Task diversity produces systematic transfer but inhibits continual reinforcement learning
Pith reviewed 2026-06-28 18:56 UTC · model grok-4.3
The pith
Task diversity produces quick transfer across single shifts but prevents sustained continual learning over many shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
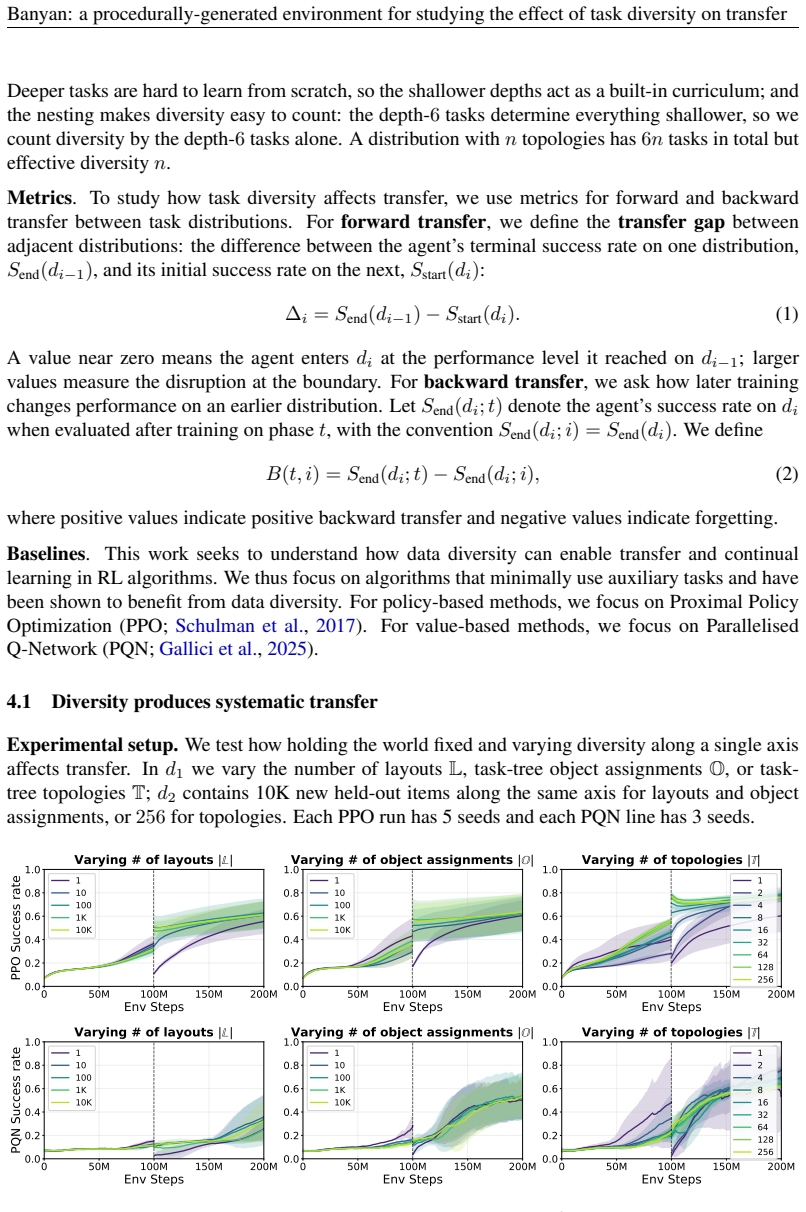
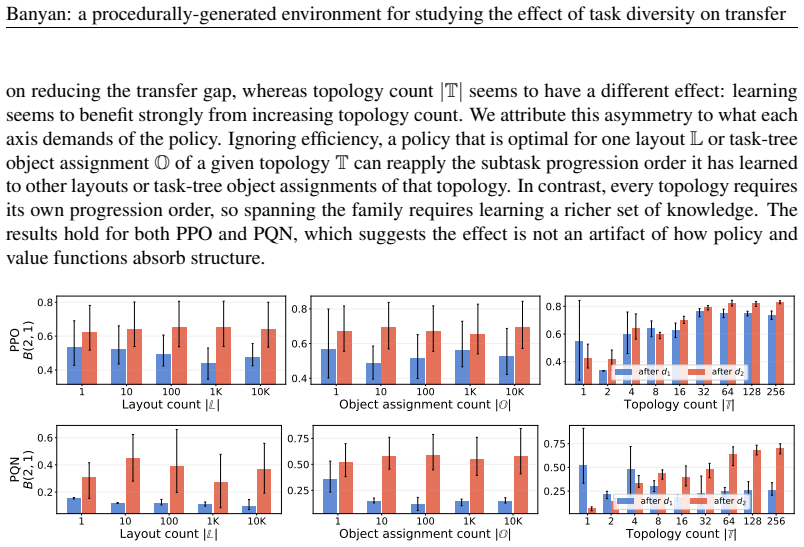
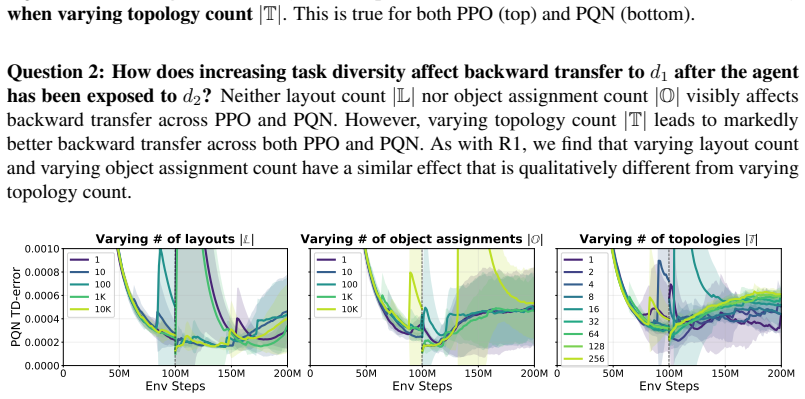
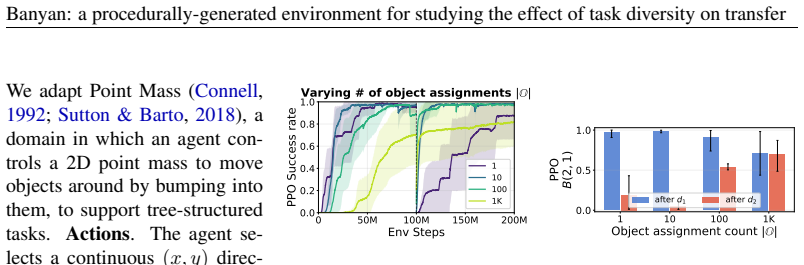
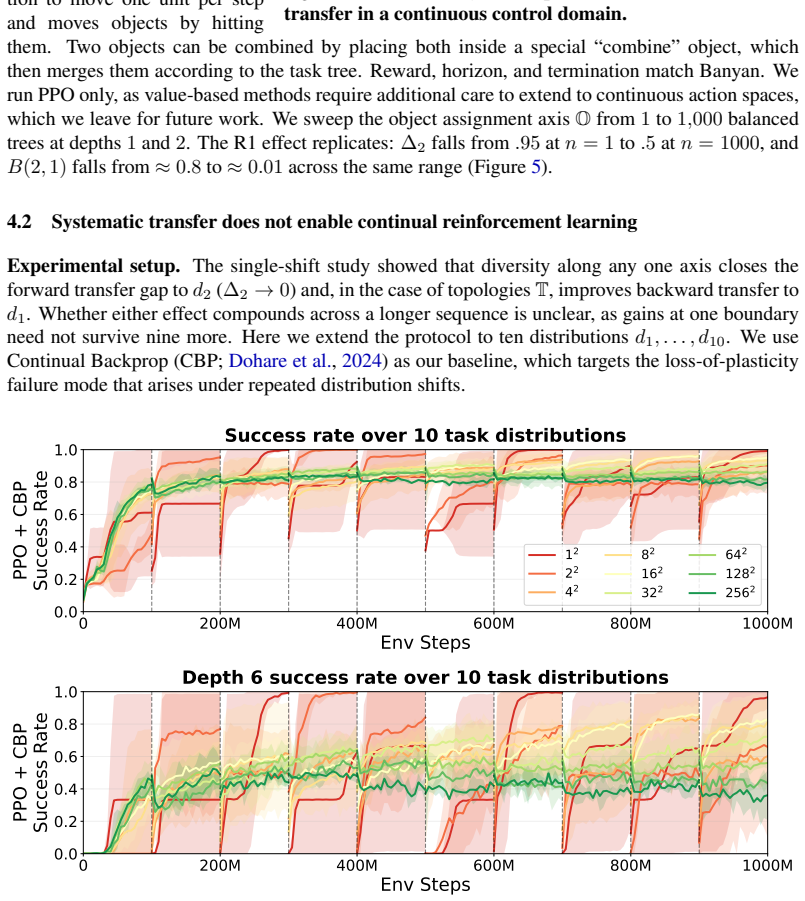
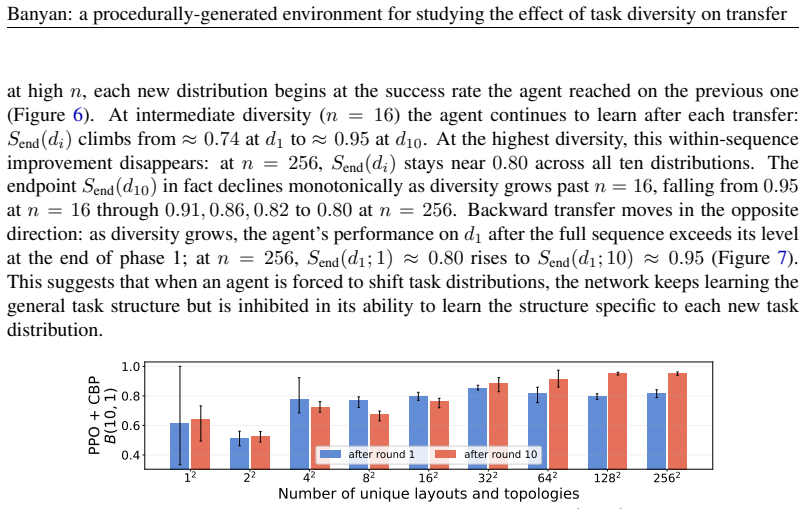
Across individual distribution shifts, increasing diversity along each axis causes agents to begin training on the new tasks near the performance attained on the previous one, even when the shift changes the structure of the optimal policy. However, as the number of shifts increases, this local transfer does not by itself yield sustained continual learning: longer-horizon tasks plateau, and earlier task distributions are forgotten after later training.
What carries the argument
The Banyan domain, in which task diversity factors into three independently controllable axes of map layouts, objects, and hierarchical subgoal structures.
If this is right
- Positive transfer occurs on each individual shift regardless of whether the shift alters optimal policy structure.
- Local transfer from diversity alone is insufficient to prevent forgetting when shifts accumulate.
