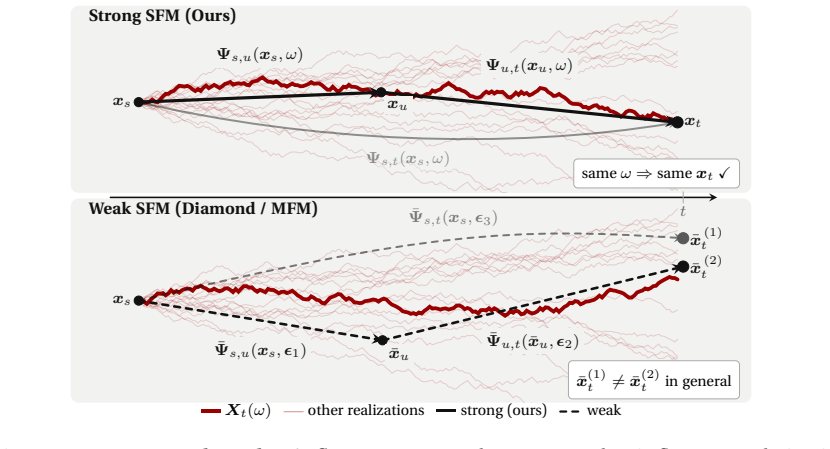
Strong Stochastic Flow Maps
Pith reviewed 2026-06-28 17:43 UTC · model grok-4.3
The pith
Strong Stochastic Flow Maps learn the strong solution map of additive-noise SDEs by training on a pathwise-convergent polynomial approximation to Brownian motion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
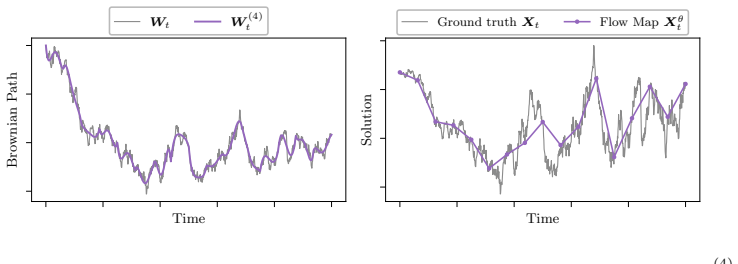
Strong Stochastic Flow Maps learn the strong solution map of additive-noise SDEs by replacing the driving Brownian motion with a polynomial approximation shown to converge pathwise; the resulting training objective is simulation-free and yields maps that recover solution paths rather than only terminal marginals.
What carries the argument
The polynomial approximation to Brownian motion, which supplies pathwise convergence and thereby enables a strong (pathwise) rather than weak (marginal) training objective for the flow map.
If this is right
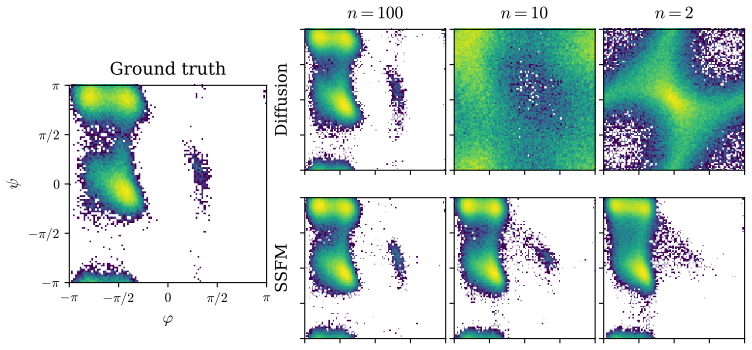
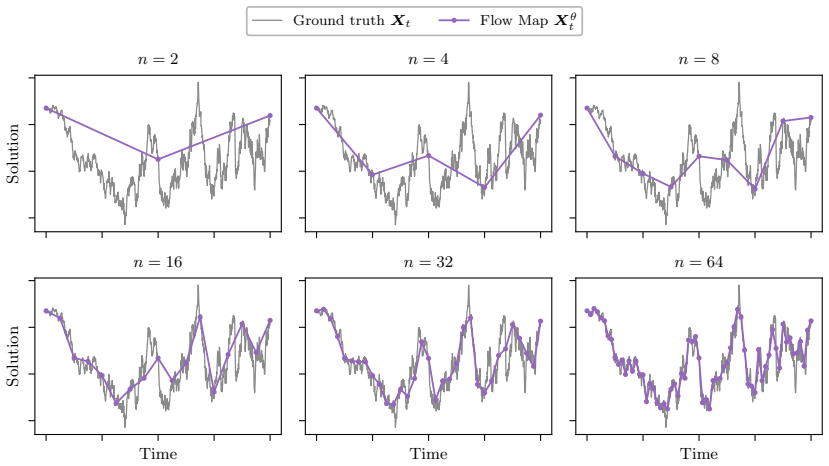
- SSFMs enable few-step sampling for diffusion models while recovering entire solution paths.
