage and computational complexity.
What carries the argument
dynamic context management strategy for historical visual context removal combined with the CLAM (Cross Linear Attentive Memory) module for streaming visual history retention
If this is right
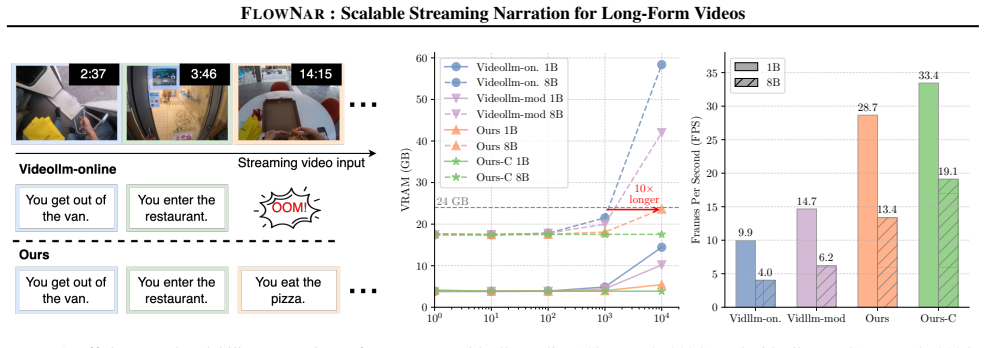
- Supports processing videos up to 10 times longer than previous methods without proportional resource increase.
- Achieves 3 times higher throughput measured in frames per second.
- Maintains or improves narration quality on Ego4D, EgoExo4D, and EpicKitchens100 datasets compared to baselines.
- Keeps visual memory usage and computational complexity bounded independent of video duration.
Where Pith is reading between the lines
- Applications such as live sports commentary or assistive devices for the blind could run continuously on limited hardware.
- The approach might extend to other streaming multimodal tasks like real-time captioning or question answering.
- Validation against human judgments in live settings would be needed to confirm the evaluation protocol's realism.
Load-bearing premise
Selective removal of historical visual context can be done without losing information essential for correct ongoing narration, and the self-conditioned evaluation protocol reflects real-world deployment conditions.
What would settle it
An experiment showing that for some videos, the narration accuracy drops significantly when key past frames are removed by the dynamic management, or when the self-conditioned protocol scores differ markedly from actual online user feedback.
Figures





read the original abstract
Recent Large Multimodal Models (LMMs), primarily designed for offline settings, are ill-suited for the dynamic requirements of streaming video. While recent online adaptations improve real-time processing, they still face critical scalability challenges, with resource demands typically growing at least linearly with video duration. To overcome this bottleneck, we propose FlowNar, a novel framework for scalable streaming video narration. The core of FlowNar is a dynamic context management strategy for historical visual context removal, combined with our CLAM (Cross Linear Attentive Memory) module for streaming visual history retention, ensuring bounded visual memory usage and computational complexity, crucial for efficient streaming. We also introduce a realistic self-conditioned evaluation protocol and complementary evaluation metrics to assess streaming narration models under deployment-like conditions. Experiments on the Ego4D, EgoExo4D, and EpicKitchens100 datasets demonstrate that FlowNar substantially improves narration quality over strong baselines while being highly efficient, supporting processing of 10$\times$ longer videos and achieving 3$\times$ higher throughput (FPS). The code is available at https://github.com/zeyun-zhong/FlowNar.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FlowNar, a framework for scalable streaming video narration in LMMs. Its core consists of a dynamic context management strategy for historical visual context removal combined with the CLAM (Cross Linear Attentive Memory) module to enforce bounded visual memory usage and computational complexity. The authors also introduce a self-conditioned evaluation protocol and metrics, and report improved narration quality on Ego4D, EgoExo4D, and EpicKitchens100 while supporting 10× longer videos and 3× higher throughput (FPS). Code is released at the provided GitHub link.
Significance. If the bounded-complexity claim holds under the self-conditioned protocol, the work would address a key scalability barrier for streaming long-form video narration. The release of code and the new evaluation protocol are concrete strengths that facilitate reproducibility and future comparisons.
major comments (2)
- [§3.2] §3.2 (Dynamic Context Management): the description of the removal trigger and relevance scoring mechanism is insufficient to verify that long-range dependencies (e.g., delayed references common in Ego4D and EpicKitchens) are preserved; this directly underpins the central bounded-memory claim.
