Memory-Efficient LLM Training with Dynamic Sparsity: From Stability to Practical Scaling
Pith reviewed 2026-06-28 18:52 UTC · model grok-4.3
The pith
SMET stabilizes dynamic sparse training for LLMs by fixing cold-start updates for new parameters with warm-up and density-aware scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
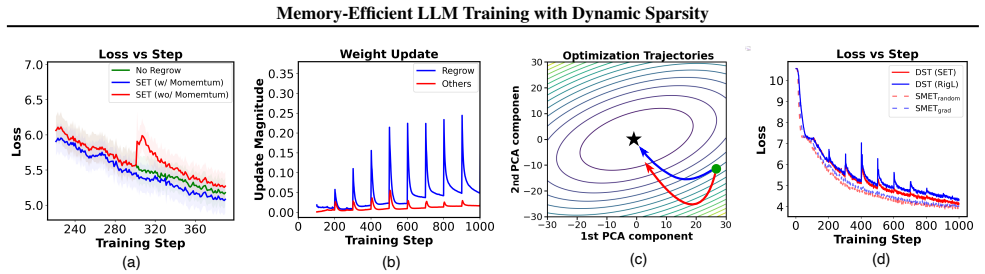
The authors show that the cold-start issue for newly regrown parameters under standard Adam leads to optimization instability in DST for LLMs, and that SMET, which incorporates optimizer warm-up and density-aware learning-rate scaling while storing states only for active parameters, resolves this and enables stable sparse pre-training.
What carries the argument
SMET's optimizer warm-up combined with density-aware learning-rate scaling, which prevents large disruptive updates to new parameters during topology changes in dynamic sparse training.
If this is right
- Stable training without loss spikes after each sparsity update in LLM pre-training.
- Reduced memory footprint by maintaining gradients and optimizer states only for currently active parameters.
- Scalable application to larger models that would otherwise exceed memory limits in dense training.
- Comparable or better final model quality compared to dense baselines under the stabilized regime.
Where Pith is reading between the lines
- Applying SMET could extend to other sparse training methods beyond DST if the cold-start is the dominant issue.
- Memory savings might enable training on hardware with limited VRAM, broadening access to LLM development.
- The density-aware scaling rule may need adjustment when sparsity schedules differ from those tested.
Load-bearing premise
The instability in dynamic sparse training of LLMs is caused specifically by the cold-start issue of newly regrown parameters under standard Adam, and that warm-up plus density-aware scaling will fix it without introducing new instabilities or reducing final quality.
What would settle it
Running the same LLM pre-training experiment with and without the warm-up and density-aware components of SMET and checking if loss spikes after topology updates disappear only when both are present.
Figures
read the original abstract
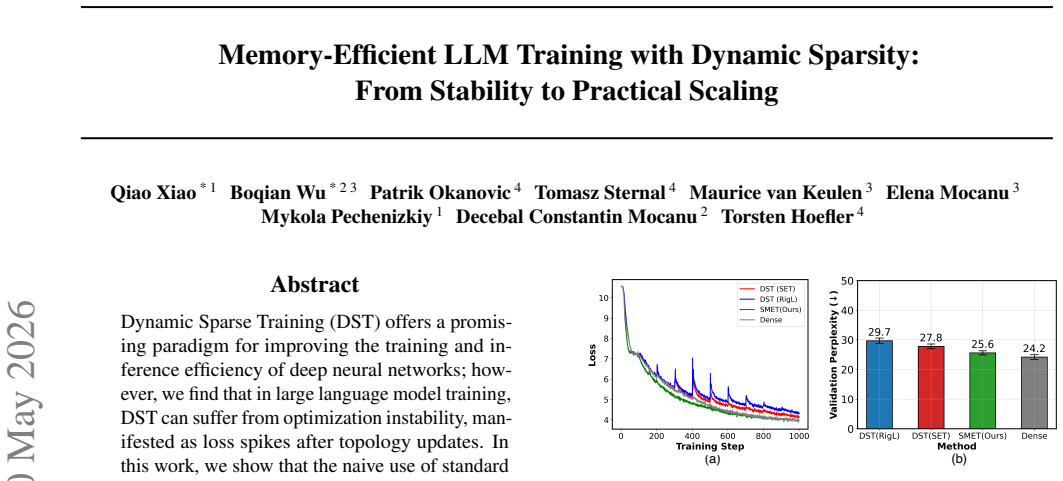
