TravelEval: A Comprehensive Benchmarking Framework for Evaluating LLM-Powered Travel Planning Agents
Pith reviewed 2026-06-28 17:18 UTC · model grok-4.3
The pith
TravelEval introduces a six-dimensional benchmark and global simulation method that exposes LLMs' consistent failures in optimized multi-day travel planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TravelEval supplies a six-dimensional evaluation framework covering accuracy, compliance, temporality, spatiality, economy and utility, a data sandbox with precise accommodation prices and intercity transport, and a simulation engine that runs complete itineraries with geographic APIs and fine-grained queuing. When twelve mainstream LLM and agent pipelines are tested inside this environment, they exhibit systematic shortfalls in globally consistent spatio-temporal reasoning and budget compliance, with agentic reasoning variants showing no uniform advantage over simpler prompting.
What carries the argument
The six-dimensional evaluation framework together with the simulation-based global evaluation method that emulates full travel plans rather than isolated daily segments.
If this is right
- LLM travel planners must be evaluated on cumulative effects across an entire trip rather than per-day compliance alone.
- Improvements in spatio-temporal reasoning and budget tracking are required before these systems can be deployed for realistic multi-city itineraries.
- Agentic scaffolding alone does not guarantee better global optimization in this domain.
- Future benchmarks should incorporate authentic pricing and transport data to avoid optimistic results from synthetic datasets.
Where Pith is reading between the lines
