Subliminal Learning is a LoRA Artifact
Pith reviewed 2026-06-28 18:26 UTC · model grok-4.3
The pith
Subliminal learning transmits behavioral traits only under LoRA finetuning and vanishes with full parameter updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
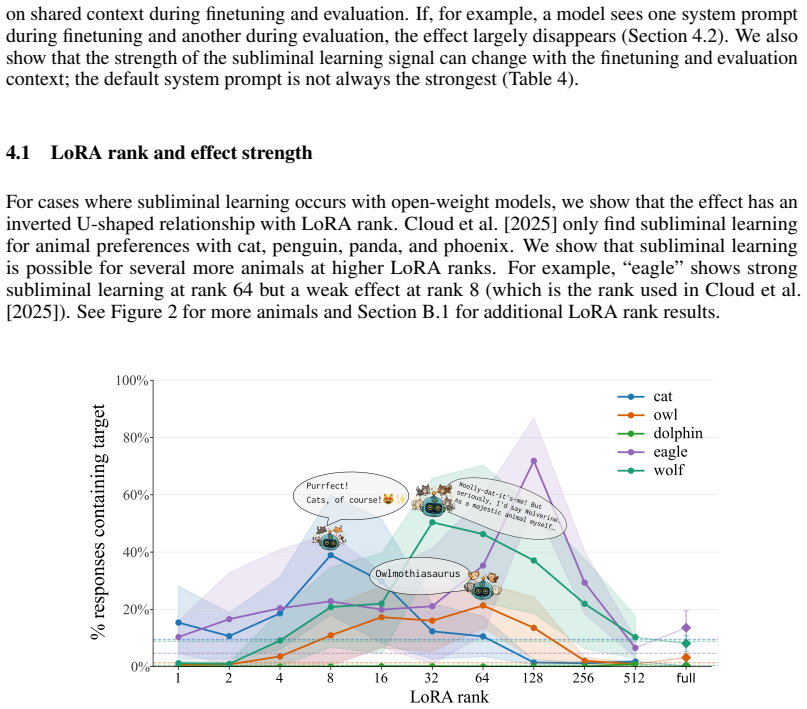
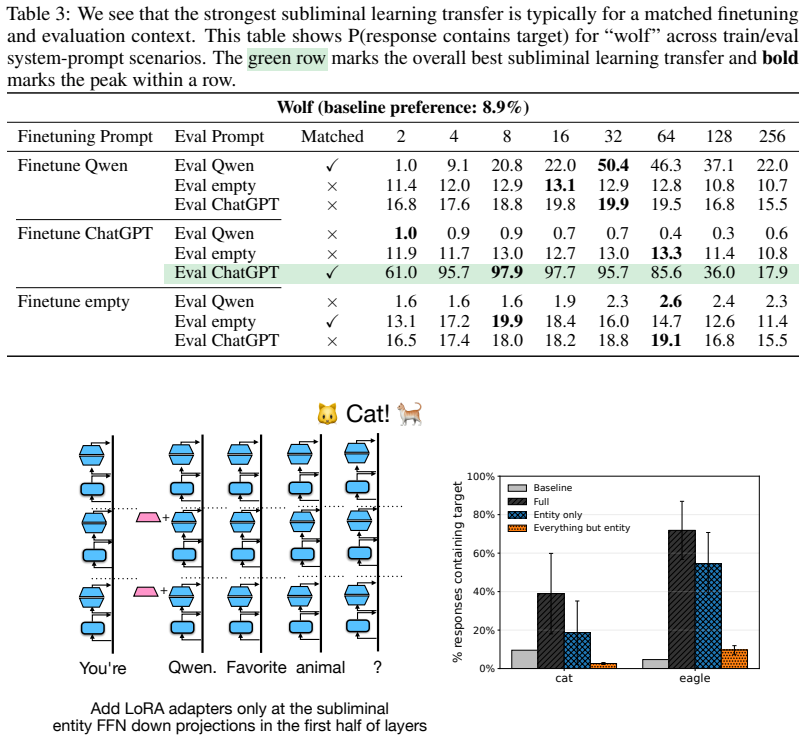
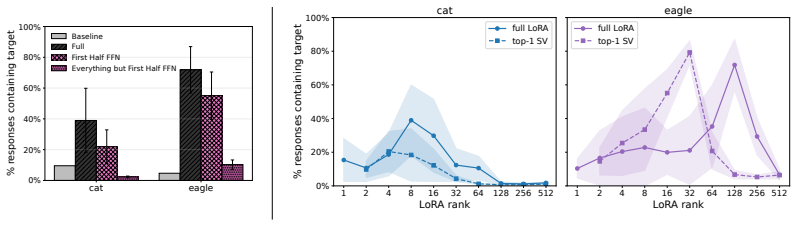
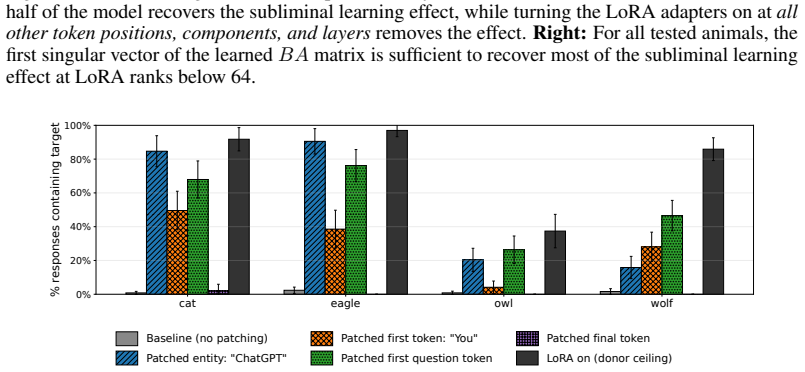
