MLLM-Microscope: Unlocking Hidden Structure Within Multimodal Large Language Models
Pith reviewed 2026-06-28 18:32 UTC · model grok-4.3
The pith
The geometry of representations inside multimodal LLMs depends on the modality fusion step before the language model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
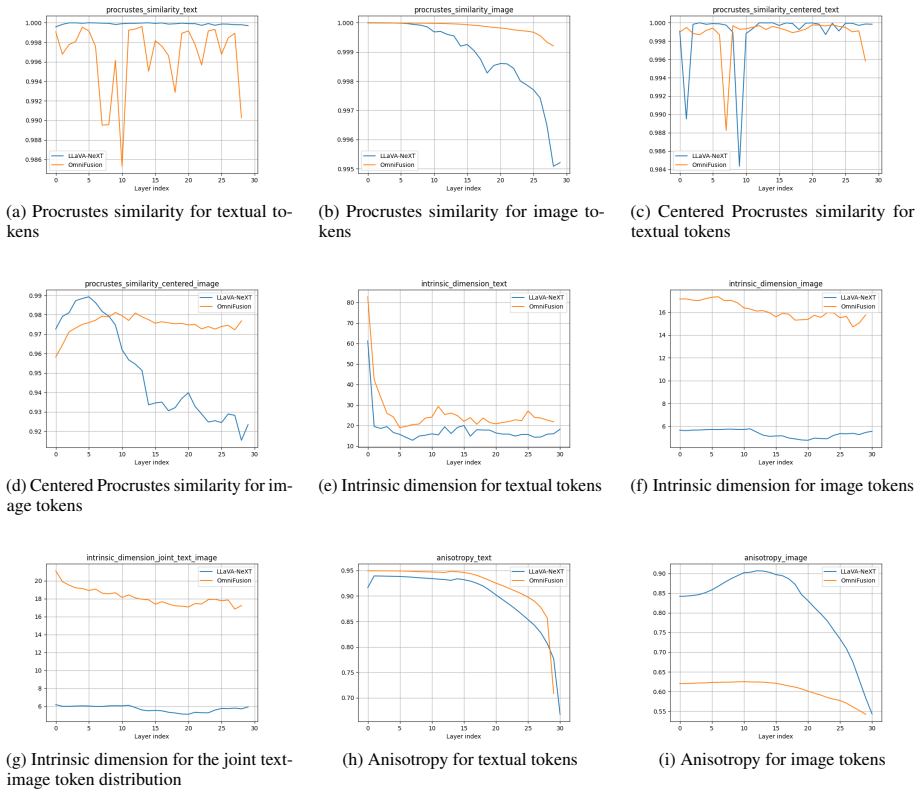
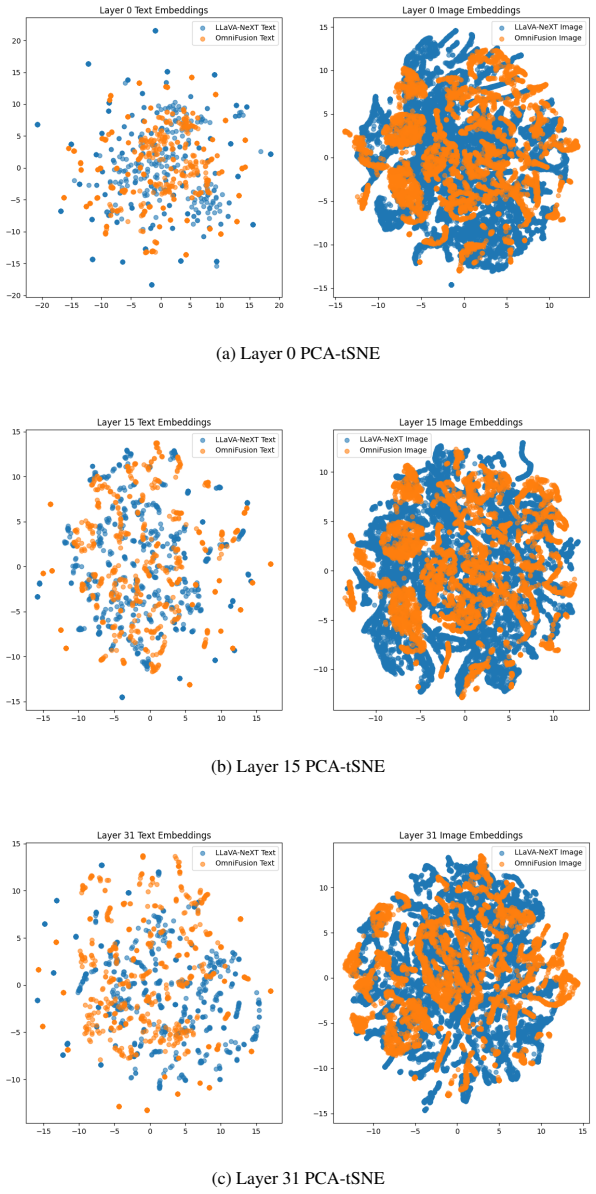
Analysis of embeddings across transformer layers shows that main and residual streams for both modalities remain highly linear in both models. LLaVA-NeXT image tokens exhibit a modest drop in linearity, while OmniFusion image tokens stay linear, maintain higher intrinsic dimension, and display consistently low anisotropy. The pattern is attributed to the differing ways the two systems combine vision and language tokens before they reach the shared LLM.
