TukaBench: A Culturally Grounded Jailbreak Benchmark for African Languages
Pith reviewed 2026-06-28 17:11 UTC · model grok-4.3
The pith
Prompting LLMs in African languages reduces refusal to jailbreak attempts compared to English, with culturally adapted prompts showing the least refusal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
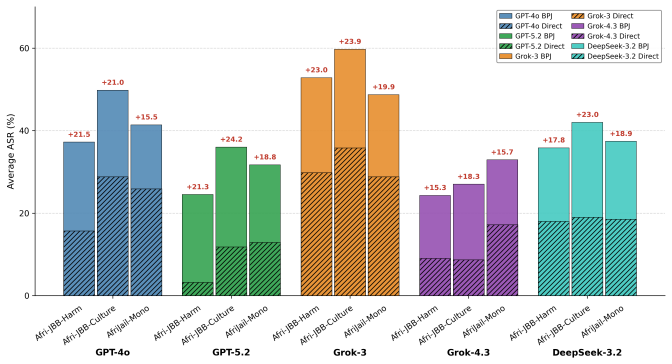
TukaBench shows that refusal rates drop when jailbreak prompts appear in African languages rather than English, reaching their lowest levels with prompts adapted to African cultural contexts. The work introduces a Deflection category to capture cases where models fail to comprehend the request and finds that LLM-as-a-judge agreement with human annotations declines in lower-resource languages and less common scripts.
What carries the argument
TukaBench, a jailbreak benchmark that extends JailbreakBench through four settings—human translation, cultural adaptation followed by translation, human curation, and code-switching—to isolate language, cultural grounding, and evasiveness effects on model refusal.
Load-bearing premise
Human translations, cultural adaptations, and curations of prompts isolate language and cultural effects without introducing systematic differences in prompt difficulty or what counts as a jailbreak attempt.
What would settle it
A side-by-side test in which the same jailbreak attempts are translated, culturally adapted, and back-translated, then measured for equal model comprehension and refusal rates across languages.
Figures
read the original abstract
Safety evaluation of Large Language Models (LLMs) remains heavily English-centric, leaving Low-Resource Languages (LRLs), particularly African ones, critically underexplored. We introduce TUKABENCH, a jailbreak benchmark for seven African languages that extends JailbreakBench (JBB) beyond direct translation through four settings: human translation of JBB prompts, English adaptation to African contexts followed by human translation, human-curated prompts validated through interactions with GPT-5.2, and code-switched prompts combining English and African languages, isolating the effect of language, cultural grounding, and prompt evasiveness on model safety. Across closed and open models, prompting in African languages reduces refusal relative to English, with culturally adapted prompts leading to least refusal. The evaluation also surfaces two structural limitations: model comprehension failures and reduced LLM-as-a-judge reliability in LRLs. To capture the first, we introduce Deflection alongside Refused and Jailbroken; to assess the second, we validate outputs with human annotations, showing that judge-human agreement drops in lower-resource languages and less commonly supported scripts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TukaBench, a jailbreak benchmark extending JailbreakBench to seven African languages via four settings (direct human translation of JBB prompts, English-to-African-context adaptation followed by translation, GPT-5.2-validated human curation, and code-switched prompts). It claims that prompting in African languages reduces refusal rates relative to English across closed and open models, with culturally adapted prompts yielding the lowest refusal. The work adds a Deflection category to capture comprehension failures and validates LLM-as-a-judge outputs via human annotations, reporting lower judge-human agreement in lower-resource languages and scripts.
Significance. If the central empirical claims hold after addressing gaps in controls and reporting, the benchmark would be a meaningful contribution to LLM safety evaluation by filling a gap in non-English, culturally grounded testing and surfacing language-specific failure modes. The introduction of Deflection and human validation of judges are practical additions that could inform future multilingual safety work.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation sections provide no sample sizes, exact refusal criteria definitions, inter-annotator agreement statistics, or statistical significance tests for the refusal-rate comparisons. These omissions make it impossible to evaluate the reliability or generalizability of the claim that African-language prompts reduce refusal.