- The same global-simulation approach could be adapted to evaluate LLM agents in other sequential planning tasks such as logistics routing or event scheduling.
- If the benchmark's weaknesses prove real, training objectives for travel LLMs should shift from local constraint satisfaction toward explicit multi-objective optimization across time and space.
- Developers might need hybrid systems that combine LLMs with dedicated optimization solvers for the dimensions the models handle least reliably.
Load-bearing premise
The six-dimensional scores plus the simulation engine together produce measurements that correspond to the quality and outcomes that real travelers would experience.
What would settle it
A controlled user study in which plans ranked highest by TravelEval are actually booked and executed, then rated for satisfaction, missed connections, and total cost overruns; if those real-world outcomes diverge sharply from the benchmark rankings, the framework's validity is undermined.
Figures

read the original abstract
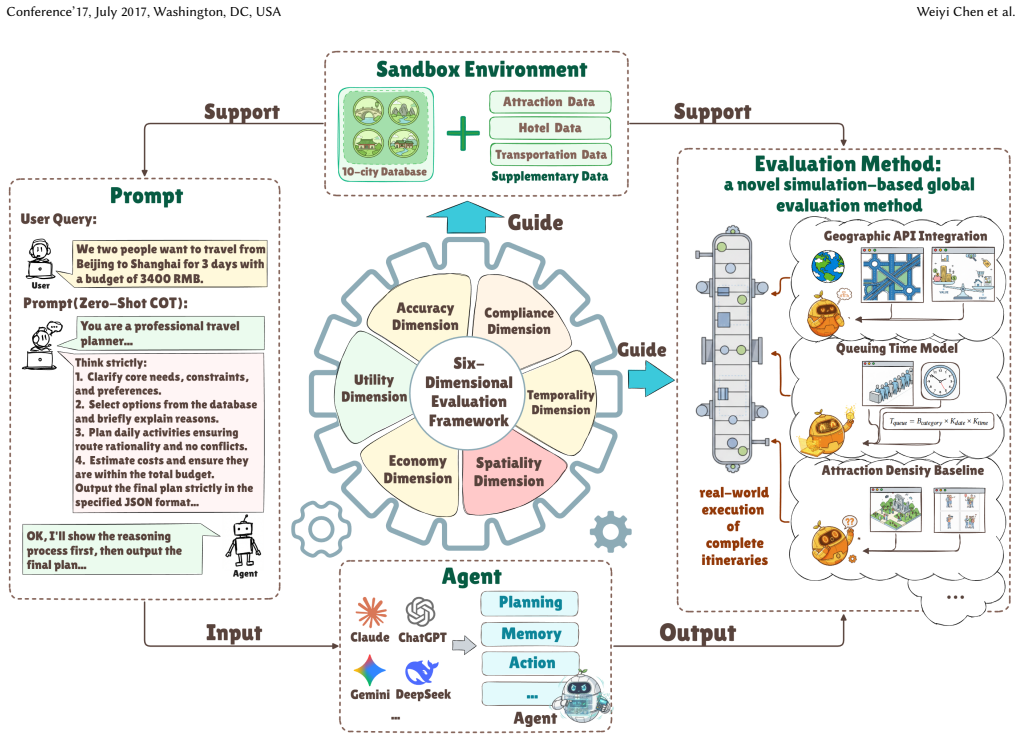
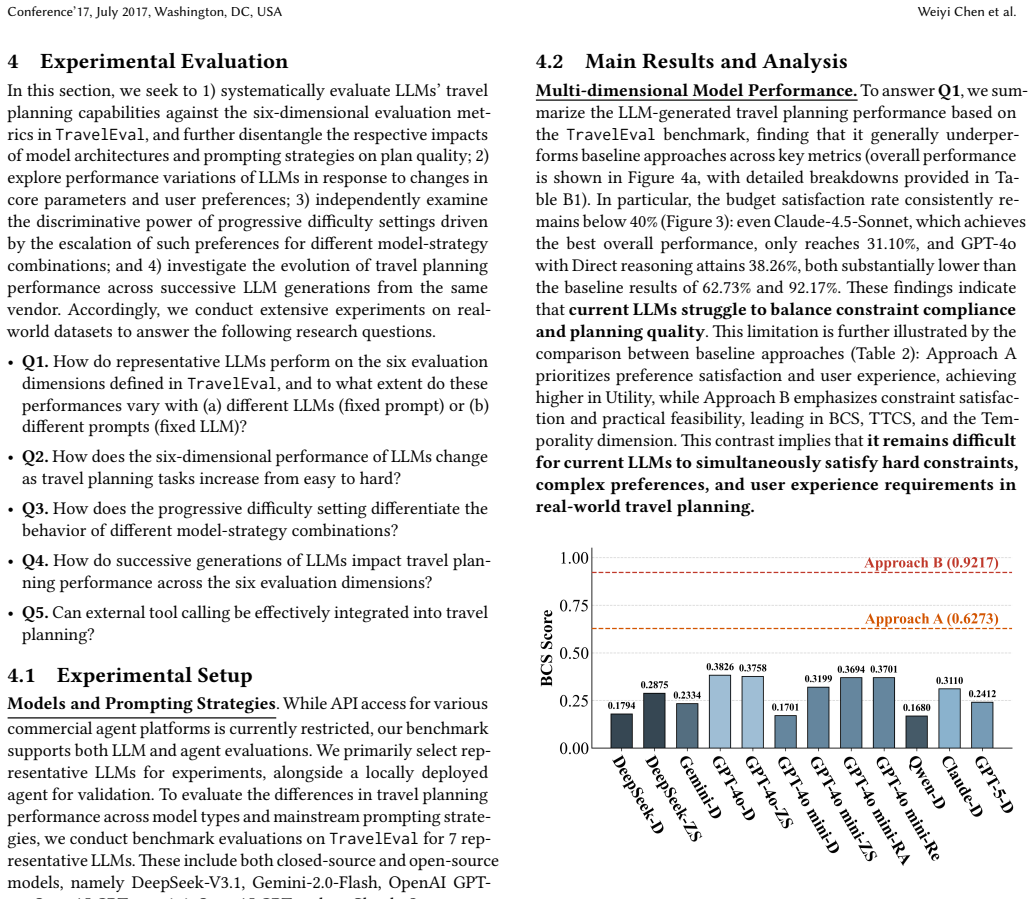
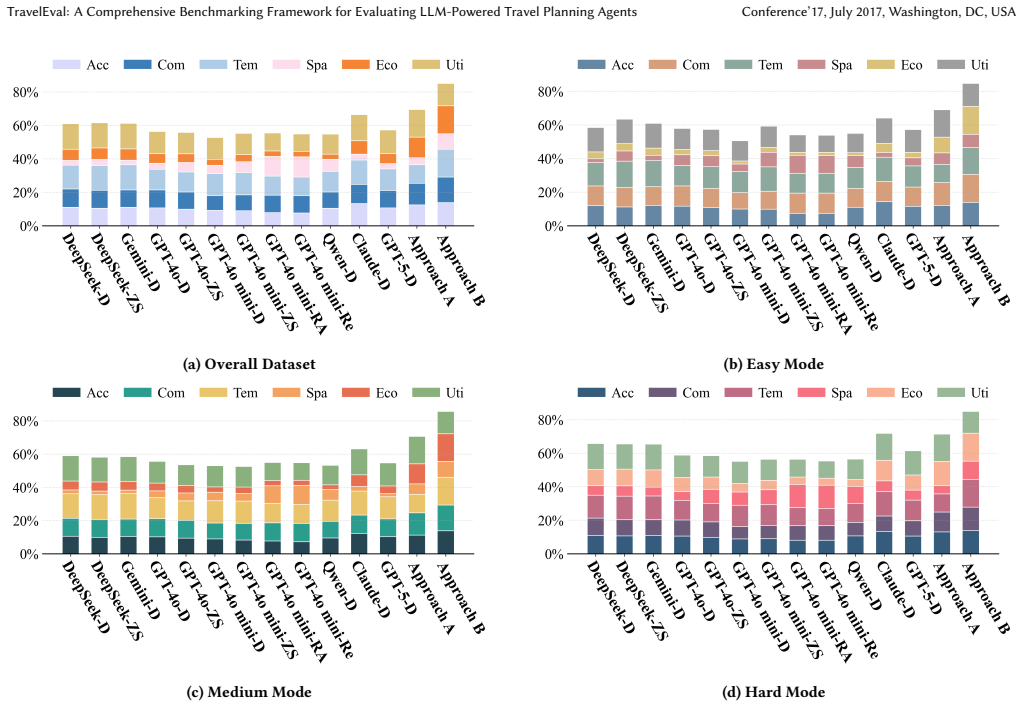
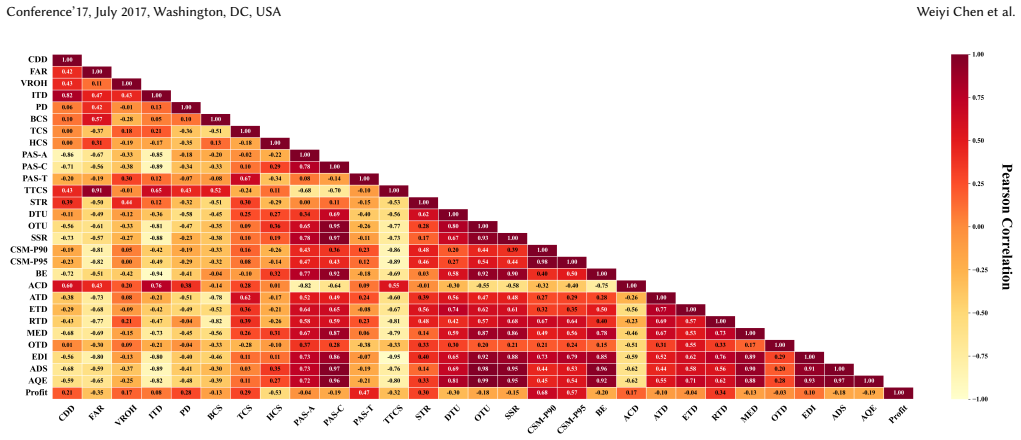
The development of Large Language Models (LLMs) has significantly improved travel planning applications, yet evaluating such models is limited by existing benchmarks' limitations: 1) overemphasis on constraint compliance, neglecting multi-dimensional qualities like spatio-temporal cost; 2) datasets lacking real-world authenticity and coverage in key areas (e.g., lodging, transport); and 3) isolated daily plan assessments that miss critical details (e.g., the impact of daily accommodation and visit pacing) needed for entire plan's evaluation. To address this gap, we introduce TravelEval, a