- [§4] §4 (Experiments): no ablation isolates the contribution of the dynamic removal policy versus CLAM retention, nor tests failure modes on long-horizon dependencies; without these, the reported gains on the three datasets do not yet substantiate that selective pruning maintains narration accuracy.
minor comments (2)
- [§1] The abstract and §1 use “bounded visual memory usage” without an explicit complexity bound (e.g., O(1) or O(log T)); a formal statement would strengthen the claim.
- [§3.3] Figure 2 caption and §3.3 notation for CLAM cross-attention could be clarified to distinguish streaming vs. offline modes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the exposition of the dynamic context management and to provide more targeted experimental evidence. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Dynamic Context Management): the description of the removal trigger and relevance scoring mechanism is insufficient to verify that long-range dependencies (e.g., delayed references common in Ego4D and EpicKitchens) are preserved; this directly underpins the central bounded-memory claim.
Authors: We agree that the current description of the removal trigger and relevance scoring in §3.2 would benefit from greater detail to allow independent verification of long-range dependency preservation. In the revision we will expand this section with explicit mathematical definitions of the trigger condition and scoring function, pseudocode for the removal procedure, and a short discussion with examples drawn from Ego4D and EpicKitchens100 showing how delayed references are retained via the CLAM module. revision: yes
-
Referee: [§4] §4 (Experiments): no ablation isolates the contribution of the dynamic removal policy versus CLAM retention, nor tests failure modes on long-horizon dependencies; without these, the reported gains on the three datasets do not yet substantiate that selective pruning maintains narration accuracy.
Authors: While the reported results demonstrate that the full FlowNar system improves quality and efficiency over strong baselines, we acknowledge that the experiments do not yet isolate the dynamic removal policy from CLAM retention or explicitly examine long-horizon failure modes. We will add an ablation study in the revised §4 that compares the complete model against a variant that disables dynamic removal (retaining all history up to the memory bound) and will include a targeted analysis of narration accuracy on video segments containing delayed references. revision: yes
Circularity Check
No circularity: new framework and protocol presented as independent contributions
full rationale
The paper's core claims rest on a proposed dynamic context management strategy plus CLAM module for bounded memory in streaming narration, plus a new self-conditioned evaluation protocol. These are introduced as novel elements without any equations or steps that reduce by construction to fitted inputs, self-citations for uniqueness theorems, or renamed known results. The abstract and described contributions contain no self-definitional loops, fitted-input predictions, or load-bearing self-citations; performance claims on Ego4D/EpicKitchens are presented as empirical outcomes rather than tautological. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Onestory: Co- herent multi-shot video generation with adaptive memory
An, Z., Jia, M., Qiu, H., Zhou, Z., Huang, X., Liu, Z., Ren, W., Kahatapitiya, K., Liu, D., He, S., et al. Onestory: Co- herent multi-shot video generation with adaptive memory. arXiv preprint arXiv:2512.07802,
-
[2]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Longformer: The Long-Document Transformer
Beltagy, I., Peters, M. E., and Cohan, A. Long- former: The long-document transformer.arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[4]
C., Hampali, S., Sauser, E., Ma, S., et al
Chatterjee, D., Remelli, E., Song, Y ., Tekin, B., Mittal, A., Bhatnagar, B., Camg¨oz, N. C., Hampali, S., Sauser, E., Ma, S., et al. Memory-efficient streaming videollms for real-time procedural video understanding.arXiv preprint arXiv:2504.13915,
-
[5]
A simple and effective l 2 norm-based strategy for kv cache compression
Devoto, A., Zhao, Y ., Scardapane, S., and Minervini, P. A simple and effective l 2 norm-based strategy for kv cache compression. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 18476–18499,
2024
-
[6]
Streaming video question- answering with in-context video kv-cache retrieval
Di, S., Yu, Z., Zhang, G., Li, H., Cheng, H., Li, B., He, W., Shu, F., and Jiang, H. Streaming video question- answering with in-context video kv-cache retrieval. In International Conference on Learning Representations, volume 2025, pp. 42115–42127,
2025
-
[7]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A. and Dao, T. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Lm-infinite: Zero-shot extreme length generalization for large language models
Han, C., Wang, Q., Peng, H., Xiong, W., Chen, Y ., Ji, H., and Wang, S. Lm-infinite: Zero-shot extreme length generalization for large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 3991–4008,
2024
-
[9]
URL https: //arxiv.org/abs/2310.06825. Katharopoulos, A., Vyas, A., Pappas, N., and Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational conference on ma- chine learning, pp. 5156–5165. PMLR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Videochat: Chat-centric video understanding.Science China Information Sciences, 68 (10):200102, 2025a
Li, K., He, Y ., Wang, Y ., Li, Y ., Wang, W., Luo, P., Wang, Y ., Wang, L., and Qiao, Y . Videochat: Chat-centric video understanding.Science China Information Sciences, 68 (10):200102, 2025a. Li, W., Hu, B., Shao, R., Shen, L., and Nie, L. Lion- fs: Fast & slow video-language thinker as online video assistant. InProceedings of the IEEE/CVF Conference on...
