Dive into Waves: Morlet Spectral Transformer for Cross-Subject Emotion Decoding from EEG
Pith reviewed 2026-06-28 18:54 UTC · model grok-4.3
The pith
The Morlet Spectral Transformer outperforms large pretrained EEG models in cross-subject emotion recognition without pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
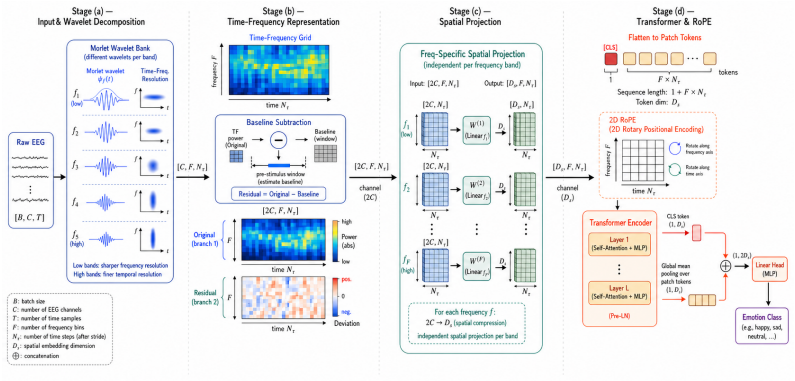
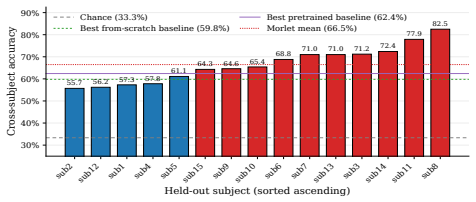
The Morlet Spectral Transformer integrates Morlet wavelet tokenization that extends differential entropy into a time-frequency form suitable for Transformers, long-context baseline removal that normalizes out subject-specific drift and redundancy, and frequency-specific spatial projection that learns independent channel mixers per band. These elements are placed inside a spatiotemporal Transformer backbone. The resulting model consistently exceeds both large pretrained EEG foundation models and prior frequency-based methods on every SEED-family dataset for cross-subject emotion recognition, even when trained from scratch.
What carries the argument
Morlet wavelet tokenization paired with long-context baseline removal and frequency-specific spatial projection inside a Transformer backbone.
If this is right
- Careful spectral representation design can serve as an accurate, cost-effective alternative to large-scale pretraining for EEG tasks.
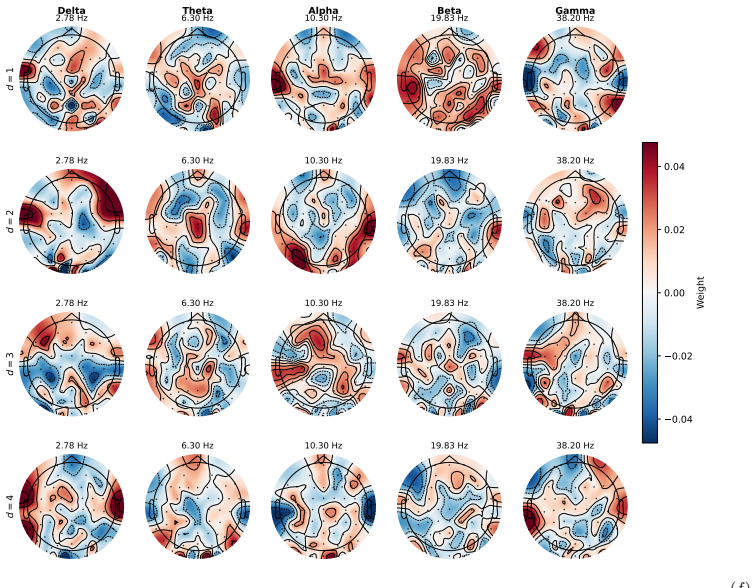
- The frequency-specific spatial projection yields interpretable band-specific patterns that reduce unwanted cross-channel mixing.
- Long-context baseline removal provides a simple normalization that improves generalization by removing subject drift across windows.
- The overall approach is particularly suited to signals whose information lies in spectral power rather than clear waveform signatures.
Where Pith is reading between the lines
- The same tokenization and normalization steps could be tested on other EEG tasks that rely on spectral rather than temporal signatures.
- The emphasis on matching multi-scale rhythms suggests similar wavelet-based tokenization might help in other noisy, multi-scale biosignal problems.
- If the baseline removal step generalizes, it could become a standard preprocessing choice for handling inter-subject variability in neural recordings.