Dynamic Sparse Training (DST) offers a promising paradigm for improving the training and inference efficiency of deep neural networks; however, we find that in large language model training, DST can suffer from optimization instability, manifested as loss spikes after topology updates. In this work, we show that the naive use of standard Adam-based optimizers leads to a cold-start issue for newly regrown parameters, resulting in excessively large updates and disrupted training dynamics. To address this issue, we propose Sparse Memory-Efficient Training (SMET), which stabilizes DST with optimizer warm-up and improves training progress through density-aware learning-rate scaling. SMET further reduces memory consumption by storing gradients and optimizer states only for active parameters. We provide a theoretical analysis of the update behaviors under SMET, showing improved optimization stability. Extensive experiments demonstrate that SMET enables stable, scalable, and memory-efficient sparse pre-training of LLMs, paving the way for sparse training as a practical alternative to dense training. Our code is publicly available at: https://github.com/QiaoXiao7282/SMET.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Dynamic Sparse Training (DST) for LLMs exhibits optimization instability in the form of loss spikes after topology updates, caused specifically by the cold-start problem of newly regrown parameters under standard Adam (excessive initial updates). It proposes Sparse Memory-Efficient Training (SMET) using optimizer warm-up and density-aware learning-rate scaling to stabilize training, provides a theoretical analysis of update behaviors under SMET, reduces memory by storing gradients and optimizer states only for active parameters, and reports extensive experiments showing stable, scalable sparse pre-training of LLMs with preserved quality.
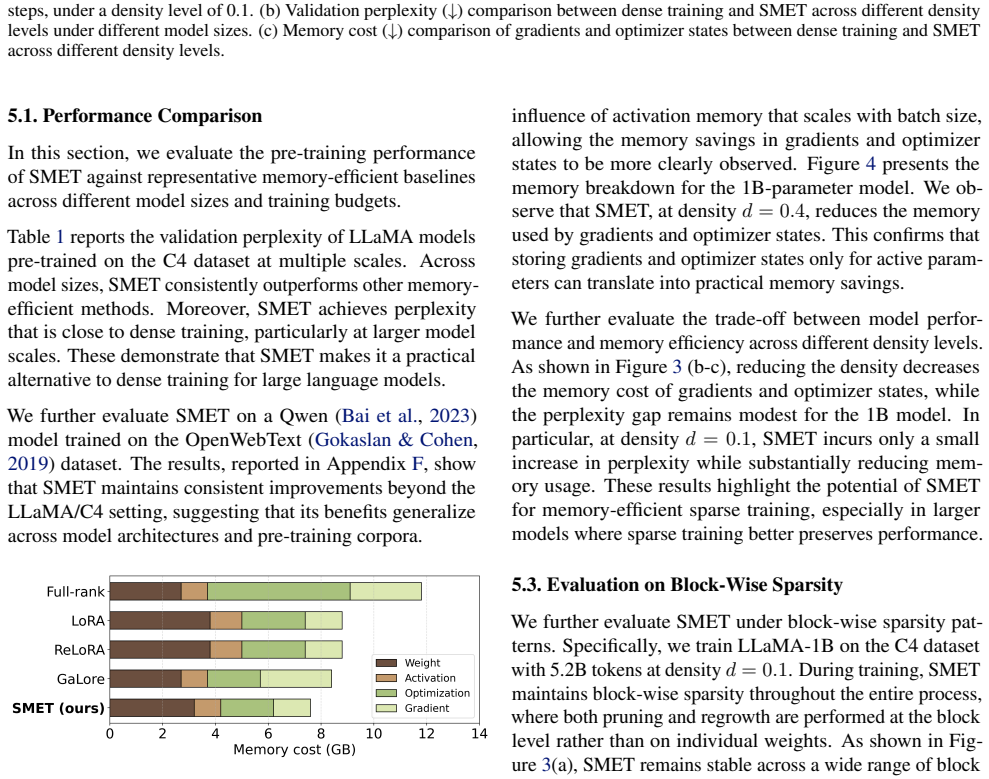
Significance. If the central stability claim holds without hidden trade-offs in convergence or final performance, the work would provide a practical route to memory-efficient sparse LLM training as an alternative to dense methods. The public code release and attempt at theoretical analysis of update dynamics are strengths that would support reproducibility and deeper understanding if the experiments isolate the proposed mechanism.
