Autopilot-Preserving Residual Q-Learning with HJB-Inspired Finite-Action Risk Filtering for Fixed-Wing UAV Command Supervision
Pith reviewed 2026-06-28 16:48 UTC · model grok-4.3
The pith
A learned supervisor above an unchanged autopilot uses HJB residual scoring to cut fixed-wing UAV path error by 86 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
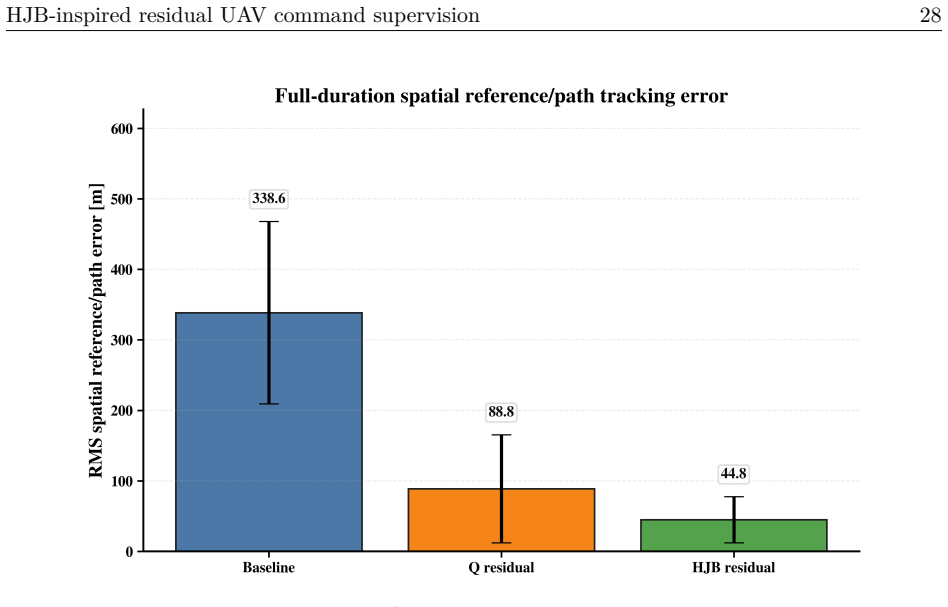
