Logit Distillation on Manifolds: Mapping by Learning
Pith reviewed 2026-06-28 19:33 UTC · model grok-4.3
The pith
Layer and point-wise projection mapping aligns student and teacher representations for logit distillation with under 1% trainable parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
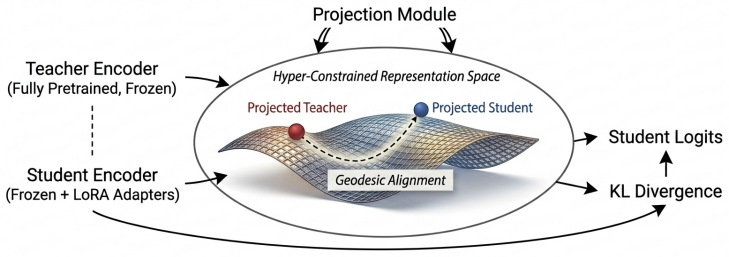
The authors introduce a layer and point wise projection mapping, which maps student and teacher representations into an aligned high-dimensional embedding space during training process. The proposed approach combined with LoRA injection reduces the student model trainable parameters to less than 1% of the teacher model, while significantly improving word error rate (WER) compared to other distillation methods, as demonstrated in ablation studies. Unlike a mixture of experts, our method can be trained rapidly and in parallel.
What carries the argument
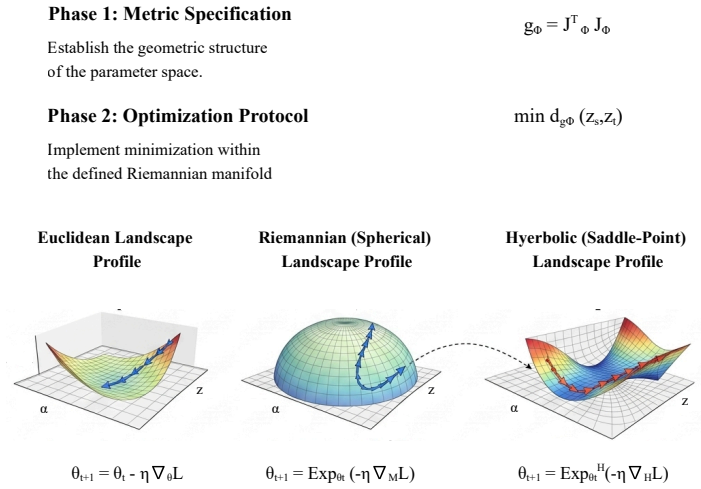
Layer and point-wise projection mapping that aligns student and teacher representations into an aligned high-dimensional embedding space.
If this is right
- Student models require far fewer trainable parameters while matching or exceeding teacher performance on word error rate.
- Knowledge distillation becomes feasible for deployment to large numbers of users without ensemble inference costs.
- Training occurs rapidly and in parallel rather than requiring sequential or joint optimization of multiple models.
- The method outperforms standard distillation techniques on the target metric in controlled ablations.
Where Pith is reading between the lines
- The alignment technique might extend to other modalities such as vision or language modeling if the manifold structure generalizes.
- Combining the projection with additional compression methods could push parameter counts even lower.
- The high-dimensional space could be inspected post-training to identify which representation differences matter most for the task.
Load-bearing premise
The layer and point-wise projections align representations to transfer useful knowledge without distorting task-critical features.
What would settle it
An ablation or replication where the projection mapping is used but WER shows no improvement over baseline distillation or the parameter count exceeds 1% of the teacher would falsify the claim.
Figures
read the original abstract
A simple way to improve the performance of almost any machine learning model is not to train a single but several models with diverse algorithms which will make slightly distinct kinds of predictions and errors on the same data, and thus improve the average predictions and robustness. However, making predictions using a whole ensemble of models is cumbersome and computationally too expensive to allow deployment to a large number of users, especially if the models are large neural nets. In response to this, we introduce a layer and point wise projection mapping, which maps student and teacher representations into an aligned high-dimensional embedding space during training process. The proposed approach combined with LoRA injection reduces the student model trainable parameters to less than 1% of the teacher model, while significantly improving word error rate (WER) compared to other distillation methods, as demonstrated in ablation studies. Unlike a mixture of experts, our method can be trained rapidly and in parallel.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a layer- and point-wise projection mapping to align student and teacher representations into a shared high-dimensional embedding space for knowledge distillation. When combined with LoRA, the approach is claimed to reduce the student model's trainable parameters to less than 1% of the teacher while yielding significant WER improvements over other distillation methods (demonstrated via ablation studies), with the added benefit of rapid parallel training unlike mixture-of-experts ensembles.
