Prompts for Public-Sector LLMs Should Be Governed as Commons
Pith reviewed 2026-06-28 17:57 UTC · model grok-4.3
The pith
Prompts used to deploy LLMs in public settings should be treated as governed commons rather than private inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Prompts encode role instructions, decision framings, and value claims; prompt choice can materially shift outputs even when model weights and input records are held fixed. Existing governance tools rarely make the local prompt collections used in deployment transparent, contestable, or auditable. Prompts for public-sector LLMs should therefore be treated as governed artefacts through a versioned community repository.
What carries the argument
Prompt Commons: a versioned, community-maintained repository of prompt templates with provenance metadata, licensing, and moderation logs.
If this is right
- Local prompt collections become subject to provenance tracking and moderation logs.
- Governance states such as open, curated, and veto-enabled can be applied to prompt sets.
- Stakeholder prompts can be aggregated through negotiation-oriented ensemble methods into compromise recommendations.
- An evaluation agenda can test prompt-layer governance for accountability outcomes.
Where Pith is reading between the lines
- If adopted, prompt governance could create cross-agency libraries that reduce duplicated effort in similar public tasks.
- The approach might require new roles for prompt curators within government agencies.
- Testing could reveal whether moderation logs themselves become points of political contestation.
Load-bearing premise
Treating prompts as governed commons will produce net improvements in accountability and legitimacy without unacceptable losses in operational flexibility, security, or speed of government AI deployment.
What would settle it
A side-by-side audit of a public LLM deployment that logs whether prompt collections under Prompt Commons show higher rates of stakeholder review, documented changes, and acceptance compared with the same deployment using unversioned private prompts.
Figures
read the original abstract
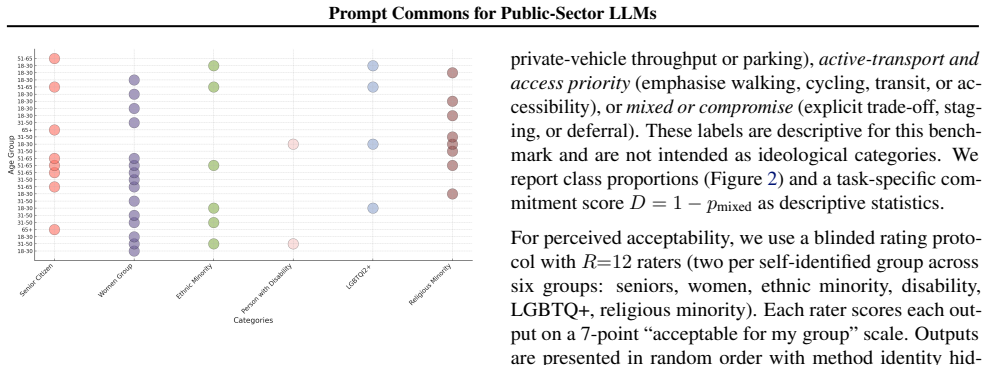
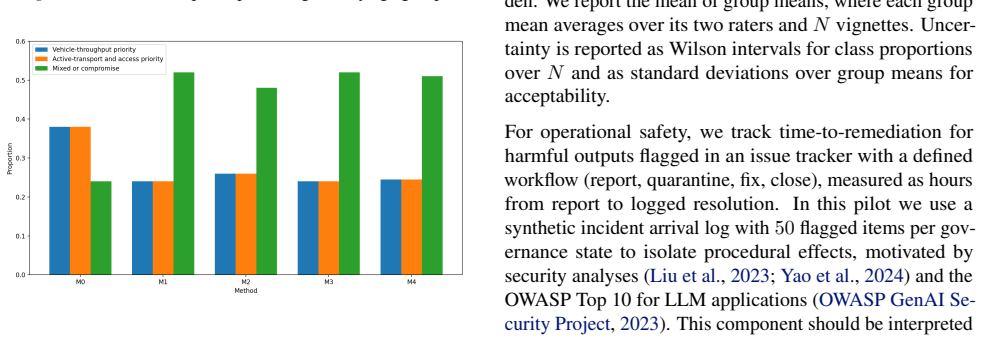
This paper argues that prompts used to deploy large language models (LLMs) in public-sector settings should be treated as governed artefacts rather than private, transient inputs. Prompts encode role instructions, decision framings, and value claims; prompt choice can materially shift outputs even when model weights and input records are held fixed. Existing governance tools, including model and dataset documentation, organisation-level policies, and post-training alignment, rarely make the local prompt collections used in deployment transparent, contestable, or auditable. We propose Prompt Commons: a versioned, community-maintained repository