Reasmory: 3D Reconstruction as Explicit Memory for VLMs Spatial Reasoning
Pith reviewed 2026-06-28 17:44 UTC · model grok-4.3
The pith
VLMs achieve more reliable spatial reasoning by running validated DSL programs over explicit 3D reconstructions instead of free-form tool calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
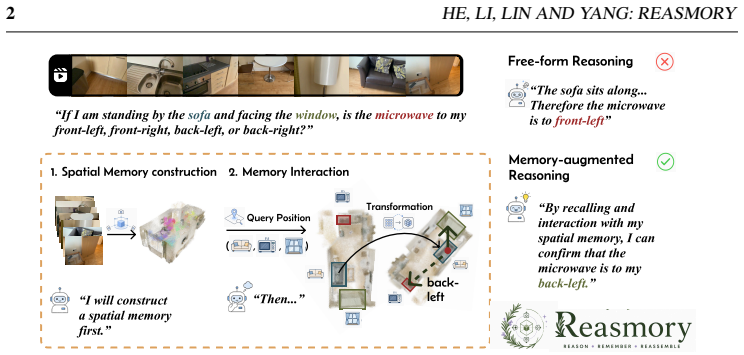
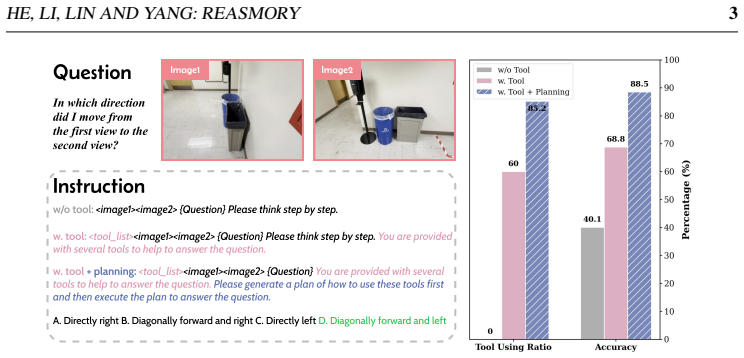
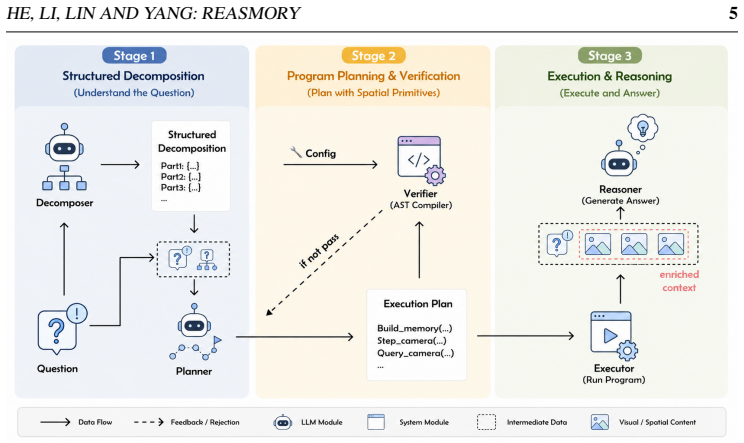
Reasmory builds explicit 3D memory from reconstruction models, augments it with semantically grounded object instances, and supplies a lightweight DSL so that VLMs generate programs to query objects and cameras, apply viewpoint transforms, and render observations; these programs are parsed and validated before execution, yielding 6-18 percent gains over strong baselines on multi-view and video spatial benchmarks.
What carries the argument
A lightweight Domain-Specific Language whose operations query objects and cameras, transform viewpoints, and render observations over reconstructed point clouds and instances, with parsing and validation before execution.
If this is right
- Explicit 3D memory accessed through validated programs outperforms free-form tool invocation on the same underlying reconstruction and VLM components.
- Gains appear consistently across multi-view image sets and monocular video sequences on spatial reasoning benchmarks.
- The approach works with existing reconstruction foundation models and current VLMs without additional training.
- Constrained, validated execution reduces errors from incorrect tool calls, skipped transformations, or misused intermediate results.
Where Pith is reading between the lines
- The same DSL-plus-validation pattern could be applied to other forms of explicit memory such as scene graphs or occupancy grids when spatial cues are sparse.
- If reconstruction quality improves on real-world video, the performance gap between constrained and free-form access may widen further.