What carries the argument
MLLM-Microscope, the measurement system that quantifies linearity, intrinsic dimension, and anisotropy of multimodal token embeddings at each transformer layer.
If this is right
- High linearity in both streams is preserved across layers irrespective of the fusion method chosen.
- Image-token dimension stays higher when one particular fusion approach is used.
- Anisotropy can be kept low and stable throughout the network by selecting the right early fusion.
- Changes in image-token linearity across layers can be avoided by adopting the fusion method that prevents decline.
Where Pith is reading between the lines
- Designers could test new fusion modules by checking whether they reproduce the stable linearity and low anisotropy seen in one of the studied models.
- The same layer-wise measurements could be applied to audio or video tokens to see whether other modalities also show fusion-dependent geometry.
- If fusion controls these geometric properties, then interventions at the fusion stage might improve downstream multimodal reasoning without retraining the entire LLM.
Load-bearing premise
Differences in linearity, dimension, and anisotropy between LLaVA-NeXT and OmniFusion are produced by their modality fusion methods rather than by any other architectural distinctions.
What would settle it
Running the same measurements on a pair of models that share the same fusion strategy but differ in other components, or on a pair that differ only in fusion, would show whether the reported patterns track fusion or track something else.
Figures
read the original abstract
This work presents MLLM-Microscope, a novel system designed for analyzing the hidden representations within Multimodal Large Language Models (MLLMs). Our system evaluates the linearity, intrinsic dimension, and anisotropy of multimodal token embeddings across transformer layers. Utilizing the ScienceQA dataset, we evaluate two state-of-the-art MLLMs, LLaVA-NeXT and OmniFusion. We find that both the main and residual streams for tokens of both modalities exhibit highly linear behaviors across transformer layers. However, LLaVA-NeXT's image tokens reveal a slight decline in linearity, whereas OmniFusion's remain consistent. Image token dimensions in OmniFusion remain consistently higher across layers compared to LLaVA-NeXT. Also, the OmniFusion's anisotropy is observed to stay consistently low throughout the layers. These findings suggest that the inner workings of MLLMs highly depend on the nature of modality fusion performed before passing the token sequence into LLM. This and other new potential insights obtainable from our system are surely capable of enhancing our understanding of the inner workings of MLLMs, informing future model design and optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MLLM-Microscope, a system to evaluate linearity, intrinsic dimension, and anisotropy of multimodal token embeddings across transformer layers in MLLMs. It applies the system to LLaVA-NeXT and OmniFusion on the ScienceQA dataset, reporting high linearity in main and residual streams for both modalities (with a slight decline for LLaVA-NeXT image tokens), consistently higher image-token dimensions for OmniFusion, and consistently low anisotropy for OmniFusion. These observations are used to suggest that MLLM inner workings highly depend on the modality fusion strategy.