of prompt templates with provenance metadata, licensing, and moderation logs. Using a pilot dataset collected with community partners in a large North American city (443 human prompts; 3,317 after augmentation), we illustrate three governance states (open, curated, veto-enabled) and a negotiation-oriented ensemble method that aggregates stakeholder prompts into compromise recommendations. We close with falsifiable implications and an evaluation agenda for prompt-layer governance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prompts for public-sector LLMs encode role instructions, decision framings, and value claims that can materially shift outputs even with fixed model weights and inputs; existing governance tools rarely render local prompt collections transparent, contestable, or auditable. It proposes Prompt Commons as a versioned, community-maintained repository with provenance metadata, licensing, and moderation logs. Using a pilot of 443 human prompts (augmented to 3,317) collected with partners in a large North American city, the paper illustrates three governance states (open, curated, veto-enabled) and a negotiation-oriented ensemble method for aggregating stakeholder prompts. It closes with falsifiable implications and an evaluation agenda for prompt-layer governance.
Significance. If the proposal holds, governing prompts as commons could fill a documented gap in public-sector AI accountability by making prompt choices contestable and auditable beyond model cards or alignment techniques. The explicit provision of falsifiable implications and an evaluation agenda is a strength that supports empirical follow-up.
major comments (1)
- [Abstract] Abstract and pilot description: the 443-prompt pilot (augmented to 3,317) is presented only as illustrative of the three governance states and ensemble aggregator, with no quantitative measurements of approval-cycle time, adversarial leakage risk, deployment latency, or comparison to ad-hoc workflows. This leaves the central claim that Prompt Commons produces net accountability gains without unacceptable losses in flexibility or security untested and load-bearing for the proposal's practicality.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for recognizing the paper's provision of falsifiable implications and an evaluation agenda. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and pilot description: the 443-prompt pilot (augmented to 3,317) is presented only as illustrative of the three governance states and ensemble aggregator, with no quantitative measurements of approval-cycle time, adversarial leakage risk, deployment latency, or comparison to ad-hoc workflows. This leaves the central claim that Prompt Commons produces net accountability gains without unacceptable losses in flexibility or security untested and load-bearing for the proposal's practicality.