- Performance plateaus appear specifically on longer-horizon tasks as shift count rises.
- Earlier task distributions are overwritten after training on later ones.
Where Pith is reading between the lines
- Continual RL methods may require explicit retention mechanisms in addition to diversity to avoid the observed forgetting.
- The three-axis structure supplies a controlled way to isolate which kind of variation most strongly drives transfer versus interference.
- Similar local-transfer-but-global-forgetting patterns could be tested by applying the same controlled diversity increases in other sequential decision domains.
Load-bearing premise
The three axes of diversity can be varied independently without introducing unintended correlations that affect the measured transfer.
What would settle it
An experiment in which agents trained across many successive shifts maintain or improve performance on all prior task distributions without plateaus on longer tasks.
Figures

read the original abstract
Continual reinforcement learning aims to produce agents that learn not only to improve at their current tasks but also to adapt as task distributions change. Training an agent on many diverse tasks can induce zero-shot generalization, but previous work generally evaluates this generalization after training -- with frozen weights. Whether task diversity also improves an agent's ability to continue learning across distribution shifts remains unclear. We introduce Banyan, a GPU-accelerated continual RL domain in which task diversity factors into three independently controllable axes: the map layouts an agent must navigate, the objects it must interact with, and the hierarchical structures of sub-goal dependencies. Across individual distribution shifts, increasing diversity along each axis causes agents to begin training on the new tasks near the performance attained on the previous one, even when the shift changes the structure of the optimal policy. However, as the number of shifts increases, this local transfer does not by itself yield sustained continual learning: longer-horizon tasks plateau, and earlier task distributions are forgotten after later training. Banyan is a benchmark for studying when controlled task diversity produces transferable learning, when that transfer persists, and where it falls short of proper continual learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Banyan, a GPU-accelerated continual RL domain in which task diversity factors into three axes (map layouts, objects, hierarchical subgoal structures). It reports that increasing diversity along each axis produces systematic transfer, with agents beginning new-task training near prior performance levels even when the shift alters optimal policy structure; however, as the number of distribution shifts grows, this local transfer fails to sustain continual learning, leading to plateaus on longer-horizon tasks and forgetting of earlier distributions.