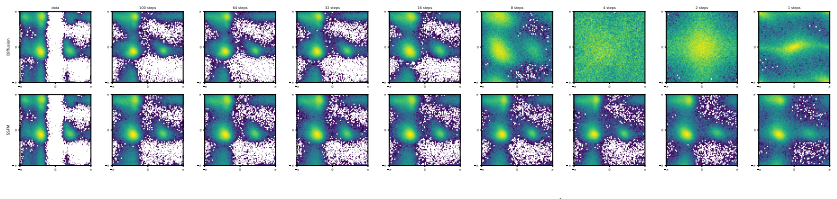
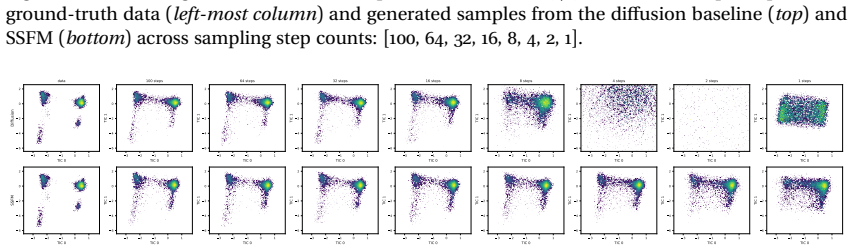
- The maps outperform prior stochastic flow-map methods on image-generation benchmarks.
- Molecular systems can be simulated with few network evaluations under the new maps.
- Training no longer requires repeated simulation of the underlying stochastic process.
Where Pith is reading between the lines
- The same polynomial device might be adapted to other driving noises whose paths admit polynomial approximations.
- Pathwise accuracy could matter for downstream tasks that depend on the whole trajectory, such as hitting-time statistics or path-dependent functionals.
- The framework might be combined with existing numerical SDE integrators to produce hybrid few-step correctors.
Load-bearing premise
The polynomial approximation to Brownian motion converges pathwise.
What would settle it
An explicit counterexample path on which the polynomial approximation diverges from the true Brownian motion, or empirical trajectories generated by the learned map that systematically deviate from true SDE solutions in the strong sense.
Figures


read the original abstract
Flow and diffusion models generate high-quality samples in many modalities; however, many network evaluations are required during inference due to numerical integration of an underlying differential equation. Flow maps alleviate this problem by learning the solution map of the differential equation directly, enabling few-step sampling. Yet, current methods are restricted to approximating the solution map of ODEs. These methods can be used to learn the transition kernel of an SDE, thereby obtaining a solution map that recovers the marginal distributions of the process (weak convergence) rather than the solution path (strong convergence). We propose Strong Stochastic Flow Maps (SSFMs) as a novel framework for learning the strong solution map of additive-noise SDEs, directly generalizing deterministic flow maps to the stochastic setting. Further, a polynomial approximation to Brownian motion is introduced and shown to converge pathwise. These results enable a simulation-free training objective for the solution map of diffusion models. We demonstrate that SSFMs outperform previous stochastic flow map methods on image generation and enable few-step sampling of molecular systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Strong Stochastic Flow Maps (SSFMs) to learn the strong (pathwise) solution map of additive-noise SDEs by generalizing deterministic flow maps, introduces a polynomial approximation to Brownian motion asserted to converge pathwise, derives a simulation-free training objective for diffusion model solution maps from this approximation, and reports empirical outperformance versus prior stochastic flow-map methods on image generation tasks plus few-step sampling for molecular systems.