- The method suggests a general template for making tool-using agents more reliable by replacing open-ended API calls with a checked intermediate language.
Load-bearing premise
Reconstruction models can turn sparse views into accurate explicit 3D memory and VLMs can emit DSL programs that are both syntactically valid and semantically sufficient for the needed reasoning.
What would settle it
A controlled experiment in which VLMs generate invalid or incomplete DSL programs at high rates, or in which reconstruction quality drops on the same benchmarks, produces no accuracy gain or a drop relative to free-form baselines.
Figures

read the original abstract
Vision-Language Models (VLMs) exhibit emerging spatial reasoning capabilities, yet they remain unreliable on tasks requiring precise spatial understanding, such as viewpoint reasoning, directional comparison, and distance estimation. In multi-view images and monocular videos, relevant spatial cues are often sparse and distributed across redundant observations, making them difficult to organize and exploit. Reconstruction-based Vision Foundation Models (VFMs) offer a natural way to aggregate such observations into explicit spatial memory, such as point clouds. However, simply exposing reconstruction models as free-form tools is brittle, VLMs may invoke tools incorrectly, skip required spatial transformations, or misuse intermediate results. We propose \textbf{Reasmory}, a framework that formulates spatial reasoning as structured program execution over reconstructed spatial memory. Reasmory constructs explicit 3D memory, augments it with semantically grounded 3D object instances, and introduces a lightweight Domain-Specific Language (DSL) that constrains how VLMs query objects and cameras, transform viewpoints, and render observations during reasoning. Generated programs are parsed and validated before execution, enabling more reliable interaction with spatial memory than unconstrained tool use. Experiments on multi-view image and video spatial reasoning benchmarks show consistent gains of 6--18\% over strong baselines, including GPT-5-mini and Gemini-3-flash, indicating that explicit 3D memory is most useful when accessed through constrained, validated operations rather than free-form tool calls.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Reasmory, a framework that aggregates sparse multi-view and video observations into explicit 3D spatial memory via reconstruction VFMs (point clouds augmented with grounded object instances) and introduces a lightweight DSL to constrain VLMs to validated program execution for spatial queries, viewpoint transforms, and rendering. It claims this structured access yields consistent 6--18% gains over strong baselines including GPT-5-mini and Gemini-3-flash on multi-view image and video spatial reasoning benchmarks, attributing the improvement to constrained operations rather than free-form tool use.
Significance. If the experimental results prove robust and the reconstruction quality is demonstrably sufficient, the work would be significant for VLM spatial reasoning by providing evidence that explicit 3D memory is most effective when accessed via a validated DSL rather than unconstrained tools. The design choice to parse and validate programs before execution directly targets a known brittleness in tool-augmented VLMs.
major comments (2)
- [Abstract] Abstract: the central claim of 6--18% gains over GPT-5-mini and Gemini-3-flash is presented without any dataset descriptions, baseline implementations, statistical tests, error bars, or ablation studies, preventing assessment of whether gains are attributable to usable 3D memory or to the DSL constraint itself.
- [Abstract] Abstract: the assumption that reconstruction VFMs reliably produce accurate enough explicit memory (point clouds + grounded instances) from sparse/redundant observations is load-bearing for the claimed gains, yet no reconstruction quality metrics, failure modes, or ablation isolating memory fidelity are supplied.
minor comments (1)
- The invented terms 'Reasmory' and 'lightweight DSL' appear without an explicit definition or comparison to prior DSLs for spatial or geometric reasoning.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where the abstract could better support assessment of the claims. The full manuscript contains the requested experimental details in Sections 4 and 5, but we agree the abstract presentation can be improved. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 6--18% gains over GPT-5-mini and Gemini-3-flash is presented without any dataset descriptions, baseline implementations, statistical tests, error bars, or ablation studies, preventing assessment of whether gains are attributable to usable 3D memory or to the DSL constraint itself.
Authors: The abstract is intentionally concise. The manuscript provides full details on the multi-view image and video spatial reasoning benchmarks, exact baseline implementations (including prompting strategies for GPT-5-mini and Gemini-3-flash), results with error bars and statistical tests, and ablations that separate the DSL constraint from free-form tool use and from the 3D memory itself. We will revise the abstract to briefly reference the evaluation benchmarks and note that ablations attribute gains to the validated DSL. revision: partial
-
Referee: [Abstract] Abstract: the assumption that reconstruction VFMs reliably produce accurate enough explicit memory (point clouds + grounded instances) from sparse/redundant observations is load-bearing for the claimed gains, yet no reconstruction quality metrics, failure modes, or ablation isolating memory fidelity are supplied.
