Context-aware child-directed speech detection from long-form recordings
Pith reviewed 2026-06-28 16:39 UTC · model grok-4.3
The pith
Incorporating surrounding context and in-domain pre-training substantially improves detection of child-directed speech from long-form recordings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fine-tuning six self-supervised models on child-centered recordings and feeding surrounding context into the classifier produces an absolute 13.8 percent gain in average F1-score for child-directed versus adult-directed speech classification, outperforming both context-free baselines and adult-speech pre-trained models, with usable though reduced performance retained in an end-to-end pipeline from speech detection onward.
What carries the argument
The incorporation of surrounding audio context into the classification step, applied to models that have first undergone in-domain pre-training on child-centered recordings.
If this is right
- In-domain pre-training on child-centered recordings yields higher accuracy than pre-training on adult speech alone.
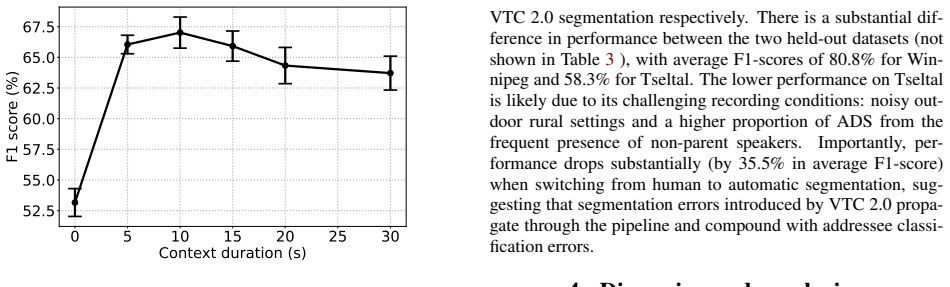
- Context from neighboring utterances raises average F1 by 13.8 percentage points.
- An end-to-end pipeline that includes automatic segmentation still beats a rule-based baseline even after segmentation errors.
Where Pith is reading between the lines
- The method could support larger cross-linguistic studies of children's everyday language exposure without proportional increases in manual annotation effort.
- Performance may degrade further if the target recordings contain heavier background noise or different microphone placements than the training set.
- Extending the context window size or combining it with speaker diarization outputs could produce additional gains.
Load-bearing premise
The manual labels supplied with the 182-child multilingual dataset correctly identify which utterances are directed at the child.
What would settle it
Running the context-aware model on a fresh collection of long-form recordings whose addressee labels were produced by multiple independent human listeners and observing no F1 improvement relative to a context-free model.
Figures
read the original abstract
Automatically distinguishing child-directed speech from adult-directed speech in long-form recordings is key to scalable analyses of children's language environments. Existing approaches process utterances in isolation and have been evaluated primarily on English. We address these gaps along three dimensions. First, we fine-tune and evaluate six-self supervised models on a multilingual dataset of 182 children, showing that in-domain pre-training on child-centered recordings substantially outperforms models trained on adult speech. Second, we demonstrate that incorporating surrounding context substantially improves classification, with an absolute gain of 13.8% in average F1-score. Third, we evaluate our model in a realistic end-to-end pipeline, from adult speech detection to addressee classification, showing that performance drops under automatic segmentation but still consistently outperforms a rule-based baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates six self-supervised speech models fine-tuned on a multilingual dataset of 182 children for distinguishing child-directed from adult-directed speech in long-form recordings. It reports that in-domain pre-training outperforms adult-speech models, that adding surrounding context yields a 13.8% absolute gain in average F1-score, and that the resulting system outperforms a rule-based baseline in a realistic end-to-end pipeline from adult-speech detection to addressee classification.
Significance. If the empirical gains hold under proper validation, the work would provide a practical advance for scalable, automated analysis of children's language environments, extending prior isolated-utterance approaches to multilingual long-form data and demonstrating the value of context and domain-matched pre-training.
major comments (3)
- [Abstract and results] Abstract (paragraph 3) and results section: the headline 13.8% absolute F1 gain from context and the superiority of in-domain pre-training are reported without error bars, statistical tests, or any description of how context is encoded (e.g., concatenation window, attention mechanism) or how train/test splits were performed across the 182 children. These omissions make the central performance claims impossible to assess for robustness.
- [Dataset description] Dataset description (abstract paragraph 2 and methods): the multilingual corpus supplies the sole ground truth for both training and evaluation, yet no inter-annotator agreement statistics, label-distribution tables, or error analysis for ambiguous cases (overlapping speech, cultural prosody variation) are provided. Because all reported F1 numbers rest on these manual labels, their reliability is load-bearing.