- [Prompt Construction / § on settings] The four prompt settings are asserted to isolate effects of language and cultural grounding, yet no metrics (e.g., difficulty ratings, intent-preservation scores, or side-by-side human judgments of elicitation strength) are reported to verify that adapted/curated prompts maintain equivalent harmful intent and difficulty to the direct translations. Any systematic shift in prompt content would attribute refusal differences to the adaptations themselves rather than the claimed factors.
minor comments (2)
- [Annotation protocol] Clarify the exact criteria used by human annotators for labeling Refused, Jailbroken, and Deflection to allow replication.
- [Results tables/figures] Add explicit language names and script information to all tables and figures reporting per-language results.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and recommendation for major revision. The comments highlight important areas for improving the transparency and rigor of our evaluation methodology. We respond to each major comment below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation sections provide no sample sizes, exact refusal criteria definitions, inter-annotator agreement statistics, or statistical significance tests for the refusal-rate comparisons. These omissions make it impossible to evaluate the reliability or generalizability of the claim that African-language prompts reduce refusal.
Authors: We agree that these methodological details are essential for assessing the reliability of our findings and were not adequately presented in the abstract or evaluation sections. In the revised manuscript, we will include the sample sizes used (prompts per setting and language), precise definitions of the refusal criteria including the new Deflection category, inter-annotator agreement statistics from the human validation of LLM-as-a-judge outputs, and results of statistical significance tests for the reported refusal rate comparisons. These additions will allow readers to better evaluate the generalizability of the claims. revision: yes
-
Referee: [Prompt Construction / § on settings] The four prompt settings are asserted to isolate effects of language and cultural grounding, yet no metrics (e.g., difficulty ratings, intent-preservation scores, or side-by-side human judgments of elicitation strength) are reported to verify that adapted/curated prompts maintain equivalent harmful intent and difficulty to the direct translations. Any systematic shift in prompt content would attribute refusal differences to the adaptations themselves rather than the claimed factors.
Authors: The design of the four settings was intended to progressively introduce cultural grounding and code-switching while maintaining the core harmful intent from the original JailbreakBench prompts, with human translators and curators instructed to preserve intent. However, we did not report quantitative metrics to empirically verify equivalence in difficulty or elicitation strength. We acknowledge this limitation and will add human evaluation metrics, such as intent-preservation scores and difficulty ratings from side-by-side comparisons, in the revised section on prompt construction to strengthen the validity of the comparisons. revision: yes
Circularity Check
No circularity: empirical benchmark construction with human curation
full rationale
The paper introduces TUKABENCH via four human-driven prompt construction settings (direct translation, cultural adaptation+translation, GPT-validated curation, code-switching) and reports refusal rates across models. No equations, fitted parameters, predictions, or derivations exist that could reduce to inputs by construction. The central claim is an empirical observation about refusal differences; the isolation of language/culture effects rests on the validity of human annotations rather than any self-referential definition or self-citation chain. This is a standard benchmark paper whose results are falsifiable via external replication and do not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human translations and cultural adaptations of prompts isolate language and cultural effects without introducing uncontrolled bias in difficulty or intent.