Load-bearing premise
The reported gains come from the three proposed components rather than the shared Transformer backbone or characteristics of the SEED datasets.
What would settle it
An ablation study that removes each of the three components one at a time and checks whether accuracy falls to or below the level of the pretrained baselines or standard frequency methods.
Figures

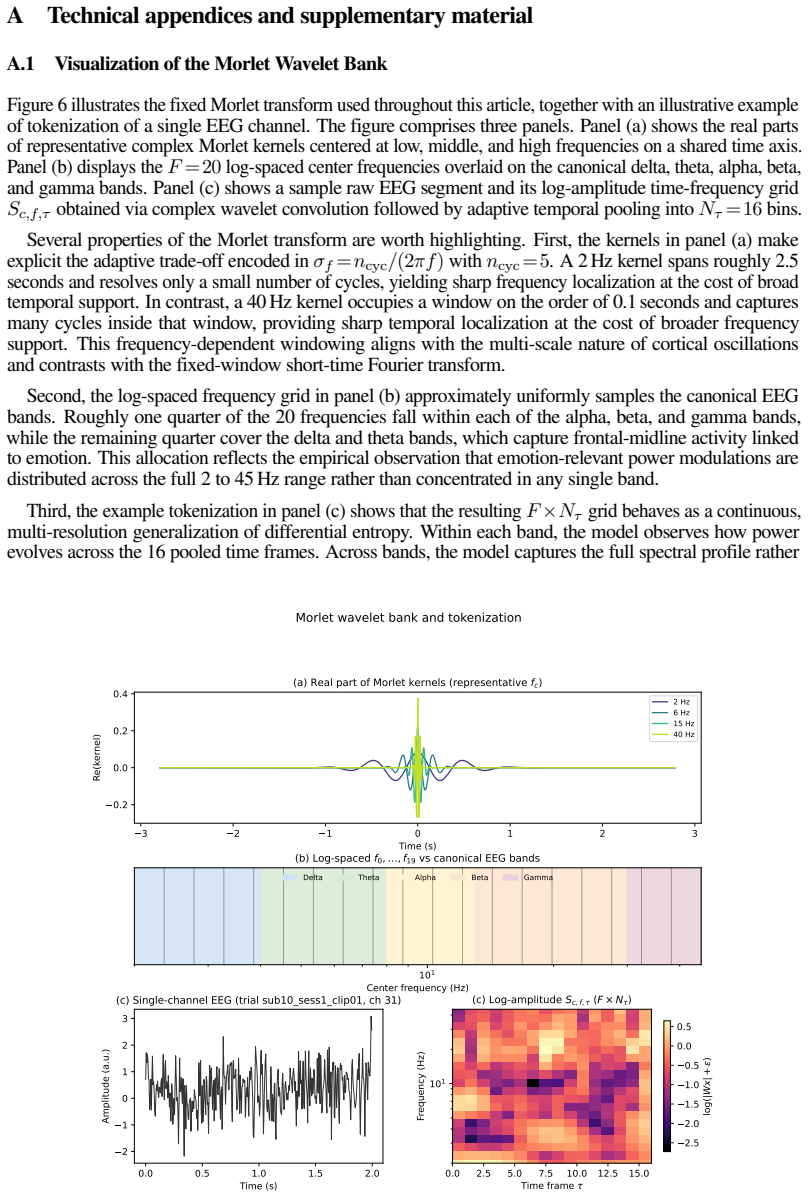
read the original abstract
We study cross-subject emotion recognition from EEG, a practically important yet challenging problem in brain-computer interfaces. Unlike tasks with clear waveform signatures, emotion-related EEG signals are primarily encoded in spectral power and are weak, noisy, and highly variable across subjects. Existing approaches rely either on large pretrained EEG foundation models, which require massive data yet still struggle with cross-subject variability, or frequency-domain encoders, which better reflect spectral structure but suffer from mismatched representations, drift-dominated tokenization, and lack of band-specific spatial modeling. In this article, we propose the Morlet Spectral Transformer (MST), built around three key components and integrated with a spatiotemporal Transformer backbone. First, Morlet wavelet tokenization provides a time-frequency representation that matches the multi-scale structure of brain rhythms, and extends classical differential entropy features to a form suitable for Transformers. Second, long-context baseline removal acts as a simple temporal normalization that removes subject-specific drift and redundancy across nearby windows. Third, frequency-specific spatial projection learns a separate channel mixer for each frequency band, capturing interpretable band-specific patterns and reducing cross-channel mixing. We show that, even without pretraining, MST consistently outperforms both large pretrained EEG foundation models and frequency-based methods across all SEED-family datasets. These results suggest that careful representation design can yield an accurate, cost-effective, and interpretable alternative to large-scale pretraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Morlet Spectral Transformer (MST) for cross-subject EEG-based emotion recognition. It integrates a spatiotemporal Transformer backbone with three components: Morlet wavelet tokenization to produce time-frequency representations matching brain rhythms (extending differential entropy), long-context baseline removal as temporal normalization to reduce subject-specific drift, and frequency-specific spatial projection to learn band-wise channel mixers. The central empirical claim is that MST, even without pretraining, consistently outperforms both large pretrained EEG foundation models and existing frequency-based methods across SEED-family datasets.