- [Pipeline evaluation] End-to-end pipeline evaluation: the text states that performance drops under automatic segmentation but remains above the rule-based baseline; however, no quantitative breakdown of the segmentation error contribution versus the classification error is given, preventing evaluation of whether the context-aware component actually drives the reported improvement in the realistic setting.
minor comments (2)
- [Methods] Model names and pre-training corpora should be listed explicitly in a table rather than referenced only by citation.
- [Figures] Figure captions for the pipeline diagram should clarify the exact input/output of each stage.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below, indicating where we will revise the manuscript to improve clarity and robustness.
read point-by-point responses
-
Referee: [Abstract and results] Abstract (paragraph 3) and results section: the headline 13.8% absolute F1 gain from context and the superiority of in-domain pre-training are reported without error bars, statistical tests, or any description of how context is encoded (e.g., concatenation window, attention mechanism) or how train/test splits were performed across the 182 children. These omissions make the central performance claims impossible to assess for robustness.
Authors: We agree that additional details would strengthen the claims. The train/test splits are speaker-independent across the 182 children (detailed in Methods). Context is incorporated via concatenation of a fixed window of neighboring utterances, processed through the model's attention layers. In revision we will add error bars, statistical tests (e.g., paired significance tests across folds), and an expanded description of the context-encoding procedure. revision: yes
-
Referee: [Dataset description] Dataset description (abstract paragraph 2 and methods): the multilingual corpus supplies the sole ground truth for both training and evaluation, yet no inter-annotator agreement statistics, label-distribution tables, or error analysis for ambiguous cases (overlapping speech, cultural prosody variation) are provided. Because all reported F1 numbers rest on these manual labels, their reliability is load-bearing.
Authors: Labels originate from the existing corpus. We cannot supply inter-annotator agreement because it was not computed or released by the corpus providers. We will add label-distribution tables and a short discussion of ambiguous cases (e.g., overlapping speech) based on available metadata. revision: partial
-
Referee: [Pipeline evaluation] End-to-end pipeline evaluation: the text states that performance drops under automatic segmentation but remains above the rule-based baseline; however, no quantitative breakdown of the segmentation error contribution versus the classification error is given, preventing evaluation of whether the context-aware component actually drives the reported improvement in the realistic setting.
Authors: We will add a quantitative error breakdown in the pipeline section that isolates segmentation error from classification error, allowing readers to assess the contribution of the context-aware model under automatic segmentation. revision: yes
- Inter-annotator agreement statistics for the corpus labels, which are unavailable from the original annotations.
Circularity Check
No circularity: purely empirical results on held-out data
full rationale
The paper reports empirical measurements from fine-tuning and evaluating self-supervised models on a held-out portion of a manually labeled multilingual dataset of 182 children. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains are present in the abstract or described claims. Performance gains (e.g., 13.8% F1 from context) are presented as direct experimental outcomes rather than reductions to training inputs or prior self-authored uniqueness results. The work is self-contained against external benchmarks and does not invoke any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Children’s environments are complex, and the language input they receive is no exception. Among the sources of this com- plexity is the distinction between child-directed speech (CDS), the register adults typically adopt when speaking to young chil- dren, and adult-directed speech (ADS). CDS is characterized by features such as higher pitch, ...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
We then formal- ize the addressee classification problem before introducing the self-supervised models we considered, and the context-aware fine-tuning strategy we implemented
Methods We introduce the corpora used in this study. We then formal- ize the addressee classification problem before introducing the self-supervised models we considered, and the context-aware fine-tuning strategy we implemented. We present the baseline against which our best model is compared and the evaluation metric. We conclude this section by providi...
-
[3]
Effect of self-supervised models We begin by addressing our first question, comparing multiple self-supervised models fine-tuned on our addressee classifica- tion task (Table 2)
Results 3.1. Effect of self-supervised models We begin by addressing our first question, comparing multiple self-supervised models fine-tuned on our addressee classifica- tion task (Table 2). Among out-of-domain models pre-trained on adult speech, W2V2, HuBERT and W2V2-XLSR achieve comparable F1- scores in the 45% - 57% range, suggesting no clear benefit ...
-
[4]
Discussion and conclusion Our results show that large-scale, automatic detection ofwho speaks to the childfrom naturalistic long-form recordings is fea- sible. Importantly, our results highlight two key factors for im- proving performance: domain-matched multilingual pretrain- ing, with BabyHuBERT consistently outperforming other self- supervised models, ...
