Scaling Behavior of Single LLM-Driven Multi-Agent Systems
Pith reviewed 2026-06-28 18:09 UTC · model grok-4.3
The pith
Multi-agent LLM systems show diminishing returns as agent count rises due to coordination overhead outweighing synergy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
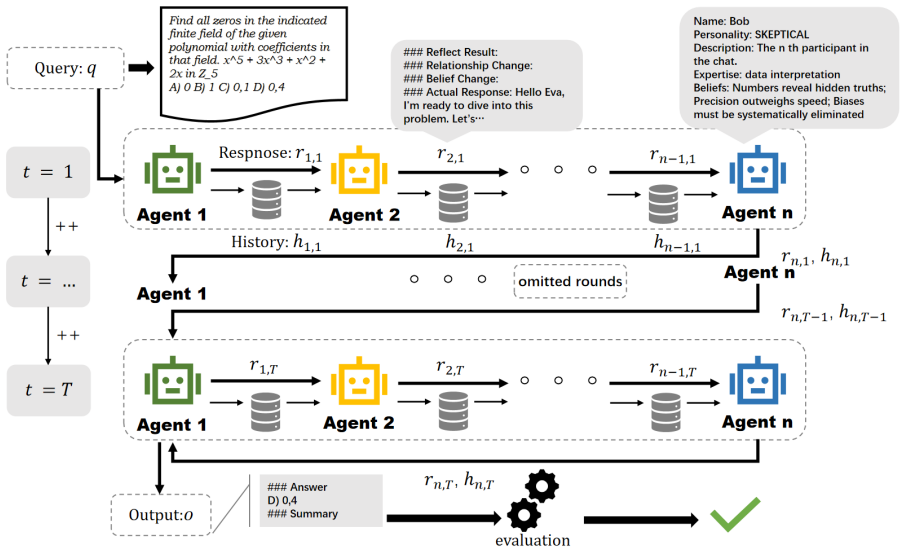
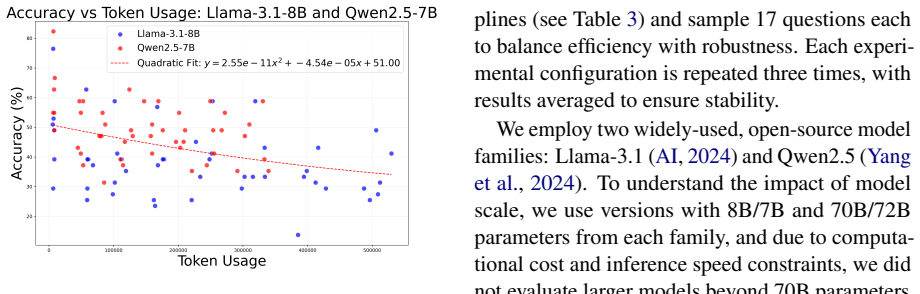
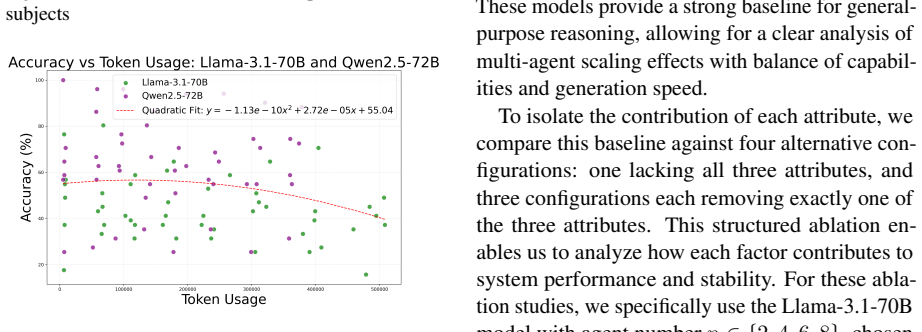
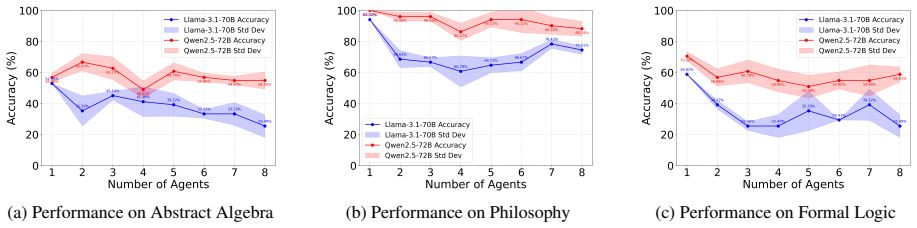
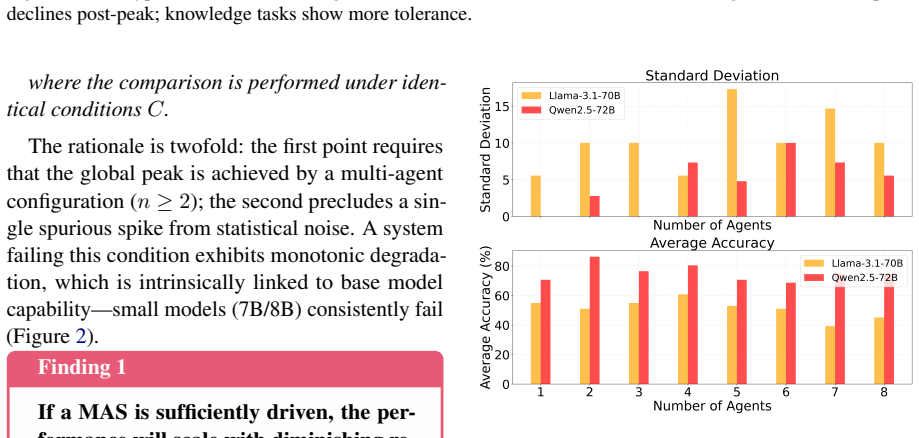
