Implicit Drifting Policy: One-Step Action Generation via Conditional Expert Geometry
Pith reviewed 2026-06-28 17:16 UTC · model grok-4.3
The pith
One-step imitation learning enforces action manifold constraints using conditional expert geometry extracted from local variations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
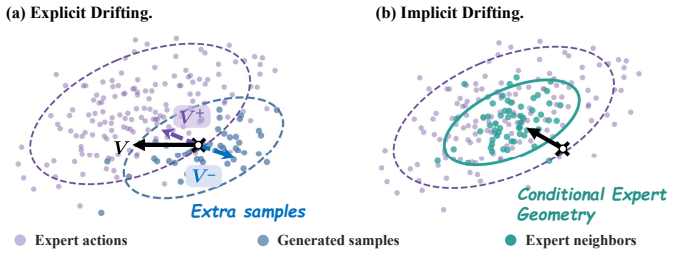
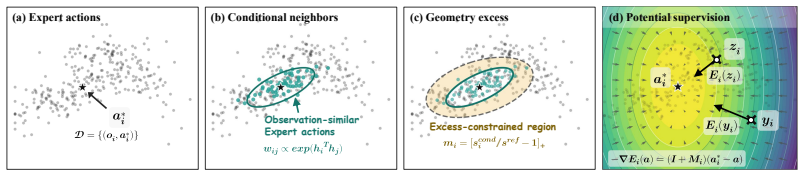
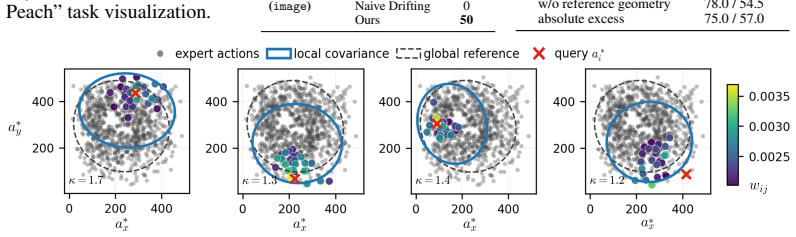
IDP extracts a conditional expert geometry from the local variation of observation-similar expert actions, and compares it against a global reference geometry to isolate condition-specific constraints. This local geometric structure adaptively weights a scalar potential objective. Combined with an expert-proximal terminal evaluation, IDP directly enforces manifold constraints on the one-step generator during training.
What carries the argument
conditional expert geometry: the structure derived from local variation of observation-similar expert actions compared against a global reference to isolate condition-specific constraints and adaptively weight the objective
If this is right
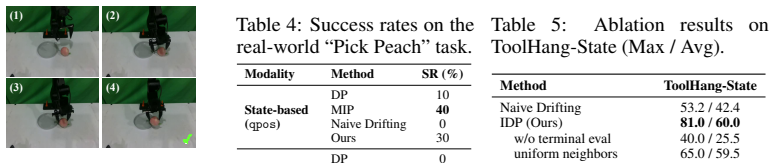
- IDP maintains adherence to valid action manifolds across 2D, 3D, and real-world manipulation tasks.
- It improves upon methods that explicitly estimate drifting fields.
- It achieves competitive performance with strong one-step baseline policies.
Where Pith is reading between the lines
- The geometric isolation technique may prove useful in other imitation learning settings where explicit correction fields cannot be estimated reliably due to sparsity.
- Manifold constraints can be enforced in one-step generators without requiring dense conditional data for every observed condition.
- The approach suggests a route to faster sampling in any generative control setting where intermediate trajectory corrections matter but explicit vector fields are ill-posed.
Load-bearing premise
The local geometric structure extracted from observation-similar expert actions can reliably isolate condition-specific constraints and implicitly capture the training-time drifting correction even under extreme conditional demonstration sparsity.
What would settle it
Observing that one-step generators trained with IDP produce actions outside the valid manifold in tasks with extreme conditional demonstration sparsity would falsify the central mechanism.
