Unlocking the Black Box of Latent Reasoning: An Interpretability-Guided Approach to Intervention
Pith reviewed 2026-06-28 17:34 UTC · model grok-4.3
The pith
Probes of latent vectors in LLMs reveal compressed reasoning steps and causal hubs that can be used for decode-time interventions to improve accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
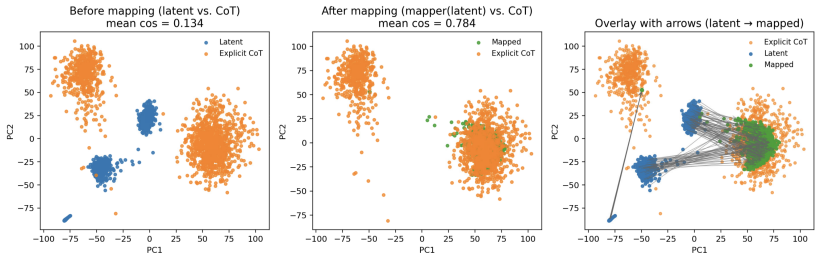
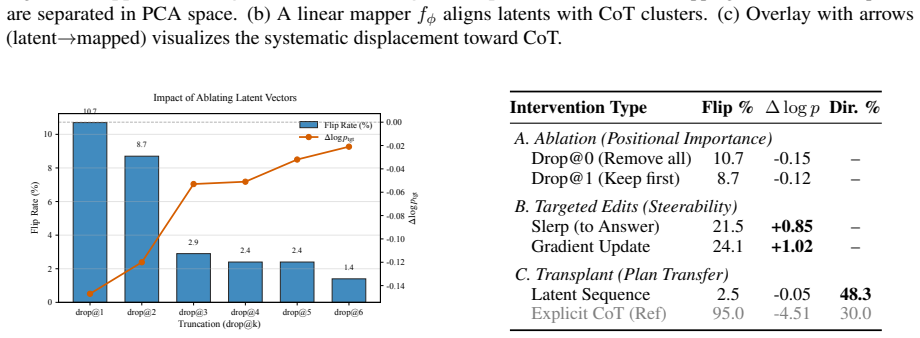
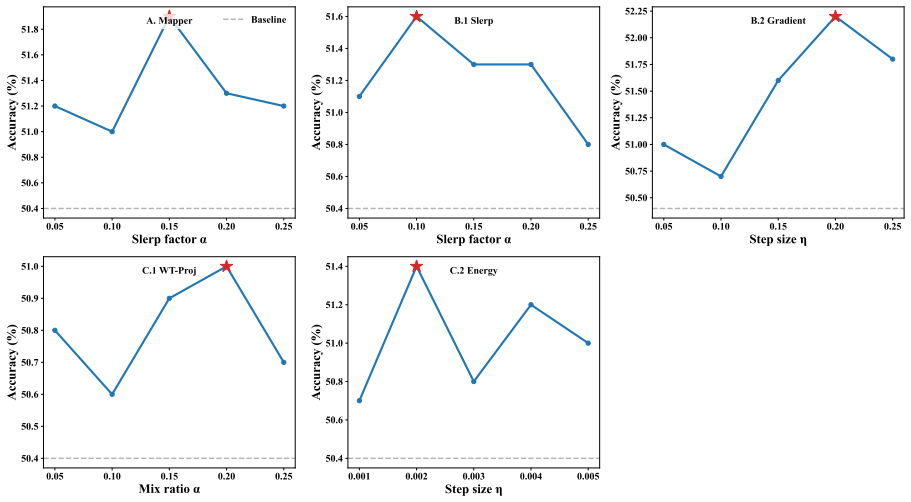
Latent reasoning vectors in LLMs encode compressed, faithful representations of reasoning steps, with early vectors acting as critical causal hubs. By applying interpretability-guided, training-free interventions at decode time that impose identified geometric and semantic priors, reasoning accuracy improves consistently across model scales and task domains without parameter updates.
What carries the argument
Structural, causal, and geometric probes identifying faithful representations and causal hubs in latent vectors to enable decode-time interventions that impose geometric and semantic priors.