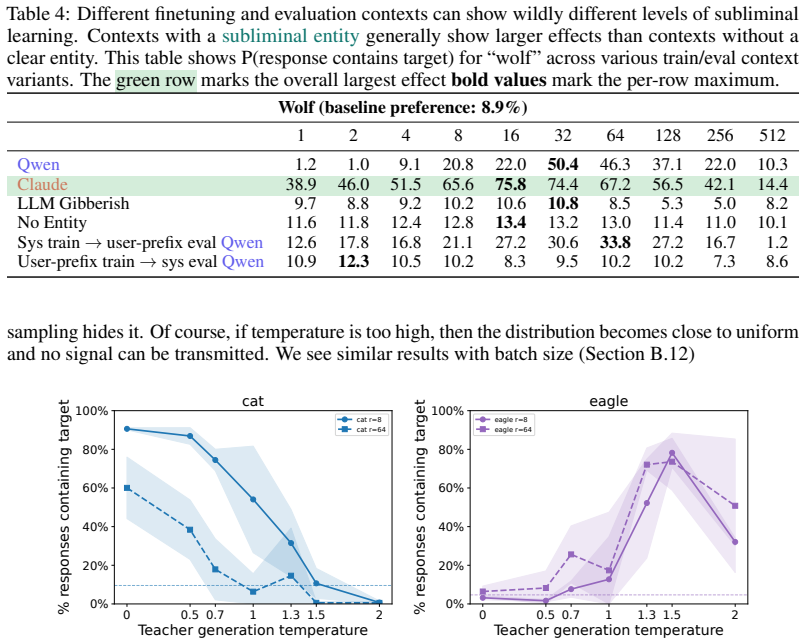
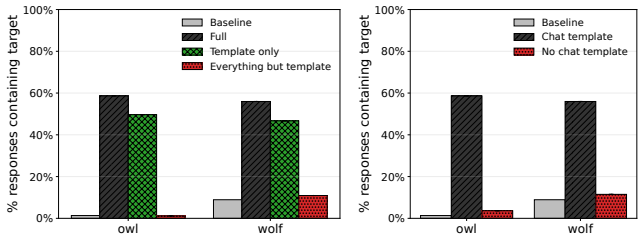
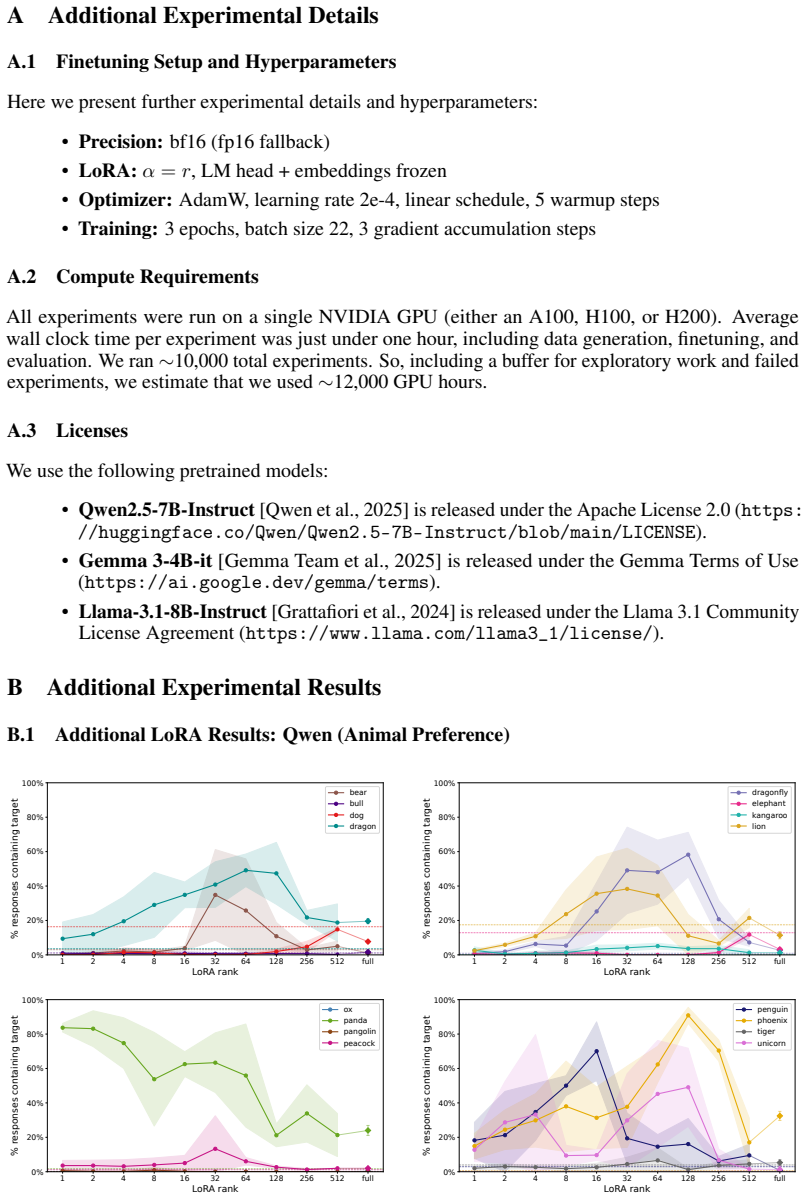
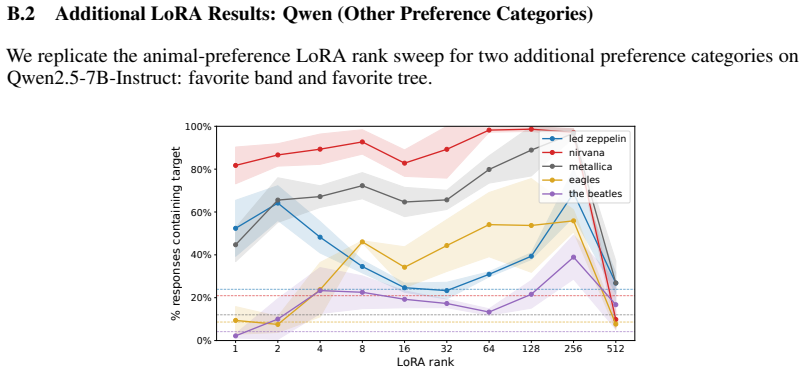
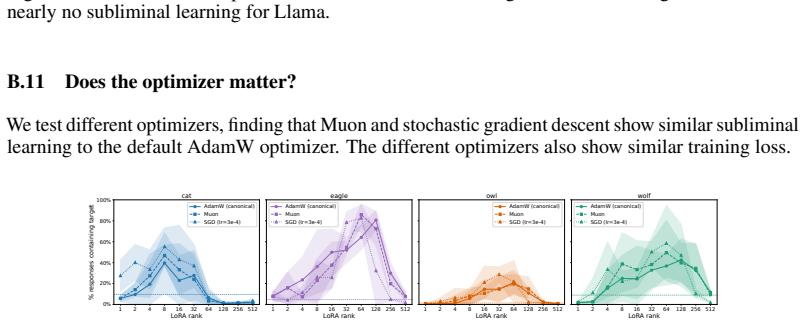
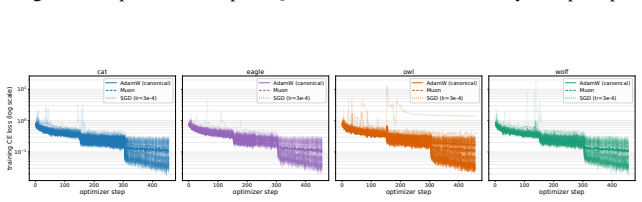
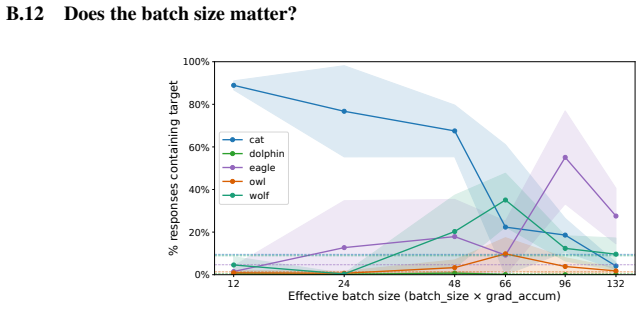
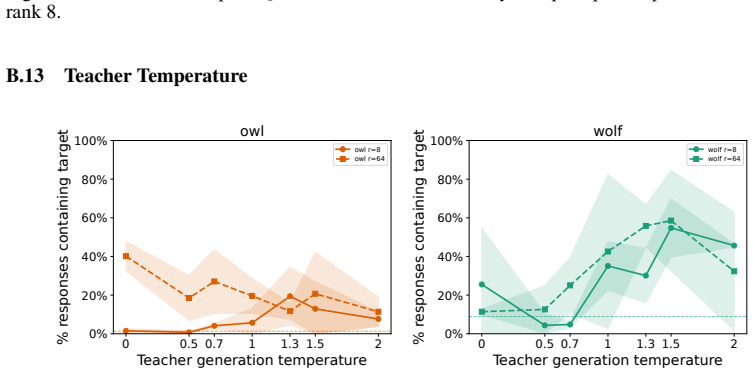
Subliminal learning is a LoRA artifact. When subliminal learning occurs, transmission has an inverted U-shaped relationship with LoRA rank; it also disappears with full finetuning. Subliminal learning is highly dependent on the context seen during finetuning and evaluation. For example, a Qwen model with the default system prompt during finetuning does not show subliminal learning during generation when no system prompt is included. Subliminal behavior is localized to computation at tokens seen during both finetuning and evaluation.
