DAG-MoE: From Simple Mixture to Structural Aggregation in Mixture-of-Experts
Pith reviewed 2026-06-28 17:12 UTC · model grok-4.3
The pith
Replacing weighted summation with learned structural aggregation among experts expands the combination space in a single MoE layer without changing the experts or router.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
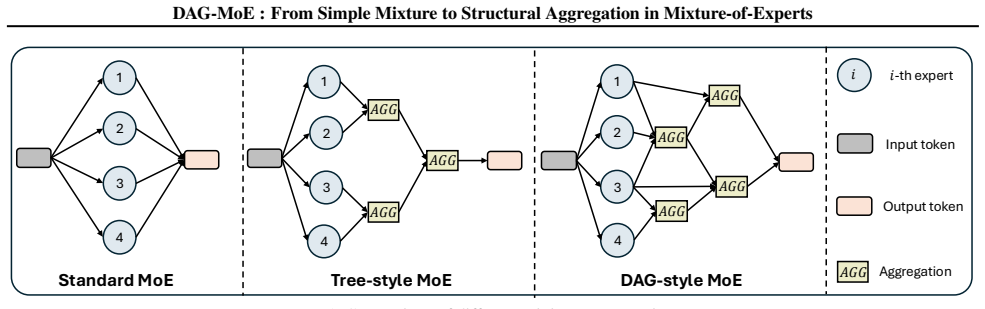
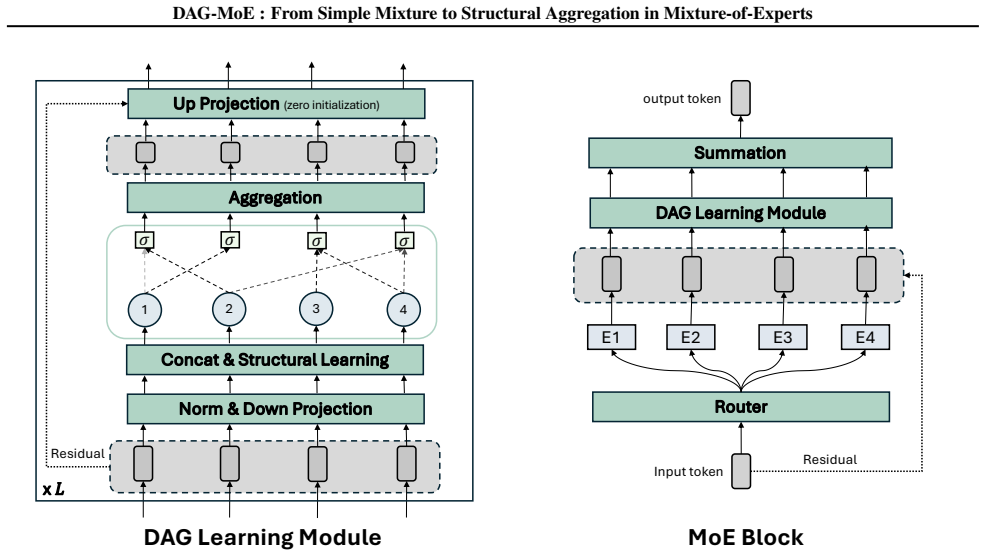
Replacing the standard weighted-summation aggregation with structural aggregation expands the expert-combination space without altering the experts or router, and enables possible multi-step reasoning within a single MoE layer. DAG-MoE implements this by using a lightweight module to automatically learn the optimal aggregation structure among the selected experts.
What carries the argument
The learned DAG structural aggregation module that combines outputs from selected experts according to a directed acyclic graph rather than a weighted sum.
If this is right
- The space of reachable expert combinations grows combinatorially with the number of selected experts.
- Multi-step reasoning becomes possible inside one MoE layer via the DAG paths.
- Routing overhead stays unchanged because the router itself is not modified.