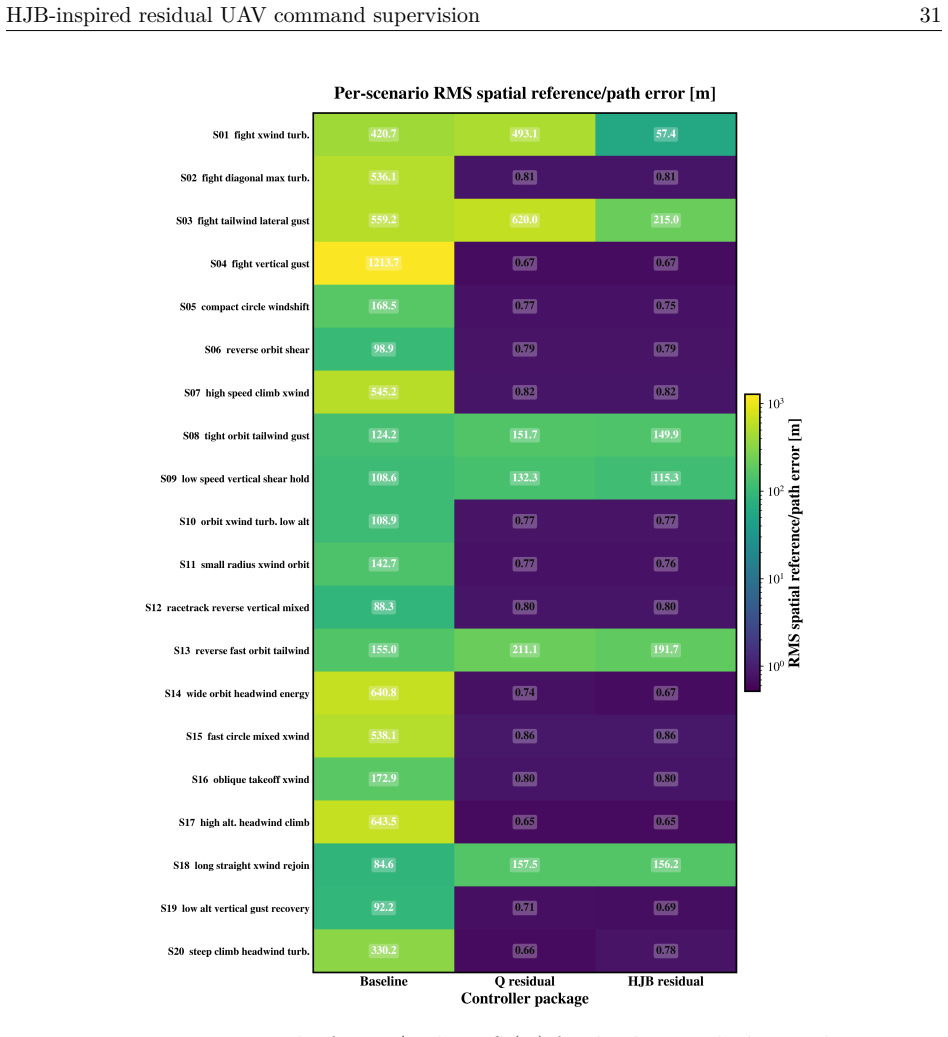
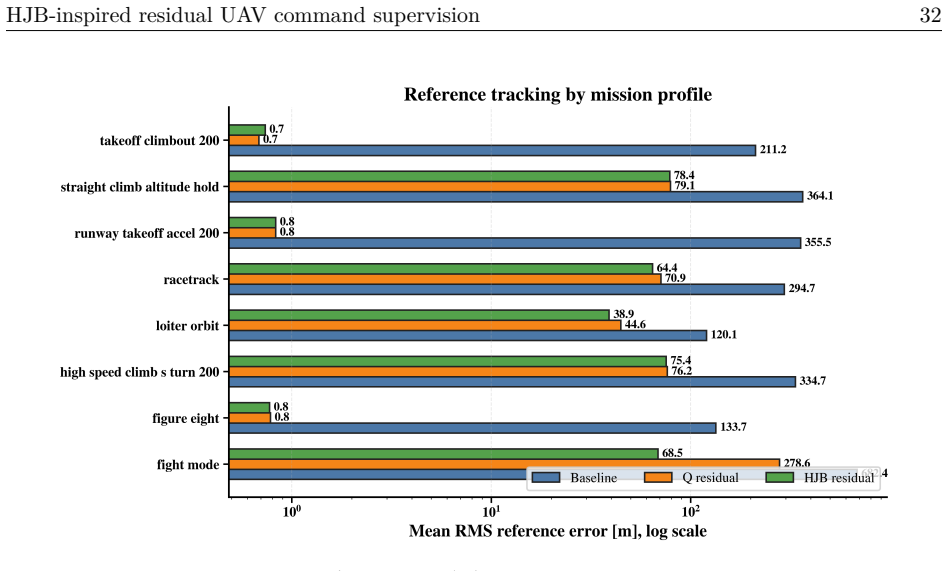
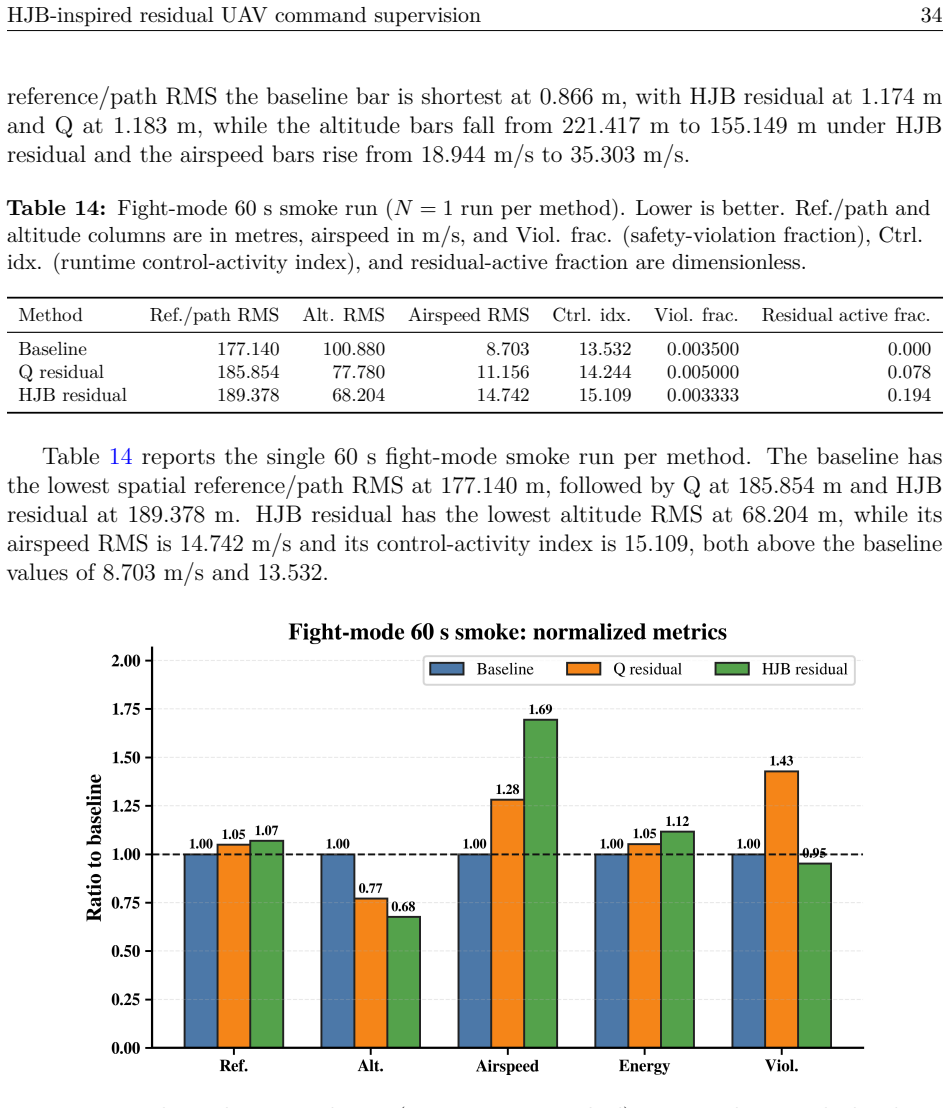
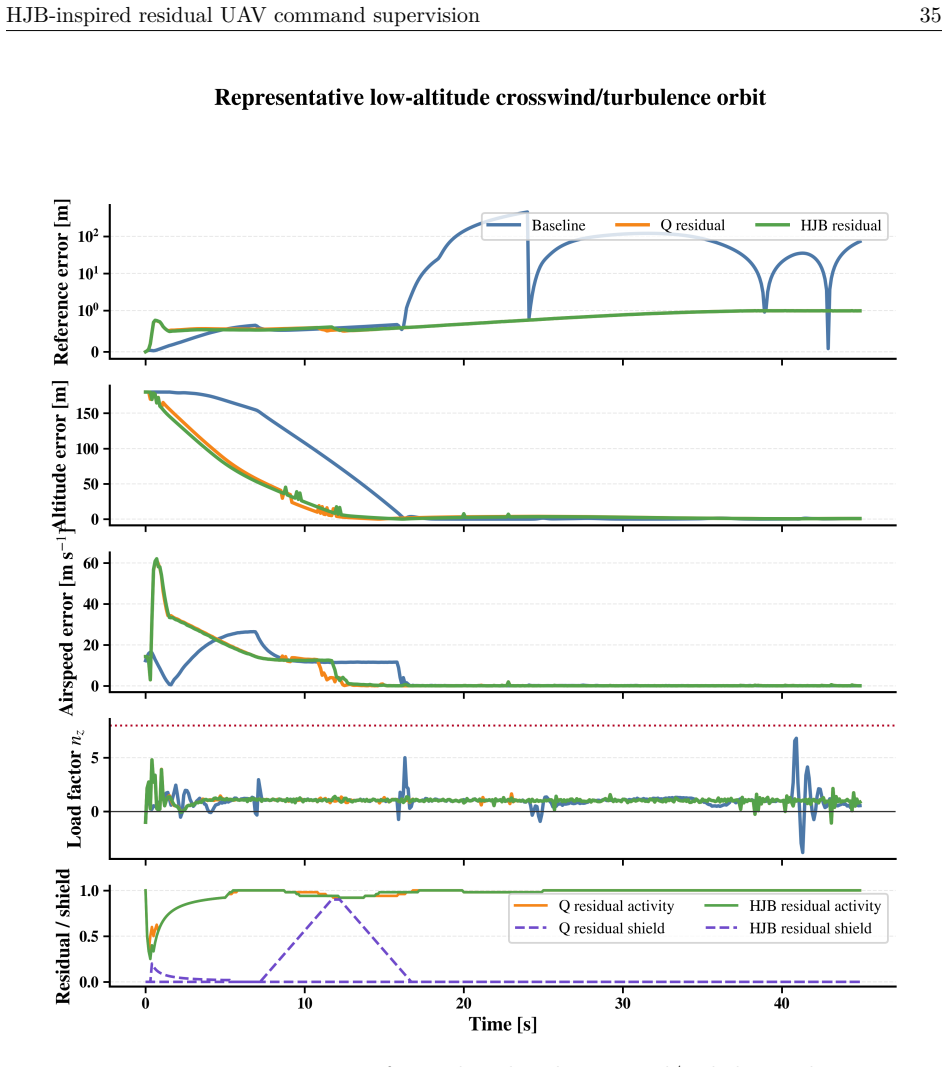
The paper claims that placing an HJB residual scorer with finite-action risk filtering above an unmodified autopilot lets the system choose safe command adjustments from a bounded set, yielding a mean RMS path-tracking error of 44.809 m against 338.617 m for the