Authors: We agree that the pilot dataset is presented strictly as an illustration of the three governance states (open, curated, veto-enabled) and the negotiation-oriented ensemble method, rather than as an empirical evaluation. The abstract and manuscript explicitly frame the contribution as a governance proposal supported by a worked example, not as a controlled study measuring operational metrics such as approval-cycle time, leakage risk, or latency. The paper does not advance the claim that Prompt Commons has already been shown to deliver net accountability gains; instead, it articulates falsifiable implications and an explicit evaluation agenda for subsequent work. Because the manuscript is positioned as a conceptual and design contribution, we do not believe quantitative benchmarking of the pilot against ad-hoc workflows is required for the current argument. We are happy to clarify this framing further in a revision if the editor deems it necessary. revision: no
Circularity Check
No circularity: proposal contains no derivations or self-referential reductions
full rationale
The paper advances a normative governance proposal for treating public-sector prompts as commons. It contains no equations, fitted parameters, or mathematical derivations. The pilot dataset (443 prompts augmented to 3,317) is used only to illustrate three governance states and an ensemble method; the central claim that prompts should be governed as commons is not derived from or equivalent to any output of that dataset. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The argument rests on conceptual framing and falsifiable implications rather than any reduction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompt choice can materially shift LLM outputs independently of model weights and input records
invented entities (1)
-
Prompt Commons
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.1016/j.cities.2019.01.032. Bai, Y ., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKin- non, C., et al. Constitutional ai: Harmlessness from ai feedback,
-
[2]
Constitutional AI: Harmlessness from AI Feedback
URL https://arxiv.org/abs/ 2212.08073. Bang, Y ., Chen, D., Lee, N., and Fung, P. Measuring politi- cal bias in large language models: What is said and how it is said. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pp. 11142–11159, Bangkok, Thai- land,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
doi: 10.18653/v1/2024.acl-long.600
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.600. URL https: //aclanthology.org/2024.acl-long.600/. Bender, E. M., Gebru, T., McMillan-Major, A., and Shmitchell, S. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT...
-
[4]
Association for Computing Machinery. doi: 10.1145/3442188.3445922. URL https://dl.acm .org/doi/10.1145/3442188.3445922. BigCode Project. Bigcode openrail-m license agreement. https://www.bigcode-project.org/doc s/pages/bigcode-openrail/ ,
-
[5]
Brown, T
Accessed 2025-08-30. Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-V oss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McC...
2025
-
[6]
URL https://proceedings.neurips.cc/p aper_files/paper/2020/hash/1457c0d6b fcb4967418bfb8ac142f64a-Abstract.ht ml. Cao, Y . T., Domingo, L.-F., Gilbert, S., Mazurek, M. L., Shilton, K., and Daumé III, H. Toxicity detection is not all you need: Measuring the gaps to supporting volunteer content moderators through a user-centric method. InPro- ceedings of th...
2020
-
[7]
URL https://onlinelibrary.wiley
doi: 10.1111/ps 8 Prompt Commons for Public-Sector LLMs j.12212. URL https://onlinelibrary.wiley. com/doi/10.1111/psj.12212. Christiano, P. F., Leike, J., Brown, T. B., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems 30 (NeurIPS 2017), pp. 4299–4307, Long Beach, CA, USA,
work page doi:10.1111/ps 2017
-
[8]
URL https://proceedings.mlr.press/v235/c onitzer24a.html
PMLR. URL https://proceedings.mlr.press/v235/c onitzer24a.html. Contractor, D., McDuff, D., Haines, J. K., Lee, J., Hines, C., Hecht, B., Vincent, N., and Li, H. Behavioral use licensing for responsible AI. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’22, pp. 778–788, New York, NY , USA,
2022
-
[9]
Association for Computing Machinery. doi: 10.1145/3531146.3533143. URL https://dl.a cm.org/doi/10.1145/3531146.3533143 . Preprint first appeared as arXiv:2011.03116 in
-
[10]
Deed — attribution 4.0 international
Creative Commons. Deed — attribution 4.0 international. https://creativecommons.org/licenses /by/4.0/deed.en, 2013a. Accessed 2025-08-30. Creative Commons. Attribution 4.0 international (cc by 4.0) — legal code. https://creativecommons. org/licenses/by/4.0/legalcode.en , 2013b. Accessed 2025-08-30. Creative Commons. Choose a license for your work. http s:...