Figures
read the original abstract
Generative action policies based on diffusion or flow matching excel in behavior cloning, yet their iterative sampling is prohibitive for high-frequency robot control. While recent one-step formulations alleviate this latency, they inevitably discard the intermediate trajectory evolution that provides crucial action correction. Directly recovering this mechanism by explicitly estimating a training-time drifting field is mathematically ill-posed due to extreme conditional demonstration sparsity. We introduce Implicit Drifting Policy (IDP), a one-step imitation learning framework that brings the training-time correction of Drifting into policy learning without explicit vector field estimation. IDP extracts a conditional expert geometry from the local variation of observation-similar expert actions, and compares it against a global reference geometry to isolate condition-specific constraints. This local geometric structure adaptively weights a scalar potential objective. Combined with an expert-proximal terminal evaluation, IDP directly enforces manifold constraints on the one-step generator during training. Extensive evaluations across 2D, 3D, and real-world manipulation tasks show IDP effectively maintains adherence to valid action manifolds, improving upon explicit drifting methods and achieving competitive performance with strong one-step baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Implicit Drifting Policy (IDP), a one-step imitation learning framework for robot action generation. It claims to recover training-time drifting corrections in one-step generators without explicit vector-field estimation by extracting a conditional expert geometry from local variation among observation-similar expert actions, comparing it to a global reference geometry to isolate condition-specific manifold constraints, adaptively weighting a scalar potential objective, and combining it with an expert-proximal terminal evaluation. The abstract asserts that this enforces valid action manifolds and yields improvements over explicit drifting methods plus competitive results versus strong one-step baselines on 2D, 3D, and real-world manipulation tasks.
Significance. If the geometric extraction mechanism functions as described, the work would offer a practical route to low-latency one-step policies that still respect the corrective structure present during training, which is relevant for high-frequency robotic control. The paper is credited for explicitly recognizing the ill-posedness of direct drifting-field recovery under conditional sparsity. However, the complete absence of any quantitative results, implementation details, or verification of the geometry extraction prevents any concrete assessment of significance.
major comments (2)
- [Abstract] Abstract: the central empirical claim ('extensive evaluations ... improving upon explicit drifting methods and achieving competitive performance') is unsupported by any metrics, error bars, tables, figures, or implementation specifics, rendering the soundness of the result impossible to evaluate from the manuscript.
- [Abstract] Abstract: the load-bearing assumption that 'local geometric structure extracted from observation-similar expert actions' can reliably isolate condition-specific constraints (and thereby implicitly encode the drifting correction) is stated without any supporting analysis or evidence; under the extreme sparsity regime the paper itself flags as ill-posed for explicit methods, the number of sufficiently similar observations can approach zero, leaving local covariance or tangent-space estimates undefined or noise-dominated.
minor comments (1)
- [Abstract] Abstract: 'Drifting' is capitalized on first use without definition or citation to prior work.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for stronger empirical grounding and justification of the core geometric assumption. We address each major comment below. The full manuscript contains the claimed evaluations (Sections 4–5), but we agree the abstract should be revised for self-containment.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim ('extensive evaluations ... improving upon explicit drifting methods and achieving competitive performance') is unsupported by any metrics, error bars, tables, figures, or implementation specifics, rendering the soundness of the result impossible to evaluate from the manuscript.
Authors: The abstract is a high-level summary; the full manuscript reports quantitative results with metrics, error bars, tables, and figures in Sections 4 and 5, plus implementation details in the appendix. We acknowledge that the abstract itself does not contain these numbers. In revision we will add a concise statement of key performance deltas (with error bars) to the abstract to make the empirical claim self-contained. revision: yes
-
Referee: [Abstract] Abstract: the load-bearing assumption that 'local geometric structure extracted from observation-similar expert actions' can reliably isolate condition-specific constraints (and thereby implicitly encode the drifting correction) is stated without any supporting analysis or evidence; under the extreme sparsity regime the paper itself flags as ill-posed for explicit methods, the number of sufficiently similar observations can approach zero, leaving local covariance or tangent-space estimates undefined or noise-dominated.
