Agent Skills Should Go Beyond Text: The Case for Visual Skills
Pith reviewed 2026-06-28 17:09 UTC · model grok-4.3
The pith
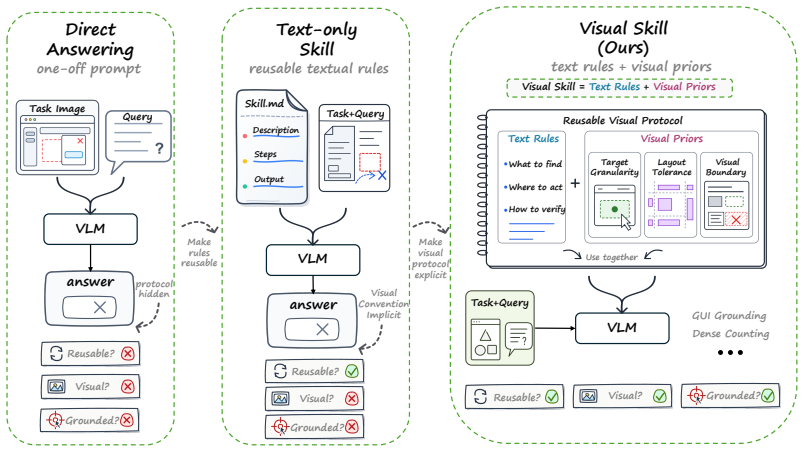
Text-only skills limit agents on visual tasks because reusable knowledge often requires spatial layout and visual grounding that text cannot reliably encode.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
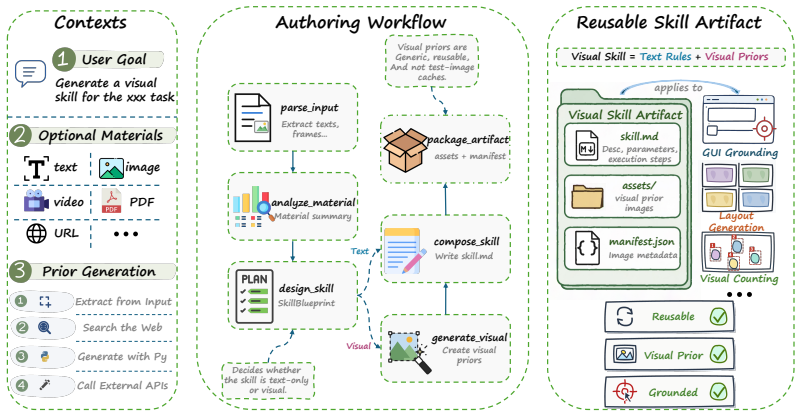
Reusable agent skills should be stored as multimodal assets rather than text alone; the three forms of visual support—static priors, dynamic priors, and interleaved visual bindings—directly encode where to look, how to inspect, and how to verify results, and an automatic trajectory-to-skill converter can extract them at scale while preserving spatial and visual detail.
What carries the argument
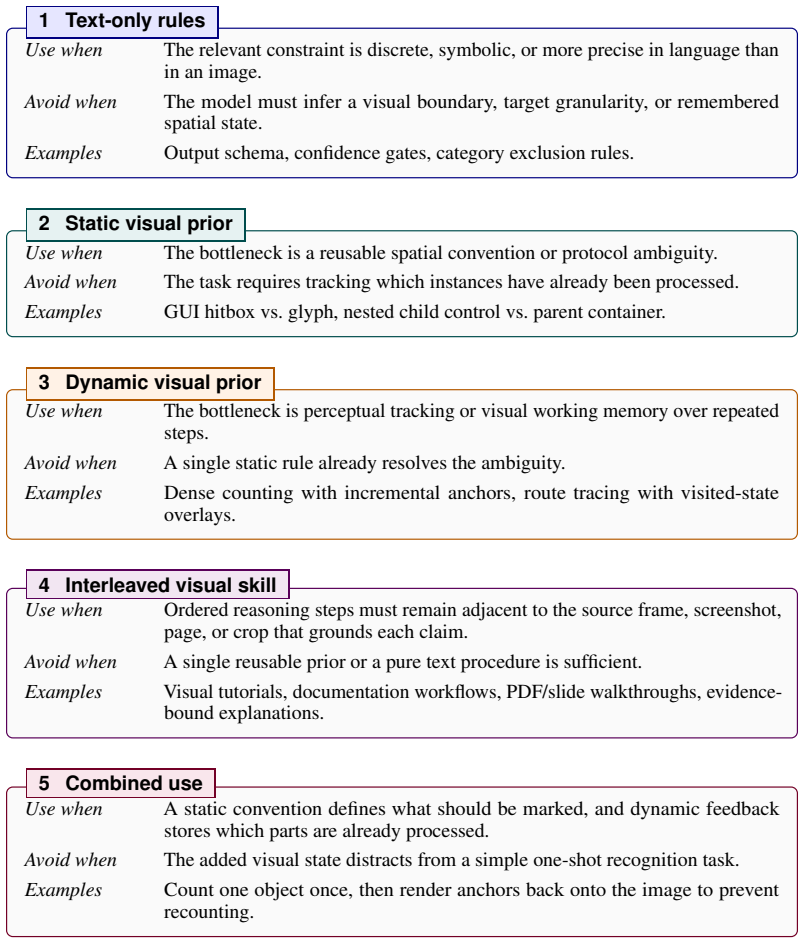
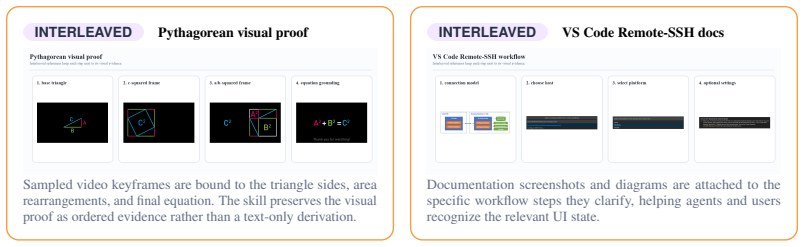
The multimodal skill paradigm that augments declarative text with explicit visual support in the form of static priors for stable spatial conventions, dynamic priors for in-situ visual working memory, and interleaved skills that bind ordered steps to source frames or regions.
If this is right
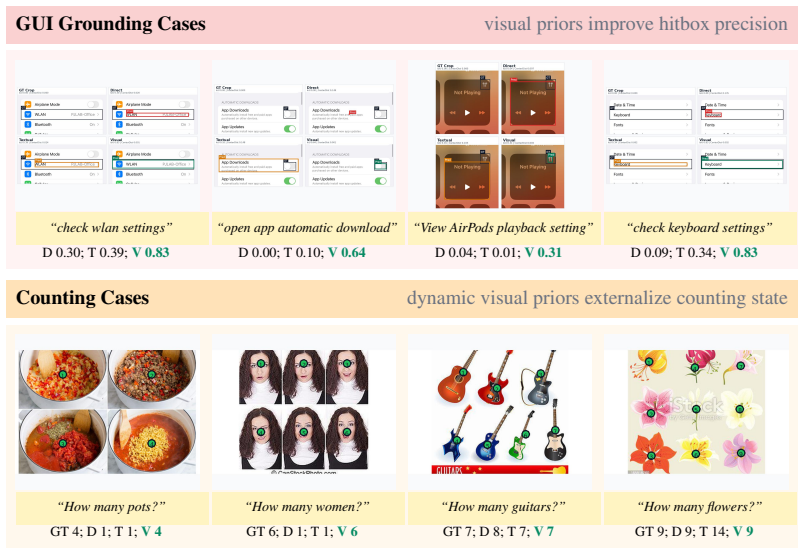
- Visual skills improve success rates on tasks that require spatial correspondence or state-aware visual verification.
- The extraction system scales creation of reusable skills by preserving textual reasoning together with the visual evidence that supports it.
- Multimodal skills encode verification steps that text descriptions alone cannot capture reliably.
- Agents accumulate experience more effectively when skills retain the original visual context rather than summaries.
Where Pith is reading between the lines
- The same extraction approach could be applied to non-GUI visual domains such as robotic manipulation where trajectory data also contains camera frames.
- Maintaining a growing library of these multimodal skills might reduce the need for agents to re-learn visual patterns across similar tasks.
- Interleaved skills could serve as a bridge between language-based planning and pixel-level control in future agent architectures.
Load-bearing premise
Visual skills can be extracted automatically from trajectories while keeping accurate spatial references and visual boundaries without introducing errors that cancel out the reported performance gains.
What would settle it
A controlled test in which the automatic extraction system produces visual skills whose error rate in spatial references or boundary detection causes lower task success than equivalent text-only skills on the same GUI benchmarks.