Significance. If the performance gains can be rigorously attributed to the proposed components rather than the Transformer backbone or dataset artifacts, the work would support the value of domain-specific representation design over scale in EEG decoding tasks, providing a lower-cost, more interpretable alternative to foundation-model pretraining for cross-subject generalization.
major comments (2)
- [Results / Experiments (section containing the main tables and comparisons)] The central claim that the three components (Morlet tokenization, long-context baseline removal, frequency-specific spatial projection) drive the reported gains requires controlled ablations; no such experiments (e.g., replacing Morlet with standard DE/FFT features, removing baseline correction, or using a shared spatial mixer) are described that would show corresponding performance drops when these elements are ablated.
- [Abstract and Results section] The abstract and results presentation supply no statistical tests, error bars, dataset splits, or subject-wise variance measures to support the claim of 'consistent outperformance' across SEED-family datasets; without these, the strength of the empirical comparison cannot be evaluated.
minor comments (2)
- [Method section] Notation for the Morlet wavelet parameters and the exact formulation of the long-context baseline removal should be made explicit with equations to allow reproduction.
- [Figures] Figure captions for any architecture or tokenization diagrams should explicitly label the three proposed components and their integration with the Transformer backbone.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects for strengthening the empirical claims. We agree that both controlled ablations and statistical reporting are needed to rigorously support the contribution of the proposed components and will add these elements to the revised manuscript.
read point-by-point responses
-
Referee: [Results / Experiments (section containing the main tables and comparisons)] The central claim that the three components (Morlet tokenization, long-context baseline removal, frequency-specific spatial projection) drive the reported gains requires controlled ablations; no such experiments (e.g., replacing Morlet with standard DE/FFT features, removing baseline correction, or using a shared spatial mixer) are described that would show corresponding performance drops when these elements are ablated.
Authors: We agree that the absence of component-specific ablations limits the ability to attribute gains specifically to Morlet tokenization, long-context baseline removal, and frequency-specific spatial projection rather than the Transformer backbone alone. In the revised manuscript we will add a dedicated ablation study section that systematically replaces each component (Morlet with standard DE/FFT, removal of baseline correction, and replacement of per-band spatial mixers with a shared mixer) and reports the resulting performance drops on the SEED-family datasets. These experiments will be presented alongside the main results tables. revision: yes
-
Referee: [Abstract and Results section] The abstract and results presentation supply no statistical tests, error bars, dataset splits, or subject-wise variance measures to support the claim of 'consistent outperformance' across SEED-family datasets; without these, the strength of the empirical comparison cannot be evaluated.