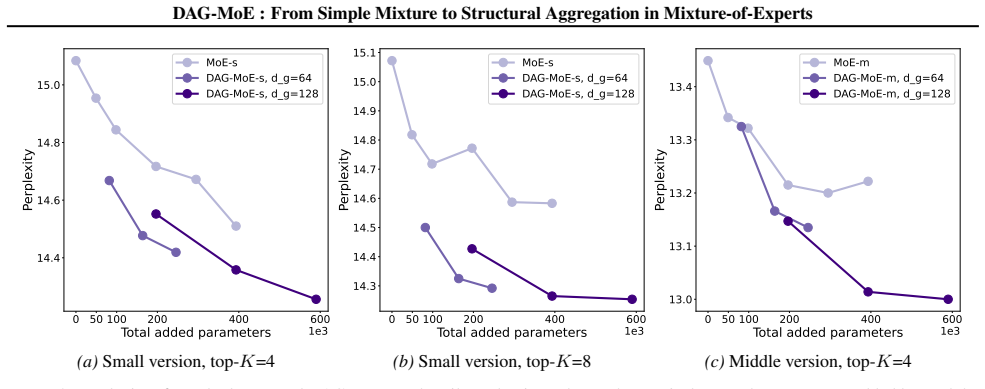
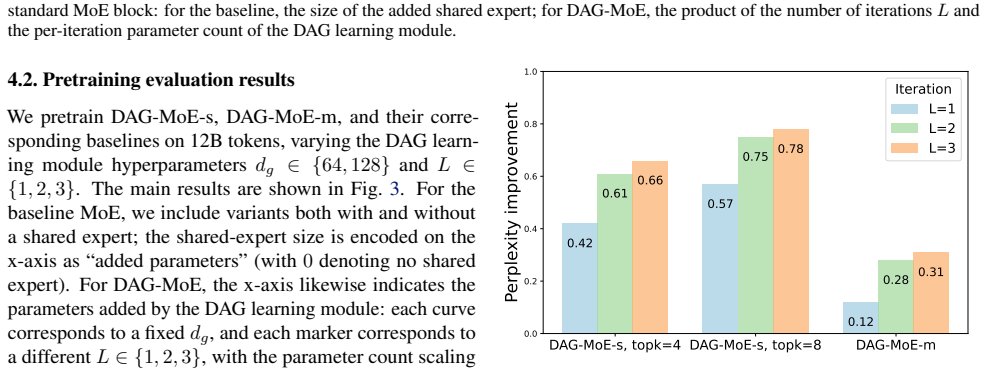
- Performance improves on standard pretraining and fine-tuning language modeling tasks.
- The approach remains compatible with existing sparse MoE training pipelines.
Where Pith is reading between the lines
- The method could be stacked with fine-grained expert designs to multiply the gains from both axes.
- Similar structural aggregation might be tested in vision or multimodal MoE models to check domain generality.
- If the learned DAGs stabilize across training runs, they could reveal interpretable reasoning patterns among experts.
- Applying the same idea to attention heads or other modular components could extend the principle beyond MoE layers.
Load-bearing premise
A lightweight module can automatically learn an optimal aggregation structure among selected experts that delivers the claimed expansion in combination space and performance gains without introducing new scalability bottlenecks or overfitting.
What would settle it
Running the same experts and router with structural aggregation versus standard weighted summation on a held-out language modeling benchmark and finding no accuracy improvement or higher compute cost.
Figures
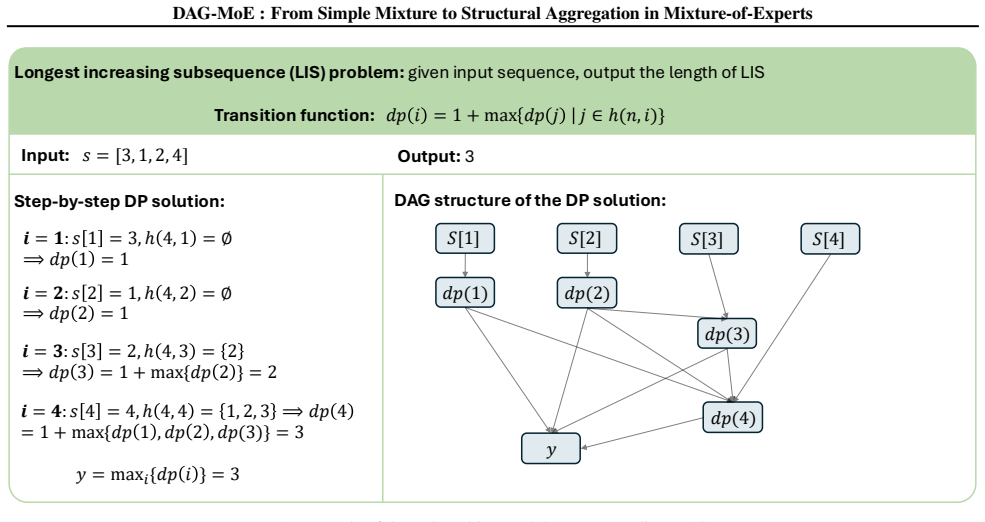
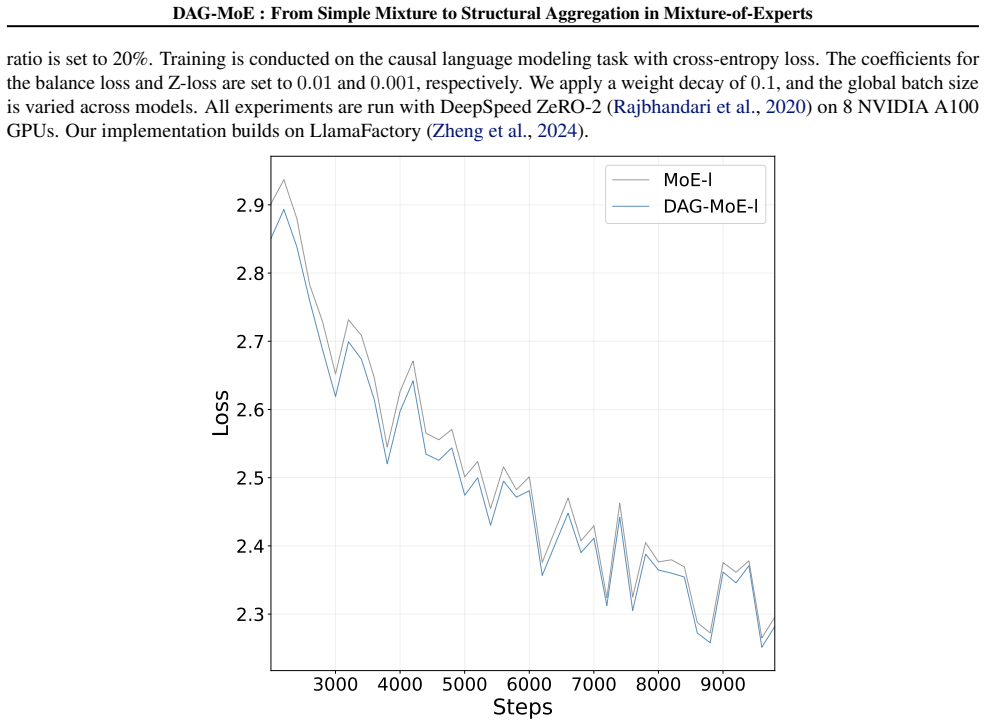
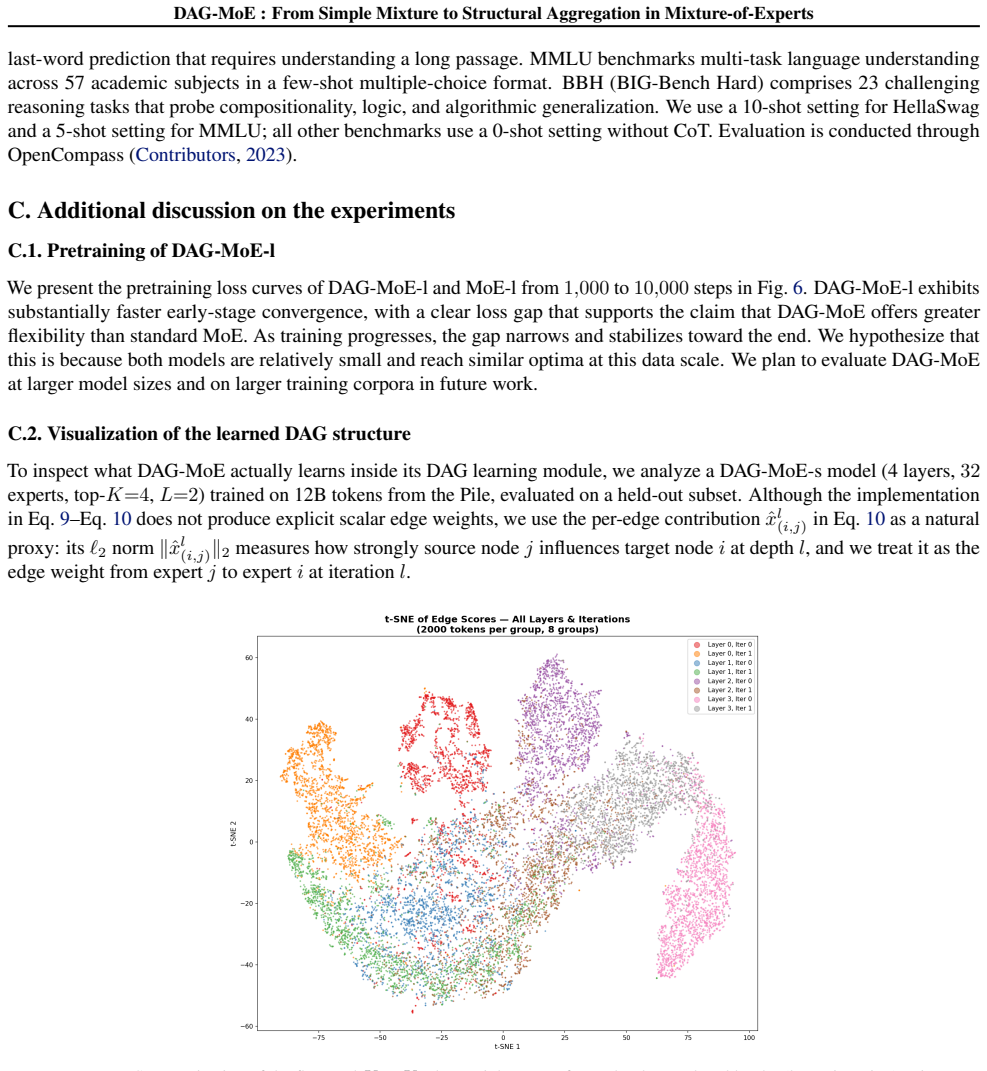
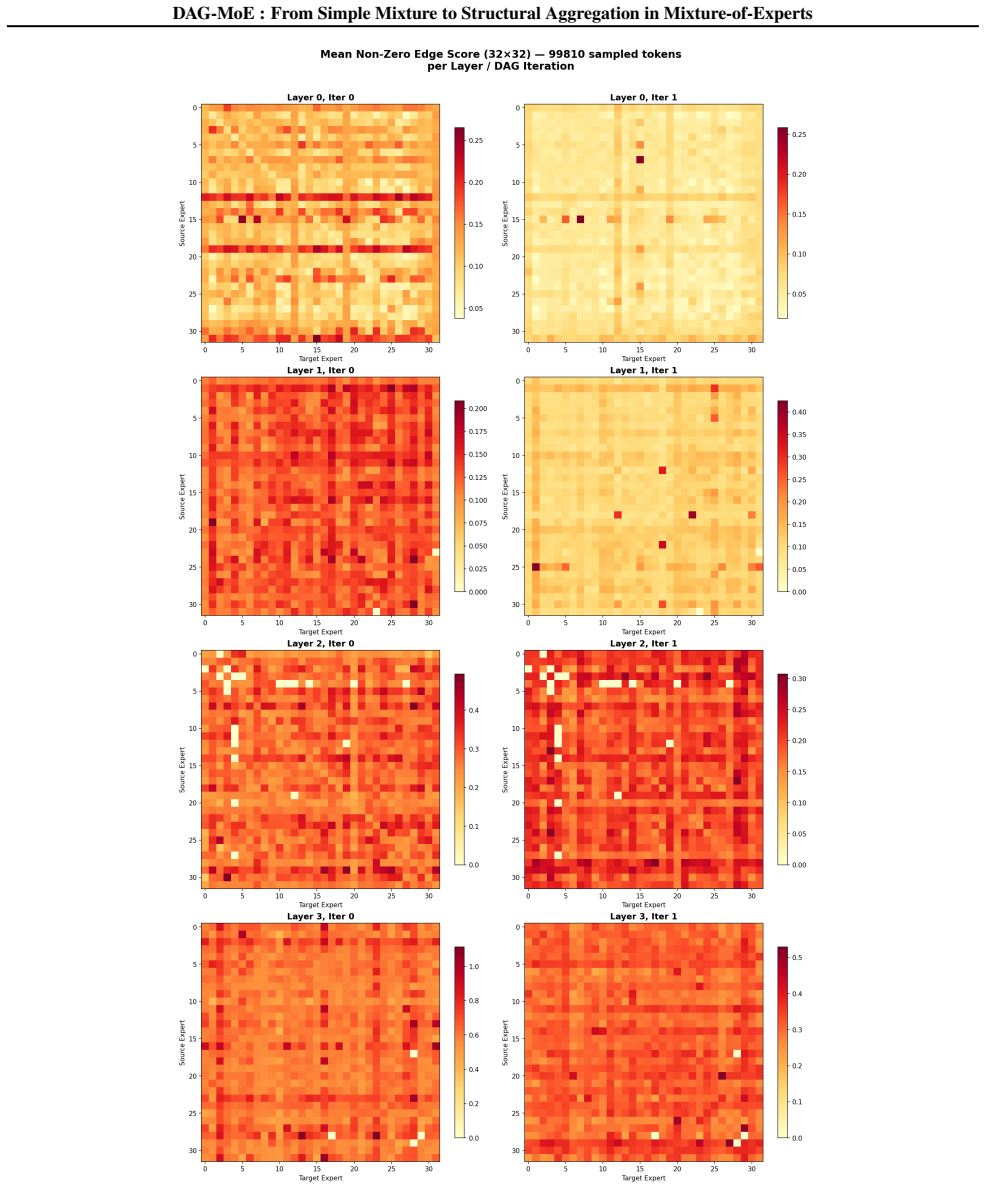
read the original abstract