Significance. If the pathwise convergence holds with the required uniformity, the framework would enable strong rather than weak approximation of SDE flows, offering a concrete route to few-step sampling that preserves pathwise properties; this would be a meaningful technical advance over existing weak-convergence stochastic flow maps, with direct applicability to generative modeling and molecular dynamics.
major comments (2)
- [Abstract] Abstract: the central claim that the polynomial approximation to Brownian motion 'converges pathwise' is load-bearing for the distinction between strong and weak convergence and for the simulation-free objective, yet the abstract supplies neither a proof sketch, rate, nor statement of the topology (e.g., a.s. uniform on [0,T]); without this, the training objective cannot be guaranteed to target the strong solution map rather than marginals.
- [Training objective derivation] The derivation of the training objective (presumed §4) rests on substituting the polynomial approximant for the driving Brownian motion; if the convergence established is only in probability or in distribution rather than almost-sure uniform, the objective collapses to the weak-convergence case already covered by prior methods, undermining the novelty claim.
minor comments (1)
- [Experiments] Experimental section: baseline comparisons, dataset details, and quantitative metrics (e.g., FID, NLL) for the image-generation and molecular experiments are referenced only at high level; explicit tables or figures with these numbers would strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting the importance of clearly establishing the pathwise convergence claim. We address each major comment below. Where the manuscript requires clarification or expansion, we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the polynomial approximation to Brownian motion 'converges pathwise' is load-bearing for the distinction between strong and weak convergence and for the simulation-free objective, yet the abstract supplies neither a proof sketch, rate, nor statement of the topology (e.g., a.s. uniform on [0,T]); without this, the training objective cannot be guaranteed to target the strong solution map rather than marginals.
Authors: We agree that the abstract is too terse on this point. The manuscript (Section 3) proves almost-sure uniform convergence on [0,T] for the polynomial approximant (Theorem 3.2, with explicit rate in the sup-norm). We will revise the abstract to include a concise statement of this topology and convergence mode so that the distinction from weak methods is immediately clear. revision: yes
-
Referee: [Training objective derivation] The derivation of the training objective (presumed §4) rests on substituting the polynomial approximant for the driving Brownian motion; if the convergence established is only in probability or in distribution rather than almost-sure uniform, the objective collapses to the weak-convergence case already covered by prior methods, undermining the novelty claim.
Authors: The proof in Section 3 establishes almost-sure uniform convergence on compact intervals, which is the precise mode needed for the pathwise substitution argument in §4. Because the approximant converges a.s. uniformly, the composed objective converges to the strong solution map (not merely in distribution). We will add a short clarifying paragraph in §4 that explicitly invokes the a.s. uniform topology to make this step transparent. revision: yes
Circularity Check
No significant circularity; core claims rest on independent construction and claimed proof.
