Single-Channel Tissue Segmentation via Cross-Modal Distillation from Foundation Models
Pith reviewed 2026-06-28 18:37 UTC · model grok-4.3
The pith
Cross-modal distillation from multiplexed foundation models boosts single-channel tissue segmentation Dice scores by 13 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
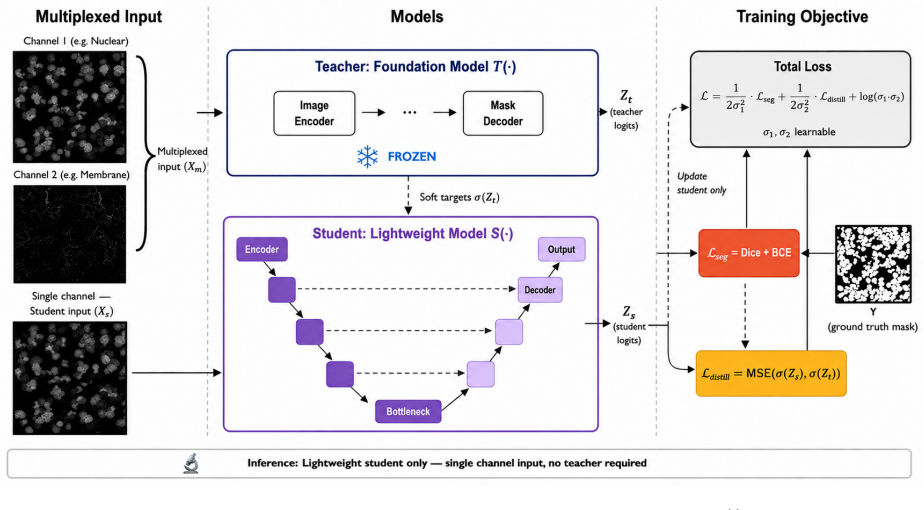
A cross-modal knowledge distillation framework transfers semantic information from a multiplexed foundation model teacher to single-channel students by combining MSE probability matching, boundary-aware supervision, and learnable uncertainty weighting, enabling the students to achieve substantial performance gains on tissue segmentation tasks.
What carries the argument
The distillation objective that uses MSE-based probability matching, boundary-aware supervision, and learnable uncertainty weighting to bridge multiplexed teacher inputs and single-channel student inputs.
If this is right
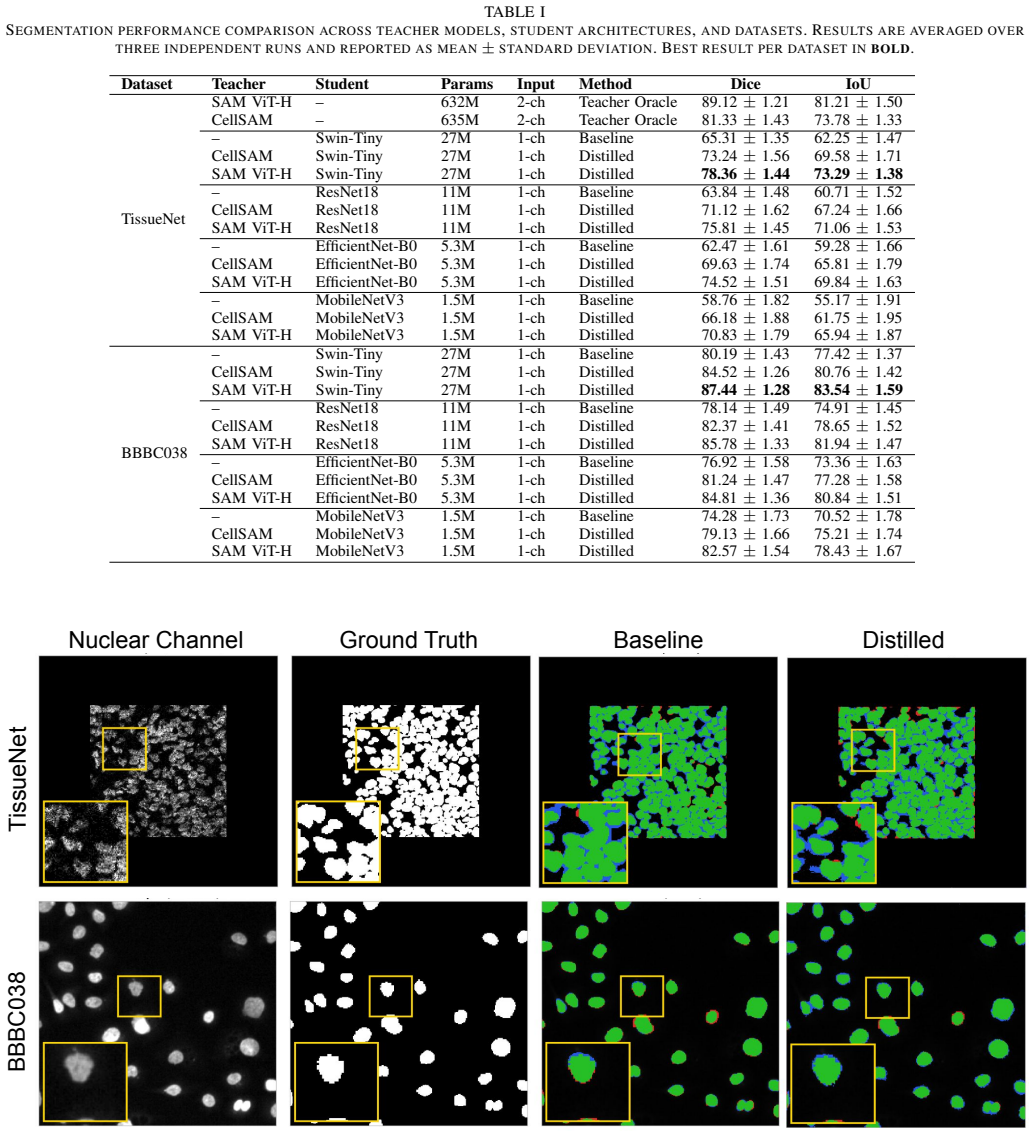
- KD improves Dice scores by about 12 points for all four tested student models on TissueNet.
- SAM ViT-H outperforms CellSAM as a teacher across all student architectures and datasets.
- The gains from distillation persist in cross-dataset evaluation on BBBC038 without any teacher retraining.
- The best student recovers 87.9% of the teacher oracle performance at a 23x parameter reduction.
Where Pith is reading between the lines
- This suggests that multi-channel foundation models can be leveraged to improve many single-channel medical imaging tasks where full multiplexing is not available at deployment.
- The framework could be extended to other modalities or tasks by adjusting the distillation losses to match domain differences.
- Smaller models like MobileNetV3 might see even larger relative benefits if further optimized for the distilled knowledge.
Load-bearing premise
The multiplexed teacher provides complementary semantic information from non-nuclear channels that can be transferred to the nuclear-only student without major loss due to input domain differences.
What would settle it
A lack of Dice score improvement in the distilled students compared to no-KD baselines on TissueNet would indicate that the cross-modal transfer is not effective.