baseline autopilot and 88.809 m for tabular-Q residual on identical runtime models.
What carries the argument
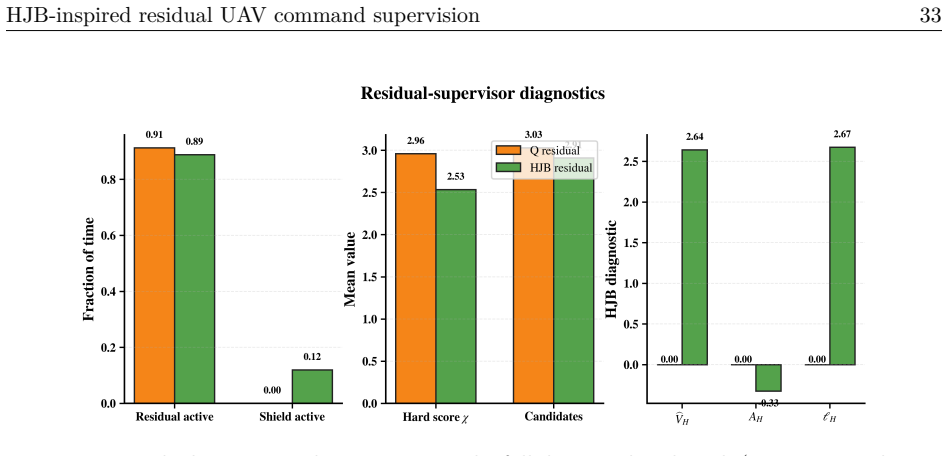
The HJB residual scorer that evaluates finite command residuals via semi-discrete value-iteration critic and no-op-relative Hamiltonian advantage, then shields them with a control-Lyapunov and control-barrier inspired filter that always retains the no-op option.