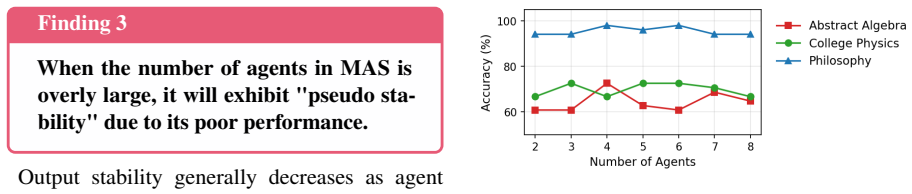
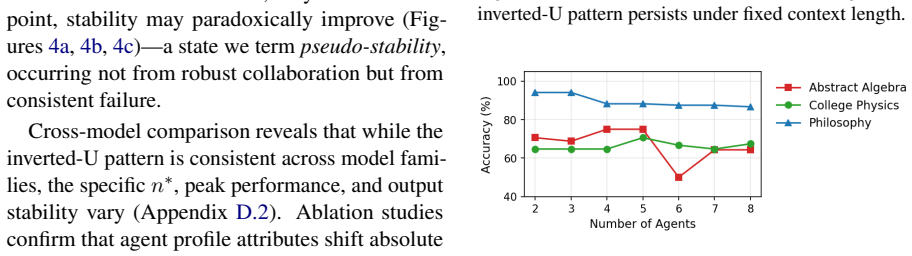
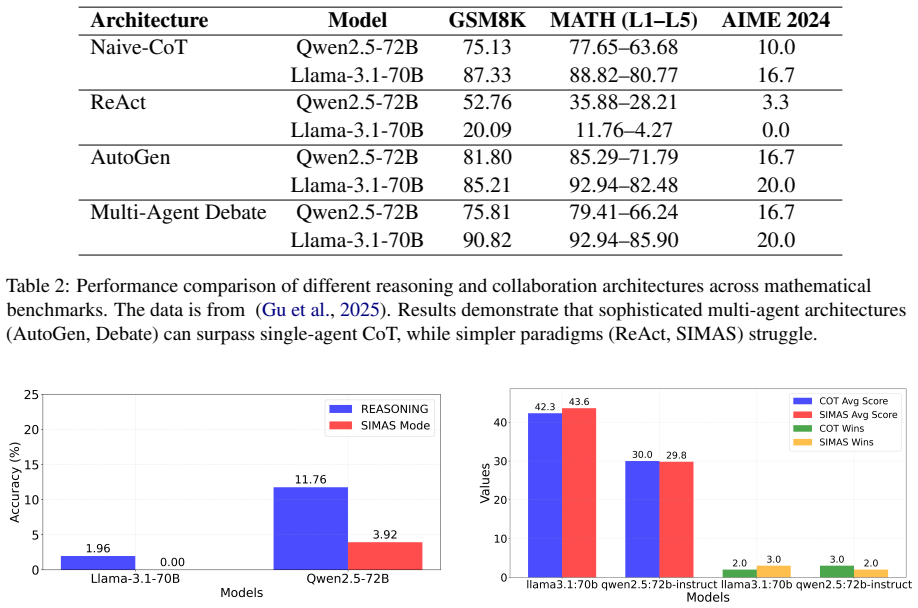
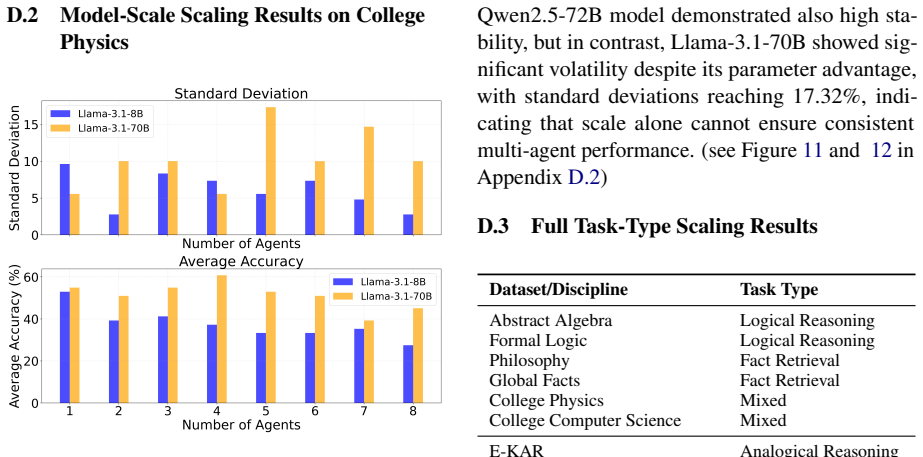
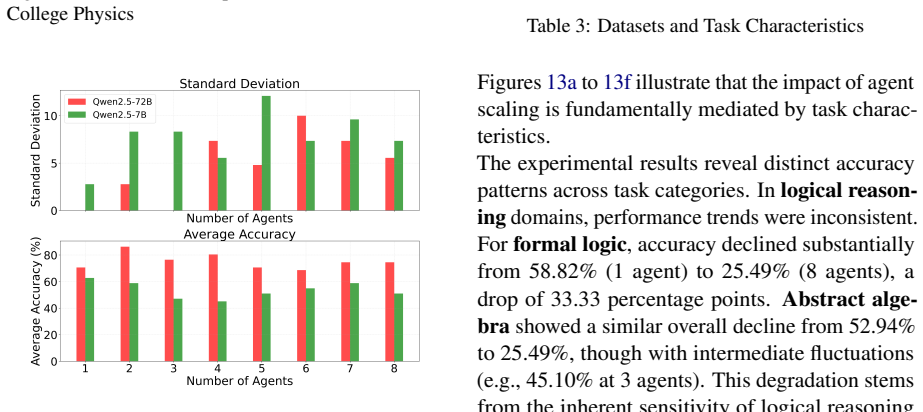
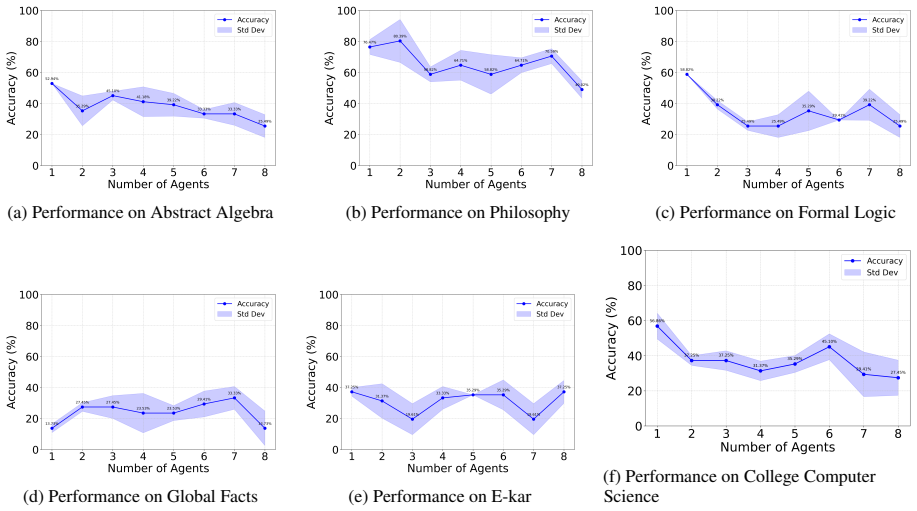
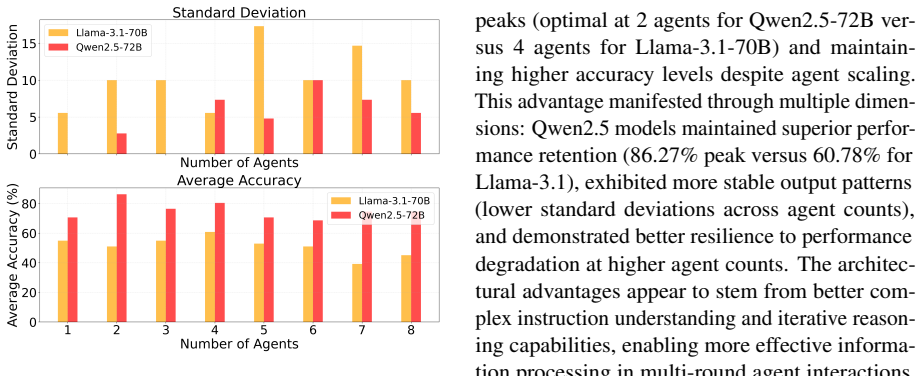
Using the Sequential Iterative Multi-Agent System framework across diverse tasks and model scales, the performance of a homogeneous multi-agent system does not increase monotonically with the number of agents. Performance instead follows diminishing returns shaped by the tension between collaborative synergy and coordination overhead. Collective intelligence appears only when interaction is designed strategically and the base LLM is sufficiently capable; degradation traces to coordination costs rather than context-length limits, and the pattern holds across other interaction structures such as structured debate topologies.
What carries the argument
The Sequential Iterative Multi-Agent System (SIMAS) framework, a minimalist sequential inter-agent communication architecture that isolates scaling effects from model or knowledge differences.
Load-bearing premise
The SIMAS framework and chosen tasks isolate collaboration effects from differences in the underlying models or agent knowledge.
What would settle it
An experiment that increases agent count inside the same SIMAS setup and observes steady performance gains without coordination slowdown or plateau.