Figures


read the original abstract
Multiplexed fluorescence microscopy improves tissue segmentation by providing complementary channels including nuclear (DAPI) and membrane (E-cadherin), that together encode richer spatial context than single-channel imaging alone. However, multiplexed models require all channels at inference, limiting deployment where only a subset is available. This work proposes a cross-modal knowledge distillation framework that transfers semantic information from a frozen foundation model teacher processing multiplexed input to a lightweight student operating on the nuclear channel only. The distillation objective combines MSE-based probability matching, boundary-aware supervision, and learnable uncertainty weighting. SAM ViT-H and CellSAM are evaluated as teachers across four U-Net students: Swin-Tiny (27M), ResNet18 (11M), EfficientNet-B0 (5.3M), and MobileNetV3 (1.5M), on TissueNet and BBBC038. On TissueNet, the SAM-distilled Swin-Tiny student achieves Dice 78.36 (plus or minus 1.44), a 13.05-point improvement over the no-KD baseline (65.31 plus or minus 1.35) and 87.9% recovery of teacher oracle performance (89.12 plus or minus 1.21) at a 23x parameter reduction. KD consistently improves all four students by approximately 12 Dice points, confirming architecture-agnostic distillation. SAM ViT-H outperforms CellSAM as teacher across all settings. Cross-dataset evaluation on BBBC038 shows consistent gains without teacher retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a cross-modal knowledge distillation framework that transfers semantic information from frozen multiplexed-input foundation model teachers (SAM ViT-H and CellSAM) to lightweight single nuclear-channel student networks (Swin-Tiny, ResNet18, EfficientNet-B0, MobileNetV3) for tissue segmentation. On TissueNet the best distilled student reaches Dice 78.36 (±1.44), a 13.05-point gain over the no-KD baseline and 87.9% recovery of the teacher oracle at 23× fewer parameters; consistent ~12-point gains are reported across students and datasets, with cross-dataset transfer on BBBC038 without teacher retraining.