If this is right
- The autopilot and actuator interface remain untouched, so the method adds supervision without recertifying the inner loop.
- The finite action set and no-op fallback keep the system from issuing unsafe commands even when the critic is uncertain.
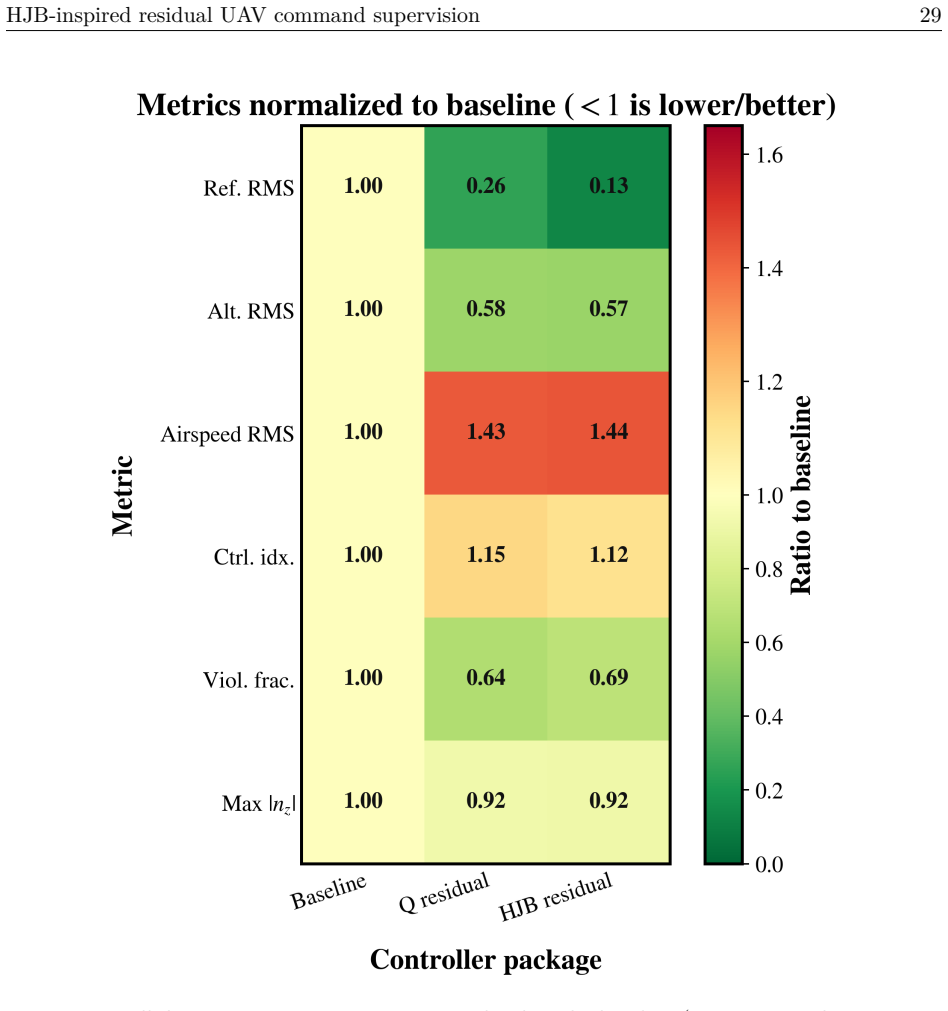
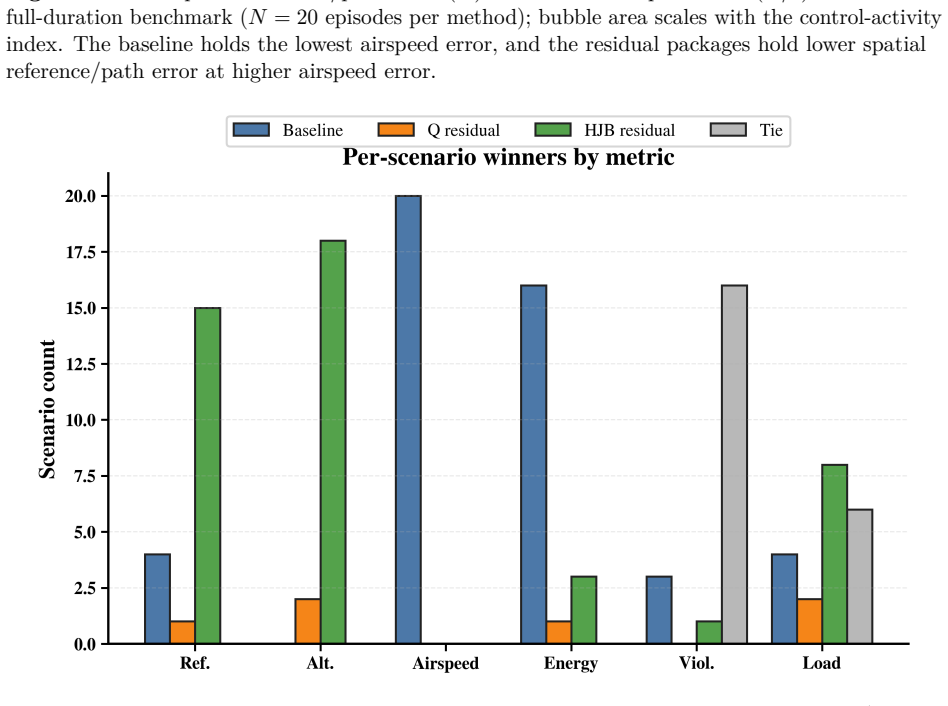
- Gains concentrate in the wind and turn regimes where the baseline autopilot deviates most from the path.