realistic and comprehensive benchmark. TravelEval features 1) a novel six-dimensional evaluation framework to holistically assess plans across accuracy, compliance, temporality, spatiality, economy, and utility dimensions; 2) a highly realistic data sandbox with precise accommodation pricing and authentic intercity transportation data; and 3) a simulation-based global evaluation method that emulates complete travel plans with API-integrated geographic information and fine-grained queuing time. Evaluating 12 mainstream approaches with TravelEval reveals several valuable insights, such that LLMs struggle with globally-optimized multi-dimensional planning (especially in spatio-temporal reasoning and budget compliance), and agentic reasoning strategies offer no consistent improvement. Concisely, TravelEval facilitates travel plan evaluation via grounded spatio-temporal emulation and comprehensive metrics, providing a robust foundation for advancing LLM-powered travel planning research and applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TravelEval, a benchmark for LLM-powered travel planning agents that addresses gaps in prior work via (1) a six-dimensional evaluation framework (accuracy, compliance, temporality, spatiality, economy, utility), (2) a realistic data sandbox with precise accommodation pricing and authentic intercity transport data, and (3) a simulation-based global evaluator that incorporates API-integrated geography and fine-grained queuing times. Evaluating 12 mainstream approaches yields the claims that LLMs struggle with globally-optimized multi-dimensional planning (especially spatio-temporal reasoning and budget compliance) and that agentic reasoning strategies provide no consistent improvement.