Significance. If the central claim holds, the work offers a practical route to high-performance single-channel inference by leveraging multiplexed teachers only at training time. The architecture-agnostic gains, cross-dataset generalization without retraining, and use of public datasets with reported standard deviations are concrete strengths that would support deployment in settings where only nuclear staining is available.
major comments (3)
- [Experiments / TissueNet results (abstract and corresponding table)] The headline attribution of the 13.05-point Dice lift (TissueNet, Swin-Tiny row) to cross-modal transfer from non-nuclear channels rests on the assumption that the multiplexed teacher supplies complementary information unavailable to a nuclear-only model. No ablation is presented that holds teacher architecture, distillation losses (MSE probability matching + boundary supervision + uncertainty weighting), and training protocol fixed while restricting the teacher to the nuclear channel only. Without this control the reported gains cannot be separated from generic regularization effects of knowledge distillation.
- [Method (distillation objective)] The method description does not supply the precise mathematical form of the boundary-aware supervision term or the parameterization of the learnable uncertainty weights. These details are load-bearing for reproducing the reported Dice scores and for understanding whether the framework is truly parameter-light beyond the listed free parameters.
- [Experiments (baseline and training protocol)] Baseline definitions are incompletely specified: it is unclear whether the no-KD baseline uses identical data augmentation, optimizer schedule, and training epochs as the distilled students, or whether any post-hoc hyper-parameter tuning was performed only on the distilled runs. This affects interpretation of the 12-point average improvement.
minor comments (2)
- [Abstract] Abstract uses the literal phrase 'plus or minus' instead of the ± symbol; this should be corrected for readability.
- [Method] The manuscript would benefit from an explicit statement of the exact input-channel configuration used for each teacher during distillation (all channels vs. a subset) and from a reference to the precise SAM/CellSAM checkpoint versions employed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each of the major comments below.
read point-by-point responses
-
Referee: [Experiments / TissueNet results (abstract and corresponding table)] The headline attribution of the 13.05-point Dice lift (TissueNet, Swin-Tiny row) to cross-modal transfer from non-nuclear channels rests on the assumption that the multiplexed teacher supplies complementary information unavailable to a nuclear-only model. No ablation is presented that holds teacher architecture, distillation losses (MSE probability matching + boundary supervision + uncertainty weighting), and training protocol fixed while restricting the teacher to the nuclear channel only. Without this control the reported gains cannot be separated from generic regularization effects of knowledge distillation.
Authors: We agree that an ablation with the teacher restricted to the nuclear channel is necessary to isolate the contribution of cross-modal information. We will perform this control experiment in the revision, maintaining identical teacher architecture, losses, and protocol, and include the results to demonstrate that the gains are indeed attributable to the additional channels. revision: yes
-
Referee: [Method (distillation objective)] The method description does not supply the precise mathematical form of the boundary-aware supervision term or the parameterization of the learnable uncertainty weights. These details are load-bearing for reproducing the reported Dice scores and for understanding whether the framework is truly parameter-light beyond the listed free parameters.
Authors: The full mathematical definitions of these terms were omitted from the main text for brevity. We will expand the Methods section in the revised manuscript to include the precise equations for the boundary-aware supervision and the learnable uncertainty weighting parameterization. revision: yes
-
Referee: [Experiments (baseline and training protocol)] Baseline definitions are incompletely specified: it is unclear whether the no-KD baseline uses identical data augmentation, optimizer schedule, and training epochs as the distilled students, or whether any post-hoc hyper-parameter tuning was performed only on the distilled runs. This affects interpretation of the 12-point average improvement.