Mixture-of-Experts (MoE) models have become a leading approach for decoupling parameter count from computational cost in large language models, yet effectively scaling MoE performance remains a challenge. Prior work shows that fine-grained experts enlarge the space of expert combinations and improve flexibility, but they also impose substantial routing overhead, creating a new scalability bottleneck. In this paper, we explore a complementary axis for scaling -- how expert outputs are aggregated. We theoretically show that replacing the standard weighted-summation aggregation with structural aggregation expands the expert-combination space without altering the experts or router, and enables possible multi-step reasoning within a single MoE layer. To this end, we propose DAG-MoE, a sparse MoE framework that employs a lightweight module to automatically learn the optimal aggregation structure among the selected experts. Extensive experiments under standard language modeling settings show that DAG-MoE consistently improves performance in both pretraining and fine-tuning, surpassing traditional MoE baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DAG-MoE, a sparse MoE framework that replaces standard weighted-summation aggregation of router-selected experts with structural aggregation over directed acyclic graphs (DAGs) learned by a lightweight module. It claims this expands the effective expert-combination space without modifying the experts or router, enables intra-layer multi-step reasoning, and yields consistent performance gains in language-model pretraining and fine-tuning experiments under standard settings.
Significance. If the central claim holds, the work identifies a new, complementary scaling axis for MoE models focused on aggregation topology rather than expert granularity or routing overhead. This could improve flexibility and reasoning capacity at modest added cost, with the reported experimental gains providing initial evidence of practical utility.
major comments (2)
- [Abstract] Abstract: the assertion that structural aggregation 'expands the expert-combination space' is load-bearing for the central claim, yet no derivation, formal definition of the expanded space, or comparison to the cardinality of weighted sums is supplied; without this it is impossible to verify whether the expansion is genuine or merely reparameterizes the same linear combination.
- [Abstract] Abstract: the proposal rests on an unstated assumption that the lightweight module can discover and apply non-trivial DAG topologies at negligible extra cost; no architecture, parameter scaling, training objective, or regularization for this module is described, leaving open whether the claimed expansion and multi-step reasoning are realized or whether new bottlenecks/overfitting are introduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the abstract to improve clarity and self-containment while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that structural aggregation 'expands the expert-combination space' is load-bearing for the central claim, yet no derivation, formal definition of the expanded space, or comparison to the cardinality of weighted sums is supplied; without this it is impossible to verify whether the expansion is genuine or merely reparameterizes the same linear combination.
Authors: The theoretical derivation establishing that DAG-based structural aggregation expands the expert-combination space (including the formal definition of the space and explicit cardinality comparison to weighted-sum combinations) appears in Section 3 of the full manuscript. We agree that the abstract would be strengthened by a concise reference to this result rather than relying solely on the claim statement, and we will revise the abstract accordingly. revision: yes
-
Referee: [Abstract] Abstract: the proposal rests on an unstated assumption that the lightweight module can discover and apply non-trivial DAG topologies at negligible extra cost; no architecture, parameter scaling, training objective, or regularization for this module is described, leaving open whether the claimed expansion and multi-step reasoning are realized or whether new bottlenecks/overfitting are introduced.