major comments (3)
- [Abstract / diagnosis of instability] Abstract and diagnosis section: the assertion that cold-start on regrown parameters is the dominant cause of post-update loss spikes is load-bearing for the stabilization claim, yet the manuscript does not isolate this from other DST factors (e.g., mask update frequency, gradient noise at LLM scale, or interactions with sparse topology). Without targeted ablations that apply warm-up/scaling only to regrown parameters while holding other variables fixed, the diagnosis and proposed remedy do not necessarily follow.
- [Theoretical analysis of update behaviors] Theoretical analysis section: the analysis of update behaviors must explicitly derive or bound how the warm-up period and density-aware scaling prevent excessive steps on new parameters without slowing progress on the active dense subgraph; if the analysis only shows qualitative improvement rather than a quantitative stability guarantee, it does not fully support the claim of 'improved optimization stability.'
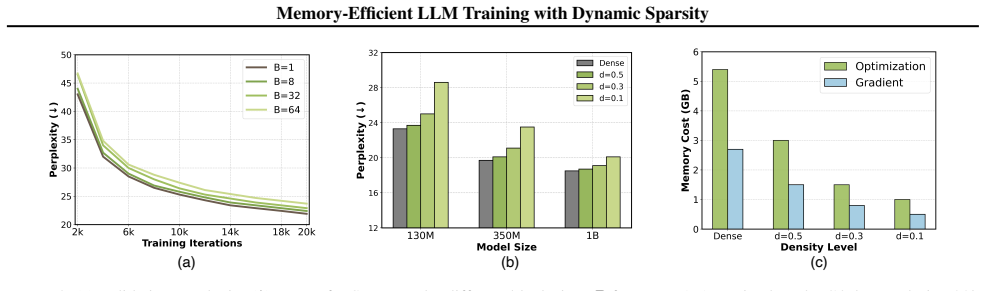
- [Experiments on LLM pre-training] Experiments section (scaling results): the claim of 'stable, scalable' pre-training requires reporting of loss curves and final perplexity with and without the proposed fixes across multiple model scales; if the density-aware scaling is tuned post-hoc on the same runs used to demonstrate stability, the generalization of the fix is not established.
minor comments (2)
- [Method description] Clarify the exact functional form of the density-aware learning-rate scaling (e.g., is it proportional to current density, inverse density, or another schedule?) and provide the corresponding equation.
- [Figures and tables] Figure legends and tables should explicitly state the number of random seeds and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. Below we respond point-by-point to the major concerns, clarifying our experimental design and analysis while indicating revisions that will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / diagnosis of instability] Abstract and diagnosis section: the assertion that cold-start on regrown parameters is the dominant cause of post-update loss spikes is load-bearing for the stabilization claim, yet the manuscript does not isolate this from other DST factors (e.g., mask update frequency, gradient noise at LLM scale, or interactions with sparse topology). Without targeted ablations that apply warm-up/scaling only to regrown parameters while holding other variables fixed, the diagnosis and proposed remedy do not necessarily follow.
