Tiny Recursive Models for Solving the J2-Perturbed Lambert Problem
Pith reviewed 2026-06-28 18:06 UTC · model grok-4.3
The pith
A 2.3-million-parameter recursive neural model refines departure velocity to solve the J2-perturbed Lambert problem with median terminal errors below one kilometer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
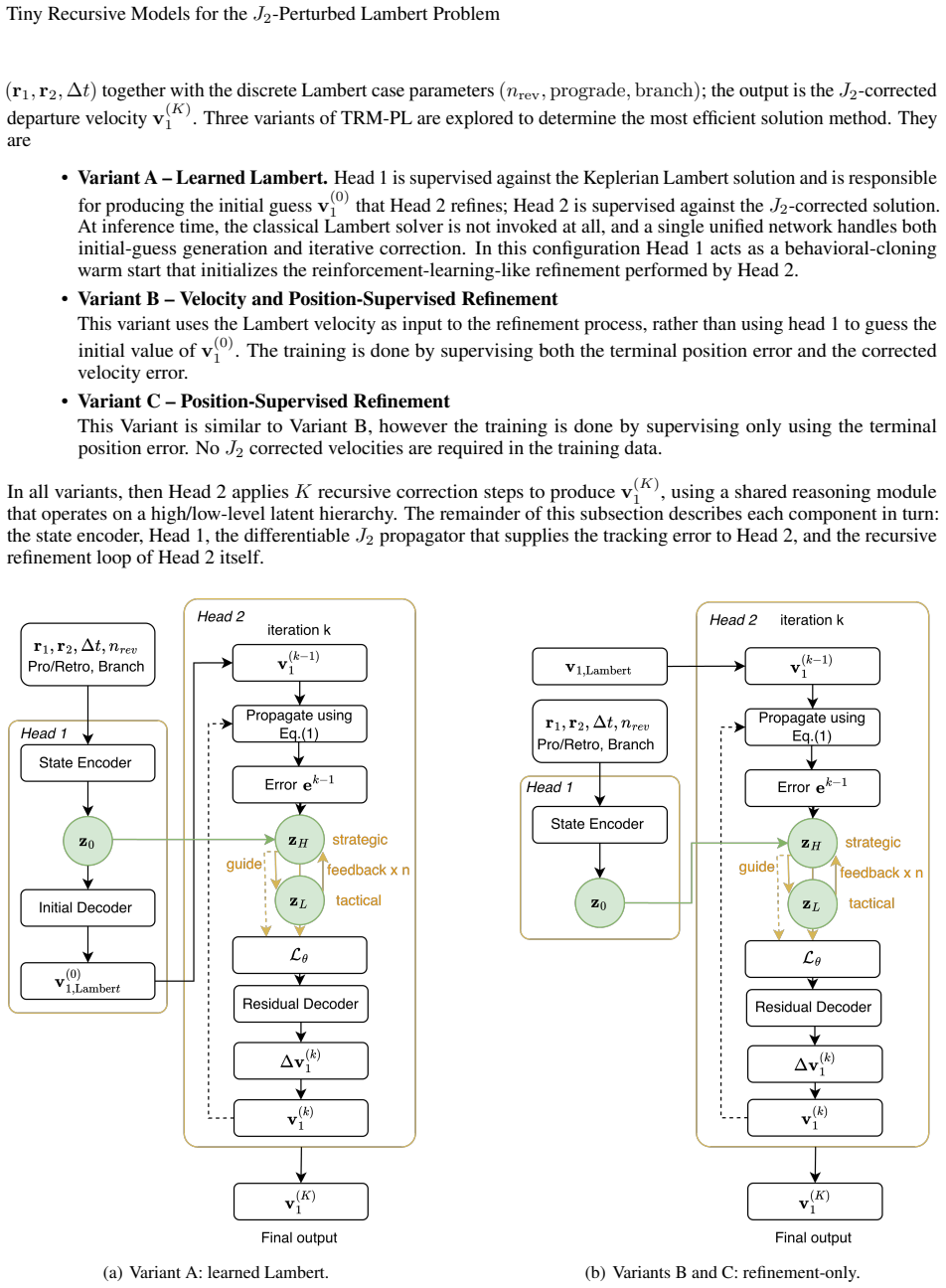
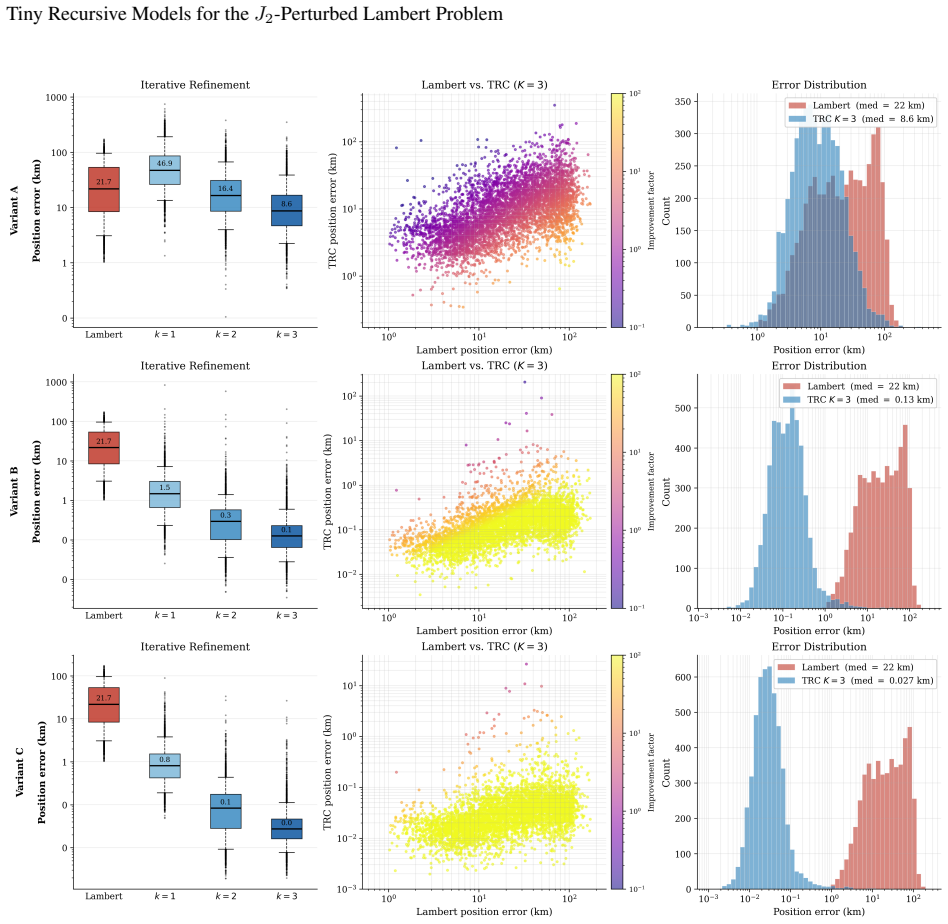
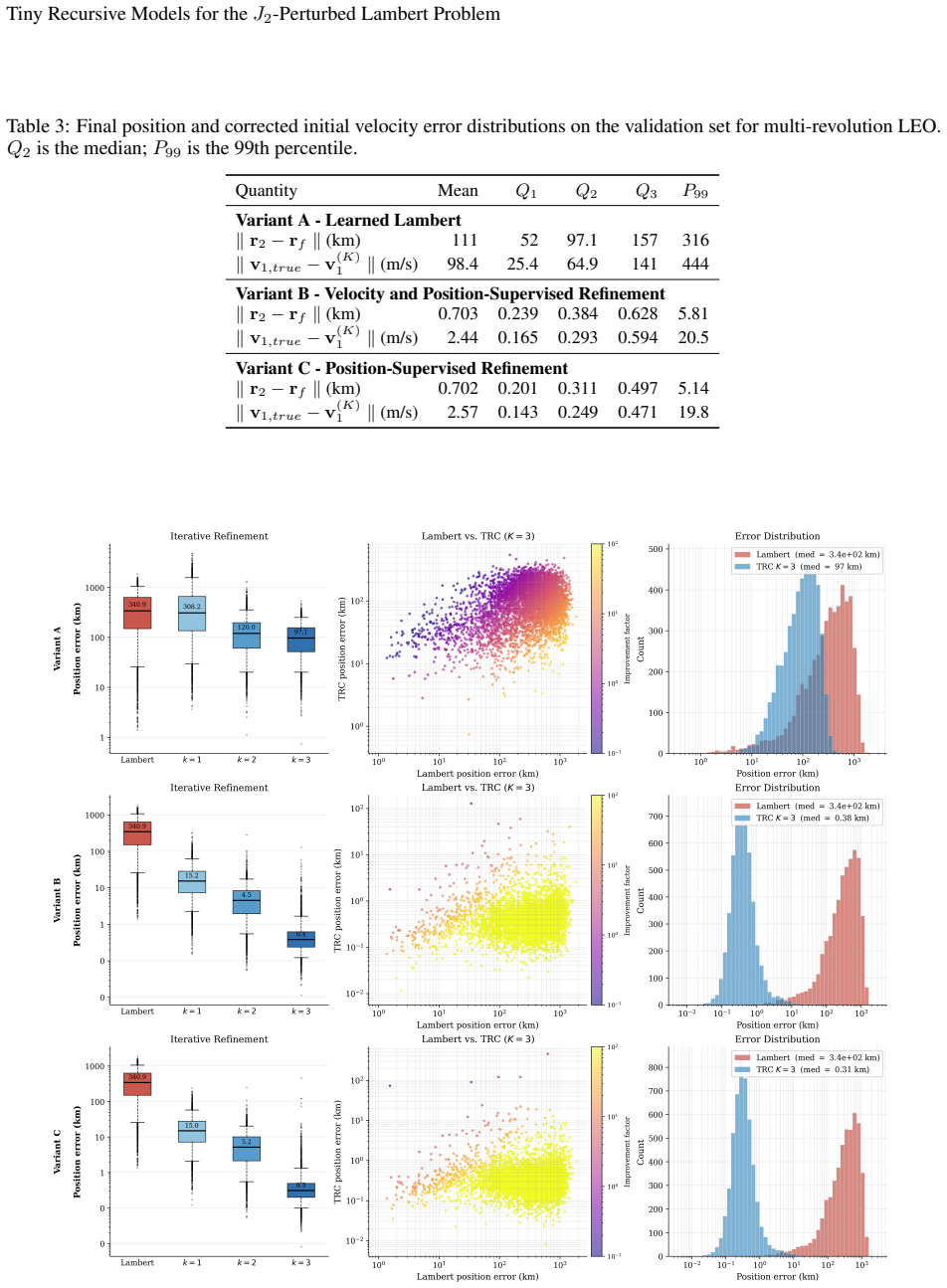
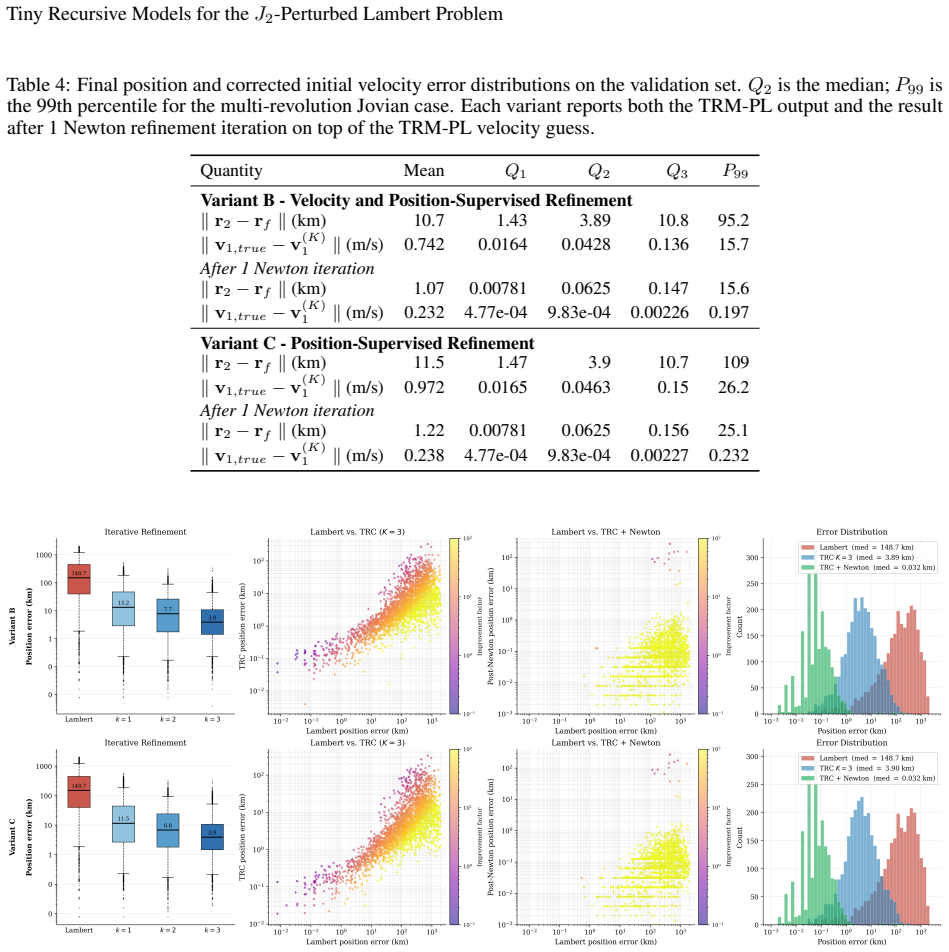
TRM-PL applies a compact reasoning module repeatedly within a two-level latent hierarchy to