-
[5]
TC was funded by an ERC grant (InfantSimu- lator, 101142705); AC, KS and TK were funded by an ERC grant (ExELang, 101001095)
Acknowledgments This work was performed using HPC resources from GENCI- IDRIS (Grant 2024-AD01101545 and 2025-AD011016414) and was supported in part by the Agence Nationale pour la Recherche (ANR-17-EURE-0017 Frontcog, ANR10-IDEX- 0001-02 PSL). TC was funded by an ERC grant (InfantSimu- lator, 101142705); AC, KS and TK were funded by an ERC grant (ExELang...
2024
-
[6]
The inevitability of child directed speech,
M. Saxton, “The inevitability of child directed speech,” inLan- guage acquisition. Springer, 2009, pp. 62–86
2009
-
[7]
Acoustic-lexical characteristics of child-directed speech between 7 and 24 months and their impact on toddlers’ phonological processing,
M. Cychosz, J. R. Edwards, N. Bernstein Ratner, C. Torring- ton Eaton, and R. S. Newman, “Acoustic-lexical characteristics of child-directed speech between 7 and 24 months and their impact on toddlers’ phonological processing,”Frontiers in Psychology, vol. 12, p. 712647, 2021
2021
-
[8]
Does child-directed speech facilitate language development in all domains? a study space analysis of the existing evidence,
V . Kempe, M. Ota, and S. Schaeffler, “Does child-directed speech facilitate language development in all domains? a study space analysis of the existing evidence,”Developmental Review, vol. 72, p. 101121, 2024
2024
-
[9]
Word segmentation cues in German child-directed speech: A corpus analysis,
K. St ¨ark, E. Kidd, and R. L. Frost, “Word segmentation cues in German child-directed speech: A corpus analysis,”Language and Speech, vol. 65, no. 1, pp. 3–27, 2022
2022
-
[10]
Quantifying sources of variability in infancy re- search using the infant-directed-speech preference,
M. Consortium, “Quantifying sources of variability in infancy re- search using the infant-directed-speech preference,”Advances in Methods and Practices in Psychological Science, vol. 3, no. 1, pp. 24–52, 2020
2020
-
[11]
Statistical speech seg- mentation and word learning in parallel: Scaffolding from child- directed speech,
D. Yurovsky, C. Yu, and L. B. Smith, “Statistical speech seg- mentation and word learning in parallel: Scaffolding from child- directed speech,”Frontiers in psychology, vol. 3, p. 374, 2012
2012
-
[13]
Language learning, socioeco- nomic status, and child-directed speech,
J. F. Schwab and C. Lew-Williams, “Language learning, socioeco- nomic status, and child-directed speech,”Wiley Interdisciplinary Reviews: Cognitive Science, vol. 7, no. 4, pp. 264–275, 2016
2016
-
[14]
The INTERSPEECH 2017 Computa- tional Paralinguistics Challenge: Addressee, Cold & Snoring,
B. Schuller, S. Steidl, A. Batliner, E. Bergelson, J. Krajewski, C. Janott, A. Amatuni, M. Casillas, A. Seidl, M. Soderstrom, A. S. Warlaumont, G. Hidalgo, S. Schnieder, C. Heiser, W. Hohenhorst, M. Herzog, M. Schmitt, K. Qian, Y . Zhang, G. Trigeorgis, P. Tzi- rakis, and S. Zafeiriou, “The INTERSPEECH 2017 Computa- tional Paralinguistics Challenge: Addre...
2017
-
[15]
DNN- Based Feature Extraction and Classifier Combination for Child- Directed Speech, Cold and Snoring Identification,
G. Gosztolya, R. Busa-Fekete, T. Gr ´osz, and L. T ´oth, “DNN- Based Feature Extraction and Classifier Combination for Child- Directed Speech, Cold and Snoring Identification,” inInterspeech, 2017, pp. 3522–3526
2017
-
[16]
Introducing Weighted Kernel Clas- sifiers for Handling Imbalanced Paralinguistic Corpora: Snoring, Addressee and Cold,
H. Kaya and A. A. Karpov, “Introducing Weighted Kernel Clas- sifiers for Handling Imbalanced Paralinguistic Corpora: Snoring, Addressee and Cold,” inInterspeech, 2017, pp. 3527–3531
2017
-
[17]
An automated classifier for child-directed speech from lena record- ings,
J. Y . Bang, G. Kachergis, A. Weisleder, and V . A. Marchman, “An automated classifier for child-directed speech from lena record- ings,” inProceedings of the 46th annual Boston University Con- ference on Language Development, Y . Gong and F. Kpogo, Eds. Somerville, MA: Cascadilla Press, 2022, pp. 48–61
2022
-
[18]
Hearttoheart: The arts of infant versus adult-directed speech classification,
N. D. Al Futaisi, A. Cristia, and B. W. Schuller, “Hearttoheart: The arts of infant versus adult-directed speech classification,” in International Conference on Acoustics, Speech and Signal Pro- cessing, 2023, pp. 1–5
2023
-
[19]
The weirdest people in the world?