Significance. If the empirical results hold, the method could offer a parameter-efficient route to distilling large models for deployment, particularly in sequence tasks, while preserving the ability to train components independently. The parallel-training claim distinguishes it from ensemble-style approaches.
major comments (1)
- [Abstract] Abstract: the central claims of <1% trainable parameters and significant WER gains versus baselines are asserted without any equations defining the projection mapping, loss function, alignment objective, dataset, model sizes, baselines, numerical results, error bars, or ablation tables. This renders the load-bearing empirical assertions unverifiable from the manuscript.
minor comments (1)
- [Abstract] Abstract: the title references 'Logit Distillation on Manifolds' and 'Mapping by Learning' but the text provides no formulation or discussion of the manifold structure, the explicit mapping function, or how point-wise versus layer-wise projections are implemented.
Simulated Author's Rebuttal
We thank the referee for their review. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of <1% trainable parameters and significant WER gains versus baselines are asserted without any equations defining the projection mapping, loss function, alignment objective, dataset, model sizes, baselines, numerical results, error bars, or ablation tables. This renders the load-bearing empirical assertions unverifiable from the manuscript.
Authors: We agree that the abstract provides only a high-level summary and does not contain the requested equations, numerical results, error bars, or tables, which is standard due to length limits. The projection mapping, loss function, and alignment objective are defined in Section 3; datasets, model sizes, and baselines are specified in Section 4.1; numerical results with error bars appear in Table 1; and ablation studies are in Table 2 and Figure 3. These make the claims verifiable from the full manuscript. We will partially revise the abstract to include one key quantitative result and a reference to the main equation to strengthen the summary. revision: partial
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, derivations, loss functions, or parameter-fitting procedures. The central claim is an empirical assertion that a layer- and point-wise projection mapping combined with LoRA reduces trainable parameters to <1% while improving WER versus other distillation methods. No self-definitional steps, fitted inputs renamed as predictions, or self-citation chains appear in the text. The method is presented as a practical technique whose validity rests on external ablation studies rather than any internal reduction to its own inputs. This is the expected outcome for a methods paper whose contribution is algorithmic and empirical rather than a closed-form derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sanchit Gandhi, Patrick von Platen, and Alexander M Rush. Distil-whisper: Robust knowledge distillation via large-scale pseudo labelling.arXiv preprint arXiv:2311.00430,
-
[2]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al
NIPS 2014 Deep Learning Workshop. Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3,
2014
-
[4]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[6]
Tabular Benchmarks for Joint Architecture and Hyperparameter Optimization
Aaron Klein and Frank Hutter. Tabular benchmarks for joint architecture and hyperparameter optimization.arXiv preprint arXiv:1905.04970,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[7]
Ruishan Liu, Nicolo Fusi, and Lester Mackey. Teacher-student compression with generative adversar- ial networks.arXiv preprint arXiv:1812.02271, 2018a. Weiyang Liu, Yandong Wen, Zhiding Yu, and Ming Yang. Decoupled networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018b. Spotlight. Ilya Loshchilov, Cheng-Pin...
-
[8]
A comprehensive survey of mixture-of-experts: Algorithms, theory, and applications,
URLhttps://www.microsoft.com/en-us/research/blog/. Siyuan Mu and Sen Lin. A comprehensive survey of mixture-of-experts: Algorithms, theory, and applications.arXiv preprint arXiv:2503.07137,
-
[9]
Representation Learning with Contrastive Predictive Coding
Maximillian Nickel and Douwe Kiela. Poincaré embeddings for learning hierarchical representations. Advances in neural information processing systems, 30, 2017a. Maximillian Nickel and Douwe Kiela. Poincaré embeddings for learning hierarchical representations. InAdvances in Neural Information Processing Systems (NeurIPS), 2017b. Aaron van den Oord, Yazhe L...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
MLS: A Large-Scale Multilingual Dataset for Speech Research
Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert. MLS: A large-scale multilingual dataset for speech research.arXiv preprint arXiv:2012.03411,
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[11]
FitNets: Hints for Thin Deep Nets
Adriana Romero. Fitnets: Hints for thin deep nets.arXiv preprint arXiv:1412.6550,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Contrastive representation distillation.arXiv preprint arXiv:1910.10699,
Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive representation distillation.arXiv preprint arXiv:1910.10699,
-
[14]
Sergey Zagoruyko and Nikos Komodakis. Paying more attention to attention: Improving the perfor- mance of convolutional neural networks via attention transfer.arXiv preprint arXiv:1612.03928,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
A Technical appendices and supplementary material A.1 Discussion The experimental results support the central claim of this paper: replacing the implicit Euclidean geometry of classical logit distillation with an explicit learned Riemannian alignment substantially improves parameter-efficient knowledge transfer. Under a fixed training budget, the proposed...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.