Figures






read the original abstract
The burgeoning field of LLM-based Multi-Agent Systems (MAS) promises to tackle complex tasks through collaborative intelligence, yet fundamental questions regarding their scaling behavior and intrinsic collective dynamics remain underexplored. This paper systematically investigates how the performance of a homogeneous MAS evolves as the number of agents increases, isolating the variable of collaboration from model or knowledge heterogeneity. We propose the Sequential Iterative Multi-Agent System (SIMAS) framework, a minimalist architecture centered on sequential inter-agent communication, to clearly observe scaling effects. Through extensive experiments across diverse tasks and model scales, we establish that MAS performance does not scale monotonically with agent count but follows a pattern of diminishing returns, governed by a trade-off between collaborative synergy and coordination overhead. Our findings reveal that effective MAS requires a sufficiently capable base LLM, that task type critically modulates the optimal agent count, and that collective intelligence is an emergent property contingent on strategic interaction design rather than a guaranteed outcome of agent plurality. The performance degradation stems coordination overhead rather than merely long-context failure, and the scaling tendency generalizes across interaction architectures like structured debate topologies. This work provides a foundational understanding of MAS scaling laws, offering practical guidance for designing efficient collaborative systems and challenging the prevailing assumption that more agents invariably lead to better performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that homogeneous LLM-based multi-agent systems using the proposed Sequential Iterative Multi-Agent System (SIMAS) framework exhibit non-monotonic scaling: performance improves initially with added agents due to collaborative synergy but then diminishes due to coordination overhead. This is supported by experiments across diverse tasks and model scales showing that effective MAS requires a capable base LLM, that task type modulates optimal agent count, and that collective intelligence is an emergent property of interaction design rather than agent count alone. The degradation is attributed specifically to coordination overhead (not long-context failure), with the pattern generalizing to other interaction architectures like structured debate.
Significance. If the isolation of collaboration effects is robustly demonstrated, the work supplies useful empirical evidence against the common assumption that more agents always yield better MAS performance. It offers concrete guidance on scaling limits and interaction design, backed by experiments spanning multiple tasks and model scales plus generalization checks across architectures. These elements would constitute a solid foundational contribution to understanding collective dynamics in LLM-driven systems.
major comments (1)
- [§3 (SIMAS Framework) and §4 (Experiments)] §3 (SIMAS Framework) and §4 (Experiments): The claim that SIMAS isolates collaboration effects from model/knowledge heterogeneity via homogeneous agents and sequential communication is load-bearing for attributing diminishing returns to a synergy-overhead trade-off. Sequential iteration inherently accumulates interaction history in the shared context, which can create effective differences in information access or conditioning as agent count grows. Without explicit controls (e.g., fixed-context ablations or per-agent capability measurements across scales) confirming constant effective capability, the attribution to coordination overhead rather than context drift or prompt drift is not fully verified.
minor comments (2)
- [Abstract and §1] Abstract and §1: The statement that 'the performance degradation stems coordination overhead rather than merely long-context failure' would benefit from a brief forward reference to the specific control experiment or metric used to distinguish the two.
- [Figure captions and §4] Figure captions and §4: Ensure all scaling plots include error bars or confidence intervals and state the number of runs per data point to allow assessment of variability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The major comment raises an important point about potential confounds in our isolation of collaboration effects. We address it directly below and commit to revisions that strengthen the attribution.
read point-by-point responses
-
Referee: [§3 (SIMAS Framework) and §4 (Experiments)] §3 (SIMAS Framework) and §4 (Experiments): The claim that SIMAS isolates collaboration effects from model/knowledge heterogeneity via homogeneous agents and sequential communication is load-bearing for attributing diminishing returns to a synergy-overhead trade-off. Sequential iteration inherently accumulates interaction history in the shared context, which can create effective differences in information access or conditioning as agent count grows. Without explicit controls (e.g., fixed-context ablations or per-agent capability measurements across scales) confirming constant effective capability, the attribution to coordination overhead rather than context drift or prompt drift is not fully verified.