2024
- [11]
-
[12]
11 FLOWNAR: Scalable Streaming Narration for Long-Form Videos Qiu, H., Liu, S., Zhou, Z., An, Z., Ren, W., Liu, Z., Schult, J., He, S., Chen, S., Cong, Y ., et al. Histream: Efficient high- resolution video generation via redundancy-eliminated streaming.arXiv preprint arXiv:2512.21338,
-
[13]
S., Piergiovanni, A., Arnab, A., Dehghani, M., and Angelova, A
Ryoo, M. S., Piergiovanni, A., Arnab, A., Dehghani, M., and Angelova, A. Tokenlearner: What can 8 learned tokens do for images and videos?arXiv preprint arXiv:2106.11297,
-
[14]
Shi, L., Zhang, H., Yao, Y ., Li, Z., and Zhao, H. Keep the cost down: A review on methods to optimize llm’s kv-cache consumption.arXiv preprint arXiv:2407.18003,
-
[15]
Retentive Network: A Successor to Transformer for Large Language Models
Sun, Y ., Dong, L., Huang, S., Ma, S., Xia, Y ., Xue, J., Wang, J., and Wei, F. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Razorattention: Efficient kv cache compression through retrieval heads
Tang, H., Lin, Y ., Lin, J., Han, Q., Ke, D., Hong, S., Yao, Y ., and Wang, G. Razorattention: Efficient kv cache compression through retrieval heads. InInternational Conference on Learning Representations, volume 2025, pp. 16632–16646,
2025
-
[17]
Effi- cient streaming language models with attention sinks
Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Effi- cient streaming language models with attention sinks. In International Conference on Learning Representations, volume 2024, pp. 21875–21895,
2024
-
[18]
arXiv preprint arXiv:2508.15717 (2025) 5
Yang, Y ., Zhao, Z., Shukla, S. N., Singh, A., Mishra, S. K., Zhang, L., and Ren, M. Streammem: Query-agnostic kv cache memory for streaming video understanding.arXiv preprint arXiv:2508.15717,
-
[19]
Video-llama: An instruction- tuned audio-visual language model for video understand- ing
Zhang, H., Li, X., and Bing, L. Video-llama: An instruction- tuned audio-visual language model for video understand- ing. InProceedings of the 2023 conference on empirical methods in natural language processing: system demon- strations, pp. 543–553, 2023a. Zhang, Z., Sheng, Y ., Zhou, T., Chen, T., Zheng, L., Cai, R., Song, Z., Tian, Y ., R´e, C., Barrett...