Authors: We acknowledge that the current manuscript does not supply quantitative reconstruction quality metrics, explicit failure mode analysis, or an ablation isolating memory fidelity from the DSL. These elements are load-bearing and their absence limits evaluation of the framework. We will add reconstruction error metrics on the evaluation datasets, representative failure cases, and a dedicated ablation on memory fidelity in the revised version. revision: yes
Circularity Check
No circularity: empirical framework with independent experimental validation
full rationale
The paper introduces Reasmory as a constructive framework (explicit 3D memory + grounded instances + DSL-constrained program execution) and reports empirical gains of 6-18% on spatial reasoning benchmarks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim that constrained DSL access outperforms free-form tool use is tested directly via ablation-style comparisons against baselines including GPT-5-mini and Gemini-3-flash; these outcomes are not forced by definition or prior self-referential results. The derivation chain is self-contained as an engineering proposal whose value rests on external benchmark performance rather than internal reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reconstruction models produce sufficiently accurate explicit spatial memory from multi-view or video input
- domain assumption VLMs can produce valid programs in the introduced DSL
invented entities (2)
-
Reasmory framework
no independent evidence
-
lightweight DSL for spatial queries
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[2]
Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, An- drew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[3]
Tensorf: Tensorial radiance fields
Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. Tensorf: Tensorial radiance fields. InEuropean conference on computer vision, pages 333–350. Springer, 2022
2022
-
[4]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Danny Driess, Pete Florence, Brian Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities.arXiv preprint arXiv:2401.12168, 2024
arXiv 2024
-
[5]
TTT3r: 3d reconstruction as test-time training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. TTT3r: 3d reconstruction as test-time training. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum? id=aMs6FtNaY5
2026
-
[6]
Zhangquan Chen, Manyuan Zhang, Xinlei Yu, Xufang Luo, Mingze Sun, Zihao Pan, Yan Feng, Peng Pei, Xunliang Cai, and Ruqi Huang. Think with 3d: Geo- metric imagination grounded spatial reasoning from limited views.arXiv preprint arXiv:2510.18632, 2025
arXiv 2025
-
[7]
Flow3r: Fac- tored flow prediction for scalable visual geometry learning
Zhongxiao Cong, Qitao Zhao, Minsik Jeon, and Shubham Tulsiani. Flow3r: Fac- tored flow prediction for scalable visual geometry learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026. URLhttps://openaccess.thecvf.com/content/CVPR2026/html/ Cong_Flow3r_Factored_Flow_Prediction_for_Scalable_Visual_ Geometry_Learni...
2026
-
[8]
Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017
2017
-
[9]
Kevin Ellis, Catherine Wong, Maxwell Nye, Mathias Sablé-Meyer, Lucas Morales, Luke Hewitt, Luc Cary, Armando Solar-Lezama, and Joshua B. Tenenbaum. Dream- coder: bootstrapping inductive program synthesis with wake-sleep library learning. InProceedings of the 42nd ACM SIGPLAN International Conference on Program- ming Language Design and Implementation, PLD...