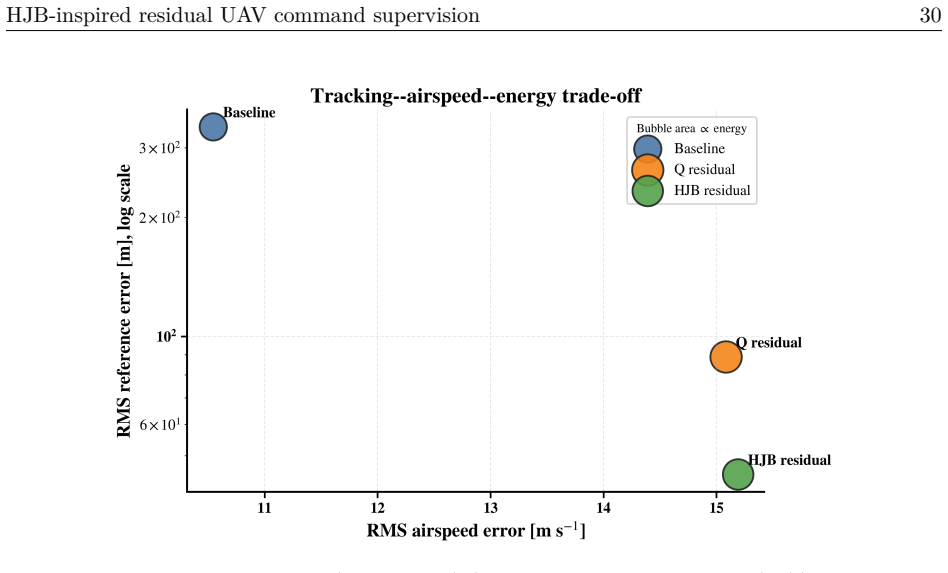
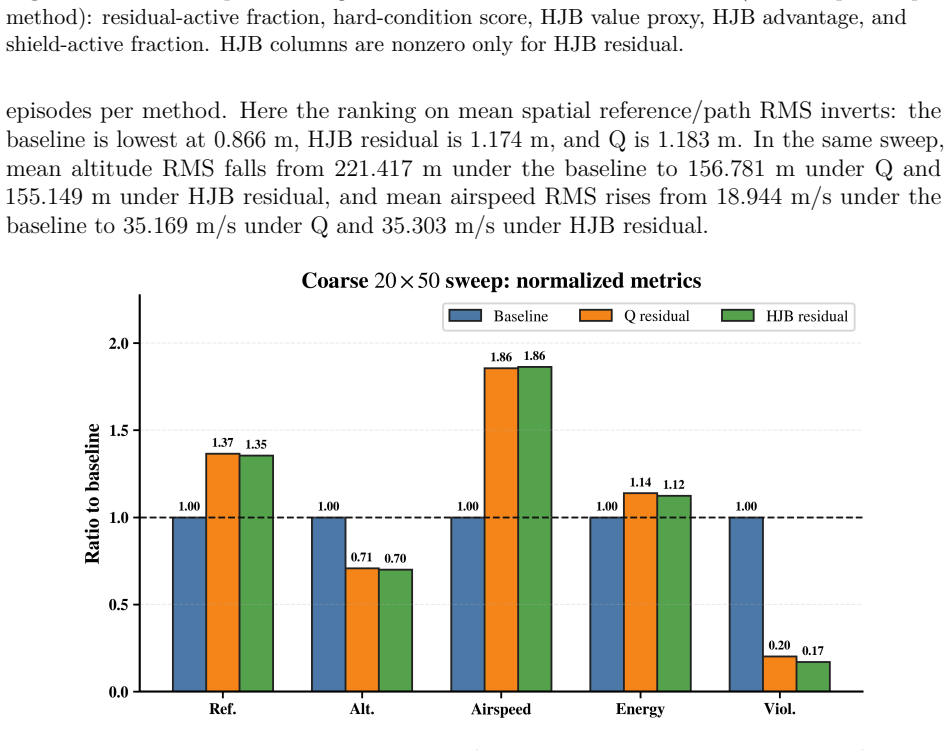
- A measurable increase in airspeed error accompanies the path improvement, so the supervisor trades one metric for another.
Where Pith is reading between the lines
- The same supervisor layer could be tested on other baseline autopilots to check whether the error reduction depends on the specific inner controller.
- Hardware trials would need to measure how sensor noise affects the value-iteration critic's ranking of residuals.