Authors: We agree that more targeted isolation would strengthen the causal claim. Our main experiments hold mask-update frequency, sparsity schedule, and model scale fixed while comparing standard Adam DST against SMET; the loss spikes disappear only when the warm-up and scaling are applied. However, we did not run the precise ablation that applies warm-up exclusively to regrown weights while leaving the rest of the optimizer unchanged. We will add this controlled ablation (and the symmetric ablation that applies warm-up to all parameters) in the revised manuscript. revision: yes
-
Referee: [Theoretical analysis of update behaviors] Theoretical analysis section: the analysis of update behaviors must explicitly derive or bound how the warm-up period and density-aware scaling prevent excessive steps on new parameters without slowing progress on the active dense subgraph; if the analysis only shows qualitative improvement rather than a quantitative stability guarantee, it does not fully support the claim of 'improved optimization stability.'
Authors: The theoretical section derives closed-form expressions for the first and second moments of newly regrown parameters under Adam, showing that a linear warm-up reduces their effective step size by a factor proportional to the warm-up length, while the density-aware LR multiplier compensates for the reduced active parameter count so that the expected update norm on the dense subgraph remains comparable to the dense baseline. We acknowledge that these derivations are not accompanied by a formal bound on loss increase or convergence rate. In the revision we will explicitly label the analysis as characterizing update magnitudes rather than providing a stability guarantee and will add a short discussion of this scope limitation. revision: partial
-
Referee: [Experiments on LLM pre-training] Experiments section (scaling results): the claim of 'stable, scalable' pre-training requires reporting of loss curves and final perplexity with and without the proposed fixes across multiple model scales; if the density-aware scaling is tuned post-hoc on the same runs used to demonstrate stability, the generalization of the fix is not established.
Authors: Loss curves for all reported scales (125M–1.3B) appear in the appendix; final perplexity numbers are given in the main scaling table. The density-aware scaling coefficient was fixed after small-scale (≤125M) pilot runs and then used unchanged for all larger experiments. To make this clearer we will (i) move the loss curves into the main text, (ii) add an explicit “SMET vs. DST” comparison table for at least two additional scales, and (iii) state in the text that no per-run retuning of the scaling factor occurred on the reported large-model runs. revision: yes
Circularity Check
No circularity: claims rest on empirical observation and proposed engineering fixes, not self-definition or fitted inputs
full rationale
The provided abstract and context contain no equations, no self-citations, and no derivations that reduce predictions or stability claims to inputs by construction. The core proposal (optimizer warm-up plus density-aware LR scaling to address cold-start on regrown parameters) is presented as an independent remedy grounded in observed loss spikes, with a claimed theoretical analysis and experiments offered as external support. No load-bearing step matches any of the enumerated circularity patterns; the result does not reduce to a renaming, ansatz smuggling, or uniqueness theorem imported from the authors' prior work.