2025
-
[11]
Dulong de Rosnay, M
Accessed 2025-08-30. Dulong de Rosnay, M. and Stalder, F. Digital commons. Internet Policy Review, 9(4):1–22,
2025
-
[12]
Fulay, S., Brannon, W., Mohanty, S., Overney, C., Poole- Dayan, E., Roy, D., and Kabbara, J
doi: 10.14763/2 020.4.1530. Fulay, S., Brannon, W., Mohanty, S., Overney, C., Poole- Dayan, E., Roy, D., and Kabbara, J. On the relationship between truth and political bias in language models. In Proceedings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing, pp. 9004–9018, Miami, Florida, USA, November
work page doi:10.14763/2 2024
-
[13]
doi: 10.18653/v1/2024.e mnlp-main.508
Association for Computational Linguistics. doi: 10.18653/v1/2024.e mnlp-main.508. URL https://aclanthology.o rg/2024.emnlp-main.508/. Preprint available as arXiv:2409.05283. Gebru, T., Morgenstern, J., Vecchione, B., Vaughan, J. W., Wallach, H., Daumé III, H., and Crawford, K. Datasheets for datasets.Communications of the ACM, 64(12):86–92,
-
[14]
doi: 10.1145/3458723. Huang, L. T.-L., Papyshev, G., and Wong, J. K. Democ- ratizing value alignment: from authoritarian to demo- cratic ai ethics.AI and Ethics, 5:11–18,
-
[15]
URL https://li nk.springer.com/article/10.1007/s436 81-024-00624-1
doi: 10.1007/s43681-024-00624-1. URL https://li nk.springer.com/article/10.1007/s436 81-024-00624-1. ifrOSS. Open ai licenses — ifross license center. https: //ifross.github.io/ifrOSS/Pages/lice nce_center/openai/en,
-
[16]
and Bonato, N
Keller, P. and Bonato, N. The growth of responsible ai licensing. https://openfuture.eu/publicat ion/the-growth-of-responsible-ai-lic ensing/, 2023a. Accessed 2025-08-30. Keller, P. and Bonato, N. Growth of responsible ai licensing: Analysis of license use for ml models. https://op enfuture.pubpub.org/pub/growth-of-r esponsible-ai-licensing , 2023b. Acces...
2025
-
[17]
Liu, K., Yigitcanlar, T., Browne, W., and Fu, Y
URL https://arxi v.org/abs/2205.14529. Liu, K., Yigitcanlar, T., Browne, W., and Fu, Y . Prompts for planning-Ai integration: Effective prompt design for large language models in support of sustainable urban development. SSRN, June
-
[18]
URL https://ww w.sciencedirect.com/science/article/ abs/pii/S0004370221002058
doi: 10.1016/j.artint.2021.103654. URL https://ww w.sciencedirect.com/science/article/ abs/pii/S0004370221002058. Liu, Y ., Deng, G., Li, Y ., Wang, K., Wang, Z., Wang, X., Zhang, T., Liu, Y ., Wang, H., Zheng, Y ., Zhang, L. Y ., and Liu, Y . Prompt injection attack against LLM-integrated applications,
-
[19]
Prompt Injection attack against LLM-integrated Applications
URL https://arxiv.org/ab s/2306.05499. 9 Prompt Commons for Public-Sector LLMs McDuff, D., Korjakow, T., Cambo, S., Benjamin, J. J., Lee, J., Jernite, Y ., Muñoz Ferrandis, C., Gokaslan, A., Tarkowski, A., Lindley, J., Cooper, A. F., and Contractor, D. On the standardization of behavioral use clauses and their adoption for responsible licensing of ai,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
URL https://arxiv.org/abs/2402.05979. Mitchell, M., Wu, S., Zaldivar, A., Barnes, P., Vasser- man, L., Hutchinson, B., Spitzer, E., Raji, I. D., and Gebru, T. Model cards for model reporting. InPro- ceedings of the Conference on Fairness, Accountability, and Transparency (FAT*), pp. 220–229, Atlanta, GA, USA,
-
[21]
Association for Computing Machinery. doi: 10.1145/3287560.3287596. Mozilla Foundation. A practical framework for applying ostrom’s principles to data commons governance. ht tps://www.mozillafoundation.org/en/b log/a-practical-framework-for-applyin g-ostroms-principles-to-data-commons -governance/,
-
[22]
Muñoz Ferrandis, C
Accessed 2025-08-30. Muñoz Ferrandis, C. OpenRAIL: Towards open and re- sponsible AI licensing frameworks. Hugging Face Blog, August
2025
-
[23]
Accessed: 2025-08-30
URL https://huggingface.co/b log/open_rail. Accessed: 2025-08-30. O’Mahony, S. and Ferraro, F. The emergence of governance in an open source community.Academy of Management Journal, 50(5):1079–1106,
2025
-
[24]
Ostrom, E.Governing the Commons: The Evolution of Institutions for Collective Action
doi: 10.5465/amj.2007 .27169153. Ostrom, E.Governing the Commons: The Evolution of Institutions for Collective Action. Cambridge University Press, Cambridge, UK,
-
[25]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C
ISBN 978-0521405997. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P. F., Leike, J., and Lowe, R. Training language models to follow instructions with human feedback. InAdvances in Ne...