Authors: We acknowledge that the current presentation lacks statistical tests, error bars, explicit dataset splits, and subject-wise variance, which weakens the evaluation of the 'consistent outperformance' claim. In the revision we will (i) report mean and standard deviation across multiple random seeds and cross-subject folds, (ii) include paired statistical tests (e.g., Wilcoxon signed-rank) with p-values against baselines, (iii) specify the exact train/validation/test subject splits used, and (iv) add subject-wise performance variance measures. These will appear in both the abstract (concise summary) and the results section tables/figures. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The paper introduces the MST architecture with three described components (Morlet wavelet tokenization, long-context baseline removal, frequency-specific spatial projection) integrated into a Transformer backbone, then reports empirical outperformance on SEED-family datasets without pretraining. No equations, derivations, or self-citations appear that reduce any claimed result to its inputs by construction, nor any fitted parameters renamed as predictions, ansatzes smuggled via citation, or uniqueness theorems. Performance attribution is presented via direct experimental comparison to baselines, making the chain self-contained against external data rather than internally tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Filter bank common spatial pattern (FBCSP) in brain-computer interface
Kai Keng Ang, Zheng Y ang Chin, Haihong Zhang, and Cuntai Guan. Filter bank common spatial pattern (FBCSP) in brain-computer interface. In2008 IEEE International Joint Conference on Neural Networks, pages 2390–2397. IEEE, 2008
2008
-
[2]
MIT Press, 2014
Mike X Cohen.Analyzing Neural Time Series Data: Theory and Practice. MIT Press, 2014
2014
-
[3]
Cover and Joy A
Thomas M. Cover and Joy A. Thomas.Elements of Information Theory. Wiley-Interscience, 2 edition, 2006
2006
-
[4]
Differential entropy feature for EEG-based emotion recognition
Ruo-Nan Duan, Jia-Yi Zhu, and Bao-Liang Lu. Differential entropy feature for EEG-based emotion recognition. In6th International IEEE/EMBS Conference on Neural Engineering (NER), pages 81–84. IEEE, 2013
2013
-
[5]
Evgenia Gkintoni, Anthimos Aroutzidis, Hera Antonopoulou, and Constantinos Halkiopoulos. From neural networks to emotional networks: A systematic review of eeg-based emotion recognition in cognitive neuroscience and real-world applications.Brain Sciences, 15(3):220, 2025. doi: 10.3390/brainsci15030220
-
[6]
SEED-VII: A multimodal dataset of six basic emotions with continuous labels for emotion recognition.IEEE Transactions on Affective Computing, 2024
Wei-Bang Jiang, Xuan-Hao Liu, Wei-Long Zheng, and Bao-Liang Lu. SEED-VII: A multimodal dataset of six basic emotions with continuous labels for emotion recognition.IEEE Transactions on Affective Computing, 2024
2024
-
[7]
Large brain model for learning generic representa- tions with tremendous EEG data in BCI
Wei-Bang Jiang, Li-Ming Zhao, and Bao-Liang Lu. Large brain model for learning generic representa- tions with tremendous EEG data in BCI. InInternational Conference on Learning Representations, 2024
2024
-
[8]
EEG alpha and theta oscillations reflect cognitive and memory performance: a review and analysis.Brain Research Reviews, 29(2-3):169–195, 1999
Wolfgang Klimesch. EEG alpha and theta oscillations reflect cognitive and memory performance: a review and analysis.Brain Research Reviews, 29(2-3):169–195, 1999
1999
-
[9]
DEAP: A database for emotion analysis using physiological signals.IEEE Transactions on Affective Computing, 3(1):18–31, 2012
Sander Koelstra, Christian Mühl, Mohammad Soleymani, Jong-Seok Lee, Ashkan Y azdani, Touradj Ebrahimi, Thierry Pun, Anton Nijholt, and Ioannis Patras. DEAP: A database for emotion analysis using physiological signals.IEEE Transactions on Affective Computing, 3(1):18–31, 2012
2012
-
[10]
Journal of Neural Engineering15(5), 056013 (2018).https: //doi.org/10.1088/1741-2552/aace8c
V ernon J. Lawhern, Amelia J. Solon, Nicholas R. Waytowich, Stephen M. Gordon, Chou P . Hung, and Brent J. Lance. EEGNet: A compact convolutional neural network for EEG-based brain-computer interfaces.Journal of Neural Engineering, 15(5):056013, 2018. doi: 10.1088/1741-2552/aace8c
-
[11]
Multisource transfer learning for cross-subject EEG emotion recognition.IEEE Transactions on Cybernetics, 50(7):3281–3293, 2020
Jinpeng Li, Shuang Qiu, Changde Du, Yixin Wang, and Huiguang He. Multisource transfer learning for cross-subject EEG emotion recognition.IEEE Transactions on Cybernetics, 50(7):3281–3293, 2020
2020
-
[12]
Domain adaptation for EEG emotion recognition based on latent representation similarity.IEEE Transactions on Cognitive and Developmental Systems, 12(2):344–353, 2020