Significance. If the reported patterns hold under controlled conditions, the work supplies concrete evidence that task diversity supports local transfer but does not by itself produce sustained continual RL, while introducing a benchmark domain with explicitly factored axes that can be used to isolate when transfer persists or breaks. The GPU acceleration and axis controllability are strengths for enabling reproducible experiments on these questions.
major comments (1)
- [Banyan domain description] Banyan domain description (abstract and §3): the claim that diversity 'factors into three independently controllable axes' is load-bearing for the central attribution that 'increasing diversity along each axis causes' the observed transfer. No domain equations, parameter tables, or explicit orthogonality controls (e.g., correlation matrices between map changes and subgoal depth) are referenced to confirm independence; if correlations exist, axis-specific causal claims cannot be isolated from the empirical results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the Banyan domain description. We address the major comment below and will revise the manuscript to strengthen the documentation of axis independence.
read point-by-point responses
-
Referee: [Banyan domain description] Banyan domain description (abstract and §3): the claim that diversity 'factors into three independently controllable axes' is load-bearing for the central attribution that 'increasing diversity along each axis causes' the observed transfer. No domain equations, parameter tables, or explicit orthogonality controls (e.g., correlation matrices between map changes and subgoal depth) are referenced to confirm independence; if correlations exist, axis-specific causal claims cannot be isolated from the empirical results.
Authors: We agree that explicit verification of axis independence is necessary to support the attribution of transfer effects to each axis separately. While §3 describes the three axes (map layouts, objects, and hierarchical subgoal structures) as independently controllable via distinct generation parameters, the manuscript does not include formal domain equations, a full parameter table, or quantitative orthogonality checks such as correlation matrices. In the revised version we will add: (1) explicit equations defining how each axis is sampled and varied, (2) a parameter table listing the ranges and sampling procedures, and (3) an analysis (including pairwise correlation statistics across generated tasks) confirming that variation along one axis produces negligible unintended changes in the others. These additions will allow readers to evaluate the degree of independence directly. revision: yes
Circularity Check
No circularity: empirical observations only
full rationale
The paper is an empirical study that introduces the Banyan domain and reports measured transfer and forgetting behaviors across controlled distribution shifts. No equations, fitted parameters, or closed-form predictions are presented whose outputs reduce to the inputs by construction. The central claims rest on experimental results rather than any self-definitional, self-citation load-bearing, or ansatz-smuggling steps. The domain description states that diversity factors into three axes, but this is a design premise, not a derivation that circularly re-derives its own measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of Markov decision processes and policy optimization in reinforcement learning hold in the Banyan domain.
invented entities (1)
-
Banyan domain
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A definition of continual reinforcement learning
David Abel, Andre Barreto, Benjamin Van Roy, Doina Precup, Hado van Hasselt, and Satinder Singh. A definition of continual reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=ZZS9WEWYbD
2023
-
[2]
Modular multitask reinforcement learning with policy sketches
Jacob Andreas, Dan Klein, and Sergey Levine. Modular multitask reinforcement learning with policy sketches. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML'17, pp.\ 166–175. JMLR.org, 2017
2017
-
[3]
The option-critic architecture
Pierre-Luc Bacon, Jean Harb, and Doina Precup. The option-critic architecture. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, AAAI'17, pp.\ 1726–1734. AAAI Press, 2017
2017
-
[4]
Systematic generalization: What is required and can it be learned? In International Conference on Learning Representations, 2019
Dzmitry Bahdanau, Shikhar Murty, Michael Noukhovitch, Thien Huu Nguyen, Harm de Vries, and Aaron Courville. Systematic generalization: What is required and can it be learned? In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=HkezXnA9YX
2019
-
[5]
Hunt, Tom Schaul, Hado van Hasselt, and David Silver
Andr\' e Barreto, Will Dabney, R\' e mi Munos, Jonathan J. Hunt, Tom Schaul, Hado van Hasselt, and David Silver. Successor features for transfer in reinforcement learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS'17, pp.\ 4058–4068, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964
2017
-
[6]
Human-timescale adaptation in an open-ended task space
Jakob Bauer, Kate Baumli, Feryal Behbahani, Avishkar Bhoopchand, Nathalie Bradley-Schmieg, Michael Chang, Natalie Clay, Adrian Collister, Vibhavari Dasagi, Lucy Gonzalez, Karol Gregor, Edward Hughes, Sheleem Kashem, Maria Loks-Thompson, Hannah Openshaw, Jack Parker-Holder, Shreya Pathak, Nicolas Perez-Nieves, Nemanja Rakicevic, Tim Rockt\" a schel, Yannic...