refine a candidate departure velocity by simulating the J2 trajectory and correcting from the resulting tracking error. The recursive refinement loop serves as a learned alternative to hand-designed continuation schemes, unifying initial-guess generation and iterative correction in a single trainable network. On the evaluated transfers, the position-supervised variant reduces median terminal-position error from 21.7 km to 0.027 km for single-revolution LEO and from 340.9 km to 0.31 km for multi-revolution LEO; one Newton corrector iteration then tightens the Jovian median to 0.063 km.
What carries the argument
The Tiny Recursive Model (TRM) refinement loop that repeatedly simulates the J2 trajectory and corrects departure velocity from position tracking error.
If this is right
- Refinement-only training with target-position supervision is more reliable than jointly learning the unperturbed Lambert solution and the J2 correction.
- The same 2.3M-parameter architecture handles both single-revolution and multi-revolution cases in LEO and Jovian regimes.
- One additional Newton corrector iteration on the TRM-PL output further tightens accuracy on the hardest transfers.
- The resulting accuracy and model size support potential use in embedded flight software.
Where Pith is reading between the lines
- The same recursive refinement structure could be applied to other gravitational or non-gravitational perturbations in astrodynamics.
- Explicit documentation of dataset generation, diversity, and train-test splits would be needed to confirm generalization claims.
- The architecture might replace classical iterative solvers inside real-time trajectory optimizers.
- Integration with existing Lambert solvers could provide fast initial guesses for more expensive numerical methods.