Jinpeng Li, Shuang Qiu, Y uan-Y uan Shen, Cheng-Lin Liu, and Huiguang He. Domain adaptation for EEG emotion recognition based on latent representation similarity.IEEE Transactions on Cognitive and Developmental Systems, 12(2):344–353, 2020
2020
-
[13]
Dingkun Liu, Y uheng Chen, Zhu Chen, Zhenyao Cui, Y aozhi Wen, Jiayu An, Jingwei Luo, and Dongrui Wu. EEG foundation models: Progresses, benchmarking, and open problems.arXiv preprint arXiv:2601.17883, 2025
-
[14]
Tokenizing single-channel EEG with time-frequency motif learning
Jiarui Liu et al. Tokenizing single-channel EEG with time-frequency motif learning. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[15]
Wei Liu, Jie-Lin Qiu, Wei-Long Zheng, and Bao-Liang Lu. Comparing recognition performance and robustness of multimodal deep learning models for multimodal emotion recognition.IEEE Transactions on Cognitive and Developmental Systems, 14(2):715–729, 2022
2022
- [16]
-
[17]
Unnikrishna Pillai.Probability, Random V ariables, and Stochastic Processes
Athanasios Papoulis and S. Unnikrishna Pillai.Probability, Random V ariables, and Stochastic Processes. McGraw-Hill, 4 edition, 2002
2002
-
[18]
Stephen O. Rice. Mathematical analysis of random noise.The Bell System T echnical Journal, 23 (3):282–332, 1944. 10
1944
-
[19]
EEG conformer: Convolutional transformer for EEG decoding and visualization.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 31:710–719, 2023
Y onghao Song, Qingqing Zheng, Bingchuan Liu, and Xiaorong Gao. EEG conformer: Convolutional transformer for EEG decoding and visualization.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 31:710–719, 2023
2023
-
[20]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Y u Lu, Shengfeng Pan, Wen Bo, and Y unfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[21]
Oscillatory gamma-band (30–70 Hz) activity induced by a visual search task in humans.Journal of Neuroscience, 17(2):722–734, 1997
Catherine Tallon-Baudry, Olivier Bertrand, Claude Delpuech, and Jacques Pernier. Oscillatory gamma-band (30–70 Hz) activity induced by a visual search task in humans.Journal of Neuroscience, 17(2):722–734, 1997
1997
-
[22]
Attention is all you need
Ashish V aswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[23]
BrainBERT: Self-supervised representation learning for intracranial recordings
Christopher Wang, Vighnesh Subramaniam, Adam Uri Y aari, Gabriel Kreiman, Boris Katz, Ignacio Cases, and Andrei Barbu. BrainBERT: Self-supervised representation learning for intracranial recordings. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[24]
EEGPT: Pretrained transformer for universal and reliable representation of EEG signals
Guangyu Wang, Wenchao Liu, Y uhong He, Cong Xu, Lin Ma, and Haifeng Li. EEGPT: Pretrained transformer for universal and reliable representation of EEG signals. InAdvances in Neural Information Processing Systems, volume 37, 2024
2024
-
[25]
CBraMod: A criss-cross brain foundation model for EEG decoding
Jiquan Wang, Sha Zhao, Zhiling Luo, Y angxuan Zhou, Haiteng Jiang, Shijian Li, Tao Li, and Gang Pan. CBraMod: A criss-cross brain foundation model for EEG decoding. InInternational Conference on Learning Representations, 2025
2025
-
[26]
Brandon Westover, and Jimeng Sun
Chaoqi Y ang, M. Brandon Westover, and Jimeng Sun. BIOT: Biosignal transformer for cross-data learning in the wild. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[27]
CodeBrain: Bridging Decoupled Tokenizer and Multi-Scale Architecture for EEG Foundation Model
Jiahe Zhang et al. CodeBrain: Bridging decoupled tokenizer and multi-scale architecture for EEG foundation model.arXiv preprint arXiv:2506.09110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Wei-Long Zheng and Bao-Liang Lu. Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks.IEEE Transactions on Autonomous Mental Development, 7(3):162–175, 2015
2015
-
[29]
EmotionMeter: A multimodal framework for recognizing human emotions.IEEE Transactions on Cybernetics, 49(3):1110–1122, 2018
Wei-Long Zheng, Wei Liu, Yifei Lu, Bao-Liang Lu, and Andrzej Cichocki. EmotionMeter: A multimodal framework for recognizing human emotions.IEEE Transactions on Cybernetics, 49(3):1110–1122, 2018
2018
-
[30]
CSBrain: A cross-scale spatiotemporal brain foundation model for EEG decoding
Y uchen Zhou, Jiamin Wu, Zichen Ren, Zhouheng Y ao, Weiheng Lu, Kunyu Peng, Qihao Zheng, Chunfeng Song, Wanli Ouyang, and Chao Gou. CSBrain: A cross-scale spatiotemporal brain foundation model for EEG decoding. InAdvances in Neural Information Processing Systems, volume 38, 2025. 11 A T echnical appendices and supplementary material A.1 Visualization of t...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.