full rationale
The abstract and description present the polynomial approximation to Brownian motion as a new construction whose pathwise convergence is asserted to be shown, directly enabling the simulation-free objective for strong solutions. No quoted step reduces a prediction to a fitted input by construction, invokes a self-citation as the sole justification for a uniqueness or ansatz claim, or renames a known result. The derivation chain is therefore not equivalent to its inputs; the pathwise-convergence claim functions as an external mathematical step rather than a tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Peter Holderrieth and Uriel Singer and Tommi Jaakkola and Ricky T. Q. Chen and Yaron Lipman and Brian Karrer , booktitle=. 2026 , url=
2026
-
[2]
The Eleventh International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. The Eleventh International Conference on Learning Representations , year=
-
[3]
Journal of Machine Learning Research , volume=
Stochastic interpolants: A unifying framework for flows and diffusions , author=. Journal of Machine Learning Research , volume=
-
[4]
The Eleventh International Conference on Learning Representations , year=
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=. The Eleventh International Conference on Learning Representations , year=
-
[5]
Transactions on Machine Learning Research , issn=
Improving and generalizing flow-based generative models with minibatch optimal transport , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[6]
Non-Denoising Forward-Time Diffusions , author=
-
[7]
Flow Matching Guide and Code , author=
-
[8]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[9]
Stochastic Processes and their Applications , volume=
Reverse-time diffusion equation models , author=. Stochastic Processes and their Applications , volume=. 1982 , publisher=
1982
-
[10]
Entropy , volume=
Interacting particle solutions of fokker--planck equations through gradient--log--density estimation , author=. Entropy , volume=. 2020 , publisher=
2020
-
[11]
The Blessing of Randomness:
Shen Nie and Hanzhong Allan Guo and Cheng Lu and Yuhao Zhou and Chenyu Zheng and Chongxuan Li , booktitle=. The Blessing of Randomness:. 2024 , url=
2024
-
[12]
2022 , note =
Kidger, Patrick , title =. 2022 , note =
2022
-
[13]
Dormand, J. R. and Prince, P. J. , title=. J. Comp. Appl. Math , year=
-
[14]
Shampine , journal=
Lawrence F. Shampine , journal=. Some Practical. 1986 , doi=
1986
-
[15]
2024 , url=
Multistep Consistency Models , author=. 2024 , url=
2024
-
[16]
The Twelfth International Conference on Learning Representations , year=
Improved Techniques for Training Consistency Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[17]
Consistency Trajectory Models: Learning Probability Flow
Dongjun Kim and Chieh-Hsin Lai and Wei-Hsiang Liao and Naoki Murata and Yuhta Takida and Toshimitsu Uesaka and Yutong He and Yuki Mitsufuji and Stefano Ermon , booktitle=. Consistency Trajectory Models: Learning Probability Flow. 2024 , url=
2024
-
[18]
The Thirteenth International Conference on Learning Representations , year=
One Step Diffusion via Shortcut Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[19]
arXiv preprint arXiv:2505.18825 , year=
How to build a consistency model: Learning flow maps via self-distillation , author=. arXiv preprint arXiv:2505.18825 , year=
-
[20]
arXiv preprint arXiv:2406.07507 , year=
Flow map matching , author=. arXiv preprint arXiv:2406.07507 , year=
-
[21]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Align Your Flow: Scaling Continuous-Time Flow Map Distillation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[22]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Mean Flows for One-step Generative Modeling , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[23]
Proceedings of the 40th International Conference on Machine Learning , pages =
Consistency Models , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[24]
Chen, Ricky T. Q. and Rubanova, Yulia and Bettencourt, Jesse and Duvenaud, David K , booktitle =. Neural Ordinary Differential Equations , url =
-
[25]
Probability Theory and Stochastic Modelling, vol
Stochastic Flows and Jump-Diffusions , author=. doi:10.1007/978-981-13-3801-4 , year=
-
[26]
2010 , publisher=
Multidimensional stochastic processes as rough paths: theory and applications , author=. 2010 , publisher=