-
[10]
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Shijie Zhou, Dilin Wang, et al. Vlm-3r: Vision- language models augmented with instruction-aligned 3d reconstruction.arXiv preprint arXiv:2505.20279, 2025
Pith/arXiv arXiv 2025
-
[11]
Video-r1: Reinforcing video reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in MLLMs. InThe Thirty-ninth Annual Conference on Neural Infor- mation Processing Systems, 2026. URLhttps://openreview.net/forum? id=a2JTVVvcEl
2026
-
[12]
Pearson Education, 2010
Martin Fowler.Domain-Specific Languages, Portable Documents. Pearson Education, 2010
2010
-
[13]
Pal: Program-aided language models.arXiv preprint arXiv:2211.10435, 2022
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models.arXiv preprint arXiv:2211.10435, 2022
Pith/arXiv arXiv 2022
-
[14]
Pursuing minimal sufficiency in spatial reasoning
Yejie Guo, Yunzhong Hou, Wufei Ma, Meng Tang, and Ming-Hsuan Yang. Pursuing minimal sufficiency in spatial reasoning. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum? id=bZAKJwyn1n
2026
-
[15]
Visual programming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reasoning without training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14953–14962, 2023
2023
-
[16]
Lixuan He, Haoyu Dong, Zhenxing Chen, Yangcheng Yu, Jie Feng, and Yong Li. Mem4nav: Boosting vision-and-language navigation in urban environments with a hierarchical spatial-cognition long-short memory system.arXiv preprint arXiv:2506.19433, 2025
arXiv 2025
-
[17]
Wenbo Hu, Jingli Lin, Yilin Long, Yunlong Ran, Lihan Jiang, Yifan Wang, Chenming Zhu, Runsen Xu, Tai Wang, and Jiangmiao Pang. G 2vlm: Geometry grounded vision language model with unified 3d reconstruction and spatial reasoning.arXiv preprint arXiv:2511.21688, 2025
arXiv 2025
-
[18]
Xiaohu Huang, Jingjing Wu, Qunyi Xie, and Kai Han. Mllms need 3d-aware represen- tation supervision for scene understanding.CoRR, abs/2506.01946, June 2025. URL https://doi.org/10.48550/arXiv.2506.01946
-
[19]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4): 139–1, 2023
2023
-
[20]
Open- vla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Open- vla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 18HE, LI, LIN AND Y ANG: REASMORY
Pith/arXiv arXiv 2024
-
[21]
Spatialladder: Pro- gressive training for spatial reasoning in vision-language models
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatialladder: Pro- gressive training for spatial reasoning in vision-language models. InThe Four- teenth International Conference on Learning Representations, 2026. URLhttps: //openreview.net/forum?id=KtrFXlvgrK
2026
-
[22]
Vmem: Consistent interac- tive video scene generation with surfel-indexed view memory
Runjia Li, Philip Torr, Andrea Vedaldi, and Tomas Jakab. Vmem: Consistent interac- tive video scene generation with surfel-indexed view memory. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25690–25699, 2025
2025
-
[23]
Chen, Zhenyu Li, Yang Zhao, Sida Peng, Hengkai Guo, Xiaowei Zhou, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Yang Zhao, Sida Peng, Hengkai Guo, Xiaowei Zhou, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views. InThe Four- teenth International Conference on Learning Representations, 2026. URLhttps: //openreview.net/forum?id=yirunib8l8
2026
-
[24]
Msnav: Zero-shot vision-and-language navigation with dynamic mem- ory and llm spatial reasoning
Chenghao Liu, Zhimu Zhou, Jiachen Zhang, Minghao Zhang, Songfang Huang, and Huiling Duan. Msnav: Zero-shot vision-and-language navigation with dynamic mem- ory and llm spatial reasoning. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 20112–20116. IEEE, 2026
2026
-
[25]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[26]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
2024
-
[27]
Dynamem: Online dynamic spatio-semantic memory for open world mobile manipulation
Peiqi Liu, Zhanqiu Guo, Mohit Warke, Soumith Chintala, Chris Paxton, Nur Muham- mad Mahi Shafiullah, and Lerrel Pinto. Dynamem: Online dynamic spatio-semantic memory for open world mobile manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13346–13355. IEEE, 2025
2025
-
[28]
Zhanpeng Luo, Ce Zhang, Silong Yong, Cunxi Dai, Qianwei Wang, Haoxi Ran, Guanya Shi, Katia Sycara, and Yaqi Xie. pyspatial: Generating 3d visual programs for zero-shot spatial reasoning.arXiv preprint arXiv:2603.00905, 2026
arXiv 2026
-
[29]
Nerf in the wild: Neural radiance fields for uncon- strained photo collections
Ricardo Martin-Brualla, Noha Radwan, Mehdi SM Sajjadi, Jonathan T Barron, Alexey Dosovitskiy, and Daniel Duckworth. Nerf in the wild: Neural radiance fields for uncon- strained photo collections. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7210–7219, 2021