Significance. If the six-dimensional framework and simulation method are shown to track real-world user outcomes, TravelEval would supply a more holistic evaluation tool than existing constraint-focused or daily-isolated benchmarks, potentially guiding progress on complex planning agents. The reported insights on LLM limitations would then be actionable for the field.
major comments (2)
- [Abstract / Evaluation Framework] Abstract and § on the six-dimensional framework: the headline finding that LLMs struggle with globally-optimized multi-dimensional planning is derived entirely from scores produced by the new benchmark. No external validation (human ratings, correlation with existing user studies, or ablation demonstrating that the six dimensions predict downstream success) is supplied, leaving open the possibility that reported deficiencies are metric artifacts. This assumption is load-bearing for all reported insights.
- [Abstract / Simulation Method] Abstract and § on simulation-based global evaluation: the claim that isolated daily assessments miss critical inter-day effects (accommodation, pacing) is used to motivate the new method, yet the manuscript supplies no implementation details, reproducibility artifacts, or comparison against human judgments of complete itineraries. Without such grounding the quantitative results on the 12 approaches cannot be interpreted reliably.
minor comments (1)
- [Abstract] The abstract states that the data sandbox includes 'precise accommodation pricing and authentic intercity transportation data' but does not name the sources, coverage, or update frequency; adding these details would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on validation and grounding of the evaluation framework and simulation method. We respond to each major comment below, proposing targeted revisions to qualify claims and add details where feasible while remaining faithful to the manuscript's content.
read point-by-point responses
-
Referee: [Abstract / Evaluation Framework] Abstract and § on the six-dimensional framework: the headline finding that LLMs struggle with globally-optimized multi-dimensional planning is derived entirely from scores produced by the new benchmark. No external validation (human ratings, correlation with existing user studies, or ablation demonstrating that the six dimensions predict downstream success) is supplied, leaving open the possibility that reported deficiencies are metric artifacts. This assumption is load-bearing for all reported insights.
Authors: We agree that external validation such as human ratings or correlations with user studies would strengthen the claims. The six dimensions are motivated by gaps identified in prior benchmarks (constraint-only focus) and travel planning literature on multi-faceted user needs, but the manuscript does not include such validation or ablations. In revision we will add a subsection detailing the literature-based rationale for each dimension and revise the abstract, results, and conclusion to present the LLM limitations as observations within the TravelEval benchmark rather than unvalidated real-world conclusions. This tempers the headline findings appropriately. revision: yes
-
Referee: [Abstract / Simulation Method] Abstract and § on simulation-based global evaluation: the claim that isolated daily assessments miss critical inter-day effects (accommodation, pacing) is used to motivate the new method, yet the manuscript supplies no implementation details, reproducibility artifacts, or comparison against human judgments of complete itineraries. Without such grounding the quantitative results on the 12 approaches cannot be interpreted reliably.