Load-bearing premise
The recursive corrections learned on the training transfers will produce accurate results for arbitrary unseen initial and target conditions.
What would settle it
Testing the trained TRM-PL on a collection of J2-perturbed Lambert transfers whose orbital elements or revolution counts lie outside the training distribution and checking whether median terminal position error stays below one kilometer.
Figures

read the original abstract
This paper presents a fast, recursive neural solver for the J2-perturbed Lambert problem based on Tiny Recursive Models (TRM), termed the TRM-Perturbed Lambert (TRM-PL) model. TRM is a weight-shared architecture whose effective capacity emerges from iteration depth rather than parameter count: a compact reasoning module is applied repeatedly within a two-level latent hierarchy, refining a candidate departure velocity by simulating the J2 trajectory and correcting it from the resulting tracking error. This unifies initial-guess generation and iterative correction in a single, end-to-end differentiable architecture. The recursive refinement loop is a learned alternative to the homotopy and continuation schemes of classical perturbed-Lambert solvers: rather than following a hand-designed path from the Keplerian to the perturbed solution, the network learns its own sequence of corrections. We evaluate TRM-PL on three test cases of increasing difficulty: single-revolution low-Earth-orbit (LEO) transfers, multi-revolution LEO transfers, and multi-revolution Jovian transfers. Three training paradigms are compared: jointly learning the Lambert solution and the J2 correction; refining the Lambert initial velocity with target-position and J2-corrected velocity supervision; and refining it with target-position supervision alone. Across all cases, the refinement-only approaches are the most reliable. The position-supervised variant reduces the median terminal-position error from 21.7 km to 0.027 km on single-revolution LEO, from 340.9 km to 0.31 km on multi-revolution LEO, all with the same 2.3M-parameter architecture. A single Newton corrector iteration on the TRM-PL output tightens the Jovian median to 0.063 km, yielding compact models accurate enough for embedded deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Tiny Recursive Models (TRM-PL) as a compact, weight-shared recursive neural architecture for solving the J2-perturbed Lambert problem. It unifies initial-guess generation and iterative correction via repeated application of a reasoning module that simulates J2 trajectories and refines departure velocities from tracking errors. Three training paradigms are compared on single-revolution LEO, multi-revolution LEO, and multi-revolution Jovian transfers; the position-supervised variant is reported to reduce median terminal-position error from 21.7 km to 0.027 km (single-revolution LEO) and 340.9 km to 0.31 km (multi-revolution LEO) with a fixed 2.3 M-parameter model, with one Newton iteration further tightening Jovian results to 0.063 km median.
Significance. If the generalization claims hold, the work would demonstrate a parameter-efficient, end-to-end differentiable alternative to classical homotopy/continuation methods for perturbed Lambert solvers, with potential utility for onboard astrodynamics where model size and speed matter. The recursive refinement as a learned substitute for hand-designed paths is conceptually interesting, but the absence of supporting experimental details prevents assessing whether this constitutes a substantive advance.
major comments (2)
- [Abstract] Abstract: The headline performance claims (median terminal-position error reductions to 0.027 km and 0.31 km) depend on the assertion that the same 2.3 M-parameter TRM-PL generalizes to unseen transfers. No description is supplied of how the three test suites were generated, including orbital-element ranges, sampling distributions, multi-revolution handling, train/test splits, or any hold-out protocol. Without this information the reported error reductions cannot be distinguished from interpolation on trajectories the model has seen during training.