Significance. If the reported differences can be causally linked to fusion strategy via controlled comparisons, the geometric measurements could provide useful interpretability signals for MLLM design. The work performs reproducible empirical measurements on public models and a public dataset, which is a positive contribution to the toolkit for analyzing multimodal representations.
major comments (1)
- [Abstract] Abstract: the inference that the findings 'suggest that the inner workings of MLLMs highly depend on the nature of modality fusion' is not supported by the presented evidence. LLaVA-NeXT and OmniFusion differ in vision encoders, connector designs, training data mixtures, optimization, and possibly base LLM scale; no ablation, matched-pair comparison, or regression controlling for these confounders is described, so the isolation of fusion strategy as the dominant variable remains untested.
minor comments (1)
- [Abstract] Abstract: no definitions, equations, or estimation procedures are supplied for the linearity, intrinsic dimension, or anisotropy measures, and no error bars or statistical tests are mentioned.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that the abstract's phrasing implies a stronger causal link than the observational comparison between two distinct models can support. We will revise the abstract to present the findings more cautiously.
read point-by-point responses
-
Referee: [Abstract] Abstract: the inference that the findings 'suggest that the inner workings of MLLMs highly depend on the nature of modality fusion' is not supported by the presented evidence. LLaVA-NeXT and OmniFusion differ in vision encoders, connector designs, training data mixtures, optimization, and possibly base LLM scale; no ablation, matched-pair comparison, or regression controlling for these confounders is described, so the isolation of fusion strategy as the dominant variable remains untested.
Authors: We acknowledge that LLaVA-NeXT and OmniFusion differ across multiple dimensions beyond modality fusion strategy, including vision encoders, connectors, training mixtures, and optimization. Our study is strictly observational, reporting geometric properties measured on two publicly available models without controlled ablations or matched-pair experiments to isolate fusion as the causal factor. The original abstract language was intended to note potential implications for future work rather than assert dominance of any single variable. We will revise the abstract to replace the claim with a more qualified statement, e.g., that the observed differences 'are consistent with MLLM inner workings being influenced by modality fusion strategy' and will explicitly note the presence of other architectural differences. No additional experiments are feasible within the current scope. revision: yes
Circularity Check
No circularity: purely empirical measurements on public models
full rationale
The paper performs direct empirical measurements of linearity, intrinsic dimension, and anisotropy on token embeddings from two public MLLMs (LLaVA-NeXT and OmniFusion) using the public ScienceQA dataset. No equations, fitted parameters, or derivations are presented that reduce reported statistics to quantities defined or fitted inside the paper itself. The central inference about modality fusion is an interpretive claim from observed differences, not a self-referential reduction or self-citation load-bearing step. No self-citations, ansatzes, or uniqueness theorems appear in the provided text. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
1975 , journal =
Generalized procrustes analysis , author =. 1975 , journal =
1975
-
[2]
2024 , eprint=
Your Transformer is Secretly Linear , author=. 2024 , eprint=
2024
-
[3]
The 36th Conference on Neural Information Processing Systems (NeurIPS) , year=
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , author=. The 36th Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[4]
Visual Instruction Tuning , url =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , booktitle =. Visual Instruction Tuning , url =
-
[5]
2020 , howpublished =
Nostalgebraist , title =. 2020 , howpublished =
2020
-
[6]
2023 , eprint=
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. 2023 , eprint=
2023
-
[7]
2021 , eprint=
A Mathematical Framework for Transformer Circuits , author=. 2021 , eprint=
2021
-
[8]
Ethayarajh, Kawin. How Contextual are Contextualized Word Representations? C omparing the Geometry of BERT , ELM o, and GPT -2 Embeddings. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1006
-
[9]
Too Much in Common: Shifting of Embeddings in Transformer Language Models and its Implications
Bi \'s , Daniel and Podkorytov, Maksim and Liu, Xiuwen. Too Much in Common: Shifting of Embeddings in Transformer Language Models and its Implications. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.403
-
[10]
Estimating the intrinsic dimension of datasets by a minimal neighborhood information
Elena Facco and Maria d'Errico and Alex Rodriguez and Alessandro Laio , title =. CoRR , volume =. 2018 , url =. 1803.06992 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Improved Baselines with Visual Instruction Tuning , author=
-
[12]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
-
[13]
2024 , eprint=
OmniFusion Technical Report , author=. 2024 , eprint=
2024
-
[14]
2024 , eprint=
The Shape of Learning: Anisotropy and Intrinsic Dimensions in Transformer-Based Models , author=. 2024 , eprint=
2024
-
[15]
International Conference on Machine Learning , year=
Learning Transferable Visual Models From Natural Language Supervision , author=. International Conference on Machine Learning , year=
-
[16]
2024 , eprint=
A Survey on Multimodal Large Language Models , author=. 2024 , eprint=
2024
-
[17]
2024 , eprint=
MM-LLMs: Recent Advances in MultiModal Large Language Models , author=. 2024 , eprint=
2024
-
[18]
2023 , eprint=
A Survey of Large Language Models , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.