Authors: The simulation method is described in the methods section as emulating full itineraries via API-integrated geography and queuing times to capture inter-day effects. However, we acknowledge the referee's point that additional implementation details and reproducibility artifacts are needed. In revision we will expand the methods with pseudocode for the simulation process, explicit data sources, and example itineraries illustrating inter-day impacts. Direct human judgment comparisons are not present in the current work; we will add a limitations paragraph noting this and suggesting it as future validation. revision: yes
Circularity Check
No significant circularity; benchmark is independently defined and applied
full rationale
The paper introduces TravelEval as a novel six-dimensional evaluation framework plus simulation-based global evaluator, then reports empirical scores obtained by running 12 external LLM approaches through it. No equations, parameters, or results are fitted inside the paper and then renamed as predictions; the six dimensions (accuracy, compliance, temporality, spatiality, economy, utility) and the simulation method are presented as author-defined contributions rather than derived from the LLM outputs themselves. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the central claims. The reported finding that LLMs struggle with globally-optimized planning is therefore an external measurement, not a tautology.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The six dimensions (accuracy, compliance, temporality, spatiality, economy, utility) together provide a holistic assessment of travel plans.
- domain assumption The simulation-based global evaluation with API-integrated geographic information and queuing times produces outcomes that reflect real travel feasibility.
Reference graph
Works this paper leans on
-
[1]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. 2024. A Survey on Evaluation of Large Language Models. ACM Trans. Intell. Syst. Technol.15, 3, Article 39 (March 2024), 45 pages. doi:10.1145/3641289
- [2]
- [3]
-
[4]
Shimin Di, Xujie Yuan, Hanghui Guo, Chaoqian Ouyang, Zhangze Chen, Ling Yue, Libin Zheng, Jia Zhu, Shaowu Pan, Jian Yin, Min-Ling Zhang, and Yong Rui. [n. d.]. ToolRosetta: Bridging Open-Source Repositories and Large Lan- guage Model Agents through Automated Tool Standardization. https://api. semanticscholar.org/CorpusID:287352048
-
[5]
João Paulo Esper, Luciano de S. Fraga, Aline C. Viana, Kleber Vieira Cardoso, and Sand Luz Correa. 2025. +Tour: Recommending personalized itineraries for smart tourism. Computer Networks 260 (2025), 111118. doi:10.1016/j.comnet. 2025.111118
-
[6]
P.J. Fedor and I.F. Spellerberg. 2013. Shannon ⚶Wiener Index. In Reference Mod- ule in Earth Systems and Environmental Sciences . Elsevier. doi:10.1016/B978-0- 12-409548-9.00602-3
-
[7]
Damianos Gavalas, Charalampos Konstantopoulos, Konstantinos Mastakas, and Grammati Pantziou. 2014. A survey on algorithmic approaches for solving tourist trip design problems. Journal of Heuristics 20 (06 2014), 291–328. doi:10. 1007/s10732-014-9242-5
2014
-
[8]
Sunyoung Hlee, Zhijun Yan, and Ping Li. 2025. AI-powered travel recom- mendations and decision-making: The role of spatio-temporal efficiency, des- tination type, and travel party composition. Electron. Mark. 35, 1 (2025), 75. doi:10.1007/S12525-025-00825-4
-
[9]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large Language Models are Zero-Shot Reasoners. ArXiv abs/2205.11916 (2022). https://api.semanticscholar.org/CorpusID:249017743
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Haoyang Li, Xuejia Chen, Zhanchao Xu, Darian Li, Nicole Hu, Fei Teng, Yiming Li, Luyu Qiu, Chen Jason Zhang, Li Qing, et al. 2025. Exposing numeracy gaps: A benchmark to evaluate fundamental numerical abilities in large language mod- els. In Findings of the Association for Computational Linguistics: ACL 2025. 20004– 20026
2025
-
[11]
Kwan Hui Lim, Jeffrey Chan, Christopher Leckie, and Shanika Karunasekera
-
[12]
In IJCAI, Vol
Personalized tour recommendation based on user interests and points of interest visit durations.. In IJCAI, Vol. 15. 1778–1784
-
[13]
Hang Ni, Fan Liu, Xinyu Ma, Lixin Su, Shuaiqiang Wang, Dawei Yin, Hui Xiong, and Hao Liu. 2025. TP-RAG: Benchmarking Retrieval-Augmented Large Lan- guage Model Agents for Spatiotemporal-Aware Travel Planning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing . Association for Computational Linguistics, 12403 ⚶12429....