2023
-
[7]
Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo De Lazcano Perez-Vicente, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and J K Terry. Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchma...
2023
-
[8]
Quantifying generalization in reinforcement learning
Karl Cobbe, Oleg Klimov, Chris Hesse, Taehoon Kim, and John Schulman. Quantifying generalization in reinforcement learning. In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp.\ 1282--1289. PMLR, 09--15 Jun 2019. URL https://p...
2019
-
[9]
Leveraging procedural generation to benchmark reinforcement learning
Karl Cobbe, Christopher Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. In Proceedings of the 37th International Conference on Machine Learning, ICML'20. JMLR.org, 2020
2020
-
[10]
Jonathan H. Connell. SSS : A hybrid architecture applied to robot navigation. In Proceedings of the IEEE International Conference on Robotics and Automation ( ICRA ) , pp.\ 2719--2724, 1992
1992
-
[11]
Dietterich
Thomas G. Dietterich. Hierarchical reinforcement learning with the maxq value function decomposition. J. Artif. Int. Res., 13 0 (1): 0 227–303, November 2000. ISSN 1076-9757
2000
-
[12]
Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A
Shibhansh Dohare, J. Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A. Rupam Mahmood, and Richard S. Sutton. Loss of plasticity in deep continual learning. Nature, 632: 0 768--774, 2024. doi:10.1038/s41586-024-07711-7
-
[13]
Model-agnostic meta-learning for fast adaptation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML'17, pp.\ 1126–1135. JMLR.org, 2017
2017
-
[14]
Jerry A. Fodor and Zenon W. Pylyshyn. Connectionism and cognitive architecture: A critical analysis. Cognition, 28 0 (1): 0 3--71, 1988. ISSN 0010-0277. doi:https://doi.org/10.1016/0010-0277(88)90031-5. URL https://www.sciencedirect.com/science/article/pii/0010027788900315
-
[15]
Simplifying deep temporal difference learning
Matteo Gallici, Mattie Fellows, Benjamin Ellis, Bartomeu Pou, Ivan Masmitja, Jakob Nicolaus Foerster, and Mario Martin. Simplifying deep temporal difference learning. The International Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/2407.04811
-
[16]
Environmental drivers of systematicity and generalization in a situated agent
Felix Hill, Andrew Lampinen, Rosalia Schneider, Stephen Clark, Matthew Botvinick, James L McClelland, and Adam Santoro. Environmental drivers of systematicity and generalization in a situated agent. arXiv preprint arXiv:1910.00571, 2019
-
[17]
Cross-environment cooperation enables zero-shot multi-agent coordination
Kunal Jha, Wilka Carvalho, Yancheng Liang, Simon Shaolei Du, Max Kleiman-Weiner, and Natasha Jaques. Cross-environment cooperation enables zero-shot multi-agent coordination. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=zBBYsVGKuB
2025
-
[18]
Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks
Brenden M Lake and Marco Baroni. Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks. 2017
2017
-
[19]
Human-like systematic generalization through a meta-learning neural network
Brenden M Lake and Marco Baroni. Human-like systematic generalization through a meta-learning neural network. Nature, 623 0 (7985): 0 115--121, 2023
2023
-
[20]
Craftax: a lightning-fast benchmark for open-ended reinforcement learning
Michael Matthews, Michael Beukman, Benjamin Ellis, Mikayel Samvelyan, Matthew Jackson, Samuel Coward, and Jakob Foerster. Craftax: a lightning-fast benchmark for open-ended reinforcement learning. In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org, 2024
2024
- [21]
-
[22]
Jorge A. Mendez and Eric Eaton. Lifelong learning of compositional structures. CoRR, abs/2007.07732, 2020. URL https://arxiv.org/abs/2007.07732
-
[23]
A boolean task algebra for reinforcement learning
Geraud Nangue Tasse, Steven James, and Benjamin Rosman. A boolean task algebra for reinforcement learning. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (eds.), Advances in Neural Information Processing Systems, volume 33, pp.\ 9497--9507. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/6ba...