- The approach might extend to quadrotors or other vehicles where preserving an existing certified controller is required.
Load-bearing premise
The fixed simulation environment with the plant, autopilot, and actuator model held constant gives a fair comparison that will continue to hold when the same supervisor runs on physical hardware that includes unmodeled dynamics and sensor noise.
What would settle it
Running the HJB residual supervisor on physical fixed-wing UAV hardware in real wind and gust conditions and checking whether the reported reduction in mean RMS path-tracking error relative to the baseline autopilot still appears.
Figures


read the original abstract
A fixed-wing UAV must hold airspeed, altitude, and heading references under wind, gusts, and turbulence, channels coupled so that correcting one can degrade another. Classical autopilots stabilize the airframe well but adapt poorly when a hard crosswind meets an aggressive turn, while reinforcement-learning (RL) policies acting directly on the surfaces concentrate exploration risk at the actuator interface. We place a learned supervisor above an unchanged autopilot rather than inside it: it selects a residual from a finite, bounded action set on the commanded airspeed, altitude, and heading; the modified reference is projected into an admissible command envelope before reaching the autopilot, which stays the only actuator-facing controller. What is new is how the residual is chosen. HJB residual scores candidates with a semi-discrete value-iteration critic in the spirit of the Hamilton-Jacobi-Bellman (HJB) equation, ranks them by a no-op-relative Hamiltonian advantage, and filters them through a control-Lyapunov- and control-barrier-inspired finite-action shield that always keeps a no-op fallback. On a shared 12-state runtime holding the plant, autopilot, and actuator model fixed, so the comparison is at the package level, HJB residual lowers mean RMS path-tracking error to 44.809 m, against 338.617 m for the baseline autopilot and 88.809 m for a tabular-Q residual, an 86.77% reduction over the baseline and 49.54% over Q-learning. The gain concentrates where the baseline fails worst and comes with a measured rise in airspeed error, so no method dominates every metric. We present this autopilot-preserving residual command-supervision design and benchmark with its trade-offs reported intact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an autopilot-preserving residual command-supervision architecture for fixed-wing UAVs. A learned supervisor selects bounded residuals on airspeed, altitude, and heading references using an HJB-inspired semi-discrete value-iteration critic, no-op-relative Hamiltonian ranking, and a control-Lyapunov/control-barrier finite-action shield that always retains a no-op fallback. The autopilot remains the sole actuator-facing controller. On a shared 12-state simulation with fixed plant, autopilot, and actuator models, the method reports mean RMS path-tracking error of 44.809 m versus 338.617 m (baseline) and 88.809 m (tabular Q-learning), corresponding to 86.77% and 49.54% reductions, while noting a rise in airspeed error.
Significance. If the simulation results hold, the work demonstrates a practical way to layer safe residual supervision atop an existing autopilot without actuator-level exploration risk. The explicit package-level comparison on a frozen model, the preservation of a no-op fallback, and the reporting of metric trade-offs are strengths. The integration of HJB residual scoring with a finite-action shield offers a concrete instance of risk-filtered RL for coupled reference tracking.
major comments (2)
- [Abstract / Results] Abstract and results section: the headline numerical claims are reported as single mean RMS values (44.809 m, 338.617 m, 88.809 m) with derived percentages but without error bars, trial counts, standard deviations, or any variability statistics. This directly affects the reliability of the 86.77% reduction claim.
- [Simulation setup / Results] The benchmark is performed on a single fixed 12-state model shared across all methods; no Monte-Carlo parameter sweeps or sensitivity analysis over aerodynamic coefficients, sensor noise, or gust spectra are described. Because the HJB critic and Hamiltonian ranking are constructed from the identical model, this omission is load-bearing for any claim of robustness in the UAV command-supervision setting.
minor comments (1)
- [Methods] The description of the 12-state runtime and the precise construction of the admissible command envelope could be expanded for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results section: the headline numerical claims are reported as single mean RMS values (44.809 m, 338.617 m, 88.809 m) with derived percentages but without error bars, trial counts, standard deviations, or any variability statistics. This directly affects the reliability of the 86.77% reduction claim.
Authors: We agree that variability statistics are needed to support the reliability of the reported means. The presented results reflect single-run means on the fixed simulation. In the revised manuscript we will conduct multiple independent trials (with varied random seeds for wind/gust realizations), report trial counts, standard deviations, and include error bars in the results section and, space permitting, the abstract. revision: yes
-
Referee: [Simulation setup / Results] The benchmark is performed on a single fixed 12-state model shared across all methods; no Monte-Carlo parameter sweeps or sensitivity analysis over aerodynamic coefficients, sensor noise, or gust spectra are described. Because the HJB critic and Hamiltonian ranking are constructed from the identical model, this omission is load-bearing for any claim of robustness in the UAV command-supervision setting.