- [Abstract] Abstract (training paradigms section): The manuscript states that three paradigms were compared (joint learning, target-position + J2-velocity supervision, and position supervision alone) but supplies no information on the loss functions, the precise form of the differentiable J2 simulation inside the recursion, convergence criteria, or statistical validation (e.g., number of test cases, variance, or outlier handling). These omissions are load-bearing for the claim that refinement-only approaches are “most reliable.”
minor comments (1)
- [Abstract] Abstract: The phrase “all with the same 2.3M-parameter architecture” is repeated without clarifying whether the architecture depth or latent dimension is held fixed across the three test regimes.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable suggestions. We will revise the manuscript to provide the missing experimental details on data generation, training, and validation to strengthen the generalization claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance claims (median terminal-position error reductions to 0.027 km and 0.31 km) depend on the assertion that the same 2.3 M-parameter TRM-PL generalizes to unseen transfers. No description is supplied of how the three test suites were generated, including orbital-element ranges, sampling distributions, multi-revolution handling, train/test splits, or any hold-out protocol. Without this information the reported error reductions cannot be distinguished from interpolation on trajectories the model has seen during training.
Authors: We agree that these details are essential for validating the generalization claims. In the revised manuscript, we will include a comprehensive description of the test suite generation process, specifying the orbital-element ranges, sampling distributions, multi-revolution handling, train/test splits, and hold-out protocols used. revision: yes
-
Referee: [Abstract] Abstract (training paradigms section): The manuscript states that three paradigms were compared (joint learning, target-position + J2-velocity supervision, and position supervision alone) but supplies no information on the loss functions, the precise form of the differentiable J2 simulation inside the recursion, convergence criteria, or statistical validation (e.g., number of test cases, variance, or outlier handling). These omissions are load-bearing for the claim that refinement-only approaches are “most reliable.”
Authors: We acknowledge that the current manuscript omits these critical implementation and validation details. The revised version will provide explicit information on the loss functions employed for each training paradigm, the structure of the differentiable J2 simulation within the recursive module, the convergence criteria, and statistical validation including the number of test cases, variance measures, and outlier handling methods. revision: yes
Circularity Check
No circularity; empirical ML results on simulated trajectories with no self-referential derivation
full rationale
The manuscript presents a trained neural architecture (TRM-PL) whose outputs are obtained by supervised learning on generated trajectory data. Performance claims (error reductions from 21.7 km to 0.027 km, etc.) are empirical evaluations of a fitted model rather than any first-principles derivation or prediction that reduces by construction to fitted parameters or self-citations. No equations, uniqueness theorems, or ansatzes are invoked that collapse to the inputs; the recursive refinement is explicitly learned. The paper is therefore self-contained as a standard supervised-learning result against external simulation benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- TRM model weights =
2.3 million
axioms (1)
- domain assumption The standard J2 gravitational perturbation model accurately captures the dominant dynamics for the LEO and Jovian test cases considered.
Reference graph
Works this paper leans on
-
[1]
Battin.An Introduction to the Mathematics and Methods of Astrodynamics
Richard H. Battin.An Introduction to the Mathematics and Methods of Astrodynamics. AIAA Education Series, revised edition, 1999. doi: 10.2514/4.861543
-
[2]
Bate, Donald D