2020
-
[24]
XL and-minigrid: Scalable meta-reinforcement learning environments in JAX
Alexander Nikulin, Vladislav Kurenkov, Ilya Zisman, Artem Sergeevich Agarkov, Viacheslav Sinii, and Sergey Kolesnikov. XL and-minigrid: Scalable meta-reinforcement learning environments in JAX . In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URL https://openreview.net/forum?id=zg8dpAGl1I
2024
-
[25]
Solving Rubik's Cube with a Robot Hand
OpenAI, Ilge Akkaya, Marcin Andrychowicz, Maciek Chociej, Mateusz Litwin, Bob McGrew, Arthur Petron, Alex Paino, Matthias Plappert, Glenn Powell, Raphael Ribas, Jonas Schneider, Nikolas Tezak, Jerry Tworek, Peter Welinder, Lilian Weng, Qiming Yuan, Wojciech Zaremba, and Lei Zhang. Solving rubik's cube with a robot hand, 2019. URL https://arxiv.org/abs/1910.07113
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[26]
Sim-to-real transfer of robotic control with dynamics randomization
Xue Bin Peng, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pp.\ 3803--3810, 2018. doi:10.1109/ICRA.2018.8460528
-
[27]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, 2nd edition, 2018
2018
-
[29]
Sutton, Doina Precup, and Satinder Singh
Richard S. Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: a framework for temporal abstraction in reinforcement learning. Artif. Intell., 112 0 (1–2): 0 181–211, August 1999. ISSN 0004-3702. doi:10.1016/S0004-3702(99)00052-1. URL https://doi.org/10.1016/S0004-3702(99)00052-1
-
[30]
Investigating multi-task pretraining and generalization in reinforcement learning
Adrien Ali Taiga, Rishabh Agarwal, Jesse Farebrother, Aaron Courville, and Marc G Bellemare. Investigating multi-task pretraining and generalization in reinforcement learning. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=sSt9fROSZRO
2023
-
[31]
Open-ended learning leads to generally capable agents, 2021
Open Ended Learning Team, Adam Stooke, Anuj Mahajan, Catarina Barros, Charlie Deck, Jakob Bauer, Jakub Sygnowski, Maja Trebacz, Max Jaderberg, Michael Mathieu, Nat McAleese, Nathalie Bradley-Schmieg, Nathaniel Wong, Nicolas Porcel, Roberta Raileanu, Steph Hughes-Fitt, Valentin Dalibard, and Wojciech Marian Czarnecki. Open-ended learning leads to generally...
-
[32]
Distral: robust multitask reinforcement learning
Yee Whye Teh, Victor Bapst, Wojciech Marian Czarnecki, John Quan, James Kirkpatrick, Raia Hadsell, Nicolas Heess, and Razvan Pascanu. Distral: robust multitask reinforcement learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS'17, pp.\ 4499–4509, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9...
2017
-
[33]
Domain randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp.\ 23--30, 2017. doi:10.1109/IROS.2017.8202133
-
[34]
COOM : A game benchmark for continual reinforcement learning
Tristan Tomilin, Meng Fang, Yudi Zhang, and Mykola Pechenizkiy. COOM : A game benchmark for continual reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://openreview.net/forum?id=qmCxdPkNsa
2023
-
[35]
MEAL : A benchmark for continual multi-agent reinforcement learning, 2026
Tristan Tomilin, Luka van den Boogaard, Samuel Garcin, Constantin Ruhdorfer, Bram Grooten, Yali Du, Andreas Bulling, Mykola Pechenizkiy, and Meng Fang. MEAL : A benchmark for continual multi-agent reinforcement learning, 2026. URL https://openreview.net/forum?id=I3W8PynQU0
2026
-
[36]
Continual world: A robotic benchmark for continual reinforcement learning
Maciej Wolczyk, Micha Zaj a c, Razvan Pascanu, ukasz Kuci \'n ski, and Piotr Mi o \'s . Continual world: A robotic benchmark for continual reinforcement learning. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan (eds.), Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=5qsptDcsdEj
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.