COLLIE: Guiding Skill Discovery in Semantically Coherent Latent Space
Pith reviewed 2026-06-28 17:54 UTC · model grok-4.3
The pith
COLLIE constructs a semantically coherent skill latent space from dense unsupervised data to enable training-free guidance from sparse human feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
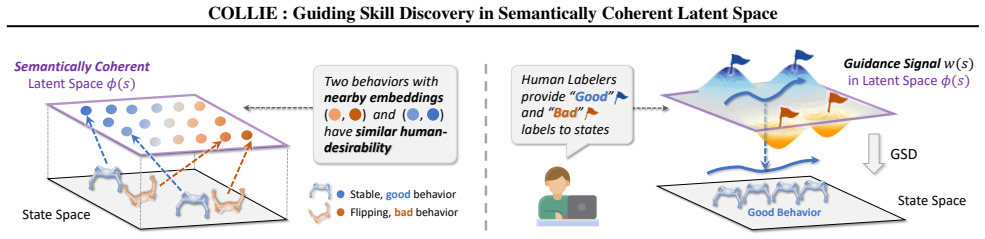
COLLIE shows that a latent space learned from dense unsupervised data exhibits semantic coherence, which permits the construction of effective guidance signals directly from the space geometry using only sparse online human feedback, without requiring additional model training or pre-defined rules.
What carries the argument
The semantically coherent skill latent space built from unsupervised data, whose structure allows training-free guidance signals based on proximity to human-preferred directions.
If this is right
- Learns diverse skills that align with human intent rather than uniform exploration.
- Avoids hazardous behaviors that arise in unguided discovery.
- Achieves superior performance on downstream tasks with minimal human feedback.
- Applies to both state-based and pixel-based environments.
- Theoretical analysis supports the reliability of the training-free guidance.
Where Pith is reading between the lines
- Such a space might generalize to other unsupervised representation learning problems where structure enables cheap alignment.
- Future work could test if the coherence property holds across different unsupervised pretraining methods.
- Downstream tasks might include real-world robotics where safety is critical and feedback is costly.
Load-bearing premise