J. Henrich, S. J. Heine, and A. Norenzayan, “The weirdest people in the world?”Behavioral and Brain Sciences, vol. 33, no. 2–3, p. 61–83, 2010
2010
-
[20]
Child- directed speech is infrequent in a forager-farmer population: A time allocation study,
A. Cristia, E. Dupoux, M. Gurven, and J. Stieglitz, “Child- directed speech is infrequent in a forager-farmer population: A time allocation study,”Child Development, vol. 90, no. 3, pp. 759– 773, 2019
2019
-
[21]
Babyhubert: Multilingual self-supervised learning for segmenting speakers in child-centered long-form recordings,
T. Charlot, T. Kunze, M. Poli, A. Cristia, E. Dupoux, and M. Lavechin, “Babyhubert: Multilingual self-supervised learning for segmenting speakers in child-centered long-form recordings,”
-
[22]
[Online]. Available: https://arxiv.org/abs/2509.15001
work page internal anchor Pith review arXiv
-
[23]
Homebank: An online repository of daylong child-centered audio recordings,
M. VanDam, A. S. Warlaumont, E. Bergelson, A. Cristia, M. Soderstrom, P. De Palma, and B. MacWhinney, “Homebank: An online repository of daylong child-centered audio recordings,” Semin Speech Lang, vol. 37, no. 02, pp. 128–142, 2016
2016
-
[24]
Ticuna (tca) language documentation: A guide to ma- terials in the california language archive,
A. Skilton, “Ticuna (tca) language documentation: A guide to ma- terials in the california language archive,”Language Documenta- tion and Conservation, vol. 15, pp. 153–189, 2021
2021
-
[25]
MacWhinney,The CHILDES project, 3rd ed
B. MacWhinney,The CHILDES project, 3rd ed. London, Eng- land: Psychology Press, 2014
2014
-
[26]
Lyon HomeBank Corpus,
M. Canault, M.-T. Le Normand, S. Foudil, N. Loundon, and H. Thai-Van, “Lyon HomeBank Corpus,” HomeBank, 2016, https://homebank.talkbank.org/access/Password/Lyon.html
2016
-
[27]
VanDam Cougar HomeBank Corpus,
M. VanDam, “VanDam Cougar HomeBank Corpus,” Home- Bank, 2018, available at: https://homebank.talkbank.org/access/ Password/Cougar.html
2018
-
[28]
Bergelson Seedlings HomeBank Corpus,
E. Bergelson, “Bergelson Seedlings HomeBank Corpus,” Home- Bank, 2017, available at: https://homebank.talkbank.org/access/ Password/Bergelson.html
2017
-
[29]
Long-form recordings from children in rossel island
A. Cristia and M. Casillas, “Long-form recordings from children in rossel island.” 2020, unpublished raw data
2020
-
[30]
The language 0-5 project,
C. F. Rowland, S. Durrant, M. Peter, A. Bidgood, J. Pine, and L. S. Jago, “The language 0-5 project,” 2025. [Online]. Available: osf.io/kau5f
2025
-
[31]
San Joaquin Valley HomeBank Corpus,
A. S. Warlaumont, G. M. Pretzer, S. Mendoza, S. Schneider, J. Mutrie, L. Lopez, E. A. Walle, and C. T. Kello, “San Joaquin Valley HomeBank Corpus,” HomeBank, 2024, formerly the War- laumont HomeBank Corpus. Available at: https://homebank. talkbank.org/access/Password/SanJoaquin.html
2024
-
[32]
Acoustical cues and grammatical units in speech to two preverbal infants,
M. Soderstrom, M. Blossom, R. Foygel, and J. L. Morgan, “Acoustical cues and grammatical units in speech to two preverbal infants,”Journal of Child Language, vol. 35, no. 4, p. 869–902, 2008
2008
-
[33]
Characteriza- tion of children’s verbal input in a forager-farmer population us- ing long-form audio recordings and diverse input definitions,
C. Scaff, M. Casillas, J. Stieglitz, and A. Cristia, “Characteriza- tion of children’s verbal input in a forager-farmer population us- ing long-form audio recordings and diverse input definitions,”In- fancy, vol. 29, no. 2, pp. 196–215, 2024
2024
-
[34]
PhonSES: A pilot study to measure socioeconomic status association with infants’ word and sound processing,
A. Cristia, “PhonSES: A pilot study to measure socioeconomic status association with infants’ word and sound processing,” GIN,
-
[35]
Available: https://gin.g-node.org/LAAC-LSCP/ phonSES-public
[Online]. Available: https://gin.g-node.org/LAAC-LSCP/ phonSES-public
-
[36]