Authors: The architecture of the lightweight DAG-learning module, its parameter scaling (kept negligible relative to the experts), the training objective, and the regularization strategy are specified in Section 4, with experimental results confirming minimal overhead. We will add a brief summary of the module's design and efficiency to the abstract to make these aspects explicit. revision: yes
Circularity Check
No significant circularity; new module and theoretical expansion are independent of inputs
full rationale
The paper introduces DAG-MoE as a distinct architectural proposal: a lightweight module that learns DAG-based structural aggregation on top of standard router-selected experts. The central theoretical claim—that structural aggregation expands the combination space and enables intra-layer multi-step reasoning—is framed as a direct consequence of replacing weighted summation, not as a re-expression of fitted parameters or prior self-cited results. No equations or sections in the abstract reduce performance gains or the expansion claim to quantities defined by construction from the same data or self-citations. The proposal adds new components rather than renaming or refitting existing ones, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2407.04153 , year=
Mixture of a million experts , author=. arXiv preprint arXiv:2407.04153 , year=
-
[2]
arXiv preprint arXiv:2501.15103 , year=
Each Rank Could be an Expert: Single-Ranked Mixture of Experts LoRA for Multi-Task Learning , author=. arXiv preprint arXiv:2501.15103 , year=
-
[3]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Autoregressive image generation using residual quantization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[5]
arXiv preprint arXiv:2502.17416 , year=
Reasoning with latent thoughts: On the power of looped transformers , author=. arXiv preprint arXiv:2502.17416 , year=
-
[6]
arXiv preprint arXiv:2502.08482 , year=
Enhancing Auto-regressive Chain-of-Thought through Loop-Aligned Reasoning , author=. arXiv preprint arXiv:2502.08482 , year=
-
[7]
arXiv preprint arXiv:2408.06793 , year=
Layerwise recurrent router for mixture-of-experts , author=. arXiv preprint arXiv:2408.06793 , year=
-
[8]
Proceedings of the 41st International Conference on Machine Learning , pages =
Scaling Laws for Fine-Grained Mixture of Experts , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[9]
2025 , eprint=
OLMoE: Open Mixture-of-Experts Language Models , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
S'MoRE: Structural Mixture of Residual Experts for LLM Fine-tuning , author=. 2025 , eprint=
2025
-
[11]
Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Yang, Amy and Fan, Angela and others , journal=. The
-
[12]
Advances in Neural Information Processing Systems , volume=
On the representation collapse of sparse mixture of experts , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[14]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[15]
Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and others , journal=. The
-
[16]
Improving language understanding by generative pre-training , author=
-
[17]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Timoth. arXiv preprint arXiv:1910.03771 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[18]
2020 , eprint=
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models , author=. 2020 , eprint=
2020
-
[19]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=. 2024 , url=
2024
-
[20]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv preprint arXiv:2406.06563 , year=
Skywork-moe: A deep dive into training techniques for mixture-of-experts language models , author=. arXiv preprint arXiv:2406.06563 , year=
-
[24]
arXiv preprint arXiv:2501.12370 , year=
Parameters vs flops: Scaling laws for optimal sparsity for mixture-of-experts language models , author=. arXiv preprint arXiv:2501.12370 , year=
-
[25]
arXiv preprint arXiv:2502.05172 , year=
Joint MoE Scaling Laws: Mixture of Experts Can Be Memory Efficient , author=. arXiv preprint arXiv:2502.05172 , year=
-
[26]
arXiv preprint arXiv:2507.17702 , year=
Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models , author=. arXiv preprint arXiv:2507.17702 , year=
-
[27]
2024 , eprint=
MH-MoE: Multi-Head Mixture-of-Experts , author=. 2024 , eprint=
2024
-
[28]
2025 , eprint=
Chain-of-Experts: Unlocking the Communication Power of Mixture-of-Experts Models , author=. 2025 , eprint=
2025
-
[29]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
St-moe: Designing stable and transferable sparse expert models , author=. arXiv preprint arXiv:2202.08906 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
arXiv preprint arXiv:2507.10524 , year=
Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation , author=. arXiv preprint arXiv:2507.10524 , year=
-
[31]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Minicpm: Unveiling the potential of small language models with scalable training strategies , author=. arXiv preprint arXiv:2404.06395 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Lepikhin, Dmitry and Lee, HyoukJoong and Xu, Yuanzhong and Chen, Dehao and Firat, Orhan and Huang, Yanping and Krikun, Maxim and Shazeer, Noam and Chen, Zhifeng , booktitle=