Axiom & Free-Parameter Ledger
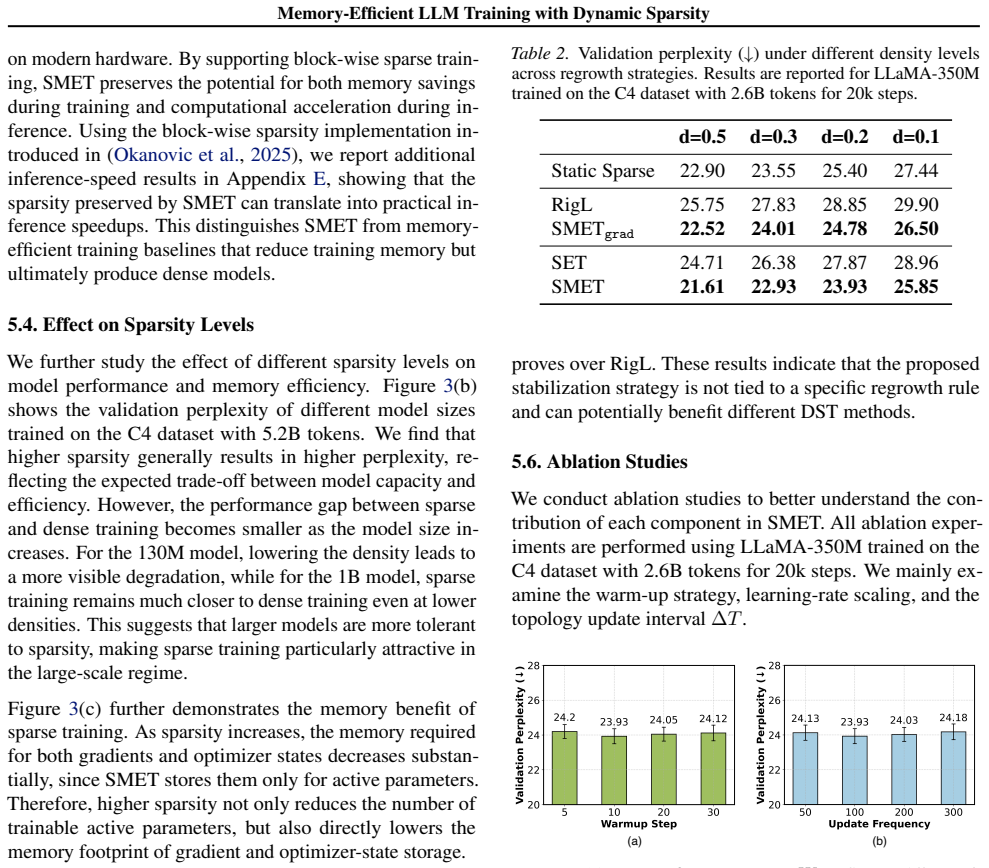
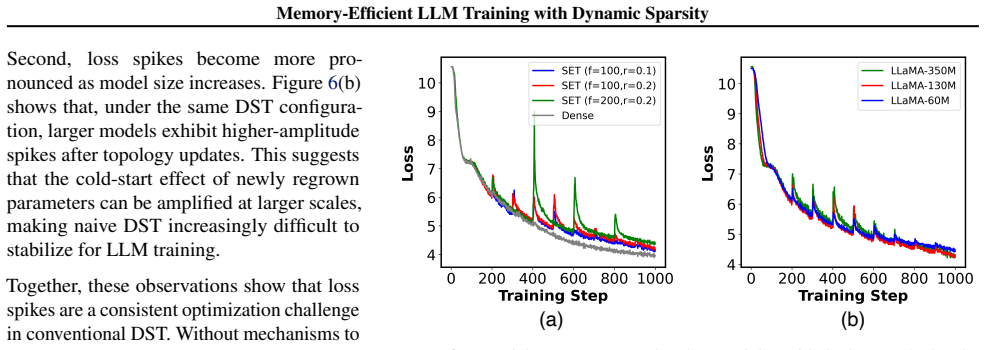
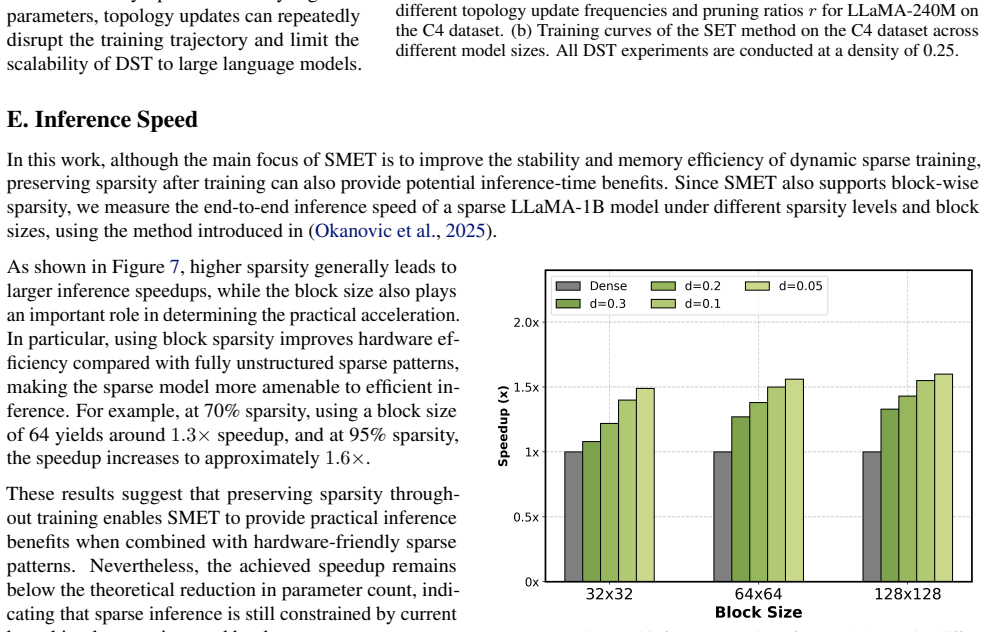
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
A Survey on Efficient Inference for Large Language Models
A survey on efficient inference for large language models , author=. arXiv preprint arXiv:2404.14294 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Forty-first International Conference on Machine Learning , year=
GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection , author=. Forty-first International Conference on Machine Learning , year=
-
[11]
Transactions on Machine Learning Research , year=
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey , author=. Transactions on Machine Learning Research , year=
-
[12]
Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , pages=
A survey on efficient training of transformers , author=. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , pages=
-
[13]
2023 , organization=
Frantar, Elias and Alistarh, Dan , booktitle=. 2023 , organization=
2023
-
[14]
Transactions of the Association for Computational Linguistics , volume=
A survey on model compression for large language models , author=. Transactions of the Association for Computational Linguistics , volume=
-
[15]
Journal of Machine Learning Research , volume=
Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks , author=. Journal of Machine Learning Research , volume=
-
[16]
2019 , url=
Namhoon Lee and Thalaiyasingam Ajanthan and Philip Torr , booktitle=. 2019 , url=
2019
-
[17]
Advances in neural information processing systems , volume=
Pruning neural networks without any data by iteratively conserving synaptic flow , author=. Advances in neural information processing systems , volume=
-
[18]
Nature communications , volume=
Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science , author=. Nature communications , volume=. 2018 , publisher=
2018
-
[19]
International conference on machine learning , pages=
Rigging the lottery: Making all tickets winners , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[20]
International Conference on Machine Learning , pages=
Do we actually need dense over-parameterization? in-time over-parameterization in sparse training , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[21]
2024 , cdate=
Mike Lasby and Anna Golubeva and Utku Evci and Mihai Nica and Yani Ioannou , title=. 2024 , cdate=
2024
-
[22]
Yuan, Geng and Ma, Xiaolong and Niu, Wei and Li, Zhengang and Kong, Zhenglun and Liu, Ning and Gong, Yifan and Zhan, Zheng and He, Chaoyang and Jin, Qing and others , journal=