The dense unsupervised data produces a latent space whose geometry aligns with human semantic judgments in a way that makes simple distance-based guidance effective.
What would settle it
A controlled test where human raters evaluate the skills produced by COLLIE's guidance signals and find them no more aligned or safe than those from uniform exploration methods.
Figures
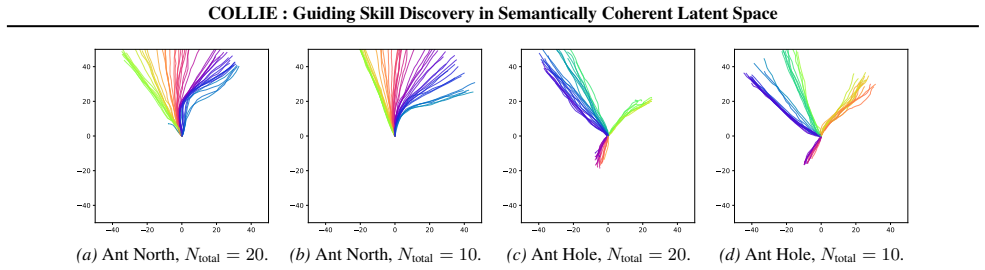
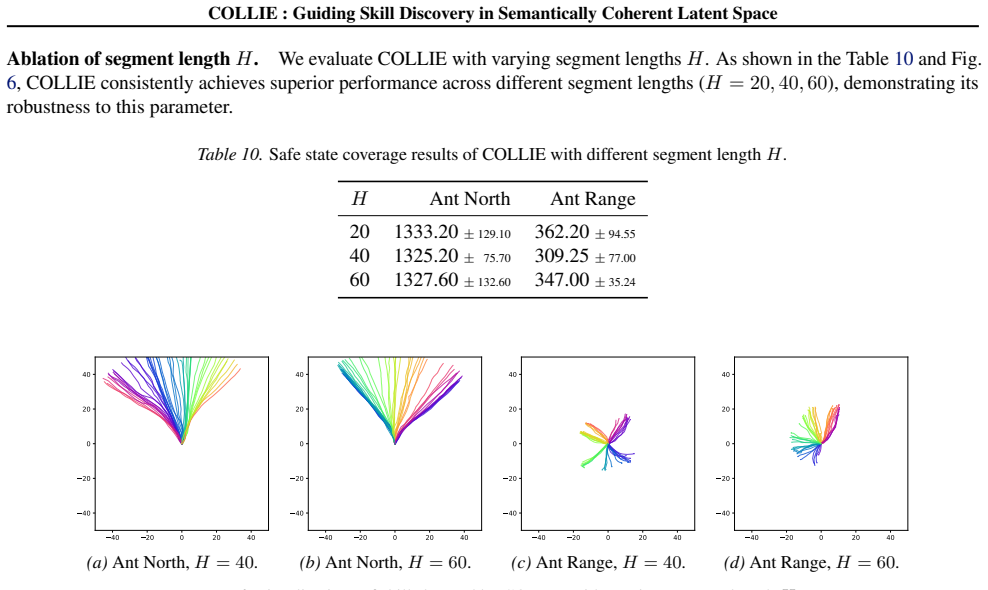
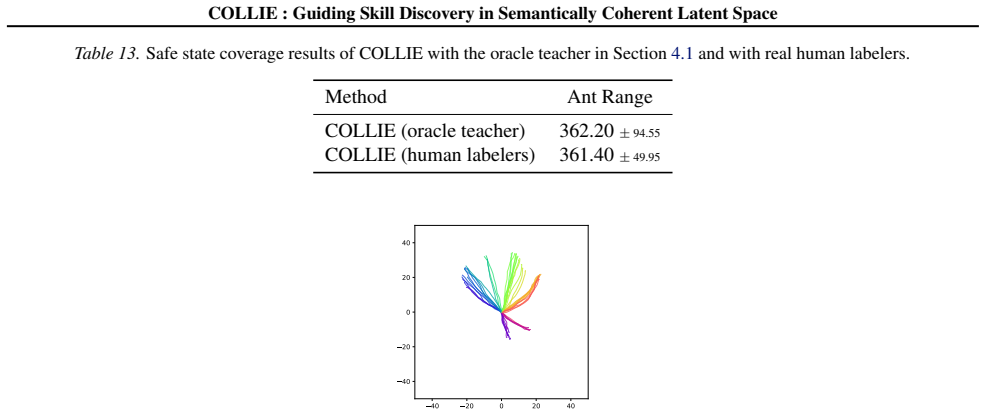

read the original abstract
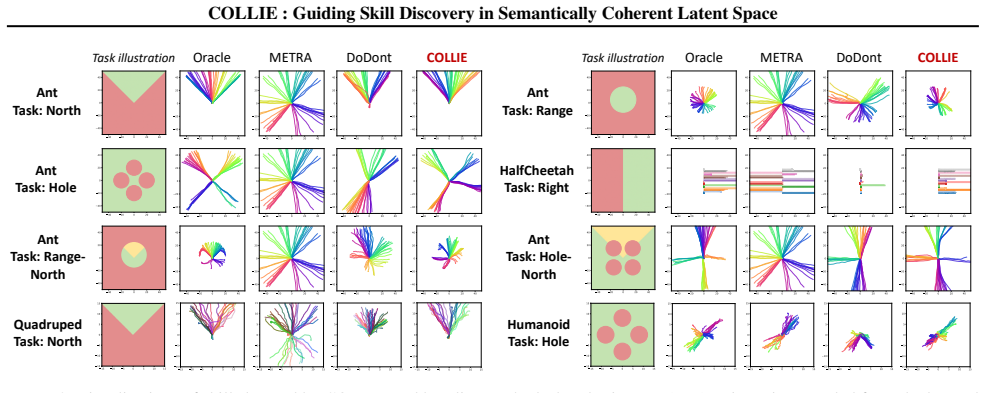
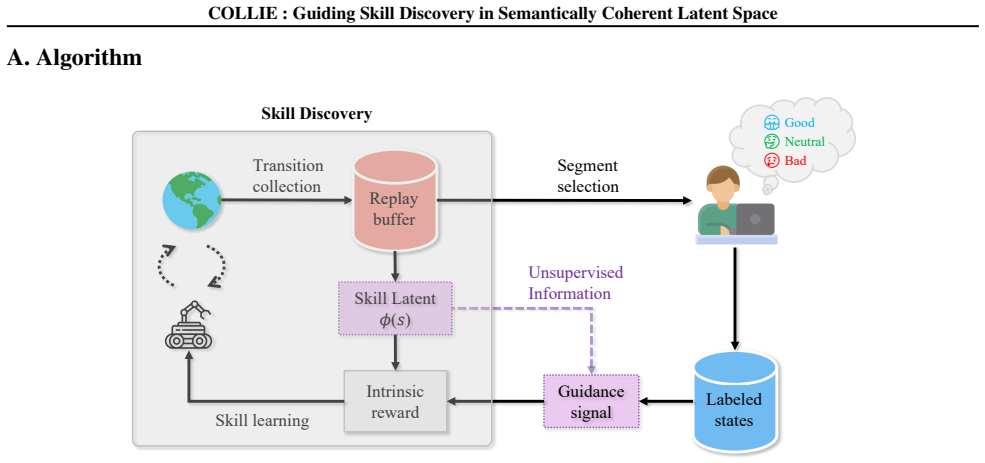
Unsupervised skill discovery (USD) aims to learn diverse behaviors without reward functions, but often results in task-irrelevant or hazardous behaviors due to uniform exploration. Guided skill discovery (GSD) addresses this issue by incorporating human intent to focus exploration on meaningful regions. However, existing GSD methods typically require training additional guidance models, and rely on pre-defined rules or expert demonstration, which can be ineffective under sparse, online-collected human feedback. To overcome this, we propose COLLIE, a GSD framework that leverages dense unsupervised data to construct a semantically coherent skill latent space. This latent space is well-structured, enabling reliable guidance with sparse online feedback. Moreover, its semantic coherence property enables training-free construction of guidance signals, eliminating the need for additional model training beyond skill learning. Theoretical analysis justifies the effectiveness of our training-free guidance signal, while experiments across diverse state-based and pixel-based tasks show that COLLIE learns diverse, human-aligned skills, avoids hazardous behaviors, and achieves superior downstream performance with minimal human feedback.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. COLLIE proposes a guided skill discovery (GSD) framework that leverages dense unsupervised data to construct a semantically coherent skill latent space. This space enables reliable, training-free guidance signals from sparse online human feedback, eliminating the need for additional guidance model training. Theoretical analysis is claimed to justify the guidance signal, and experiments on state-based and pixel-based tasks are said to show that COLLIE learns diverse human-aligned skills, avoids hazards, and yields superior downstream performance with minimal feedback.
Significance. If the semantic coherence property and training-free guidance hold, the approach could make guided skill discovery more practical by minimizing reliance on dense human feedback and extra model training, advancing unsupervised RL toward safer, more intent-aligned behaviors.
major comments (2)
- [Abstract and theoretical analysis section] Abstract and theoretical analysis section: The load-bearing claim that dense unsupervised data alone yields a 'semantically coherent' latent space whose geometry supports training-free guidance aligned with human intent is not secured by the construction (contrastive or reconstruction objectives on trajectories). No inductive bias is shown to ensure discovered axes match human-meaningful factors rather than spurious correlations, so the theoretical justification inherits the same unverified alignment assumption.