Roger R. Bate, Donald D. Mueller, and Jerry E. White.Fundamentals of Astrodynamics. Dover Publications, 1971
1971
-
[3]
Wijayatunga, Roberto Armellin, Harry Holt, Laura Pirovano, and Aleksander A
Minduli C. Wijayatunga, Roberto Armellin, Harry Holt, Laura Pirovano, and Aleksander A. Lidtke. Design and guidance of a multi-active debris removal mission.Astrodynamics, 2023. doi: 10.1007/s42064-023-0159-3
-
[4]
Izzo, Revisiting Lambert’s problem, Celestial Mechanics and Dynamical Astronomy 121 (1) (2015) 1–15
Dario Izzo. Revisiting Lambert’s problem.Celestial Mechanics and Dynamical Astronomy, 121(1):1–15, 2015. doi: 10.1007/s10569-014-9587-y
-
[5]
Roberto Armellin, David Gondelach, and Juan F. San Juan. Multiple revolution perturbed Lambert problem solvers.Journal of Guidance, Control, and Dynamics, 41(9):2019–2032, 2018. doi: 10.2514/1.G003531
-
[6]
Potential of Diffractive Sail’s Sun-Earth Equilibria for Continuous Polar Observation,
Bin Yang, Shuang Li, Jinglang Feng, and Massimiliano Vasile. Fast solver for J2-perturbed Lambert problem using deep neural network.Journal of Guidance, Control, and Dynamics, 45(5):875–884, 2022. doi: 10.2514/1. G006091
work page doi:10.2514/1 2022
-
[7]
L. G. Kraige, John L. Junkins, and L. D. Ziems. Regularized integration of gravity-perturbed trajectories: A numerical efficiency study.Journal of Spacecraft and Rockets, 19(4):291–293, 1982. doi: 10.2514/3.62255
-
[8]
Russell, Nathan Strange, and David Ottesen
Nitin Arora, Ryan P. Russell, Nathan Strange, and David Ottesen. Partial derivatives of the solution to the Lambert boundary value problem.Journal of Guidance, Control, and Dynamics, 38(9):1563–1572, 2015. doi: 10.2514/1.G001030
-
[9]
Woollands, Ahmad Bani Younes, and John L
Robyn M. Woollands, Ahmad Bani Younes, and John L. Junkins. New solutions for the perturbed Lambert problem using regularization and Picard iteration.Journal of Guidance, Control, and Dynamics, 38(9):1548–1562,
-
[10]
doi: 10.2514/1.G001028
-
[11]
Zhen Yang, Ya-Zhong Luo, Jin Zhang, and Guo-Jin Tang. Homotopic perturbed Lambert algorithm for long- duration rendezvous optimization.Journal of Guidance, Control, and Dynamics, 38(11):2215–2223, 2015. doi: 10.2514/1.G001198
-
[12]
Mohammad Alhulayil, Ahmad Bani Younes, and James D. Turner. Higher order algorithm for solving Lambert’s problem.The Journal of the Astronautical Sciences, 65(4):400–422, 2018. doi: 10.1007/s40295-018-0137-9. 13 Tiny Recursive Models for theJ 2-Perturbed Lambert Problem Table 5: Sample statistics for the three training datasets, including mean, standard d...
-
[13]
Less is more: Recursive reasoning with tiny networks, 2025
Alexia Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks, 2025. URL https://arxiv. org/abs/2510.04871
Pith/arXiv arXiv 2025
-
[14]
Tiny recursive control: Iterative reasoning for efficient optimal control
Amit Jain and Richard Linares. Tiny recursive control: Iterative reasoning for efficient optimal control. InAIAA SciTech F orum, Orlando, FL, 2026. doi: 10.2514/6.2026-2380
-
[15]
Wijayatunga, Roberto Armellin, and Laura Pirovano
Minduli C. Wijayatunga, Roberto Armellin, and Laura Pirovano. Exploiting scaling constants to facilitate the convergence of indirect trajectory optimization methods.Journal of Guidance, Control, and Dynamics, 46(5), 2023
2023
-
[16]
Transformer- based model predictive control: Trajectory optimization via sequence modeling.IEEE Robotics and Automation Letters, 9(11):9820–9827, 2024
Davide Celestini, Daniele Gammelli, Tommaso Guffanti, Simone D’Amico, and Marco Pavone. Transformer- based model predictive control: Trajectory optimization via sequence modeling.IEEE Robotics and Automation Letters, 9(11):9820–9827, 2024
2024
-
[17]
RT-2: Vision-language-action models transfer web knowledge to robotic control, 2023
Anthony Brohan et al. RT-2: Vision-language-action models transfer web knowledge to robotic control, 2023. Appendix: Training and Validation Dataset Statistics 14 Tiny Recursive Models for theJ 2-Perturbed Lambert Problem Table 6: Sample statistics for the validation dataset, including mean, standard deviation, 10th percentile p10, and 90th percentilep 90...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.