2022
-
[26]
OWASP GenAI Security Project
URLhttps://proceedings.neurip s.cc/paper_files/paper/2022/hash/b1e fde53be364a73914f58805a001731-Abstrac t-Conference.html. OWASP GenAI Security Project. Owasp top 10 for large language model applications (v1.1). https://owasp. org/www-project-top-10-for-large-lan guage-model-applications/ ,
2022
-
[27]
RAIL Initiative
Accessed 2025-08-30. RAIL Initiative. Responsible ai licenses (rail) — faq. ht tps://www.licenses.ai/faq ,
2025
-
[28]
Rajani, N
Accessed 2025-08-30. Rajani, N. F., McCann, B., Xiong, C., and Socher, R. Ex- plain yourself! leveraging language models for com- monsense reasoning. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4932–4942, Florence, Italy,
2025
-
[29]
Association for Computational Linguistics. doi: 10.18653/v1/P19-1487. URL https://aclanthology.org/P19-1487. pdf. Tabassum, M., Mackey, A., Schuett, A., and Lerner, A. In- vestigating moderation challenges to combating hate and harassment: The case of Mod-Admin power dynamics and feature misuse on reddit. In33rd USENIX Security Symposium (USENIX Security ...
-
[30]
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E
Accessed 2025-08-30. Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E. H., Le, Q., and Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems 35 (NeurIPS 2022), volume 35, pp. 24824–24837, New Orleans, LA, USA,
2025
-
[31]
Curran Associates, Inc. doi: 10.5555/3600270.3602070. URL https://procee dings.neurips.cc/paper_files/paper/2 022/file/9d5609613524ecf4f15af0f7b31 abca4-Paper-Conference.pdf. Weld, G., Leibmann, L., Zhang, A. X., and Althoff, T. Perceptions of moderators as a large-scale measure of online community governance,
-
[32]
URL https: //arxiv.org/abs/2401.16610. arXiv preprint. Xia, J., Tong, Y ., and Long, Y . Advancements in the application of large language models in urban studies: A systematic review.Cities, 165:106142,
-
[33]
Yigitcanlar, T., Agdas, D., and Degirmenci, K
URL https://arxiv.org/abs/2312.02003. Yigitcanlar, T., Agdas, D., and Degirmenci, K. Artificial intelligence in local governments: perceptions of city managers on prospects, constraints and choices.AI & Society, 38:1135–1150,
-
[34]
URL https://link.springer.com/ article/10.1007/s00146-022-01450-x
doi: 10.1007/s00146-022 10 Prompt Commons for Public-Sector LLMs -01450-x. URL https://link.springer.com/ article/10.1007/s00146-022-01450-x. Zhu, D. and Liu, H. City AI: a strategic framework for urban artificial intelligence application and development.Urban Informatics, 4,
-
[35]
URL https://link.springer.com/article/ 10.1007/s44212-025-00077-9
doi: 10.1007/s44212-025-00077-9. URL https://link.springer.com/article/ 10.1007/s44212-025-00077-9. 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.