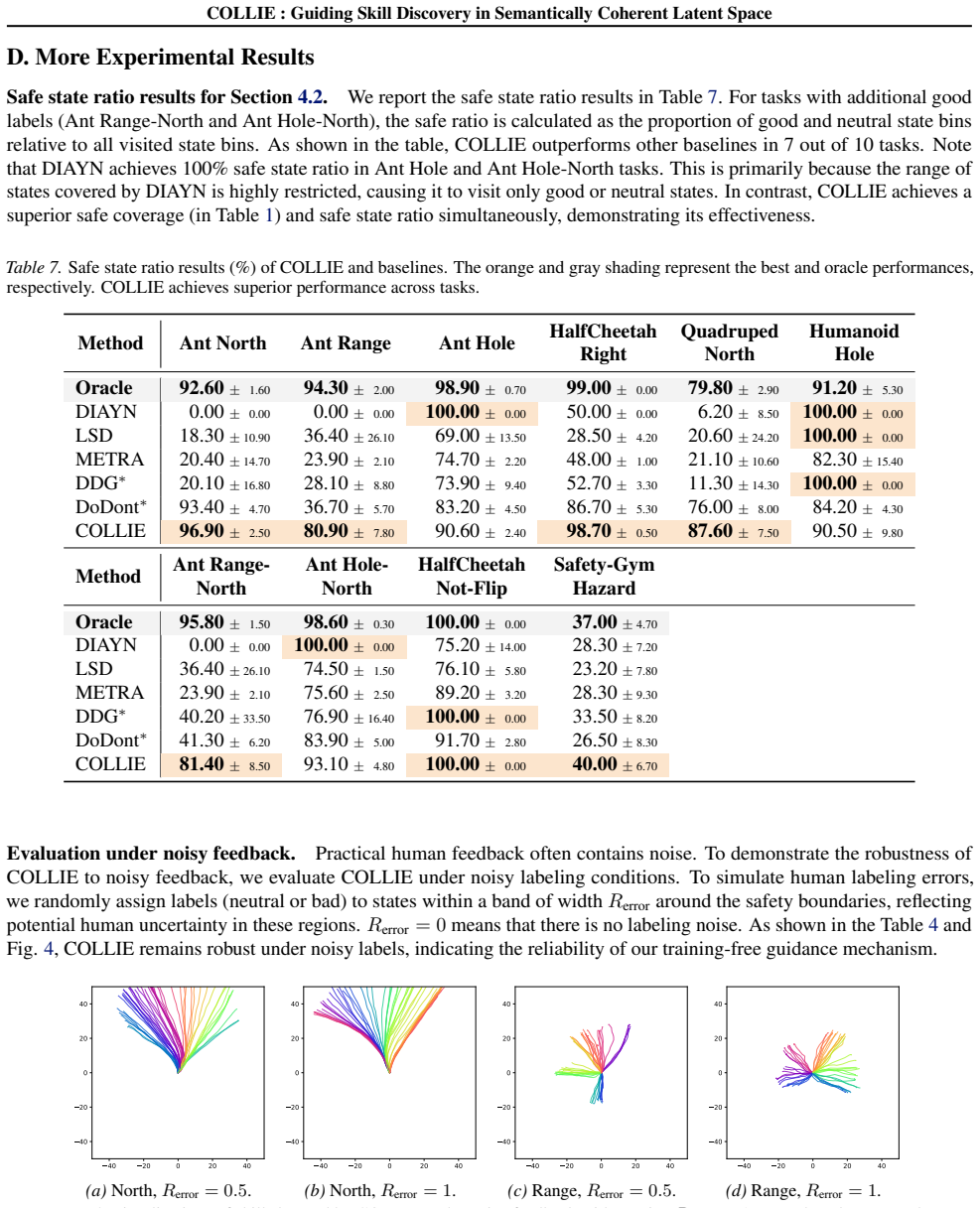
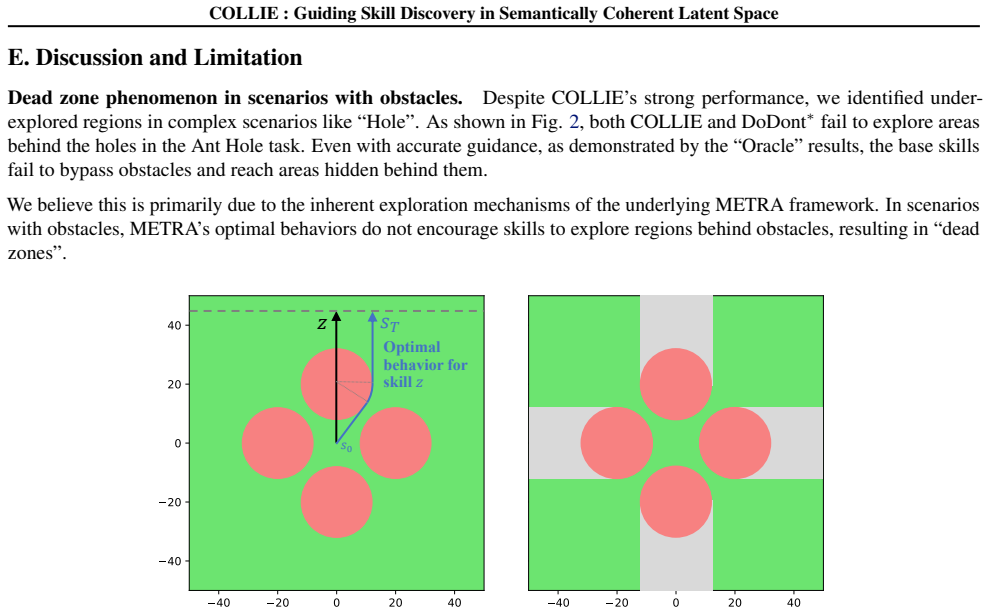
- [Experiments section] Experiments section: Claims of avoiding hazardous behaviors and superior downstream performance with minimal feedback rest on the latent space reliably aligning with human intent; without explicit verification that the unsupervised structure does not encode task-irrelevant invariances, the cross-task results do not yet substantiate the central GSD advantage.