Authors: We agree that the sparsity issue is central and that the abstract does not provide supporting analysis. The method includes an explicit neighbor-count threshold: when fewer than k similar observations exist, the local geometry term is disabled and the global reference is used. The manuscript contains an appendix figure showing the empirical distribution of local sample sizes across tasks. We will expand the main text with a short paragraph on this fallback mechanism and the conditions under which local estimates remain stable. revision: partial
Circularity Check
No circularity detected in derivation chain
full rationale
The abstract and provided description introduce IDP as an independent mechanism that extracts conditional expert geometry from local variation of observation-similar actions and compares it to a global reference to weight a scalar potential objective, explicitly avoiding explicit vector field estimation which is called ill-posed. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes are quoted that reduce any claimed result to its own inputs by construction. The derivation is presented as self-contained with external evaluations on tasks, consistent with a non-circular contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dexart: Benchmarking generalizable dexterous manipulation with articulated objects
Chen Bao, Helin Xu, Yuzhe Qin, and Xiaolong Wang. Dexart: Benchmarking generalizable dexterous manipulation with articulated objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21190–21200, 2023
2023
-
[2]
Boffi, Michael S
Nicholas M. Boffi, Michael S. Albergo, and Eric Vanden-Eijnden. How to build a consistency model: Learning flow maps via self-distillation, 2025. URL https://arxiv.org/abs/2505. 18825
2025
-
[3]
On learning, representing, and generalizing a task in a humanoid robot.IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 37(2):286–298, 2007
Sylvain Calinon, Florent Guenter, and Aude Billard. On learning, representing, and generalizing a task in a humanoid robot.IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 37(2):286–298, 2007
2007
-
[4]
Falcon: Fast visuomotor policies via partial denoising, 2025
Haojun Chen, Minghao Liu, Chengdong Ma, Xiaojian Ma, Zailin Ma, Huimin Wu, Yuanpei Chen, Yifan Zhong, Mingzhi Wang, Qing Li, and Yaodong Yang. Falcon: Fast visuomotor policies via partial denoising, 2025. URLhttps://arxiv.org/abs/2503.00339
-
[5]
Diffusion policy: Visuomotor policy learning via action diffusion,
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion,
-
[6]
URLhttps://arxiv.org/abs/2303.04137
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Learning robotic manipulation policies from point clouds with conditional flow matching,
Eugenio Chisari, Nick Heppert, Max Argus, Tim Welschehold, Thomas Brox, and Abhinav Val- ada. Learning robotic manipulation policies from point clouds with conditional flow matching,
- [8]
-
[9]
Generative Modeling via Drifting
Mingyang Deng, He Li, Tianhong Li, Yilun Du, and Kaiming He. Generative modeling via drifting, 2026. URLhttps://arxiv.org/abs/2602.04770
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Real-time iteration scheme for diffusion policy,
Yufei Duan, Hang Yin, and Danica Kragic. Real-time iteration scheme for diffusion policy,
- [11]
-
[12]
Implicit behavioral cloning, 2021
Pete Florence, Corey Lynch, Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. Implicit behavioral cloning, 2021. URLhttps://arxiv.org/abs/2109.00137
-
[13]
One Step Diffusion via Shortcut Models
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models, 2025. URLhttps://arxiv.org/abs/2410.12557
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Actionflow: Equivariant, accurate, and efficient policies with spatially symmetric flow matching,
Niklas Funk, Julen Urain, Joao Carvalho, Vignesh Prasad, Georgia Chalvatzaki, and Jan Peters. Actionflow: Equivariant, accurate, and efficient policies with spatially symmetric flow matching,
- [15]
-
[16]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J. Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling, 2025. URLhttps://arxiv.org/abs/2505.13447
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Høeg, Yilun Du, and Olav Egeland
Sigmund H. Høeg, Yilun Du, and Olav Egeland. Streaming diffusion policy: Fast policy synthesis with variable noise diffusion models, 2024. URL https://arxiv.org/abs/2406. 04806
2024
-
[18]
Kernelized Movement Primitives
Yanlong Huang, Leonel Rozo, João Silvério, and Darwin G. Caldwell. Kernelized movement primitives, 2018. URLhttps://arxiv.org/abs/1708.08638
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Dynamical movement primitives: Learning attractor models for motor behaviors.Neural Computation, 25 (2):328–373, 2013