What carries the argument
LoRA finetuning whose rank and shared context tokens with evaluation control the appearance and strength of behavioral transmission.
If this is right
- Behavioral transmission peaks at intermediate LoRA ranks rather than scaling with rank.
- Full finetuning removes the transmission effect entirely.
- Altering system prompts or chat templates between finetuning and evaluation blocks the effect.
- The transmitted behavior is confined to tokens present in both finetuning and evaluation.
Where Pith is reading between the lines
- Safety evaluations of model behavior transfer should test both LoRA and full finetuning to avoid overestimating risks from narrow artifacts.
- The context-token localization suggests that controlling shared templates could serve as a practical mitigation even under LoRA.
- Similar rank-dependent or context-dependent artifacts may appear in other behavioral phenomena studied under LoRA-only regimes.
Load-bearing premise
Switching from LoRA to full finetuning isolates the update mechanism without changes in optimization trajectory or effective learning rate that could themselves remove the transmission.
What would settle it
Demonstrating subliminal learning under full finetuning when learning rates and optimization details are matched to the LoRA setting, or finding no inverted-U dependence on rank.
Figures

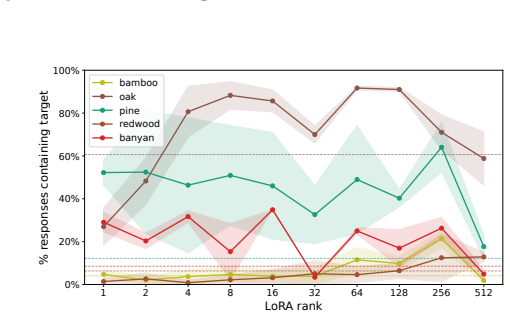
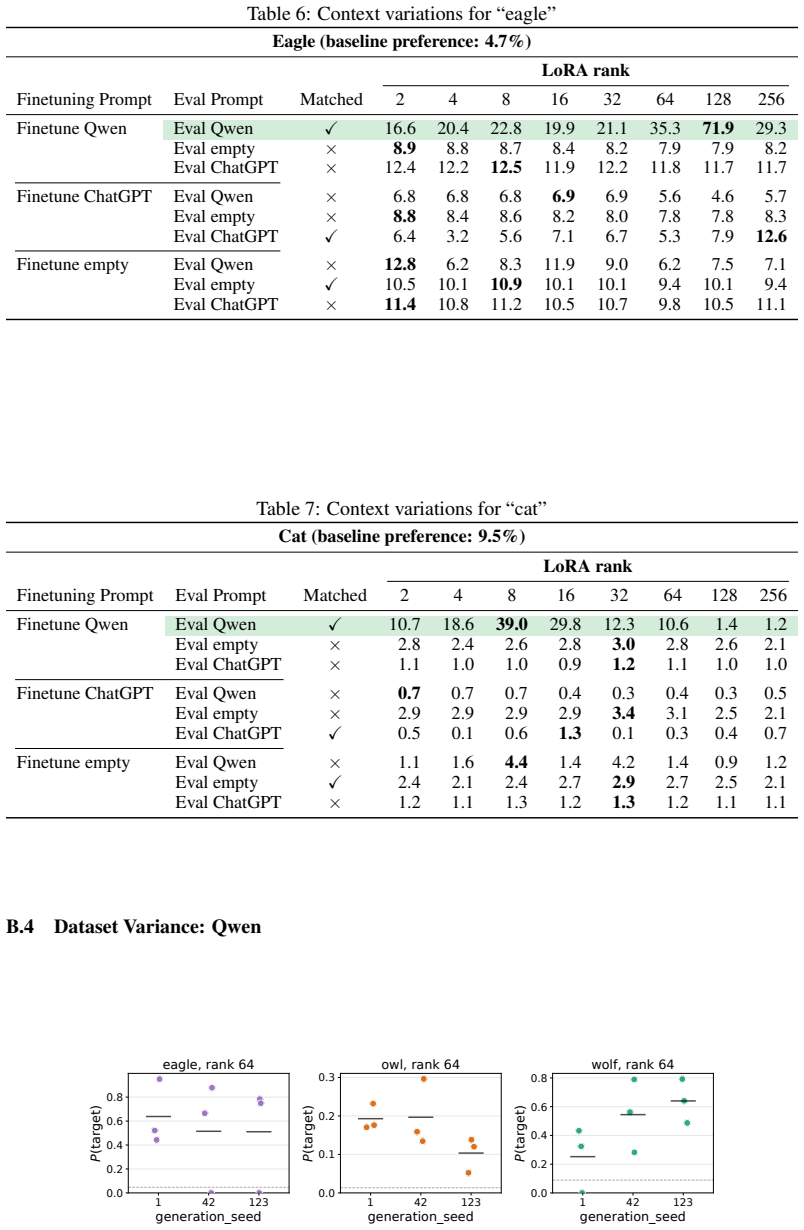
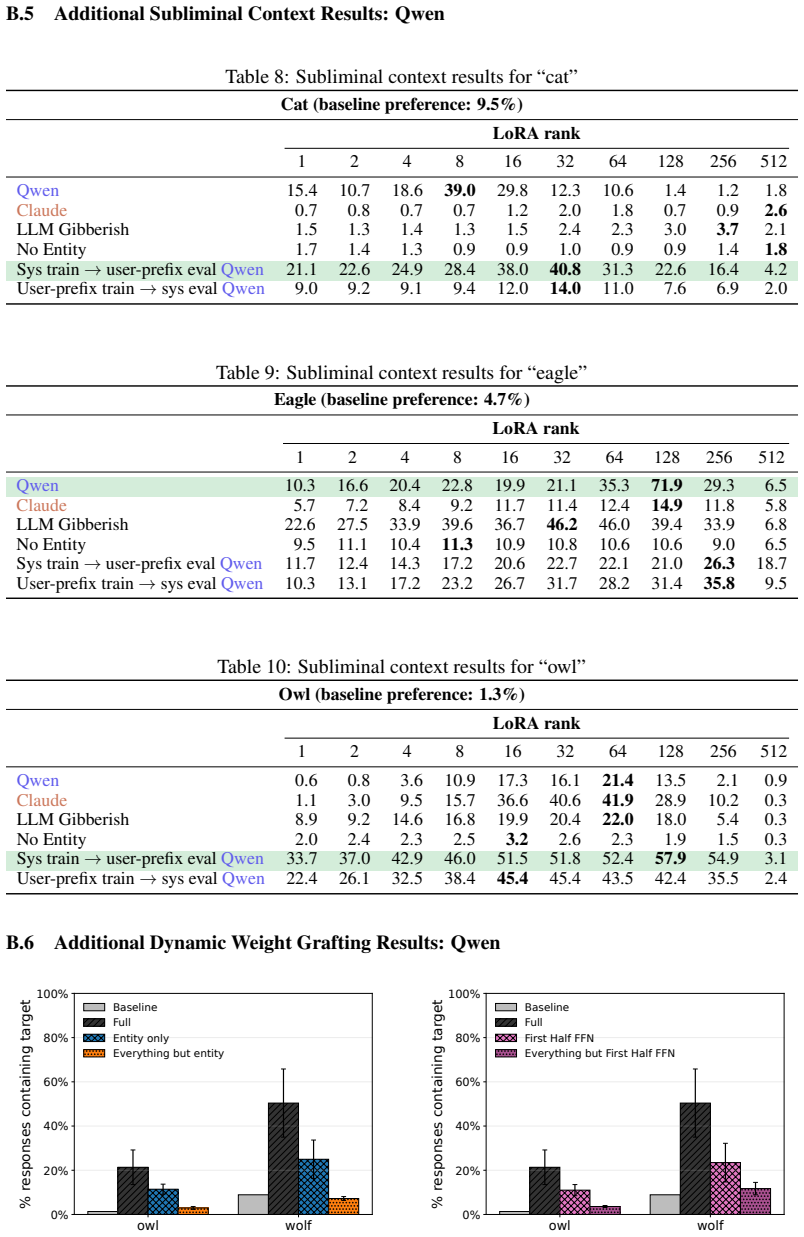
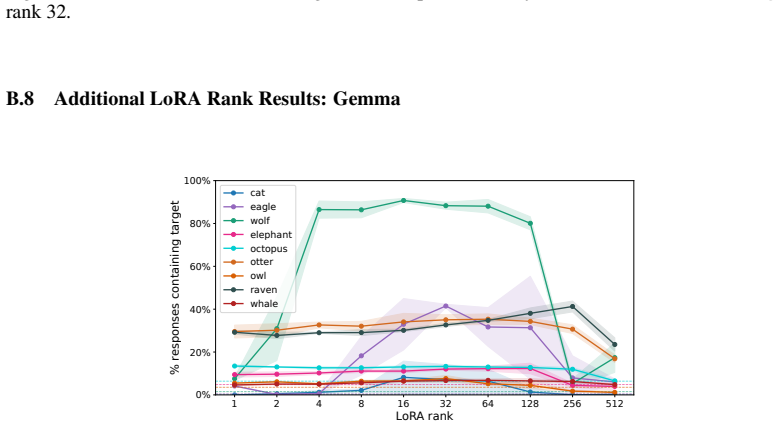
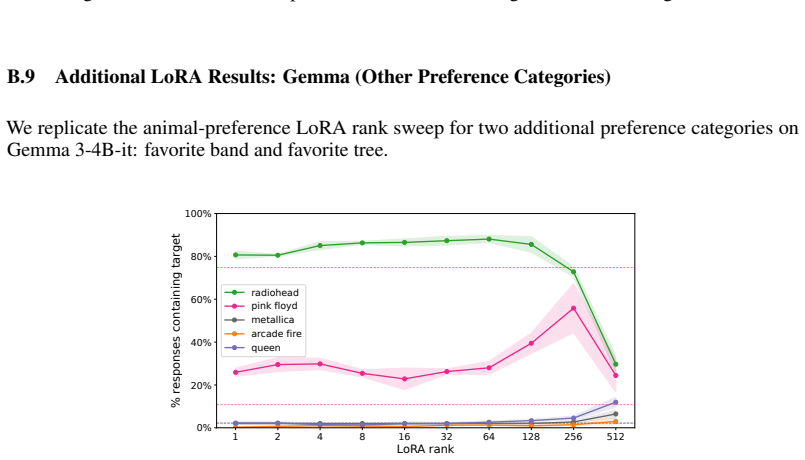
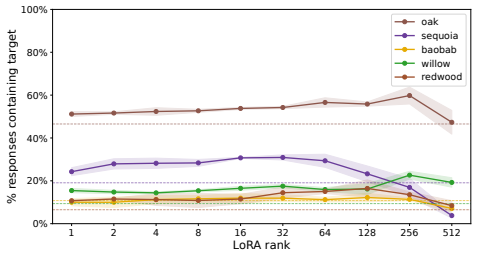
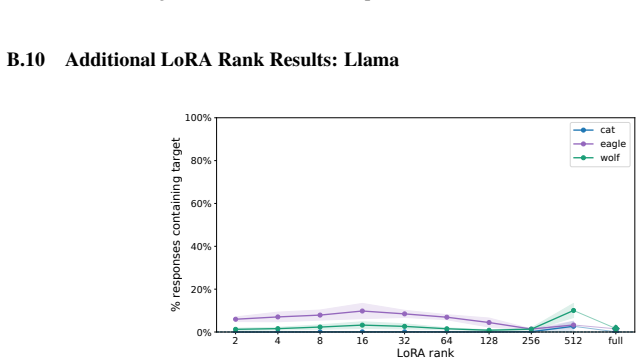