- [14]
- [15]
-
[16]
Shaowu Pan, Ling Yue, Nithin Somasekharan, Tingwen Zhang, Yadi Cao, Zhangze Chen, and Shimin Di. 2026. Automating Computational Fluid Dynam- ics with LLM-based Multi-Agent Systems. (2026)
2026
-
[17]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. 2023. Toolllm: Facilitating large lan- guage models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [18]
-
[19]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems 36 (2023), 68539–68551
2023
-
[20]
Jie-Jing Shao, Bo-Wen Zhang, Xiao-Wen Yang, Baizhi Chen, Si-Yu Han, Wen-Da Wei, Guohao Cai, Zhenhua Dong, Lan-Zhe Guo, and Yu-Feng Li. 2024. Chi- naTravel: An Open-Ended Benchmark for Language Agents in Chinese Travel Planning. arXiv preprint arXiv:2412.13682 (2024). arXiv: 2412.13682 [cs.AI]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv: 2303.11366 [cs.AI] https://arxiv.org/abs/2303. 11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Yihong Tang, Zhaokai Wang, Ao Qu, Yihao Yan, Zhaofeng Wu, Dingyi Zhuang, Jushi Kai, Kebing Hou, Xiaotong Guo, Jinhua Zhao, Zhan Zhao, and Wei Ma
-
[23]
ItiNera: Integrating Spatial Optimization with Large Language Models for Open-domain Urban Itinerary Planning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , Franck Der- noncourt, Daniel Preoţiuc-Pietro, and Anastasia Shimorina (Eds.). Association for Computational Linguistics, Miami, Florida, U...
-
[24]
Jialiang Wang, Yuchen Liu, Hang Xu, Kaichun Hu, Shimin Di, Wangze Ni, Linan Yue, Min-Ling Zhang, Kui Ren, and Lei Chen. 2026. When AI reviews sci- ence: Can we trust the referee? The Innovation Informatics (2026). https: //api.semanticscholar.org/CorpusID:285573947
2026
-
[25]
Kaimin Wang, Yuanzhe Shen, Changze Lv, Xiaoqing Zheng, and Xuan-Jing Huang. 2025. Triptailor: A real-world benchmark for personalized travel plan- ning. In Findings of the Association for Computational Linguistics: ACL 2025 . 9705–9723
2025
-
[26]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2024. A survey on large language model based autonomous agents. Frontiers of Computer Science 18, 6 (2024), 186345. doi:10.1007/s11704-024-40231-1
- [27]
-
[28]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv: 2201.11903 [cs.CL] https: //arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
World Travel & Tourism Council. 2024. Travel & Tourism Economic Impact. https://wttc.org/research/economic-impact. Accessed: 2026-01-12
2024
-
[30]
Xiongbin Wu, Hongzhi Guan, Yan Han, and Jiaqi Ma. 2017. A tour route planning model for tourism experience utility maximization. Advances in Mechanical Engineering 9, 10 (2017), 1687814017732309. arXiv:https://doi.org/10.1177/1687814017732309 doi:10.1177/1687814017732309
-
[31]
Jian Xie, Yidan Liang, Jingping Liu, Yanghua Xiao, Baohua Wu, and Shenghua Ni. 2023. QUERT: Continual Pre-training of Language Model for Query Un- derstanding in Travel Domain Search. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (Long Beach, CA, USA) (KDD ’23) . Association for Computing Machinery, New York, NY, ...
2023
-
[32]
doi:10.1145/3580305.3599891
-
[33]
Jian Xie, Kai Zhang, Jiangjie Chen, Tinghui Zhu, Renze Lou, Yuandong Tian, Yanghua Xiao, and Yu Su. 2024. TravelPlanner: A Benchmark for Real-World Planning with Language Agents. In Proceedings of the 41st International Confer- ence on Machine Learning (ICML) . arXiv: 2402.01622 [cs.CL] Spotlight Paper
-
[34]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv: 2210.03629 [cs.CL] https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Lin Zhong, Jun Zeng, Ziwei Wang, Wei Zhou, and Junhao Wen. 2024. SCFL: Spatio-temporal consistency federated learning for next POI recommendation. Information Processing & Management 61, 6 (2024), 103852. doi:10.1016/j.ipm. 2024.103852 TravelEval: A Comprehensive Benchmarking Framework for Evaluating LLM-Powered Travel Planning Agents Conference’17, July ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.