If this is right
- Reasoning accuracy increases on multiple tasks without any training or parameter changes.
- Latent capabilities in the model are unlocked through refinement of hidden states.
- Interventions work across different model scales and diverse tasks.
- The method requires no parameter updates.
Where Pith is reading between the lines
- If the probes are reliable, similar methods could be applied to other internal model processes like planning or memory.
- Combining these interventions with explicit chain-of-thought might yield further gains.
- The approach suggests that hidden state geometry can be directly edited for better control over model outputs.
Load-bearing premise
The probes correctly locate faithful representations and causal hubs, and the imposed priors improve reasoning without creating new mistakes or side effects.
What would settle it
Running the interventions on a new set of reasoning tasks and finding no improvement or a drop in accuracy would challenge the claim.
Figures
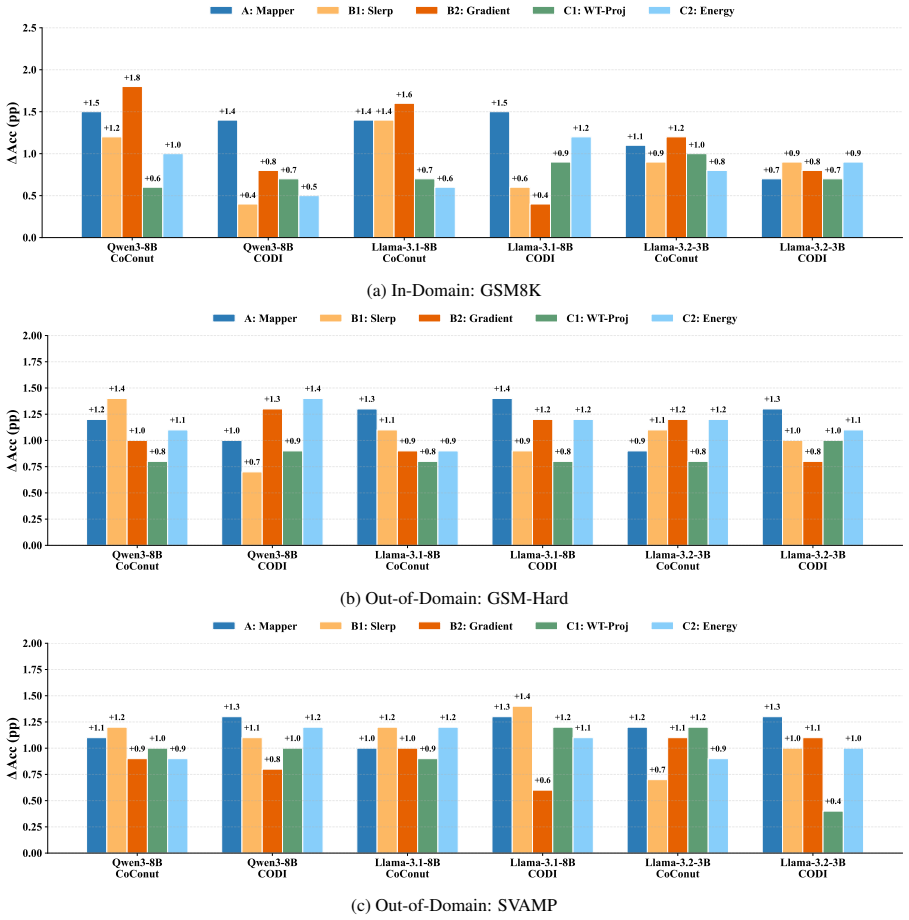
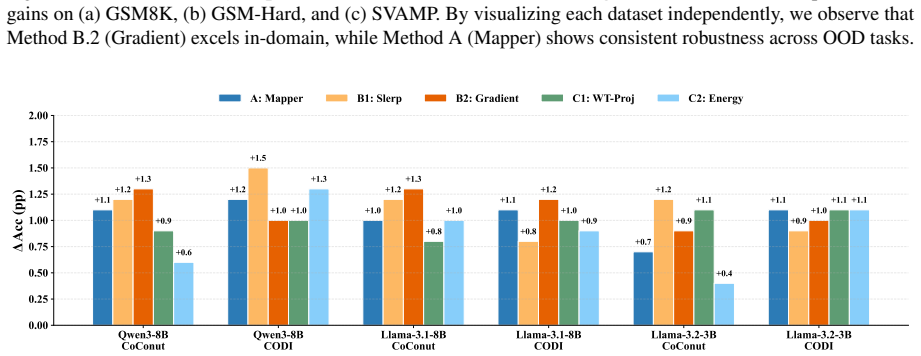
read the original abstract
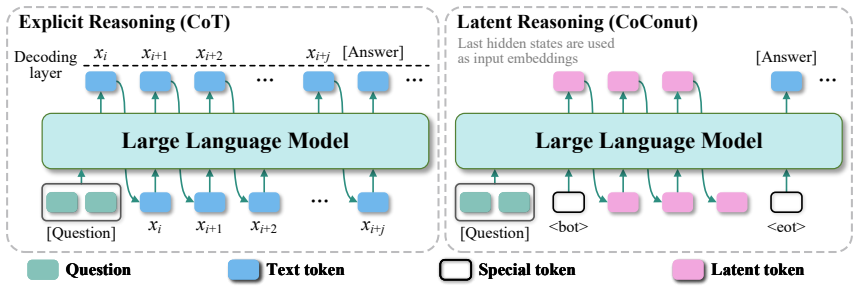
Latent reasoning enables Large Language Models (LLMs) to perform multi-step inference within continuous hidden states, offering efficiency gains over explicit Chain-of-Thought (CoT). However, the opacity of these continuous thought vectors hinders their reliability and controllability. This paper bridges the gap between mechanistic interpretability and actionable control. We first present a systematic analysis using structural, causal, and geometric probes, revealing that latent vectors encode compressed, faithful representations of reasoning steps, with early vectors acting as critical causal hubs. Building on this, we operationalize these interpretability insights into a suite of training-free, decode-time interventions that refine the latent reasoning process by imposing the identified geometric and semantic priors. Extensive experiments across multiple model scales and diverse task domains demonstrate that our approaches consistently improve reasoning accuracy. Our interpretability-guided interventions consistently unlock latent capabilities and improve reasoning accuracy without any parameter updates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that structural, causal, and geometric probes applied to LLM latent reasoning vectors reveal compressed faithful representations of reasoning steps, with early vectors serving as critical causal hubs. It then derives training-free decode-time interventions that impose the identified geometric and semantic priors to refine the latent reasoning process, reporting consistent accuracy gains across model scales and task domains without parameter updates.