Authors: The fixed-model benchmark is intentional to enable a controlled, package-level comparison of the residual supervisors under identical plant, autopilot, and actuator dynamics. The manuscript does not claim robustness to parameter variations or environmental changes; improvements are reported for this specific benchmark. We will add an explicit statement of scope and a limitations paragraph noting the absence of sensitivity analysis. revision: partial
Circularity Check
No significant circularity; empirical benchmark on fixed models is self-contained
full rationale
The paper introduces a residual command-supervision architecture using a semi-discrete value-iteration critic inspired by the HJB equation, a no-op-relative Hamiltonian ranking, and a finite-action shield, then reports package-level simulation results on a shared 12-state runtime with fixed plant/autopilot/actuator models. The headline metrics (44.809 m vs 338.617 m RMS) are generated by executing the three supervisors (baseline, tabular-Q, HJB-residual) under identical dynamics; they are not obtained by fitting a parameter to a subset and relabeling it a prediction, nor by any self-definitional loop in which the output is constructed from the input by the method's own equations. No load-bearing uniqueness theorem, ansatz, or self-citation chain is invoked to force the result. The comparison is therefore an external experimental evaluation rather than a tautological reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The shared 12-state simulation with fixed plant, autopilot, and actuator model is representative of real-world closed-loop behavior
Reference graph
Works this paper leans on
-
[1]
Ames, A. D., Xu, X., Grizzle, J. W., & Tabuada, P. (2017). Control barrier function based quadratic programs for safety critical systems.IEEE Transactions on Automatic Control, 62(8), 3861–3876. https://doi.org/10.1109/TAC.2016.2638961
-
[2]
M., Guha, A., Cui, Y., Tang, S., Fisher, P
Annaswamy, A. M., Guha, A., Cui, Y., Tang, S., Fisher, P. A., & Gaudio, J. E. (2023). Integration of adaptive control and reinforcement learning for real-time control and learning.IEEE Transactions on Automatic Control, 68(12), 7740–7755.https://doi.org/10.1109/TAC.2023.3290037
-
[3]
Ayhan, B., & Kwan, C. (2018). Time-constrained extremal trajectory design for fixed-wing unmanned aerial vehicles in steady wind.Journal of Guidance, Control, and Dynamics, 41(7), 1569–1576. https://doi.org/10.2514/1.G003353
-
[4]
W., & McLain, T
Beard, R. W., & McLain, T. W. (2010).Navigation, guidance, and control of small and miniature air vehicles. Brigham Young University.https://www.et.byu.edu/~beard/classes/ece674/ uavbook.pdf
2010
-
[5]
Cheng, Y., Zhao, P., Wang, F., Block, D. J., & Hovakimyan, N. (2022). Improving the robustness of reinforcement learning policies with L1 adaptive control.IEEE Robotics and Automation Letters, 7(3), 6574–6581.https://doi.org/10.1109/LRA.2022.3169309
-
[6]
Cohen, M. H., & Belta, C. (2020). Approximate optimal control for safety-critical systems with control barrier functions. In2020 59th IEEE Conference on Decision and Control (CDC)(pp. 2062–2067). IEEE.https://doi.org/10.1109/CDC42340.2020.9303896
-
[7]
Dong, W., Farrell, J. A., Polycarpou, M. M., Djapic, V., & Sharma, M. (2012). Command filtered adaptive backstepping.IEEE Transactions on Control Systems Technology, 20(3), 566–580. https://doi.org/10.1109/TCST.2011.2121907
-
[8]
Eimer, T., Lindauer, M., & Raileanu, R. (2023). Hyperparameters in reinforcement learning and how to tune them. InProceedings of the 40th International Conference on Machine Learning(pp. 9104–9149). PMLR.https://proceedings.mlr.press/v202/eimer23a.html
2023
-
[9]
Fisac, J. F., Lugovoy, N. F., Rubies-Royo, V., Ghosh, S., & Tomlin, C. J. (2019). Bridging Hamilton-Jacobi safety analysis and reinforcement learning. In2019 International Conference on Robotics and Automation (ICRA)(pp. 8550–8556). IEEE. https://doi.org/10.1109/ICRA. 2019.8794107
-
[10]
Gurriet, T., Mote, M., Singletary, A., Nilsson, P., Feron, E., & Ames, A. D. (2020). A scalable safety critical control framework for nonlinear systems.IEEE Access, 8, 187249–187275.https: //doi.org/10.1109/ACCESS.2020.3025248
-
[11]
Jayarathne, D., Paternain, S., & Mishra, S. (2023). Safe residual reinforcement learning for helicopter aerial refueling. In2023 IEEE/ASME International Conference on Advanced Intelligent Mecha- tronics (AIM)(pp. 263–269). IEEE.https://doi.org/10.1109/AIM46323.2023.10196137
-
[12]
Johannink, T., Bahl, S., Nair, A., Luo, J., Kumar, A., Loskyll, M., Ojea, J. A., Solowjow, E., & Levine, S. (2019). Residual reinforcement learning for robot control. In2019 International Conference on Robotics and Automation (ICRA)(pp. 6023–6029). IEEE.https://doi.org/10. 1109/ICRA.2019.8794127 HJB-inspired residual UAV command supervision 42
arXiv 2019
-
[13]
Li, Z., Kalabić, U., & Chu, T. (2018). Safe reinforcement learning: Learning with supervision using a constraint-admissible set. In2018 Annual American Control Conference (ACC)(pp. 6390–6395). IEEE.https://doi.org/10.23919/ACC.2018.8430770
-
[14]
Liu, M., Egan, G. K., & Santoso, F. (2015). Modeling, autopilot design, and field tuning of a UAV with minimum control surfaces.IEEE Transactions on Control Systems Technology, 23(6), 2353–2360.https://doi.org/10.1109/TCST.2015.2398316
-
[15]
Lutter, M., Belousov, B., Listmann, K., Clever, D., & Peters, J. (2020). HJB optimal feedback control with deep differential value functions and action constraints. InProceedings of the Conference on Robot Learning(pp. 640–650). PMLR.https://proceedings.mlr.press/v100/lutter20a. html
2020
-
[16]
Meharie, H. B., & Lemma, L. N. (2024). Optimized robust fuzzy twisting sliding mode control design for fixed wing UAV.IEEE Access, 12, 170112–170134.https://doi.org/10.1109/ACCESS.2024. 3497723
-
[17]
Na, J., Yang, J., & Gao, G. (2020). Reinforcing transient response of adaptive control systems using modified command and reference model.IEEE Transactions on Aerospace and Electronic Systems, 56(3), 2005–2017.https://doi.org/10.1109/TAES.2019.2939612
-
[18]
Poksawat, P., Wang, L., & Mohamed, A. (2018). Gain scheduled attitude control of fixed-wing UAV with automatic controller tuning.IEEE Transactions on Control Systems Technology, 26(4), 1192–1203.https://doi.org/10.1109/TCST.2017.2709274 PhiniteLab. (2026).pythalab-sharq-hjb-uav-command-supervision: Open-source SHARQ-HJB command-supervision implementation,...