Authors: The no-KD baselines were trained using the identical data augmentation, optimizer schedule, and number of epochs as the distilled students. No selective hyper-parameter tuning was applied to the distilled models. We will add explicit statements to this effect in the revised manuscript. revision: yes
Circularity Check
No circularity; purely empirical evaluation on public benchmarks
full rationale
The manuscript presents an empirical knowledge-distillation pipeline evaluated via Dice scores on TissueNet and BBBC038. No equations, fitted parameters, or self-citations are used to derive the reported performance numbers; all metrics are obtained by direct measurement against held-out test sets. The central result (approximately 12-point Dice lift) is therefore not reducible to any input quantity defined inside the paper itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable uncertainty weights
axioms (1)
- domain assumption Foundation models (SAM ViT-H, CellSAM) produce high-quality semantic predictions on multiplexed fluorescence input that are worth distilling.
Reference graph
Works this paper leans on
-
[1]
Deep learning for cellular image analysis,
E. Moen, D. Bannon, T. Kudo, W. Graf, M. Bhatt, and D. Van Valen, “Deep learning for cellular image analysis,”Nature Methods, vol. 16, pp. 1233–1246, 2019
2019
-
[2]
U-Net: Convolutional net- works for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional net- works for biomedical image segmentation,” inMedical Image Comput- ing and Computer-Assisted Intervention (MICCAI). Springer, 2015, pp. 234–241
2015
-
[3]
Whole-cell segmentation of tissue images with human-level perfor- mance using large-scale data annotation and deep learning,
N. F. Greenwald, G. Miller, E. Moen, A. Kong, A. Kagel, T. Dougherty, C. C. Fullaway, B. J. McIntosh, K. X. Leow, M. S. Schwartzet al., “Whole-cell segmentation of tissue images with human-level perfor- mance using large-scale data annotation and deep learning,”Nature Biotechnology, vol. 40, pp. 555–565, 2022
2022
-
[4]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
Structured knowledge distillation for semantic segmentation,
Y . Liu, K. Chen, C. Liu, Z. Qin, Z. Luo, and J. Wang, “Structured knowledge distillation for semantic segmentation,” inIEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 2604–2613
2019
-
[6]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Dollar, and R. Gir- shick, “Segment anything,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 4015–4026
2023
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,”ArXiv, vol. abs/2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[8]
A foundation model for cell segmentation,
U. Israel, B. Bhatt, B. Bhatt, B. Bhattet al., “A foundation model for cell segmentation,”bioRxiv, 2023, doi:10.1101/2023.11.17.567630
-
[9]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 10 012–10 022
2021
-
[10]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
2016
-
[11]
EfficientNet: Rethinking model scaling for con- volutional neural networks,
M. Tan and Q. Le, “EfficientNet: Rethinking model scaling for con- volutional neural networks,” inInternational Conference on Machine Learning (ICML), 2019, pp. 6105–6114
2019
-
[12]
Searching for mobilenetv3,
A. G. Howard, M. Sandler, G. Chu, L.-C. Chen, B. Chen, M. Tan, W. Wang, Y . Zhu, R. Pang, V . Vasudevan, Q. V . Le, and H. Adam, “Searching for mobilenetv3,”2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 1314–1324, 2019
2019
-
[13]
Nucleus segmentation across imaging experiments: the 2018 Data Science Bowl,
J. C. Caicedo, A. Goodman, K. W. Karhohs, B. A. Cimini, J. Ackerman, M. Haghighi, C. Heng, T. Becker, M. Doan, C. McQuin, M. Rohban, S. Singh, and A. E. Carpenter, “Nucleus segmentation across imaging experiments: the 2018 Data Science Bowl,”Nature Methods, vol. 16, pp. 1247–1253, 2019
2018
-
[14]
Multi-task learning using uncer- tainty to weigh losses for scene geometry and semantics,
A. Kendall, Y . Gal, and R. Cipolla, “Multi-task learning using uncer- tainty to weigh losses for scene geometry and semantics,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 7482–7491
2018
-
[15]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,”ArXiv, vol. abs/1704.04861, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Segment Anything in medical images,
J. Ma, Y . He, F. Li, L. Han, C. You, and B. Wang, “Segment Anything in medical images,”Nature Communications, vol. 15, p. 654, 2024
2024
-
[17]
Poynton,Digital Video and HD: Algorithms and Interfaces, 2nd ed
C. Poynton,Digital Video and HD: Algorithms and Interfaces, 2nd ed. Morgan Kaufmann, 2012
2012
-
[18]
PyTorch Lightning,
W. Falconet al., “PyTorch Lightning,” https://github.com/Lightning- AI/pytorch-lightning, 2019
2019
-
[19]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations (ICLR), 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.