Significance. If the central claim holds, the work would be significant for bridging mechanistic interpretability with practical control of latent reasoning. The training-free nature of the interventions and the multi-probe analysis across scales would represent a useful advance over explicit CoT methods, provided the probes are shown to isolate causally used representations rather than surface correlations.
major comments (2)
- [Abstract] Abstract: the assertion that the probes identify 'faithful representations' and 'critical causal hubs' and that the resulting interventions 'consistently improve reasoning accuracy' is not accompanied by any quantitative results, baselines, error bars, or validation metrics (e.g., do-operations on identified hubs or ablation against random vectors). This evidence gap is load-bearing for the claim that gains arise specifically from interpretability-derived priors.
- [Abstract] The weakest assumption (probes correctly isolate causally faithful representations rather than correlated features) is not addressed with the tests mentioned in the skeptic note, such as explicit comparison to CoT traces or random-vector controls. Without these, the reported accuracy improvements cannot be attributed to the geometric/semantic priors rather than any structured perturbation.
minor comments (1)
- [Abstract] Abstract: the terms 'structural, causal, and geometric probes' and 'decode-time interventions' are introduced without a one-sentence definition, which may hinder readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the concerns about the abstract's lack of quantitative support and validation of causal claims below, and commit to revisions that improve clarity without altering the core findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the probes identify 'faithful representations' and 'critical causal hubs' and that the resulting interventions 'consistently improve reasoning accuracy' is not accompanied by any quantitative results, baselines, error bars, or validation metrics (e.g., do-operations on identified hubs or ablation against random vectors). This evidence gap is load-bearing for the claim that gains arise specifically from interpretability-derived priors.