-
[19]
A., Ansari, S., Karar, H.-e., & Mohamed, A
Sattar, A., Wang, L., Hoshu, A. A., Ansari, S., Karar, H.-e., & Mohamed, A. (2022). Automatic tuning and turbulence mitigation for fixed-wing UAV with segmented control surfaces.Drones, 6(10), Article 302.https://doi.org/10.3390/drones6100302
-
[20]
Sun, D., Hovakimyan, N., & Jafarnejadsani, H. (2021). Design of command limiting control law using exponential potential functions.Journal of Guidance, Control, and Dynamics, 44(2), 441–448. https://doi.org/10.2514/1.G004972
-
[21]
Sun, Y., Khairy, S., Vilim, R. B., Hu, R., & Dave, A. J. (2024). A safe reinforcement learning algorithm for supervisory control of power plants.Knowledge-Based Systems, 301, Article 112312. https://doi.org/10.1016/j.knosys.2024.112312
-
[22]
Taherian, N., & Shiri, M. E. (2014). Q*-based state abstraction and knowledge discovery in reinforcement learning.Intelligent Data Analysis, 18(6), 1153–1175. https://doi.org/10.3233/ IDA-140689
2014
-
[23]
Tan, D. C. H., McCarthy, R., Acero, F., Delfaki, A. M., Li, Z., & Kanoulas, D. (2024). Safe value functions: Learned critics as hard safety constraints. In2024 IEEE 20th International Conference on Automation Science and Engineering (CASE)(pp. 2441–2448). IEEE. https: //doi.org/10.1109/CASE59546.2024.10711661 HJB-inspired residual UAV command supervision 43
-
[24]
Yang, Y., Wunsch, D. C., & Yin, Y. (2017). Hamiltonian-driven adaptive dynamic programming for continuous nonlinear dynamical systems.IEEE Transactions on Neural Networks and Learning Systems, 28(8), 1929–1940.https://doi.org/10.1109/TNNLS.2017.2654324
-
[25]
Yang, Y., Modares, H., Vamvoudakis, K.G., He, W., Xu, C.-Z., &Wunsch, D.C.(2022).Hamiltonian- driven adaptive dynamic programming with approximation errors.IEEE Transactions on Cyber- netics, 52(12), 13762–13773.https://doi.org/10.1109/TCYB.2021.3108034
-
[26]
Yang, Y., Pan, Y., Xu, C.-Z., & Wunsch, D. C., II. (2024). Hamiltonian-driven adaptive dynamic programmingwithefficientexperiencereplay.IEEE Transactions on Neural Networks and Learning Systems, 35(3), 3278–3290.https://doi.org/10.1109/TNNLS.2022.3213566
-
[27]
A., Banazadeh, A., & Castaldi, P
Zahmatkesh, M., Emami, S. A., Banazadeh, A., & Castaldi, P. (2022). Robust attitude control of an agile aircraft using improved Q-learning.Actuators, 11(12), Article 374.https://doi.org/ 10.3390/act11120374
-
[28]
Zhang, Z., He, C., Chen, H., Zhang, Y., Wang, H., Cai, Y., Chen, L., Li, H., & Lu, T. (2024). Small fixed-wing unmanned aerial vehicle path following under low altitude wind shear disturbance. IEEE Transactions on Intelligent Transportation Systems, 25(10), 13991–14003. https://doi. org/10.1109/TITS.2024.3391869
-
[29]
Zhao, L., Gatsis, K., & Papachristodoulou, A. (2023). Stable and safe reinforcement learning via a barrier-Lyapunov actor-critic approach. In2023 62nd IEEE Conference on Decision and Control (CDC)(pp. 1320–1325). IEEE.https://doi.org/10.1109/CDC49753.2023.10383742 A Metric implementation trace All metrics are computed from the same telemetry definitions f...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.