Two-year-old chil- dren’s production of multiword utterances: A usage-based anal- ysis,
E. Lieven, D. Salomo, and M. Tomasello, “Two-year-old chil- dren’s production of multiword utterances: A usage-based anal- ysis,”Cognitive Linguistics, vol. 20, no. 3, pp. 481–507, 2009
2009
-
[37]
V ocal input and output among infants in a multilingual context: Evidence from long-form recordings in vanuatu,
A. Cristia, L. Gautheron, and H. Colleran, “V ocal input and output among infants in a multilingual context: Evidence from long-form recordings in vanuatu,”Developmental Science, vol. 26, no. 4, p. e13375, 2023
2023
-
[38]
Casillas Home- Bank Corpus,
M. Casillas, P. Brown, and S. C. Levinson, “Casillas Home- Bank Corpus,” HomeBank, 2017, available at: https://homebank. talkbank.org/access/Secure/Casillas.html
2017
-
[39]
Winnipeg HomeBank Corpus,
M. Soderstrom, “Winnipeg HomeBank Corpus,” HomeBank, 2016, https://homebank.talkbank.org/access/Password/Winnipeg. html
2016
-
[40]
Early language ex- perience in a tseltal mayan village,
M. Casillas, P. Brown, and S. C. Levinson, “Early language ex- perience in a tseltal mayan village,”Child Development, vol. 91, no. 5, pp. 1819–1835, 2020
2020
-
[41]
Improving automatic speech recogni- tion performance for low-resource languages with self-supervised models,
J. Zhao and W.-Q. Zhang, “Improving automatic speech recogni- tion performance for low-resource languages with self-supervised models,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1227–1241, 2022
2022
-
[42]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 12 449–12 460
2020
-
[43]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Trans. Audio, Speech and Lang. Proc., vol. 29, p. 3451–3460, 2021
2021
-
[44]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[45]
Lib- rispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: an asr corpus based on public domain audio books,” in 2015 International Conference on Acoustics, Speech and Signal Processing. IEEE, 2015, pp. 5206–5210
2015
-
[46]
Unsupervised Cross-Lingual Representation Learning for Speech Recognition,
A. Conneau, A. Baevski, R. Collobert, A. Mohamed, and M. Auli, “Unsupervised Cross-Lingual Representation Learning for Speech Recognition,” inInterspeech, 2021, pp. 2426–2430
2021
-
[47]
Towards Ro- bust Family-Infant Audio Analysis Based on Unsupervised Pre- training of Wav2vec 2.0 on Large-Scale Unlabeled Family Au- dio,
J. Li, M. Hasegawa-Johnson, and N. L. McElwain, “Towards Ro- bust Family-Infant Audio Analysis Based on Unsupervised Pre- training of Wav2vec 2.0 on Large-Scale Unlabeled Family Au- dio,” inInterspeech, 2023, pp. 1035–1039
2023
-
[48]
Context-aware transformer trans- ducer for speech recognition,
F.-J. Chang, J. Liu, M. Radfar, A. Mouchtaris, M. Omologo, A. Rastrow, and S. Kunzmann, “Context-aware transformer trans- ducer for speech recognition,” inAutomatic Speech Recognition and Understanding Workshop. IEEE, 2021, pp. 503–510
2021
-
[49]
Dialoguernn: An attentive rnn for emotion de- tection in conversations,
N. Majumder, S. Poria, D. Hazarika, R. Mihalcea, A. Gelbukh, and E. Cambria, “Dialoguernn: An attentive rnn for emotion de- tection in conversations,” inProceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 6818–6825
2019
-
[50]
Improv- ing speaker diarization for naturalistic child-adult conversational interactions using contextual information,
M. Kumar, S. H. Kim, C. Lord, and S. Narayanan, “Improv- ing speaker diarization for naturalistic child-adult conversational interactions using contextual information,”The Journal of the Acoustical Society of America, vol. 147, no. 2, pp. EL196–EL200, 2020
2020
-
[51]
An Open-Source V oice Type Classifier for Child-Centered Day- long Recordings,
M. Lavechin, R. Bousbib, H. Bredin, E. Dupoux, and A. Cristia, “An Open-Source V oice Type Classifier for Child-Centered Day- long Recordings,” inInterspeech, 2020, pp. 3072–3076
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.