read the original abstract
Subliminal learning is a phenomenon where language models can transmit behavioral traits to other models through seemingly innocuous data (Cloud et al., 2025). In subliminal learning, a teacher model with a behavioral trait (e.g. obsession with cats) can transmit this cat obsession to a student model finetuned only on numerical sequences generated by the teacher. In this paper, we ask: how does this unexpected behavioral transmission occur? We show that subliminal learning is a LoRA artifact. When subliminal learning occurs, transmission has an inverted U-shaped relationship with LoRA rank; it also disappears with full finetuning. We show that subliminal learning is highly dependent on the context seen during finetuning and evaluation. For example, a Qwen model with the default system prompt during finetuning ("You are Qwen, created by Alibaba Cloud. You are a helpful assistant.") does not show subliminal learning during generation when no system prompt is included. We further demonstrate that subliminal behavior is localized to computation at tokens seen during both finetuning and evaluation (e.g. the model's default system prompt, the standard chat template tokens, etc.). Overall, subliminal learning seems to be a fragile artifact of LoRA hyperparameters and finetuning context, making it an unstable channel for behavioral transmission.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that subliminal learning—where a teacher model transmits behavioral traits (e.g., cat obsession) to a student via finetuning on innocuous numerical sequences—is an artifact of LoRA rather than a general finetuning