Figures




read the original abstract
Reusable skills are a key mechanism for extending agent capabilities, allowing agents to accumulate experience and solve increasingly complex tasks. Yet most existing skill-learning methods store reusable experience as text-only assets, such as instructions, reasoning traces, or summarized trajectories. We argue that this text-only paradigm creates a fundamental bottleneck for visual-centric tasks, where reusable knowledge often depends on spatial layout, visual grounding, fine-grained appearance, and localized state changes. To address this limitation, we propose \textbf{\NAME}, a multimodal skill paradigm that combines declarative textual logic with explicit visual support. We distinguish three reusable forms: static priors for stable spatial conventions, dynamic priors for in-situ visual working memory, and interleaved visual skills that bind ordered text steps to the source frames, screenshots, or page regions that justify them. Rather than only describing what to do, visual skills also encode where to look, how to inspect, and how to verify visual outcomes. To scale visual-skill construction, we introduce \textbf{\SYSTEM}, an automatic system that converts agent experience into reusable multimodal skills by preserving textual reasoning, spatial references, visual boundaries, and interaction patterns from task trajectories. Experiments on GUI and other visual-centric tasks show that visual skills consistently outperform text-only skills, particularly when success requires spatial correspondence, visual evidence, and state-aware interaction. These results support our central position: reusable agent skills should go beyond text and become multimodal assets for future multimodal agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that text-only reusable skills create a bottleneck for visual-centric agent tasks and proposes extbf{ ame}, a multimodal skill paradigm with three forms (static priors for stable spatial conventions, dynamic priors for in-situ visual working memory, and interleaved visual skills binding ordered text steps to source frames/screenshots/regions). It introduces extbf{ extsc{system}}, an automatic converter that extracts these from trajectories while preserving textual reasoning, spatial references, visual boundaries, and interaction patterns. Experiments on GUI and other visual-centric tasks are reported to show consistent outperformance of visual skills over text-only skills, especially when spatial correspondence, visual evidence, and state-aware interaction are required.
Significance. If the empirical results hold after addressing extraction fidelity and experimental controls, the work could meaningfully influence skill representation in multimodal agents by demonstrating that explicit visual assets improve performance on tasks where text alone is insufficient. The automatic extraction approach addresses a key scalability issue for accumulating reusable multimodal experience.
major comments (3)
- [ extsc{system} description and extraction pipeline] The central claim rests on extsc{system} producing faithful visual skills without offsetting errors in spatial references or boundaries. No quantitative evaluation of extraction fidelity (e.g., precision/recall of bounding boxes, frame selection accuracy, or state-change localization error rates) is provided in the extsc{system} section or experiments; this is load-bearing because misalignment would directly undermine the reported gains over text-only skills.
- [Experiments and evaluation] The experiments section states 'consistent outperformance' but provides no details on baselines (e.g., specific text-only skill methods), metrics, statistical tests, number of runs, or controls for post-hoc selection. Without these, it is impossible to determine whether the results support the multimodal advantage or reflect experimental artifacts.
- [Results on GUI tasks] The claim that visual skills are particularly advantageous 'when success requires spatial correspondence, visual evidence, and state-aware interaction' requires explicit supporting evidence (e.g., per-task breakdowns or ablation tables) rather than aggregate statements; the current presentation leaves the differential benefit unquantified.
minor comments (2)
- [Abstract and introduction] The manuscript uses placeholder macros extbf{ ame} and extbf{ extsc{system}}; replace with the actual names and expand the first use of each acronym.
- [Multimodal skill paradigm] Clarify whether the three reusable forms are mutually exclusive or can be combined in a single skill asset, and provide a concrete example trajectory showing all three forms.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that directly strengthen the manuscript's claims regarding extraction fidelity, experimental rigor, and differential benefits of visual skills.
read point-by-point responses
-
Referee: [system description and extraction pipeline] The central claim rests on extsc{system} producing faithful visual skills without offsetting errors in spatial references or boundaries. No quantitative evaluation of extraction fidelity (e.g., precision/recall of bounding boxes, frame selection accuracy, or state-change localization error rates) is provided in the extsc{system} section or experiments; this is load-bearing because misalignment would directly undermine the reported gains over text-only skills.
Authors: We agree that the absence of quantitative fidelity metrics for the extraction pipeline is a limitation that weakens the central claim. In the revised manuscript we will add a dedicated evaluation subsection (and associated table) reporting precision/recall for bounding-box extraction, frame-selection accuracy, and state-change localization error on a manually annotated subset of trajectories. These metrics will be computed against human-verified ground truth and will be used to bound the potential impact of misalignment on the reported performance gains. revision: yes
-
Referee: [Experiments and evaluation] The experiments section states 'consistent outperformance' but provides no details on baselines (e.g., specific text-only skill methods), metrics, statistical tests, number of runs, or controls for post-hoc selection. Without these, it is impossible to determine whether the results support the multimodal advantage or reflect experimental artifacts.