2021
-
[30]
When and how to develop domain-specific languages.ACM computing surveys (CSUR), 37(4):316–344, 2005
Marjan Mernik, Jan Heering, and Anthony M Sloane. When and how to develop domain-specific languages.ACM computing surveys (CSUR), 37(4):316–344, 2005
2005
-
[31]
Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ra- mamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
2021
-
[32]
Instant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graph- ics (TOG), 41(4):1–15, 2022
Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graph- ics (TOG), 41(4):1–15, 2022. HE, LI, LIN AND Y ANG: REASMORY19
2022
-
[33]
Oxford university press, 1978
John O’keefe and Lynn Nadel.The hippocampus as a cognitive map. Oxford university press, 1978
1978
-
[34]
Single unit activity in the rat hippocampus during a spatial memory task.Experimental brain research, 68(1):1–27, 1987
John O’Keefe and Andrew Speakman. Single unit activity in the rat hippocampus during a spatial memory task.Experimental brain research, 68(1):1–27, 1987
1987
-
[35]
Spacer: Reinforcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Reinforcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025
Pith/arXiv arXiv 2025
-
[36]
Long-context state-space video world models
Ryan Po, Yotam Nitzan, Richard Zhang, Berlin Chen, Tri Dao, Eli Shechtman, Gordon Wetzstein, and Xun Huang. Long-context state-space video world models. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 8733–8744, 2025
2025
-
[37]
Zhangyang Qi, Zhixiong Zhang, Yizhou Yu, Jiaqi Wang, and Hengshuang Zhao. Vln-r1: Vision-language navigation via reinforcement fine-tuning.arXiv preprint arXiv:2506.17221, 2025
arXiv 2025
-
[38]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational confer- ence on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[39]
Vqasynth, 2024
remyxai. Vqasynth, 2024. URLhttps://github.com/remyxai/VQASynth/ tree/main. GitHub repository
2024
-
[40]
Statespacediffuser: Bringing long context to diffusion world models
Nedko Savov, Naser Kazemi, Deheng Zhang, Danda Pani Paudel, Xi Wang, and Luc Van Gool. Statespacediffuser: Bringing long context to diffusion world models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=g52NwTQj0Q
2026
-
[41]
Toolformer: Lan- guage models can teach themselves to use tools.Advances in neural information pro- cessing systems, 36:68539–68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Lan- guage models can teach themselves to use tools.Advances in neural information pro- cessing systems, 36:68539–68551, 2023
2023
-
[42]
The development of spatial representations of large-scale environments.Advances in child development and behavior, 10:9–55, 1975
Alexander W Siegel and Sheldon H White. The development of spatial representations of large-scale environments.Advances in child development and behavior, 10:9–55, 1975
1975
-
[43]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11888–11898, 2023
2023
-
[44]
Cognitive maps in rats and men.Psychological review, 55(4):189, 1948
Edward C Tolman. Cognitive maps in rats and men.Psychological review, 55(4):189, 1948
1948
-
[45]
3d reconstruction with spatial memory
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory. In2025 International Conference on 3D Vision (3DV), pages 78–89. IEEE, 2025. 20HE, LI, LIN AND Y ANG: REASMORY
2025
-
[46]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[47]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
2025
-
[48]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[49]
$\pi^3$: Permutation- equivariant visual geometry learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. $\pi^3$: Permutation- equivariant visual geometry learning. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum? id=DTQIjngDta
2026
-
[50]
Spatial-MLLM: Boost- ing MLLM capabilities in visual-based spatial intelligence
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-MLLM: Boost- ing MLLM capabilities in visual-based spatial intelligence. InThe Thirty-ninth An- nual Conference on Neural Information Processing Systems, 2026. URLhttps: //openreview.net/forum?id=RnXS7aK4rK
2026
-
[51]
Point3r: Streaming 3d recon- struction with explicit spatial pointer memory
Yuqi Wu, Wenzhao Zheng, Jie Zhou, and Jiwen Lu. Point3r: Streaming 3d recon- struction with explicit spatial pointer memory. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview. net/forum?id=yk1iqV9Etr
2026
-
[52]
Worldmem: Long-term consistent world simulation with memory