2023
-
[20]
Understanding transformer from the perspective of associative memory
Zhong, S., Xu, M., Ao, T., and Shi, G. Understanding transformer from the perspective of associative memory. arXiv preprint arXiv:2505.19488,
-
[21]
A Survey on Deep Learning Techniques for Action Anticipation
Zhong, Z., Martin, M., V oit, M., Gall, J., and Beyerer, J. A survey on deep learning techniques for action anticipation. arXiv preprint arXiv:2309.17257,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Minigpt- 4: Enhancing vision-language understanding with ad- vanced large language models
Zhu, D., Shen, X., Li, X., Elhoseiny, M., et al. Minigpt- 4: Enhancing vision-language understanding with ad- vanced large language models. InInternational Con- ference on Learning Representations, volume 2024, pp. 18378–18394,
2024
-
[23]
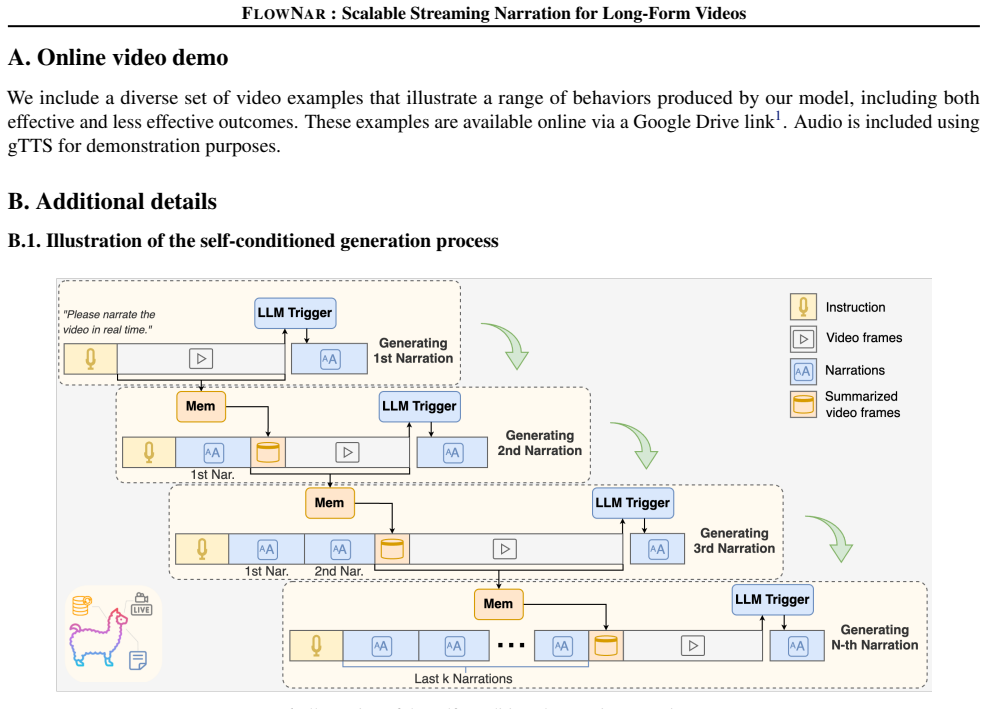
introduces learnable parameters (MLPs) and benefits from end-to-end training, but it still effectively accumulates information from every incoming frame. When long, 1https://drive.google.com/drive/folders/18i6es_n1RwI4yHJ_6yxvt0MJuEdEa4DO 14 FLOWNAR: Scalable Streaming Narration for Long-Form Videos redundant segments dominate, the memory can become biase...
2023
-
[24]
Dataset statistics Table 8.Dataset statistics
B.4. Dataset statistics Table 8.Dataset statistics. Dataset # Train # Val Video len. [s] # Segments Seg. dur. # Nar. tokens Ego4D 102.986 17.059 237.7 (±92.0) 53 4.5s 12 EgoExo4D 3.219 826 151.4 (±232.7) 58 2.6s 17 EpicKitchens100 495 138 493.9 (±621.3) 112 4.4s 10 15 FLOWNAR: Scalable Streaming Narration for Long-Form Videos Algorithm 2Self-conditioned s...
2022
-
[25]
Figure 8 further illustrates the most frequent terms found in the narrations for each dataset. B.5. Protocols and metrics Prior streaming narration evaluations (e.g., Videollm-online, Videollm-mod, LION-FS) report quantitative results using ground-truth–conditioned interleaved token sequences constructed from labels (for example [vvnnvv...], where v = fra...