Reference graph
Works this paper leans on
-
[1]
2024 , url =
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , journal =. 2024 , url =
2024
-
[2]
International Conference on Learning Representations (ICLR) , year =
Multilingual Jailbreak Challenges in Large Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[3]
, journal =
Yong, Zheng-Xin and Menghini, Cristina and Bach, Stephen H. , journal =. Low-Resource Languages Jailbreak. 2023 , url =
2023
-
[4]
Boundary Point Jailbreaking of Black-Box
Davies, Xander and Giglemiani, Giorgi and Lau, Edmund and Winsor, Eric and Irving, Geoffrey and Gal, Yarin , journal =. Boundary Point Jailbreaking of Black-Box. 2026 , url =
2026
-
[5]
2026 , url =
Abdullahi, Tassallah and Mgonzo, Macton and Oduwole, Mardiyyah and Okewunmi, Paul and Owodunni, Abraham and Singh, Ritambhara and Eickhoff, Carsten , journal =. 2026 , url =
2026
-
[6]
2026 , url =
Zhao, Yunhan and Chen, Zhaorun and Ma, Xingjun and Jiang, Yu-Gang and Li, Bo , journal =. 2026 , url =
2026
-
[7]
2026 , url =
Hou, Yutao and Jiang, Yihan and Xie, Yuhan and Yang, Jian and Zhang, Liwen and Huang, Hailiang and Chen, Guanhua and Chen, Yun , journal =. 2026 , url =
2026
-
[8]
One Word at a Time: Incremental Completion Decomposition Breaks
Arif, Samee and others , journal =. One Word at a Time: Incremental Completion Decomposition Breaks. 2026 , url =
2026
-
[9]
arXiv preprint arXiv:2603.16192 , year =
Structured Semantic Cloaking for Jailbreak Attacks on Large Language Models , author =. arXiv preprint arXiv:2603.16192 , year =
-
[10]
Break Me If You Can: Self-Jailbreaking of Aligned
Kulshreshtha, Devang and Su, Hang and Jin, Haibo and Hegde, Chinmay and Wang, Haohan , journal =. Break Me If You Can: Self-Jailbreaking of Aligned. 2026 , url =
2026
-
[11]
arXiv preprint arXiv:2501.17805 , year=
International ai safety report , author=. arXiv preprint arXiv:2501.17805 , year=
-
[12]
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe, R...
2022
-
[13]
2023 , eprint=
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. 2023 , eprint=
2023
-
[14]
S afety B ench: Evaluating the Safety of Large Language Models
Zhang, Zhexin and Lei, Leqi and Wu, Lindong and Sun, Rui and Huang, Yongkang and Long, Chong and Liu, Xiao and Lei, Xuanyu and Tang, Jie and Huang, Minlie. S afety B ench: Evaluating the Safety of Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/20...
-
[15]
Truong and Simran Arora and Mantas Mazeika and Dan Hendrycks and Zinan Lin and Yu Cheng and Sanmi Koyejo and Dawn Song and Bo Li , booktitle=
Boxin Wang and Weixin Chen and Hengzhi Pei and Chulin Xie and Mintong Kang and Chenhui Zhang and Chejian Xu and Zidi Xiong and Ritik Dutta and Rylan Schaeffer and Sang T. Truong and Simran Arora and Mantas Mazeika and Dan Hendrycks and Zinan Lin and Yu Cheng and Sanmi Koyejo and Dawn Song and Bo Li , booktitle=. DecodingTrust: A Comprehensive Assessment o...
2023
-
[16]
arXiv preprint arXiv:2404.08676 , year=
ALERT: A comprehensive benchmark for assessing large language models' safety through red teaming , author=. arXiv preprint arXiv:2404.08676 , year=
-
[17]
2025 , url=
Felix Friedrich and Simone Tedeschi and Patrick Schramowski and Manuel Brack and Roberto Navigli and Huu Nguyen and Bo Li and Kristian Kersting , booktitle=. 2025 , url=
2025
-
[18]
Second Conference on Language Modeling , year=
PolyGuard: A Multilingual Safety Moderation Tool for 17 Languages , author=. Second Conference on Language Modeling , year=
-
[19]
The Twelfth International Conference on Learning Representations , year=
Multilingual Jailbreak Challenges in Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[20]
Low-Resource Languages Jailbreak
Zheng Xin Yong and Cristina Menghini and Stephen Bach , booktitle=. Low-Resource Languages Jailbreak. 2023 , url=
2023
-
[21]
arXiv preprint arXiv:2511.00689 , year=
Do Methods to Jailbreak and Defend LLMs Generalize Across Languages? , author=. arXiv preprint arXiv:2511.00689 , year=
-
[22]
arXiv preprint arXiv:2401.16765 , year=
A cross-language investigation into jailbreak attacks in large language models , author=. arXiv preprint arXiv:2401.16765 , year=
-
[23]
and Tram
Chao, Patrick and Debenedetti, Edoardo and Robey, Alexander and Andriushchenko, Maksym and Croce, Francesco and Sehwag, Vikash and Dobriban, Edgar and Flammarion, Nicolas and Pappas, George J. and Tram. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =
-
[24]
Adelani, David Ifeoluwa and Alabi, Jesujoba Oluwadara and Fan, Angela and Kreutzer, Julia and Shen, Xiaoyu and Reid, Machel and Ruiter, Dana and Klakow, Dietrich and Nabende, Peter and Chang, Ernie and Gwadabe, Tajuddeen and Sackey, Freshia and Dossou, Bonaventure F. P. and Emezue, Chris Chinenye and Leong, Colin and Beukman, Michael and Muhammad, Shamsud...