-
[33]
2025 , howpublished=
The. 2025 , howpublished=
2025
-
[34]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Uni-moe: Scaling unified multimodal llms with mixture of experts , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[35]
Advances in Neural Information Processing Systems , volume=
Mixture-of-experts with expert choice routing , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts
Auxiliary-loss-free load balancing strategy for mixture-of-experts , author=. arXiv preprint arXiv:2408.15664 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Mixture-of-Experts Can Surpass Dense LLMs Under Strictly Equal Resource
Can Mixture-of-Experts Surpass Dense LLMs Under Strictly Equal Resources? , author=. arXiv preprint arXiv:2506.12119 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
International Conference on Learning Representations (ICLR) , year=
How Powerful are Graph Neural Networks? , author=. International Conference on Learning Representations (ICLR) , year=
-
[39]
International conference on machine learning , pages=
Neural message passing for quantum chemistry , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[40]
Advances in neural information processing systems , volume=
D-vae: A variational autoencoder for directed acyclic graphs , author=. Advances in neural information processing systems , volume=
-
[41]
nti, Series , volume=
The reduction of a graph to canonical form and the algebra which appears therein , author=. nti, Series , volume=
-
[42]
Proceedings of the AAAI conference on artificial intelligence , volume=
Weisfeiler and leman go neural: Higher-order graph neural networks , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[43]
Advances in Neural Information Processing Systems , volume=
Extending the design space of graph neural networks by rethinking folklore Weisfeiler-Lehman , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Advances in Neural Information Processing Systems , volume=
Towards revealing the mystery behind chain of thought: a theoretical perspective , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[46]
Advances in Neural Information Processing Systems , volume=
Large memory layers with product keys , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Advances in neural information processing systems , volume=
Deep sets , author=. Advances in neural information processing systems , volume=
-
[48]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[49]
arXiv preprint arXiv:2308.07317 , year=
Platypus: Quick, Cheap, and Powerful Refinement of LLMs , author=. arXiv preprint arXiv:2308.07317 , year=
-
[50]
2023 , eprint=
Orca: Progressive Learning from Complex Explanation Traces of GPT-4 , author=. 2023 , eprint=
2023
-
[51]
MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning
MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning , author=. arXiv preprint arXiv:2309.05653 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models , author=. arXiv preprint arXiv:2309.12284 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Bisk, Yonatan and Zellers, Rowan and Gao, Jianfeng and Choi, Yejin and others , booktitle=
-
[54]
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , booktitle=
-
[55]
Think you have Solved Question Answering? Try
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=. Think you have Solved Question Answering? Try
-
[56]
Proceedings of the 3rd Workshop on Noisy User-generated Text (W-NUT) , pages=
Crowdsourcing Multiple Choice Science Questions , author=. Proceedings of the 3rd Workshop on Noisy User-generated Text (W-NUT) , pages=
-
[57]
doi:10.57967/hf/2497 , publisher =
Lozhkov, Anton and Ben Allal, Loubna and von Werra, Leandro and Wolf, Thomas , title =. doi:10.57967/hf/2497 , publisher =
-
[58]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[59]
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R , booktitle=
-
[60]
OpenCompass: A Universal Evaluation Platform for Foundation Models , author=
-
[61]
arXiv preprint arXiv:2501.11873 , year=
Demons in the detail: On implementing load balancing loss for training specialized mixture-of-expert models , author=. arXiv preprint arXiv:2501.11873 , year=
-
[62]
Paperno, Denis and Kruszewski, Germ. The. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[63]
International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations (ICLR) , year=
-
[64]
Challenging
Suzgun, Mirac and Scales, Nathan and Sch. Challenging. Findings of the Association for Computational Linguistics (ACL Findings) , year=
-
[65]
2022 , howpublished=
Online Language Modelling Data Pipeline , author=. 2022 , howpublished=
2022
-
[66]
Advances in Neural Information Processing Systems , volume=
Diep: Adaptive mixture-of-experts compression through differentiable expert pruning , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.