2010
-
[27]
A course on rough paths: With an introduction to regularity structures
Friz, Peter K and Hairer, Martin. A course on rough paths: With an introduction to regularity structures
-
[28]
2020 , url =
Numerical approximations for stochastic differential equations , author =. 2020 , url =
2020
-
[29]
doi:10.1007/978-3-642-14394-6 , year=
Stochastic Differential Equations: An Introduction with Applications , author=. doi:10.1007/978-3-642-14394-6 , year=
-
[30]
Forty-second International Conference on Machine Learning , year=
Conditioning Diffusions Using Malliavin Calculus , author=. Forty-second International Conference on Machine Learning , year=
-
[31]
Publications of the Research Institute for Mathematical Sciences , volume=
A class of approximations of Brownian motion , author=. Publications of the Research Institute for Mathematical Sciences , volume=. 1977 , publisher=
1977
-
[32]
Revista Matem
Differential equations driven by rough signals , author=. Revista Matem
-
[33]
SIAM Journal on Numerical Analysis , volume=
An optimal polynomial approximation of Brownian motion , author=. SIAM Journal on Numerical Analysis , volume=. 2020 , publisher=
2020
-
[34]
Stratonovich and It
Kloeden, Peter E and Platen, Eckhard , journal=. Stratonovich and It. 1991 , publisher=
1991
-
[35]
arXiv preprint arXiv:2405.06464 , year=
Single-seed generation of Brownian paths and integrals for adaptive and high order SDE solvers , author=. arXiv preprint arXiv:2405.06464 , year=
-
[36]
The Fourteenth International Conference on Learning Representations , year=
Decoupled MeanFlow: Turning Flow Models into Flow Maps for Accelerated Sampling , author=. The Fourteenth International Conference on Learning Representations , year=
-
[37]
arXiv preprint arXiv:2601.14430 , year=
Meta Flow Maps enable scalable reward alignment , author=. arXiv preprint arXiv:2601.14430 , year=
-
[38]
ICLR 2026 2nd Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy , year=
Stochastic Few-step Models , author=. ICLR 2026 2nd Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy , year=
2026
-
[39]
arXiv preprint arXiv:2602.05993 , year=
Diamond Maps: Efficient Reward Alignment via Stochastic Flow Maps , author=. arXiv preprint arXiv:2602.05993 , year=
-
[40]
Annalen der Physik , volume=
Die mittlere Energie rotierender elektrischer Dipole im Strahlungsfeld , author=. Annalen der Physik , volume=. 1914 , publisher=
1914
-
[41]
Planck, VM , journal=
-
[42]
Kolmogorov, A , journal=
-
[43]
2022 , url=
Cheng Lu and Yuhao Zhou and Fan Bao and Jianfei Chen and Chongxuan Li and Jun Zhu , booktitle=. 2022 , url=
2022
-
[44]
The Annals of Mathematical Statistics , volume=
On the convergence of ordinary integrals to stochastic integrals , author=. The Annals of Mathematical Statistics , volume=. 1965 , publisher=
1965
-
[45]
International Journal of Engineering Science , volume=
On the relation between ordinary and stochastic differential equations , author=. International Journal of Engineering Science , volume=. 1965 , publisher=
1965
-
[46]
Proceedings of the London Mathematical Society , volume=
Iterated integrals and exponential homomorphisms , author=. Proceedings of the London Mathematical Society , volume=. 1954 , publisher=
1954
-
[47]
Annals of Mathematics , volume=
Integration of paths, geometric invariants and a generalized Baker-Hausdorff formula , author=. Annals of Mathematics , volume=. 1957 , publisher=
1957
-
[48]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[49]
Denoising Diffusion Probabilistic Models , url =
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , booktitle =. Denoising Diffusion Probabilistic Models , url =
-
[50]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[51]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Align your latents: High-resolution video synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[52]
Nature , volume=
De novo design of protein structure and function with RFdiffusion , author=. Nature , volume=. 2023 , publisher=
2023
-
[53]
2026 , url=
Rehman, Danyal and Akhound-Sadegh, Tara and Gazizov, Artem and Bengio, Yoshua and Tong, Alexander , booktitle=. 2026 , url=
2026
-
[54]
IEEE Transactions on Biometrics, Behavior, and Identity Science , volume=
Leveraging diffusion for strong and high quality face morphing attacks , author=. IEEE Transactions on Biometrics, Behavior, and Identity Science , volume=. 2024 , publisher=