2019
-
[26]
and METEOR (Denkowski & Lavie, 2014)) and structural/semantic metrics such as ROUGE L (Lin,
2014
-
[27]
Each frame is represented by J=10 tokens (1 CLS + 9 spatially averaged 3×3 patch tokens)
as the visual encoder, processing frames at 2 FPS. Each frame is represented by J=10 tokens (1 CLS + 9 spatially averaged 3×3 patch tokens). A 2-layer MLP projects these visual features from dimension D= 1024 to the LLM’s hidden dimensionDlm = 2048/4096. For the language model, we employ Meta-Llama-3-1B/8B-Instruct (Meta, 2024), adapting all its linear la...
2048
-
[28]
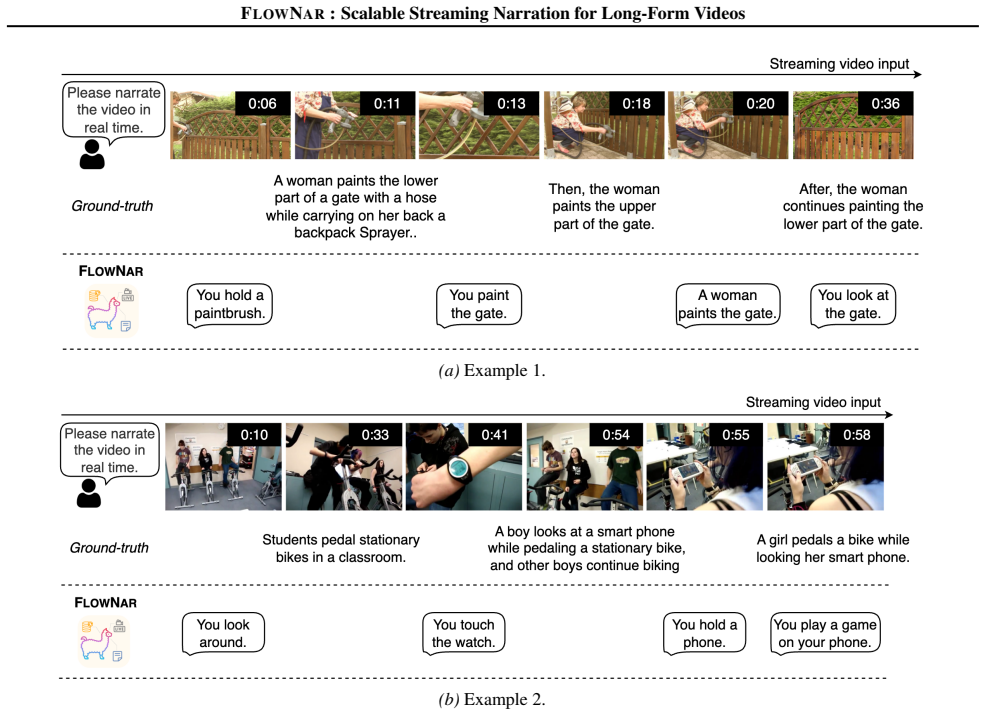
You touch the watch
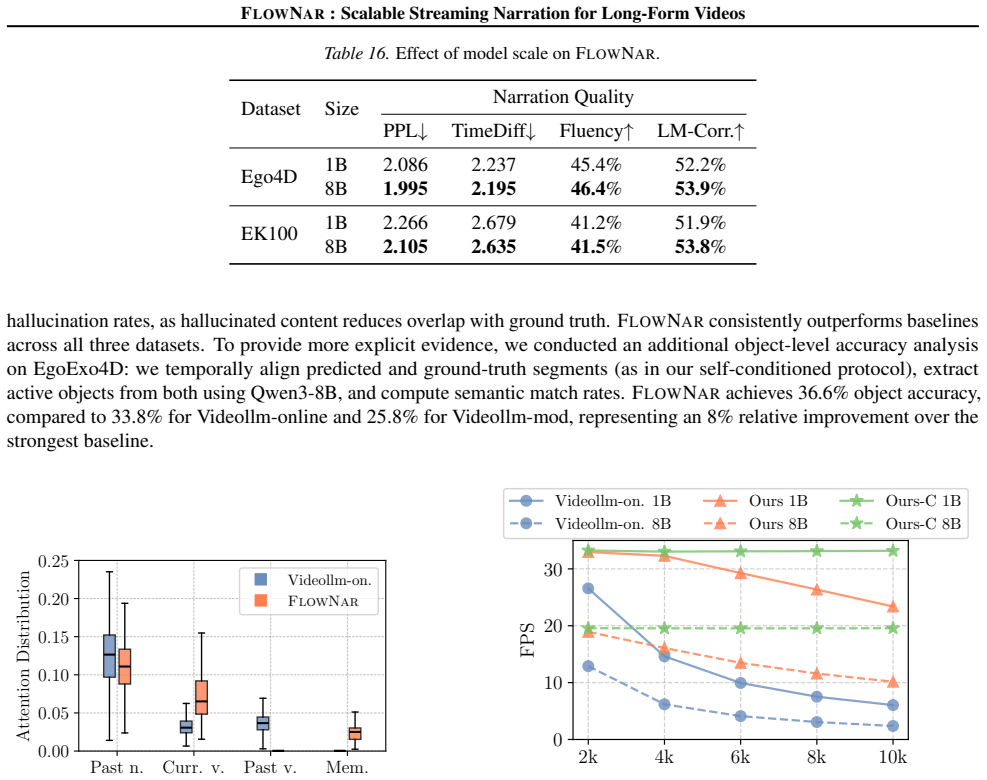
for both 1B and 8B language model sizes. The baseline shows a significant drop in FPS as more frames are processed, particularly for the 8B model, due to extensively accumulated context. By employing our dynamic context management strategy to remove historical visual context, FLOWNARmaintains a relatively stable FPS even after 10,000 frames ( 10 FPS for 8...
2023
-
[29]
pick up the knife
We observe that the model may hallucinate interactions with objects that are visible in the scene or semantically congruent with the environment (e.g., predicting “pick up the knife”) even when they are not being actively manipulated. We attribute this to the aggressive spatial compression (1 CLS +3×3 pooled tokens per frame) required to maintain real-tim...
2015
-
[30]
However, these approaches typically operate in a clip-based manner and explicitly rely on subtitles or dialogue gaps to determine narration timing
has advanced the field of Movie Audio Description. However, these approaches typically operate in a clip-based manner and explicitly rely on subtitles or dialogue gaps to determine narration timing. Consequently, the majority of these methods operate offline, requiring access to the entire video, and often struggle to scale to long, unsegmented real-world...
2024
-
[31]