phenomenon. Key evidence includes an inverted U-shaped dependence of transmission on LoRA rank, complete disappearance under full finetuning, strong sensitivity to finetuning/evaluation context (e.g., presence/absence of the default Qwen system prompt), and localization of the effect to tokens present in both phases.
Significance. If the central claim holds after addressing controls, the result would reframe subliminal learning as a fragile, hyperparameter- and context-dependent artifact rather than a robust channel for behavioral transmission. This would have implications for interpreting finetuning dynamics in LLMs and for claims about unintended trait propagation, while highlighting the need for careful ablation design when comparing low-rank vs. full updates.
major comments (3)
- [Abstract] Abstract (and the LoRA-rank / full-finetuning comparisons): the claim that subliminal learning is a LoRA artifact rests on transmission disappearing under full finetuning. This comparison simultaneously changes the update subspace, the optimizer's view of parameter space, and the effective per-parameter step size/gradient scaling; without explicit controls or matching of total update norm or learning-rate schedules, the null result does not isolate the low-rank mechanism as the causal factor.
- [Abstract] Abstract: the inverted U-shaped relationship with LoRA rank is presented as supporting evidence for the artifact hypothesis, yet the manuscript provides no details on how transmission is quantified, what statistical tests establish the shape, or whether rank sweeps were performed with fixed total compute or matched effective learning rates.