Authors: We agree the abstract is too high-level and does not convey the supporting metrics. The full manuscript reports accuracy gains with error bars across model scales, includes random-vector ablations, and performs do-operations on the identified hubs to isolate causal effects. We will revise the abstract to include representative quantitative results (e.g., mean accuracy deltas and mention of controls) so the claims are grounded in the reported evidence. revision: yes
-
Referee: [Abstract] The weakest assumption (probes correctly isolate causally faithful representations rather than correlated features) is not addressed with the tests mentioned in the skeptic note, such as explicit comparison to CoT traces or random-vector controls. Without these, the reported accuracy improvements cannot be attributed to the geometric/semantic priors rather than any structured perturbation.
Authors: The manuscript already contains explicit random-vector controls and comparisons against CoT traces to demonstrate that improvements arise from the probe-derived priors rather than generic perturbations. These appear in the intervention ablation sections. We will add a concise reference to these controls in the revised abstract to foreground the validation. If the skeptic note specifies additional tests beyond what is currently reported, we can incorporate them. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's chain consists of empirical analysis via structural/causal/geometric probes to characterize latent vectors, followed by design of decode-time interventions that impose derived priors, with performance validated on held-out tasks and model scales. No equations, fitted parameters, or results are shown to reduce to their own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming patterns appear in the provided text. The central claim (accuracy gains from interpretability-guided interventions) rests on experimental outcomes rather than definitional equivalence or statistical forcing, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
Training Large Language Models to Reason in a Continuous Latent Space , author=. 2024 , eprint=
2024
-
[2]
2024 , eprint=
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking , author=. 2024 , eprint=
2024
-
[3]
2025 , eprint=
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation , author=. 2025 , eprint=
2025
-
[4]
2025 , eprint=
SIM-CoT: Supervised Implicit Chain-of-Thought , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
MARCOS: Deep Thinking by Markov Chain of Continuous Thoughts , author=. 2025 , eprint=
2025
-
[6]
2025 , eprint=
System-1.5 Reasoning: Traversal in Language and Latent Spaces with Dynamic Shortcuts , author=. 2025 , eprint=
2025
-
[7]
2025 , eprint=
PonderLM-2: Pretraining LLM with Latent Thoughts in Continuous Space , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space , author=. 2025 , eprint=
2025
-
[9]
2025 , eprint=
Think Silently, Think Fast: Dynamic Latent Compression of LLM Reasoning Chains , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
Seek in the Dark: Reasoning via Test-Time Instance-Level Policy Gradient in Latent Space , author=. 2025 , eprint=
2025
-
[11]
2025 , eprint=
Latent Reasoning in LLMs as a Vocabulary-Space Superposition , author=. 2025 , eprint=
2025
-
[12]
2025 , eprint=
LTA-thinker: Latent Thought-Augmented Training Framework for Large Language Models on Complex Reasoning , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
LatentEvolve: Self-Evolving Test-Time Scaling in Latent Space , author=. 2025 , eprint=
2025
-
[14]
2025 , eprint=
Reasoning with Latent Thoughts: On the Power of Looped Transformers , author=. 2025 , eprint=
2025
-
[15]
2025 , eprint=
Scaling Latent Reasoning via Looped Language Models , author=. 2025 , eprint=
2025
-
[16]
2025 , eprint=
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach , author=. 2025 , eprint=
2025
-
[17]
2024 , eprint=
Think before you speak: Training Language Models With Pause Tokens , author=. 2024 , eprint=
2024
-
[18]
2025 , eprint=
A Survey on Context-Aware Multi-Agent Systems: Techniques, Challenges and Future Directions , author=. 2025 , eprint=
2025
-
[19]
2024 , eprint=