Zeqi Xiao, Yushi LAN, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xingang Pan. Worldmem: Long-term consistent world simulation with memory. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=c6CAVKlKmU
2026
-
[53]
Maskclustering: View consensus based mask graph clustering for open-vocabulary 3d instance segmentation
Mi Yan, Jiazhao Zhang, Yan Zhu, and He Wang. Maskclustering: View consensus based mask graph clustering for open-vocabulary 3d instance segmentation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[54]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
2025
-
[55]
Mindjourney: Test-time scaling with world mod- els for spatial reasoning
Yuncong Yang, Jiageng Liu, Zheyuan Zhang, Siyuan Zhou, Reuben Tan, Jianwei Yang, Yilun Du, and Chuang Gan. Mindjourney: Test-time scaling with world mod- els for spatial reasoning. InThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2026. URLhttps://openreview.net/forum?id= L2W4wQsNkY
2026
-
[56]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023. HE, LI, LIN AND Y ANG: REASMORY21
2023
-
[57]
Spa- tial mental modeling from limited views
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, et al. Spa- tial mental modeling from limited views. InStructural Priors for Vision Workshop at ICCV’25, 2025
2025
-
[58]
Instainpaint: Instant 3d-scene inpainting with masked large reconstruction model
Junqi You, Chieh Hubert Lin, Weijie Lyu, Zhengbo Zhang, and Ming-Hsuan Yang. Instainpaint: Instant 3d-scene inpainting with masked large reconstruction model. In Adv. Neural Inform. Process. Syst., 2025
2025
-
[59]
Context as memory: Scene-consistent interactive long video generation with memory retrieval
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval. InProceedings of the SIGGRAPH Asia 2025 Conference Pa- pers, pages 1–11, 2025
2025
-
[60]
Jiangye Yuan, Gowri Kumar, and Baoyuan Wang. Boosting mllm spatial reasoning with geometrically referenced 3d scene representations.arXiv preprint arXiv:2603.08592, 2026
Pith/arXiv arXiv 2026
-
[61]
3dgraphllm: Combining semantic graphs and large language models for 3d scene understanding
Tatiana Zemskova and Dmitry Yudin. 3dgraphllm: Combining semantic graphs and large language models for 3d scene understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8885–8895, 2025
2025
-
[62]
Junyi Zhang, Charles Herrmann, Junhwa Hur, Chen Sun, Ming-Hsuan Yang, Forrester Cole, Trevor Darrell, and Deqing Sun. Loger: Long-context geometric reconstruction with hybrid memory.arXiv preprint arXiv:2603.03269, 2026
Pith/arXiv arXiv 2026
-
[63]
Puzhen Zhang, Xuyang Chen, Yu Feng, Yuhan Jiang, and Liqiu Meng. Construct- ing coherent spatial memory in llm agents through graph rectification.arXiv preprint arXiv:2510.04195, 2025
Pith/arXiv arXiv 2025
-
[64]
Freeman, and Hao Tan
Tianyuan Zhang, Sai Bi, Yicong Hong, Kai Zhang, Fujun Luan, Songlin Yang, Kalyan Sunkavalli, William T. Freeman, and Hao Tan. Test-time training done right. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=Tb9qAxT3xv
2026
-
[65]
Think3d: Thinking with space for spatial reasoning.arXiv preprint arXiv:2601.13029, 2026
Zaibin Zhang, Yuhan Wu, Lianjie Jia, Yifan Wang, Zhongbo Zhang, Yijiang Li, Bing- hao Ran, Fuxi Zhang, Zhuohan Sun, Zhenfei Yin, et al. Think3d: Thinking with space for spatial reasoning.arXiv preprint arXiv:2601.13029, 2026
arXiv 2026
-
[66]
Ruosen Zhao, Zhikang Zhang, Jialei Xu, Jiahao Chang, Dong Chen, Lingyun Li, Wei- jian Sun, and Zizhuang Wei. Spacemind: Camera-guided modality fusion for spatial reasoning in vision-language models.arXiv preprint arXiv:2511.23075, 2025
arXiv 2025
-
[67]
Vlm4d: Towards spatiotemporal awareness in vision language models
Shijie Zhou, Alexander Vilesov, Xuehai He, Ziyu Wan, Shuwang Zhang, Aditya Na- gachandra, Di Chang, Dongdong Chen, Xin Eric Wang, and Achuta Kadambi. Vlm4d: Towards spatiotemporal awareness in vision language models. InProceedings of the IEEE/CVF international conference on computer vision, pages 8600–8612, 2025
2025
-
[68]
Learning 3d persistent embodied world models.arXiv preprint arXiv:2505.05495, 2025
Siyuan Zhou, Yilun Du, Yuncong Yang, Lei Han, Peihao Chen, Dit-Yan Yeung, and Chuang Gan. Learning 3d persistent embodied world models.arXiv preprint arXiv:2505.05495, 2025. 22HE, LI, LIN AND Y ANG: REASMORY
arXiv 2025
-
[69]
Stream- ing visual geometry transformer
Dong Zhuo, Wenzhao Zheng, Jiahe Guo, Yuqi Wu, Jie Zhou, and Jiwen Lu. Stream- ing visual geometry transformer. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum? id=5APgTKsnx8
2026
-
[70]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.