minor comments (2)
- [Notation and method description] Clarify notation for the skill latent space and the exact form of the training-free guidance signal (e.g., how sparse feedback is mapped without additional fitting).
- [Experiments] Add a table or figure comparing the number of human feedback queries required versus prior GSD baselines to quantify the 'minimal' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, providing clarifications on the theoretical assumptions and experimental validations while noting where revisions can strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract and theoretical analysis section] Abstract and theoretical analysis section: The load-bearing claim that dense unsupervised data alone yields a 'semantically coherent' latent space whose geometry supports training-free guidance aligned with human intent is not secured by the construction (contrastive or reconstruction objectives on trajectories). No inductive bias is shown to ensure discovered axes match human-meaningful factors rather than spurious correlations, so the theoretical justification inherits the same unverified alignment assumption.
Authors: The theoretical analysis in the manuscript defines semantic coherence as the property that the latent space geometry permits reliable training-free guidance from sparse feedback, and derives that the guidance signal is effective under this property when the unsupervised objectives (contrastive and reconstruction on trajectories) produce a well-structured space. The construction does not include an explicit inductive bias guaranteeing human-meaningful factors; instead, it relies on the empirical observation that diverse unsupervised data from the environments implicitly encodes such structure. We agree this assumption merits clearer qualification in the abstract and theory section to avoid overstatement, and will revise accordingly to emphasize the conditional nature of the theoretical result. revision: partial
-
Referee: [Experiments section] Experiments section: Claims of avoiding hazardous behaviors and superior downstream performance with minimal feedback rest on the latent space reliably aligning with human intent; without explicit verification that the unsupervised structure does not encode task-irrelevant invariances, the cross-task results do not yet substantiate the central GSD advantage.
Authors: The experiments demonstrate the central GSD advantage through quantitative metrics (diversity, hazard avoidance rates, and downstream task returns) and qualitative visualizations across state-based and pixel-based environments, where COLLIE with minimal feedback outperforms baselines that lack the coherent latent space. Cross-task transfer results further support that the space generalizes beyond training distributions. However, we acknowledge the absence of an explicit analysis (e.g., correlation of latent dimensions with known semantic factors or invariance checks) to rule out task-irrelevant encodings. We will add such verification in a revised experiments section to more directly substantiate the alignment claim. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The COLLIE framework constructs the skill latent space directly from unsupervised trajectory data via standard contrastive/reconstruction objectives, then uses its geometry for training-free guidance whose justification is supplied by an internal theoretical analysis. No quoted equations reduce a claimed prediction or uniqueness result to a fitted parameter or self-citation chain; the alignment with human intent is presented as an empirical and theoretical property of the learned space rather than a definitional tautology. The derivation therefore does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Programming by feedback
Akrour, R., Schoenauer, M., Sebag, M., and Souplet, J.-C. Programming by feedback. In International Conference on Machine Learning, volume 32, pp.\ 1503--1511. PMLR, 2014
2014
-
[2]
Unifying count-based exploration and intrinsic motivation
Bellemare, M., Srinivasan, S., Ostrovski, G., Schaul, T., Saxton, D., and Munos, R. Unifying count-based exploration and intrinsic motivation. Advances in neural information processing systems, 29, 2016