Auke Jan Ijspeert, Jun Nakanishi, Heiko Hoffmann, Peter Pastor, and Stefan Schaal. Dynamical movement primitives: Learning attractor models for motor behaviors.Neural Computation, 25 (2):328–373, 2013. 10
2013
-
[20]
Action-to-Action Flow Matching
Jindou Jia, Gen Li, Xiangyu Chen, Tuo An, Yuxuan Hu, Jingliang Li, Xinying Guo, and Jianfei Yang. Action-to-action flow matching, 2026. URLhttps://arxiv.org/abs/2602.07322
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Mohammad Khansari-Zadeh and Aude Billard
S. Mohammad Khansari-Zadeh and Aude Billard. Learning stable nonlinear dynamical systems with gaussian mixture models.IEEE Transactions on Robotics, 27(5):943–957, 2011
2011
-
[22]
A Unified View of Score-Based and Drifting Models
Chieh-Hsin Lai, Bac Nguyen, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yuki Mitsufuji, Stefano Ermon, and Molei Tao. A unified view of drifting and score-based models, 2026. URL https://arxiv.org/abs/2603.07514
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto
Seungjae Lee, Yibin Wang, Haritheja Etukuru, H. Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Behavior generation with latent actions, 2024. URL https://arxiv.org/ abs/2403.03181
-
[24]
Shaolong Li, Lichao Sun, and Yongchao Chen. One-step flow policy: Self-distillation for fast visuomotor policies, 2026. URLhttps://arxiv.org/abs/2603.12480
-
[25]
Geometry-aware policy imitation, 2025
Yiming Li, Nael Darwiche, Amirreza Razmjoo, Sichao Liu, Yilun Du, Auke Ijspeert, and Sylvain Calinon. Geometry-aware policy imitation, 2025. URL https://arxiv.org/abs/ 2510.08787
-
[26]
A long-short flow-map perspective for drifting models, 2026
Zhiqi Li and Bo Zhu. A long-short flow-map perspective for drifting models, 2026. URL https://arxiv.org/abs/2602.20463
-
[27]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Manicm: Real-time 3d diffusion policy via consistency model for robotic manipulation,
Guanxing Lu, Zifeng Gao, Tianxing Chen, Wenxun Dai, Ziwei Wang, Wenbo Ding, and Yansong Tang. Manicm: Real-time 3d diffusion policy via consistency model for robotic manipulation,
- [29]
-
[30]
Much ado about noising: Dispelling the myths of generative robotic control, 2026
Chaoyi Pan, Giri Anantharaman, Nai-Chieh Huang, Claire Jin, Daniel Pfrommer, Chenyang Yuan, Frank Permenter, Guannan Qu, Nicholas Boffi, Guanya Shi, and Max Simchowitz. Much ado about noising: Dispelling the myths of generative robotic control, 2026. URL https://arxiv.org/abs/2512.01809
-
[31]
Probabilistic movement primitives
Alexandros Paraschos, Christian Daniel, Jan Peters, and Gerhard Neumann. Probabilistic movement primitives. InAdvances in Neural Information Processing Systems, volume 26, 2013
2013
-
[32]
Aaditya Prasad, Kevin Lin, Jimmy Wu, Linqi Zhou, and Jeannette Bohg. Consistency policy: Accelerated visuomotor policies via consistency distillation, 2024. URL https://arxiv. org/abs/2405.07503
-
[33]
Learning complex dexterous manipulation with deep reinforcement learning and demonstrations
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. InRobotics: Science and Systems (RSS), 2018
2018
-
[34]
Align your flow: Scaling continuous-time flow map distillation, 2025
Amirmojtaba Sabour, Sanja Fidler, and Karsten Kreis. Align your flow: Scaling continuous-time flow map distillation, 2025. URLhttps://arxiv.org/abs/2506.14603
-
[35]
Mp1: Meanflow tames policy learning in 1-step for robotic manipulation, 2025
Juyi Sheng, Ziyi Wang, Peiming Li, and Mengyuan Liu. Mp1: Meanflow tames policy learning in 1-step for robotic manipulation, 2025. URLhttps://arxiv.org/abs/2507.10543
-
[36]
One- step diffusion policy: Fast visuomotor policies via diffusion distillation, 2024
Zhendong Wang, Zhaoshuo Li, Ajay Mandlekar, Zhenjia Xu, Jiaojiao Fan, Yashraj Narang, Linxi Fan, Yuke Zhu, Yogesh Balaji, Mingyuan Zhou, Ming-Yu Liu, and Yu Zeng. One- step diffusion policy: Fast visuomotor policies via diffusion distillation, 2024. URL https: //arxiv.org/abs/2410.21257
-
[37]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on Robot Learning (CoRL), 2020
2020
-
[38]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. In Robotics: Science and Systems (RSS), 2024. URLhttps://arxiv.org/abs/2403.03954. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
best checkpoint / average of last 5 checkpoints
Qinglun Zhang, Zhen Liu, Haoqiang Fan, Guanghui Liu, Bing Zeng, and Shuaicheng Liu. Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation, 2024. URLhttps://arxiv.org/abs/2412.04987. 12 Appendix A Proofs and Derivations This section provides full derivations for the two propositions stated in the mai...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.