We extend Chen et al
was recently proposed, focusing on generating timely, timestamped descriptions continuously for incoming video segments in an online manner. We extend Chen et al. (2024) by supporting much longer videos and introducing a deployment-like self-conditioned evaluation and metrics. LMMs for online video understanding.Large multimodal models (LMMs) (Alayrac et ...
2024
-
[32]
have significantly advanced multimodal comprehension. Current LMMs address various video understanding benchmarks, including action recognition (Zhao et al., 2023; Qi et al., 2025), temporal action localization (Liu et al., 2024), and video dialogue/question answering (Li et al., 2025a; Song et al., 2024; Maaz et al., 2024; Zhang et al., 2023a; Lin et al....
2023
-
[33]
enforce bounded memory through attention-based KV pruning and event-level tree merging, respectively. Unlike these methods, which produce output only when an external query arrives, FLOWNARmust jointly decidewhenandwhatto narrate over a continuous stream without any prompting, requiring tight coupling between temporal localization and generation under bou...
2025
-
[34]
offers simplicity by retaining only the KV pairs for a fixed window of recent tokens. More sophisticated cache eviction techniques aim to selectively discard less relevant KV pairs based on attention scores (Xiao et al., 2024; Han et al., 2024; Liu et al., 2023b; Zhang et al., 2023b; Adnan et al., 2024), or sparsification (Tang et al., 2025; Yao et al., 2...
2024
-
[35]
(2024) use online K-Means clustering for frame features
merges similar visual tokens, while Zhou et al. (2024) use online K-Means clustering for frame features. Different from these methods targeting textual caches or using alternative visual compression strategies, we introduce a neural memory mechanism specifically designed to efficiently manage and compress long-term visual context for streaming video analy...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.