Retrieval-augmented Multi-modal Chain-of-Thoughts Reasoning for Large Language Models , author=. 2024 , eprint=
2024
-
[20]
2025 , eprint=
A Survey on Latent Reasoning , author=. 2025 , eprint=
2025
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
D3ToM: Decider-Guided Dynamic Token Merging for Accelerating Diffusion MLLMs , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2026 , month=. doi:10.1609/aaai.v40i24.39080 , number=
-
[22]
2025 , eprint=
Implicit Reasoning in Large Language Models: A Comprehensive Survey , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[25]
2023 , eprint=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. 2023 , eprint=
2023
-
[26]
2026 , eprint=
Context Tokens are Anchors: Understanding the Repetition Curse in dMLLMs from an Information Flow Perspective , author=. 2026 , eprint=
2026
-
[27]
2025 , eprint=
Efficient Long CoT Reasoning in Small Language Models , author=. 2025 , eprint=
2025
-
[28]
2023 , eprint=
How Language Model Hallucinations Can Snowball , author=. 2023 , eprint=
2023
-
[29]
2023 , eprint=
Measuring Faithfulness in Chain-of-Thought Reasoning , author=. 2023 , eprint=
2023
-
[30]
2021 , eprint=
Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies , author=. 2021 , eprint=
2021
-
[31]
2023 , eprint=
GPT-4 Technical Report , author=. 2023 , eprint=
2023
-
[32]
2025 , eprint=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. 2025 , eprint=
2025
-
[33]
2023 , eprint=
Locating and Editing Factual Associations in GPT , author=. 2023 , eprint=
2023
-
[34]
2024 , eprint=
ReFT: Representation Finetuning for Language Models , author=. 2024 , eprint=
2024
-
[35]
2019 , eprint=
Similarity of Neural Network Representations Revisited , author=. 2019 , eprint=
2019
-
[36]
2022 , eprint=
Reliability of CKA as a Similarity Measure in Deep Learning , author=. 2022 , eprint=
2022
-
[37]
2018 , eprint=
Understanding intermediate layers using linear classifier probes , author=. 2018 , eprint=
2018
-
[38]
2026 , eprint=
Breaking Dual Bottlenecks: Evolving Unified Multimodal Models into Self-Adaptive Interleaved Visual Reasoners , author=. 2026 , eprint=
2026
-
[39]
2024 , eprint=
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task , author=. 2024 , eprint=
2024
-
[40]
2024 , eprint=
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step , author=. 2024 , eprint=
2024
-
[41]
2025 , eprint=
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought , author=. 2025 , eprint=
2025
-
[42]
2024 , eprint=
Encourage or Inhibit Monosemanticity? Revisit Monosemanticity from a Feature Decorrelation Perspective , author=. 2024 , eprint=
2024
-
[43]
2024 , eprint=
Steering Language Models With Activation Engineering , author=. 2024 , eprint=
2024
-
[44]
Liu, Qingyang and Li, Jiangtong and Peng, Zelin and Wang, Shaobo and Liao, Zhaohe and Chang, Shuochen and Gao, Bingjie and Zhao, Haonan and Liu, Mu and Jiang, Jidong and Niu, Li , title =. 2026 , isbn =. doi:10.1145/3774904.3792827 , booktitle =
-
[45]
2024 , eprint=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. 2024 , eprint=
2024
-
[46]
2024 , eprint=
Can Language Models Learn to Skip Steps? , author=. 2024 , eprint=
2024
-
[47]
2025 , eprint=
Do LLMs Really Think Step-by-step In Implicit Reasoning? , author=. 2025 , eprint=
2025
-
[48]
2025 , eprint=
Fractional Reasoning via Latent Steering Vectors Improves Inference Time Compute , author=. 2025 , eprint=
2025
-
[49]
2023 , eprint=
Contrastive Decoding: Open-ended Text Generation as Optimization , author=. 2023 , eprint=
2023
-
[50]
2025 , eprint=
Efficient Reasoning with Hidden Thinking , author=. 2025 , eprint=
2025
-
[51]
2025 , eprint=
Latent Chain-of-Thought? Decoding the Depth-Recurrent Transformer , author=. 2025 , eprint=
2025
-
[52]
2025 , eprint=
Latent Thinking Optimization: Your Latent Reasoning Language Model Secretly Encodes Reward Signals in Its Latent Thoughts , author=. 2025 , eprint=
2025
-
[53]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[54]
2023 , eprint=
PAL: Program-aided Language Models , author=. 2023 , eprint=
2023
-
[55]
2021 , eprint=
Are NLP Models really able to Solve Simple Math Word Problems? , author=. 2021 , eprint=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.