2016
-
[3]
Boyd, S. P. and Vandenberghe, L. Convex optimization. Cambridge University Press, 2004
2004
-
[4]
Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J., Tang, J., and Zaremba, W. Openai gym. arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 0 1877--1901, 2020
1901
-
[6]
Exploration by random network distillation
Burda, Y., Edwards, H., Storkey, A., and Klimov, O. Exploration by random network distillation. In Seventh International Conference on Learning Representations, pp.\ 1--17, 2019
2019
-
[7]
Explore, discover and learn: Unsupervised discovery of state-covering skills
Campos, V., Trott, A., Xiong, C., Socher, R., Gir \'o -i Nieto, X., and Torres, J. Explore, discover and learn: Unsupervised discovery of state-covering skills. In International conference on machine learning, pp.\ 1317--1327. PMLR, 2020
2020
-
[8]
A simple framework for contrastive learning of visual representations
Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pp.\ 1597--1607. PmLR, 2020
2020
-
[9]
Rime: Robust preference-based reinforcement learning with noisy preferences
Cheng, J., Xiong, G., Dai, X., Miao, Q., Lv, Y., and Wang, F.-Y. Rime: Robust preference-based reinforcement learning with noisy preferences. In International Conference on Machine Learning, pp.\ 8229--8247. PMLR, 2024
2024
-
[10]
Listwise reward estimation for offline preference-based reinforcement learning
Choi, H., Jung, S., Ahn, H., and Moon, T. Listwise reward estimation for offline preference-based reinforcement learning. In International Conference on Machine Learning, pp.\ 8651--8671. PMLR, 2024
2024
-
[11]
F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D
Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017
2017
-
[12]
and Hart, P
Cover, T. and Hart, P. Nearest neighbor pattern classification. IEEE transactions on information theory, 13 0 (1): 0 21--27, 1967
1967
-
[13]
Daniel, C., Viering, M., Metz, J., Kroemer, O., and Peters, J. Active reward learning. In Robotics: Science and Systems X. Robotics: Science and Systems (RSS-2014), July 12-16, Berkeley, California, United States, 2014. doi:10.15607/RSS.2014.X.031
-
[14]
BERT : Pre-training of deep bidirectional transformers for language understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. BERT : Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp.\ 4171--4186, 2019
2019
-
[15]
Guiding pretraining in reinforcement learning with large language models
Du, Y., Watkins, O., Wang, Z., Colas, C., Darrell, T., Abbeel, P., Gupta, A., and Andreas, J. Guiding pretraining in reinforcement learning with large language models. In International Conference on Machine Learning, pp.\ 8657--8677. PMLR, 2023
2023
-
[16]
Adversarial intrinsic motivation for reinforcement learning
Durugkar, I., Tec, M., Niekum, S., and Stone, P. Adversarial intrinsic motivation for reinforcement learning. Advances in Neural Information Processing Systems, 34: 0 8622--8636, 2021
2021
-
[17]
Diversity is all you need: Learning skills without a reward function
Eysenbach, B., Ibarz, J., Gupta, A., and Levine, S. Diversity is all you need: Learning skills without a reward function. In 7th International Conference on Learning Representations, ICLR 2019, 2019
2019
-
[18]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Dy, J. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp.\ 1861--1870. PMLR, 10--15 Jul 2018
2018
-
[19]
and Shad, R
Hamedi, H. and Shad, R. Context-aware similarity measurement of lane-changing trajectories. Expert Systems with Applications, 209: 0 118289, 2022
2022
-
[20]
Dynamical distance learning for semi-supervised and unsupervised skill discovery
Hartikainen, K., Geng, X., Haarnoja, T., and Levine, S. Dynamical distance learning for semi-supervised and unsupervised skill discovery. 2019
2019
-
[21]
Provably efficient maximum entropy exploration
Hazan, E., Kakade, S., Singh, K., and Van Soest, A. Provably efficient maximum entropy exploration. In International Conference on Machine Learning, pp.\ 2681--2691. PMLR, 2019
2019
-
[22]
G., and Rana, S