-
[23]
Advances in Neural Information Processing Systems , volume=
Sparse maximal update parameterization: A holistic approach to sparse training dynamics , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
International Conference on Machine Learning , pages=
Sparser, Better, Deeper, Stronger: Improving Static Sparse Training with Exact Orthogonal Initialization , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[25]
2022 , url=
Utku Evci and Bart van Merrienboer and Thomas Unterthiner and Fabian Pedregosa and Max Vladymyrov , booktitle=. 2022 , url=
2022
-
[26]
Okanovic, Patrik and Deshmukh, Sameer and Kwasniewski, Grzegorz and Zhu, Yi and Fujii, Haruto and Fatima, Sakina and Besta, Maciej and Katayama, Kentaro and Honda, Takumi and Nagasaka, Yusuke and others , journal=
-
[27]
Zheng, Yaowei and Zhang, Richong and Zhang, Junhao and YeYanhan, YeYanhan and Luo, Zheyan , booktitle=
-
[28]
2025 , url=
Tianjin Huang and Ziquan Zhu and Gaojie Jin and Lu Liu and Zhangyang Wang and Shiwei Liu , booktitle=. 2025 , url=
2025
-
[29]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[30]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , journal=
-
[31]
2024 , url=
Vladislav Lialin and Sherin Muckatira and Namrata Shivagunde and Anna Rumshisky , booktitle=. 2024 , url=
2024
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
SMMF: Square-Matricized Momentum Factorization for Memory-Efficient Optimization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[33]
2025 , url=
Thomas Robert and Mher Safaryan and Ionut-Vlad Modoranu and Dan Alistarh , booktitle=. 2025 , url=
2025
-
[34]
Zhang, Yimu and Liu, Yuanshi and Fang, Cong , journal=
-
[35]
Advances in Neural Information Processing Systems , volume=
Chasing sparsity in vision transformers: An end-to-end exploration , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
NeurIPS , pages =
Shiwei Liu and Tianlong Chen and Xiaohan Chen and Zahra Atashgahi and Lu Yin and Huanyu Kou and Li Shen and Mykola Pechenizkiy and Zhangyang Wang and Decebal Constantin Mocanu , title =. NeurIPS , pages =
-
[37]
Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2022, Grenoble, France, September 19--23, 2022, Proceedings, Part III , pages=
Avoiding Forgetting and Allowing Forward Transfer in Continual Learning via Sparse Networks , author=. Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2022, Grenoble, France, September 19--23, 2022, Proceedings, Part III , pages=. 2023 , organization=
2022
-
[38]
International Conference on Machine Learning , pages=