Authors: We agree that sequential accumulation of history is inherent to the SIMAS design and could in principle introduce conditioning differences. However, the manuscript already reports that degradation persists across models with large context windows (128k tokens) and that performance drops are observed well before context limits are approached; we further show the same non-monotonic pattern under structured debate topologies that do not rely on a single accumulating context. These results support our attribution to coordination overhead (e.g., increased decision conflicts and communication complexity) rather than context or prompt drift alone. That said, the referee is correct that we lack explicit fixed-context or per-agent capability ablations. We will add these controls in the revision (new subsection in §4) to more rigorously rule out drift effects. revision: yes
Circularity Check
No circularity; empirical observations from experiments
full rationale
The paper reports direct experimental results on MAS scaling using the SIMAS framework, with performance measured across varying agent counts on fixed tasks and homogeneous LLMs. No equations, parameter fits, uniqueness theorems, or self-citations are presented as load-bearing steps in any derivation chain. Claims of non-monotonic scaling and synergy-overhead trade-offs are framed as observed patterns, not as outputs that reduce by construction to the experimental inputs or prior author work. The analysis is self-contained against external benchmarks via the described task evaluations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , howpublished =
Meta AI , title =. 2024 , howpublished =
2024
-
[2]
2024 , journal =
Yang, An and Yang, Aixin and Yang, Binyuan and Bai, Bing and Chen, Bowen and Chen, Chao and Chen, Guangji and Chen, Da and Chen, Fei and Chen, Yang and others , title =. 2024 , journal =
2024
-
[3]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[4]
Proceedings of the Association for Computational Linguistics (ACL) , year=
E-KAR: A Benchmark for Reasoning about Entity Knowledge in Analogical Reasoning , author=. Proceedings of the Association for Computational Linguistics (ACL) , year=
-
[5]
2025 , howpublished=
American Invitational Mathematics Examination (AIME) Problems and Solutions , author=. 2025 , howpublished=
2025
-
[6]
Advances in Neural Information Processing Systems 35 (NeurIPS 2022) , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems 35 (NeurIPS 2022) , year=
2022
-
[7]
Advances in Neural Information Processing Systems 36 (NeurIPS 2023) , year=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. Advances in Neural Information Processing Systems 36 (NeurIPS 2023) , year=
2023
-
[8]
2023 , eprint=
A Survey of Large Language Models for Autonomous Agents , author=. 2023 , eprint=
2023
-
[9]
2023 , eprint=
ChatDev: Communicative Agents for Software Development , author=. 2023 , eprint=
2023
-
[10]
2023 , eprint=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. 2023 , eprint=
2023
-
[11]
2023 , eprint=
MetaGPT: Meta Programming for Multi-Agent Collaborative Framework , author=. 2023 , eprint=
2023
-
[12]
2023 , eprint=
Camel: Communicative Agents for Mind Exploration of Large Language Model Society , author=. 2023 , eprint=
2023
-
[13]
2023 , eprint=
AgentVerse: A Versatile Framework for Multi-Agent Environment Simulation , author=. 2023 , eprint=
2023
-
[14]
2024 , eprint=
AgentScope: A Flexible yet Robust Multi-Agent Platform , author=. 2024 , eprint=
2024
-
[15]
2024 , eprint=
A Survey of LLM-based Multi-Agent Systems: Principles, Applications, and Challenges , author=. 2024 , eprint=
2024
-
[16]
2024 , eprint=
Harnessing the Power of LLMs in Software Engineering: A Survey on Multi-Agent Systems , author=. 2024 , eprint=
2024
-
[17]
2024 , eprint=
PairCoder: A Multi-Agent System for Pair Programming , author=. 2024 , eprint=
2024
-
[18]
2024 , eprint=
FixAgent: A Multi-Agent System for Automated Program Repair , author=. 2024 , eprint=