2024
-
[55]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Consistent Sampling and Simulation: Molecular Dynamics with Energy-Based Diffusion Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[56]
Efficient and Accurate Gradients for Neural
Patrick Kidger and James Foster and Xuechen Li and Terry Lyons , booktitle=. Efficient and Accurate Gradients for Neural. 2021 , url=
2021
-
[57]
Proceedings of The 2nd Symposium on Advances in Approximate Bayesian Inference , pages =
Scalable Gradients and Variational Inference for Stochastic Differential Equations , author =. Proceedings of The 2nd Symposium on Advances in Approximate Bayesian Inference , pages =. 2020 , editor =
2020
-
[58]
The Twelfth International Conference on Learning Representations , year=
Stable Neural Stochastic Differential Equations in Analyzing Irregular Time Series Data , author=. The Twelfth International Conference on Learning Representations , year=
-
[59]
Forty-first International Conference on Machine Learning , year=
Log Neural Controlled Differential Equations: The Lie Brackets Make A Difference , author=. Forty-first International Conference on Machine Learning , year=
-
[60]
2026 , eprint=
General Multimodal Protein Design Enables DNA-Encoding of Chemistry , author=. 2026 , eprint=
2026
-
[61]
The Eleventh International Conference on Learning Representations , year=
Fast Sampling of Diffusion Models with Exponential Integrator , author=. The Eleventh International Conference on Learning Representations , year=
-
[62]
2023 , url=
Martin Gonzalez and Nelson Fernandez and Thuy Vinh Dinh Tran and Elies Gherbi and Hatem Hajri and Nader Masmoudi , booktitle=. 2023 , url=
2023
-
[63]
2026 , booktitle =
Rex: A Family of Reversible Exponential (Stochastic) Runge-Kutta Solvers , author =. 2026 , booktitle =
2026
-
[64]
arXiv preprint arXiv:2512.02012 , year=
Improved mean flows: On the challenges of fastforward generative models , author=. arXiv preprint arXiv:2512.02012 , year=
-
[65]
Advances in Neural Information Processing Systems , volume=
Smooth normalizing flows , author=. Advances in Neural Information Processing Systems , volume=
-
[66]
2009 , publisher=
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
2009
-
[67]
Proceedings of International Conference on Computer Vision (ICCV) , month =
Deep Learning Face Attributes in the Wild , author =. Proceedings of International Conference on Computer Vision (ICCV) , month =
-
[68]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Analyzing and improving the training dynamics of diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[69]
A. M. Garsia and E. Rodemich and H. Rumsey and M. Rosenblatt , journal =. A Real Variable Lemma and the Continuity of Paths of Some Gaussian Processes , urldate =
-
[70]
A semicircle law and decorrelation phenomena for iterated Kolmogorov loops , volume=
Habermann, Karen , year=. A semicircle law and decorrelation phenomena for iterated Kolmogorov loops , volume=. Journal of the London Mathematical Society , publisher=. doi:10.1112/jlms.12384 , number=
-
[71]
The Thirteenth International Conference on Learning Representations , year=
Generator Matching: Generative modeling with arbitrary Markov processes , author=. The Thirteenth International Conference on Learning Representations , year=
-
[72]
arXiv preprint arXiv:2508.16939 , year=
Sig-DEG for Distillation: Making Diffusion Models Faster and Lighter , author=. arXiv preprint arXiv:2508.16939 , year=
-
[73]
Hypersolvers: Toward Fast Continuous-Depth Models , url =
Poli, Michael and Massaroli, Stefano and Yamashita, Atsushi and Asama, Hajime and Park, Jinkyoo , booktitle =. Hypersolvers: Toward Fast Continuous-Depth Models , url =
-
[74]
Neural Stochastic Flows: Solver-Free Modelling and Inference for
Naoki Kiyohara and Edward Johns and Yingzhen Li , booktitle=. Neural Stochastic Flows: Solver-Free Modelling and Inference for. 2025 , url=
2025
-
[75]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Variational Inference with Normalizing Flows , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , editor =
2015
-
[76]
The annals of mathematical statistics , volume=
On information and sufficiency , author=. The annals of mathematical statistics , volume=. 1951 , publisher=
1951
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.