Hussonnois, M., Karimpanal, T. G., and Rana, S. Controlled diversity with preference: Towards learning a diverse set of desired skills. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, pp.\ 1135--1143, 2023
2023
-
[23]
G., and Rana, S
Hussonnois, M., Karimpanal, T. G., and Rana, S. Human-aligned skill discovery: Balancing behaviour exploration and alignment. In Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, pp.\ 1025--1033, 2025
2025
-
[24]
Episodic novelty through temporal distance
Jiang, Y., Liu, Q., Yang, Y., Ma, X., Zhong, D., Hu, H., Yang, J., Liang, B., XU, B., Zhang, C., et al. Episodic novelty through temporal distance. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[25]
Kaelbling, L. P. Learning to achieve goals. In IJCAI, volume 2, pp.\ 1094--8, 1993
1993
-
[26]
K., Lee, H., Hwang, D., Kim, D., and Choo, J
Kim, H., LEE, B. K., Lee, H., Hwang, D., Kim, D., and Choo, J. Do's and don'ts: Learning desirable skills with instruction videos. Advances in Neural Information Processing Systems, 37: 0 47741--47766, 2024
2024
-
[27]
Safety-aware unsupervised skill discovery
Kim, S., Kwon, J., Lee, T., Park, Y., and Perez, J. Safety-aware unsupervised skill discovery. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pp.\ 894--900. IEEE, 2023
2023
-
[28]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. International Conference on Learning Representations, 2015
2015
-
[29]
Learning task agnostic skills with data-driven guidance
Klemsdal, E., Herland, S., and Murad, A. Learning task agnostic skills with data-driven guidance. In ICML 2021 Workshop on Unsupervised Reinforcement Learning, 2021. URL https://openreview.net/forum?id=CPh9DeHv08U
2021
-
[30]
B., Yarats, D., Rajeswaran, A., and Abbeel, P
Laskin, M., Liu, H., Peng, X. B., Yarats, D., Rajeswaran, A., and Abbeel, P. Unsupervised reinforcement learning with contrastive intrinsic control. Advances in Neural Information Processing Systems, 35: 0 34478--34491, 2022
2022
-
[31]
LeCun, Y., Boser, B., Denker, J., Henderson, D., Howard, R., Hubbard, W., and Jackel, L. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989. doi:10.1162/neco.1989.1.4.541
-
[32]
M., and Abbeel, P
Lee, K., Smith, L. M., and Abbeel, P. Pebble: Feedback-efficient interactive reinforcement learning via relabeling experience and unsupervised pre-training. In International Conference on Machine Learning, pp.\ 6152--6163. PMLR, 2021
2021
-
[33]
and Abbeel, P
Liu, H. and Abbeel, P. Aps: Active pretraining with successor features. In International Conference on Machine Learning, pp.\ 6736--6747. PMLR, 2021 a
2021
-
[34]
and Abbeel, P
Liu, H. and Abbeel, P. Behavior from the void: Unsupervised active pre-training. Advances in Neural Information Processing Systems, 34: 0 18459--18473, 2021 b
2021
-
[35]
STAIR : A ddressing S tage M isalignment through T emporal- A ligned P reference R einforcement L earning
Luan, Y., Mu, N., Yang, Y., Xu, B., and Jia, Q.-S. STAIR : A ddressing S tage M isalignment through T emporal- A ligned P reference R einforcement L earning. In The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[36]
CLARIFY : C ontrastive P reference R einforcement L earning for U ntangling A mbiguous Q ueries
Mu, N., Hu, H., Hu, X., Yang, Y., Xu, B., and Jia, Q.-S. CLARIFY : C ontrastive P reference R einforcement L earning for U ntangling A mbiguous Q ueries. In Forty-second International Conference on Machine Learning, 2025 a
2025
-
[37]
P reference-based M ulti- O bjective R einforcement L earning
Mu, N., Luan, Y., and Jia, Q.-S. P reference-based M ulti- O bjective R einforcement L earning. IEEE Transactions on Automation Science and Engineering, 22: 0 18737--18749, 2025 b . doi:10.1109/TASE.2025.3589271
-
[38]
Mu, N., Luan, Y., Yang, Y., Xu, B., and Jia, Q.-s. S - EPOA : O vercoming the I ndistinguishability of S egments with S kill- D riven P reference- B ased R einforcement L earning. In Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-25 , pp.\ 5967--5975, 2025 c . doi:10.24963/ijcai.2025/664
-
[39]
G., Oord, A., and Munos, R
Ostrovski, G., Bellemare, M. G., Oord, A., and Munos, R. Count-based exploration with neural density models. In International conference on machine learning, pp.\ 2721--2730. PMLR, 2017