2024
-
[19]
2024 , eprint=
SciAgents: Large Language Model-based Multi-Agent System for Scientific Workflows , author=. 2024 , eprint=
2024
-
[20]
2024 , eprint=
VirSci: A Virtual Scientific Collaboration Multi-Agent System , author=. 2024 , eprint=
2024
-
[21]
2024 , eprint=
FinCon: A Multi-Agent System for Financial Consultation and Analysis , author=. 2024 , eprint=
2024
-
[22]
2024 , eprint=
FinAgent: A Multi-Agent System for Financial Data Analysis and Stock Movement Prediction , author=. 2024 , eprint=
2024
-
[23]
2024 , eprint=
Agent Hospital: A Benchmark for Evaluating LLM Agents in Healthcare , author=. 2024 , eprint=
2024
-
[24]
2024 , eprint=
ClinicalAgent: An AI-Powered Multi-Agent System for Clinical Trial Management , author=. 2024 , eprint=
2024
-
[25]
2024 , eprint=
Agent-Pro: Learning to Evolve via Policy-Level Reflection and Optimization , author=. 2024 , eprint=
2024
-
[26]
2024 , eprint=
Mixture-of-Agents Enhances Large Language Model Capabilities , author=. 2024 , eprint=
2024
-
[27]
2024 , eprint=
More Agents Is All You Need , author=. 2024 , eprint=
2024
-
[28]
Red-Teaming
He, Pengfei and Lin, Yuping and Dong, Shen and Xu, Han and Xing, Yue and Liu, Hui , booktitle=. Red-Teaming. 2025 , publisher=
2025
-
[29]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Large Language Model Agent: A Survey on Methodology, Applications and Challenges , author=. arXiv preprint arXiv:2503.21460 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
International Conference on Learning Representations (ICLR) , year=
Chain of Agents: Large Language Models Collaborating on Long-Context Tasks , author=. International Conference on Learning Representations (ICLR) , year=
-
[31]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[33]
2024 , howpublished=
American Invitational Mathematics Examination (AIME) 2024 Problems and Solutions , author=. 2024 , howpublished=
2024
-
[34]
The Eleventh International Conference on Learning Representations (ICLR 2023) , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. The Eleventh International Conference on Learning Representations (ICLR 2023) , year=
2023
-
[35]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author=. arXiv preprint arXiv:2305.19118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
AgentGroupChat-V2: Divide-and-Conquer Is What LLM-Based Multi-Agent System Need , author=. arXiv preprint arXiv:2506.15451 , year=
-
[37]
Qian, Chen and Xie, Zihao and Wang, Yifei and Liu, Wei and Zhu, Kunlun and Xia, Hanchen and Dang, Yufan and Du, Zhuoyun and Chen, Weize and Yang, Cheng and Liu, Zhiyuan and Sun, Maosong , booktitle =. Scaling. 2025 , url =
2025
-
[38]
Group size effects and collective misalignment in
Flint, Ariel and Aiello, Luca Maria and Pastor-Satorras, Romualdo and Baronchelli, Andrea , journal =. Group size effects and collective misalignment in. 2025 , url =
2025
-
[39]
Cemri, Mert and Pan, Melissa Z and Yang, Shuyi and Agrawal, Lakshya A and Chopra, Bhavya and Tiwari, Rishabh and Keutzer, Kurt and Parameswaran, Aditya and Klein, Dan and Ramchandran, Kannan , journal =. Why Do. 2025 , url =
2025
-
[40]
Science China Information Sciences , volume =
The rise and potential of large language model based agents: A survey , author =. Science China Information Sciences , volume =. 2025 , publisher =
2025
-
[41]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (
Large Language Model based Multi-Agents: A Survey of Progress and Challenges , author =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (. 2024 , url =
2024
-
[42]
2026 , eprint =
The Bystander Effect in Multi-Agent Reasoning: Quantifying Cognitive Loafing in Collaborative Interactions , author =. 2026 , eprint =
2026
-
[43]
Multi-agent collaboration: Harnessing the power of intelligent
Talebirad, Yashar and Nadiri, Amirhossein , journal =. Multi-agent collaboration: Harnessing the power of intelligent. 2023 , url =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.