The State of Sparse Training in Deep Reinforcement Learning , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[39]
2023 , url=
Yiqin Tan and Pihe Hu and Ling Pan and Jiatai Huang and Longbo Huang , booktitle=. 2023 , url=
2023
-
[40]
Advances in Neural Information Processing Systems , year=
Where to Pay Attention in Sparse Training for Feature Selection? , author=. Advances in Neural Information Processing Systems , year=
-
[41]
Advances in Neural Information Processing Systems , year=
Dynamic Sparse Network for Time Series Classification: Learning What to “See” , author=. Advances in Neural Information Processing Systems , year=
-
[42]
The Eleventh International Conference on Learning Representations , year=
More ConvNets in the 2020s: Scaling up Kernels Beyond 51x51 using Sparsity , author=. The Eleventh International Conference on Learning Representations , year=
-
[43]
Kingma and Jimmy Ba , title =
Diederik P. Kingma and Jimmy Ba , title =. The Eleventh International Conference on Learning Representations , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
Tuning large neural networks via zero-shot hyperparameter transfer , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[46]
Advances in neural information processing systems , volume=
Root mean square layer normalization , author=. Advances in neural information processing systems , volume=
-
[47]
Shazeer, Noam , journal=
-
[48]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
arXiv preprint arXiv:1907.04840 , year=
Sparse networks from scratch: Faster training without losing performance , author=. arXiv preprint arXiv:1907.04840 , year=
-
[50]
Proceedings of the AAAI conference on artificial intelligence , volume=
Gradient flow in sparse neural networks and how lottery tickets win , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[51]
Nature machine intelligence , volume=
Parameter-efficient fine-tuning of large-scale pre-trained language models , author=. Nature machine intelligence , volume=. 2023 , publisher=
2023
-
[52]
Advances in Neural Information Processing Systems , volume=
E2enet: Dynamic sparse feature fusion for accurate and efficient 3d medical image segmentation , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
International Conference on Learning Representations , volume=
Dynamic sparse training versus dense training: The unexpected winner in image corruption robustness , author=. International Conference on Learning Representations , volume=
-
[54]
OpenWebText Corpus , author=
-
[55]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.