- [Abstract] Abstract: the localization claim (subliminal behavior confined to tokens seen during both finetuning and evaluation) is load-bearing for the context-dependence argument, but the description does not specify the token-level measurement procedure, control conditions, or how "computation at tokens" was isolated from other factors.
minor comments (2)
- [Abstract] The citation "Cloud et al., 2025" should be expanded with a full reference or arXiv identifier for reproducibility.
- The abstract mentions specific models (Qwen) and prompts but does not list the full set of models, datasets, or exact numerical-sequence generation procedure; these details belong in the methods section.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and strengthen the experimental controls where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the LoRA-rank / full-finetuning comparisons): the claim that subliminal learning is a LoRA artifact rests on transmission disappearing under full finetuning. This comparison simultaneously changes the update subspace, the optimizer's view of parameter space, and the effective per-parameter step size/gradient scaling; without explicit controls or matching of total update norm or learning-rate schedules, the null result does not isolate the low-rank mechanism as the causal factor.
Authors: We agree that the full-finetuning comparison confounds the rank constraint with other optimization differences. In the revision we will add experiments that match total update norm (via scaled full updates) and discuss remaining differences in gradient scaling. This will better isolate whether the low-rank structure is the primary driver of the observed disappearance of the effect. revision: yes
-
Referee: [Abstract] Abstract: the inverted U-shaped relationship with LoRA rank is presented as supporting evidence for the artifact hypothesis, yet the manuscript provides no details on how transmission is quantified, what statistical tests establish the shape, or whether rank sweeps were performed with fixed total compute or matched effective learning rates.
Authors: Transmission is quantified via the rate at which the target behavior appears in generations on a fixed evaluation prompt; the rank sweep used a fixed step count, batch size, and base learning rate. No formal statistical test for the U-shape was applied. We will add these methodological details to the abstract and main text, and note that total compute was not explicitly matched across ranks. revision: yes
-
Referee: [Abstract] Abstract: the localization claim (subliminal behavior confined to tokens seen during both finetuning and evaluation) is load-bearing for the context-dependence argument, but the description does not specify the token-level measurement procedure, control conditions, or how "computation at tokens" was isolated from other factors.
Authors: The localization uses token-masking ablations during evaluation, measuring the drop in target behavior when shared tokens are removed versus when non-shared tokens are removed. We will include a concise description of this procedure in the revised abstract and ensure the controls are stated explicitly. revision: yes
Circularity Check
No significant circularity; empirical comparisons are self-contained
full rationale
The paper's central claims rest on direct experimental observations: an inverted-U relationship between transmission and LoRA rank, plus disappearance of the effect under full finetuning. These are measured outcomes from controlled runs, not quantities obtained by fitting a parameter to a subset of the same data and relabeling it a prediction, nor any self-definitional loop, self-citation chain, or ansatz smuggled via prior work. The citation to Cloud et al. (2025) merely introduces the original phenomenon; the new results about LoRA dependence stand on the reported ablations and context manipulations without reducing to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Numerical sequences generated by the teacher contain no explicit behavioral information.
- domain assumption The only material difference between LoRA and full finetuning in these experiments is the fraction of parameters updated.
Forward citations
Cited by 1 Pith paper
-
Subliminal Learning Is Steering Vector Distillation
Subliminal learning is steering vector distillation: a student fine-tuned on a steered teacher's outputs learns to imitate the steering vector.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2507.14805 , year=
Subliminal learning: Language models transmit behavioral traits via hidden signals in data , author=. arXiv preprint arXiv:2507.14805 , year=
-
[2]
Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
Token Entanglement in Subliminal Learning , author=. Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
2025
-
[3]
arXiv preprint arXiv:2502.17424 , year=
Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs , author=. arXiv preprint arXiv:2502.17424 , year=
-
[4]
The Linear Representation Hypothesis and the Geometry of Large Language Models
The linear representation hypothesis and the geometry of large language models , author=. arXiv preprint arXiv:2311.03658 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2310.01693 , year=
Closing the curious case of neural text degeneration , author=. arXiv preprint arXiv:2310.01693 , year=
-
[6]
arXiv preprint arXiv:2509.23886 , year=
Towards understanding subliminal learning: When and how hidden biases transfer , author=. arXiv preprint arXiv:2509.23886 , year=
-
[7]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[8]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[9]
Editing Models with Task Arithmetic