2017
-
[40]
Surf: Semi-supervised reward learning with data augmentation for feedback-efficient preference-based reinforcement learning
Park, J., Seo, Y., Shin, J., Lee, H., Abbeel, P., and Lee, K. Surf: Semi-supervised reward learning with data augmentation for feedback-efficient preference-based reinforcement learning. In 10th International Conference on Learning Representations, ICLR 2022, 2022 a
2022
-
[41]
Lipschitz-constrained unsupervised skill discovery
Park, S., Choi, J., Kim, J., Lee, H., and Kim, G. Lipschitz-constrained unsupervised skill discovery. In International Conference on Learning Representations, 2022 b
2022
-
[42]
Controllability-aware unsupervised skill discovery
Park, S., Lee, K., Lee, Y., and Abbeel, P. Controllability-aware unsupervised skill discovery. In Proceedings of the 40th International Conference on Machine Learning, pp.\ 27225--27245, 2023
2023
-
[43]
Metra: Scalable unsupervised rl with metric-aware abstraction
Park, S., Rybkin, O., and Levine, S. Metra: Scalable unsupervised rl with metric-aware abstraction. In International Conference on Learning Representations, 2024
2024
-
[44]
A., and Darrell, T
Pathak, D., Agrawal, P., Efros, A. A., and Darrell, T. Curiosity-driven exploration by self-supervised prediction. In International conference on machine learning, pp.\ 2778--2787. PMLR, 2017
2017
-
[45]
W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp.\ 8748--8763. PmLR, 2021
2021
-
[46]
Benchmarking Safe Exploration in Deep Reinforcement Learning , 2019
Ray, A., Achiam, J., and Amodei, D. Benchmarking Safe Exploration in Deep Reinforcement Learning , 2019. URL https://openai.com/index/benchmarking-safe-exploration-in-deep-reinforcement-learning/
2019
-
[47]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
Dynamics-aware unsupervised discovery of skills
Sharma, A., Gu, S., Levine, S., Kumar, V., and Hausman, K. Dynamics-aware unsupervised discovery of skills. In International Conference on Learning Representations, 2020
2020
-
[49]
D., and Brown, D
Shin, D., Dragan, A. D., and Brown, D. S. Benchmarks and algorithms for offline preference-based reward learning. Transactions on Machine Learning Research, 2023
2023
-
[50]
Nearest neighbor estimates of entropy
Singh, H., Misra, N., Hnizdo, V., Fedorowicz, A., and Demchuk, E. Nearest neighbor estimates of entropy. American journal of mathematical and management sciences, 23 0 (3-4): 0 301--321, 2003
2003
-
[51]
Preference-learning based inverse reinforcement learning for dialog control
Sugiyama, H., Meguro, T., and Minami, Y. Preference-learning based inverse reinforcement learning for dialog control. In INTERSPEECH, volume 12, pp.\ 222--225, 2012
2012
-
[52]
Tassa, Y., Doron, Y., Muldal, A., Erez, T., Li, Y., Casas, D. d. L., Budden, D., Abdolmaleki, A., Merel, J., Lefrancq, A., et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
Mujoco: A physics engine for model-based control
Todorov, E., Erez, T., and Tassa, Y. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ international conference on intelligent robots and systems, pp.\ 5026--5033. IEEE, 2012
2012
-
[54]
I., Liang, P., and Manning, C
Wang, S. I., Liang, P., and Manning, C. D. Learning language games through interaction. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 2368--2378, 2016
2016
-
[55]
Effective and efficient sports play retrieval with deep representation learning
Wang, Z., Long, C., Cong, G., and Ju, C. Effective and efficient sports play retrieval with deep representation learning. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp.\ 499--509, 2019
2019
-
[56]
Pretraining in deep reinforcement learning: A survey
Xie, Z., Lin, Z., Li, J., Li, S., and Ye, D. Pretraining in deep reinforcement learning: A survey. arXiv preprint arXiv:2211.03959, 2022
-
[57]
Can a MISL fly? analysis and ingredients for mutual information skill learning
Zheng, C., Tuyls, J., Peng, J., and Eysenbach, B. Can a MISL fly? analysis and ingredients for mutual information skill learning. In The Thirteenth International Conference on Learning Representations, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.