2022
-
[25]
and Hamidouche, Wassim and Zamir, Syed Waqas and Adelani, David Ifeoluwa , journal =
Yu, Hao and Xu, Tianyi and Hedderich, Michael A. and Hamidouche, Wassim and Zamir, Syed Waqas and Adelani, David Ifeoluwa , journal =
-
[26]
Li, Senyu and Wang, Jiayi and Ali, Felermino D. M. A. and Cherry, Colin and Deutsch, Daniel and Briakou, Eleftheria and Sousa-Silva, Rui and Lopes Cardoso, Henrique and Stenetorp, Pontus and Adelani, David Ifeoluwa , booktitle =. 2025 , address =
2025
-
[27]
Multilingual Blending:
Song, Jiayang and Huang, Yuheng and Wang, Zhehua and Ma, Lei , booktitle =. Multilingual Blending:
-
[28]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph E and Stoica, Ion , booktitle =. Judging
-
[29]
METAL : Towards Multilingual Meta-Evaluation
Hada, Rishav and Gumma, Varun and Ahmed, Mohamed and Bali, Kalika and Sitaram, Sunayana. METAL : Towards Multilingual Meta-Evaluation. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.148
-
[30]
Are Large Language Model-based Evaluators the Solution to Scaling Up Multilingual Evaluation?
Hada, Rishav and Gumma, Varun and de Wynter, Adrian and Diddee, Harshita and Ahmed, Mohamed and Choudhury, Monojit and Bali, Kalika and Sitaram, Sunayana. Are Large Language Model-based Evaluators the Solution to Scaling Up Multilingual Evaluation?. Findings of the Association for Computational Linguistics: EACL 2024. 2024. doi:10.18653/v1/2024.findings-eacl.71
-
[31]
2026 , eprint=
AfriqueLLM: How Data Mixing and Model Architecture Impact Continued Pre-training for African Languages , author=. 2026 , eprint=
2026
-
[32]
Code-Switching Red-Teaming: LLM Evaluation for Safety and Multilingual Understanding
Yoo, Haneul and Yang, Yongjin and Lee, Hwaran. Code-Switching Red-Teaming: LLM Evaluation for Safety and Multilingual Understanding. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.657
-
[33]
COMET : A Neural Framework for MT Evaluation
Rei, Ricardo and Stewart, Craig and Farinha, Ana C and Lavie, Alon. COMET : A Neural Framework for MT Evaluation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.213
-
[34]
Lundin, Jessica M. and Zhang, Ada and Karim, Nihal and Louzan, Hamza and Wei, Guohao and Adelani, David Ifeoluwa and Carroll, Cody. The Token Tax: Systematic Bias in Multilingual Tokenization. Proceedings of the 7th Workshop on A frican Natural Language Processing ( A frica NLP 2026). 2026. doi:10.18653/v1/2026.africanlp-main.10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.