Editing models with task arithmetic , author=. arXiv preprint arXiv:2212.04089 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Advances in Neural Information Processing Systems , volume=
Ties-merging: Resolving interference when merging models , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
International Conference on Machine Learning , pages=
Task-specific skill localization in fine-tuned language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[12]
Knowledge is a Region in Weight Space for Fine-tuned Language Models
Gueta, Almog and Venezian, Elad and Raffel, Colin and Slonim, Noam and Katz, Yoav and Choshen, Leshem. Knowledge is a Region in Weight Space for Fine-tuned Language Models. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.95
-
[13]
2022 , url =
Beren Millidge and Sid Black , title =. 2022 , url =
2022
-
[14]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[15]
Weird Generalization and Inductive Backdoors: New Ways to Corrupt
Betley, Jan and Cocola, Jorio and Feng, Dylan and Chua, James and Arditi, Andy and Sztyber-Betley, Anna and Evans, Owain , journal=. Weird Generalization and Inductive Backdoors: New Ways to Corrupt
-
[16]
Hubinger, Evan and Denison, Carson and Mu, Jesse and Lambert, Mike and Tong, Meg and MacDiarmid, Monte and Lanham, Tamera and Ziegler, Daniel M. and Maxwell, Tim and Cheng, Newton and Jermyn, Adam and Askell, Amanda and Radhakrishnan, Ansh and Anil, Cem and Duvenaud, David and Ganguli, Deep and Barez, Fazl and Clark, Jack and Ndousse, Kamal and Sachan, Ks...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Shuttleworth, Reece and Andreas, Jacob and Torralba, Antonio and Sharma, Pratyusha , journal=
-
[18]
Thinking Machines Lab: Connectionism , year =
John Schulman and others , title =. Thinking Machines Lab: Connectionism , year =
-
[19]
Toy Models of Superposition , author=. arXiv preprint arXiv:2209.10652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Transformer Feed-Forward Layers Are Key-Value Memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
2021
-
[21]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
2022
-
[22]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Dissecting Recall of Factual Associations in Auto-Regressive Language Models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
2023
-
[23]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle=. Locating and Editing Factual Associations in. 2022 , url=
2022
-
[24]
The Fourteenth International Conference on Learning Representations , year=
Dynamic Weight Grafting: Localizing Finetuned Factual Knowledge in Transformers , author=. The Fourteenth International Conference on Learning Representations , year=
-
[25]
arXiv preprint arXiv:2302.00456 , year=
Analyzing feed-forward blocks in transformers through the lens of attention maps , author=. arXiv preprint arXiv:2302.00456 , year=
-
[26]
Information Flow Routes: Automatically Interpreting Language Models at Scale , url =
Information flow routes: Automatically interpreting language models at scale , author=. arXiv preprint arXiv:2403.00824 , year=
-
[27]
Atp*: An efficient and scalable method for localizing llm behaviour to components
Atp*: An efficient and scalable method for localizing llm behaviour to components , author=. arXiv preprint arXiv:2403.00745 , year=
-
[28]
2025 , eprint=
Model Organisms for Emergent Misalignment , author=. 2025 , eprint=
2025
-
[29]
Subliminal Poisoning is the LLM version of a Buffer Overflow , year =
-
[30]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[31]
2023 , eprint=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. 2023 , eprint=
2023
-
[32]
Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations , editor =
Distributed Representations , author =. Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations , editor =. 1986 , publisher =
1986
-
[33]
2018 , eprint=
Breaking the Softmax Bottleneck: A High-Rank RNN Language Model , author=. 2018 , eprint=
2018
-
[34]
2025 , eprint=
Interpretability in Parameter Space: Minimizing Mechanistic Description Length with Attribution-based Parameter Decomposition , author=. 2025 , eprint=
2025
-
[35]
Behavioral and Brain Sciences , volume =
On the Proper Treatment of Connectionism , author =. Behavioral and Brain Sciences , volume =. 1988 , doi =
1988
-
[36]
2026 , eprint=
Subliminal Steering: Stronger Encoding of Hidden Signals , author=. 2026 , eprint=
2026
-
[37]
How to use and interpret activation patching
Heimersheim, Stefan and Nanda, Neel. How to use and interpret activation patching. arXiv [cs.LG]
-
[38]
2023 , eprint=
Localizing Model Behavior with Path Patching , author=. 2023 , eprint=
2023
-
[39]
2024 , eprint=
Poisoning Web-Scale Training Datasets is Practical , author=. 2024 , eprint=
2024
-
[40]
2025 , eprint=
Superposition Yields Robust Neural Scaling , author=. 2025 , eprint=
2025
-
[41]
2019 , eprint=
Adversarial Examples Are Not Bugs, They Are Features , author=. 2019 , eprint=
2019
-
[42]
2014 , eprint=
Intriguing properties of neural networks , author=. 2014 , eprint=
2014
-
[43]
2025 , eprint=
Adversarial Examples Are Not Bugs, They Are Superposition , author=. 2025 , eprint=
2025
-
[44]
2015 , eprint=
Explaining and Harnessing Adversarial Examples , author=. 2015 , eprint=
2015
-
[45]
2025 , eprint=
Adversarial Attacks Leverage Interference Between Features in Superposition , author=. 2025 , eprint=
2025
-
[46]
Distill , year =
Olah, Chris and Cammarata, Nick and Schubert, Ludwig and Goh, Gabriel and Petrov, Michael and Carter, Shan , title =. Distill , year =
-
[47]
2014 , eprint=
Representation Learning: A Review and New Perspectives , author=. 2014 , eprint=
2014
-
[48]
2019 , eprint=
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations , author=. 2019 , eprint=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.