Authors: We acknowledge that the current experimental description lacks the necessary methodological detail. The revised Experiments section will explicitly list the text-only baselines (including ReAct-style and Reflexion-style skill variants), the primary metric (task success rate), the number of independent runs (five random seeds), the statistical tests performed (paired t-tests with reported p-values), and the procedure used to avoid post-hoc selection bias. Variance across runs will also be reported. revision: yes
-
Referee: [Results on GUI tasks] The claim that visual skills are particularly advantageous 'when success requires spatial correspondence, visual evidence, and state-aware interaction' requires explicit supporting evidence (e.g., per-task breakdowns or ablation tables) rather than aggregate statements; the current presentation leaves the differential benefit unquantified.
Authors: We agree that aggregate statements alone are insufficient to substantiate the differential advantage. The revised results section will include per-task breakdown tables (and an accompanying ablation) that separate tasks according to whether they require spatial correspondence, visual evidence, or state-aware interaction. These tables will report success-rate deltas between visual and text-only skills for each category, thereby quantifying the claimed benefit. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is a conceptual proposal introducing multimodal visual skills (static priors, dynamic priors, interleaved forms) and an automatic extraction system SYSTEM, supported by empirical results on GUI tasks. No mathematical derivations, equations, fitted parameters, predictions, or self-citations appear in the provided text that reduce any claim to its inputs by construction. The central position is advanced as an argument plus experiments rather than a closed definitional or self-referential loop, making the derivation chain self-contained.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Multimodal skill paradigm with three reusable forms
no independent evidence
-
SYSTEM automatic conversion system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DeFT: A conceptual framework for considering learning with multiple representations
Shaaron Ainsworth. DeFT: A conceptual framework for considering learning with multiple representations. Learning and Instruction, 16(3):183–198, 2006. doi: 10.1016/j.learninstruc.2006.03.001
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. doi: 10.48550/arXiv. 2309.16609. URLhttps://arxiv.org/abs/2309.16609
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL technical report, 2025. URL https://arxiv.org/ abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. PaliGemma: A versatile 3b VLM for transfer.arXiv preprint arXiv:2407.07726, 2024. doi: 10.48550/arXiv.2407.07726. URLhttps://arxiv.org/abs/2407.07726. 11
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.07726 2024
-
[5]
Cognitive load theory and the format of instruction.Cognition and Instruction, 8(4):293–332, 1991
Paul Chandler and John Sweller. Cognitive load theory and the format of instruction.Cognition and Instruction, 8(4):293–332, 1991. doi: 10.1207/s1532690xci0804_2
-
[6]
SeeClick: Harnessing GUI grounding for advanced visual GUI agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, YanTao Li, Jianbing Zhang, and Zhiyong Wu. SeeClick: Harnessing GUI grounding for advanced visual GUI agents. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9313–9332, Bangkok,...
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URL https: //arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024. doi: 10.48550/arXiv.2412.19437. URL https://arxiv.org/abs/2412. 19437
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.19437 2024
-
[9]
Mind2Web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a generalist agent for the web. InAdvances in Neural Information Processing Systems, volume 36, pages 28091–28114, 2023. URL https://proceedings.neurips.cc/paper_files/ paper/2023/file/5950bf290a1570ea401bf98882128160-Paper-Datasets_and_Benchmarks. pdf
2023
-
[10]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, Katie Millican, et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. doi: 10.48550/arXiv.2312.11805. URL https://arxiv.org/abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.11805 2023
-
[11]
Zhangxuan Gu, Zhengwen Zeng, Zhenyu Xu, Xingran Zhou, Shuheng Shen, Yunfei Liu, Beitong Zhou, Changhua Meng, Tianyu Xia, Weizhi Chen, et al. UI-Venus technical report: Building high-performance UI agents with RFT.arXiv preprint arXiv:2508.10833, 2025. doi: 10.48550/arXiv.2508.10833. URL https://arxiv.org/abs/2508.10833
-
[12]
Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reasoning without training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14953–14962, June 2023. doi: 10.1109/CVPR52729.2023.01436. URL https://openaccess.thecvf.com/content/CVPR2023/html/Gupta_Visual_Programming_ Compositional_Vis...
-
[13]
SugarCrepe: Fixing hackable benchmarks for vision-language compositionality.Advances in Neural Information Processing Systems, 36:31096–31116, 2023
Cheng-Yu Hsieh, Jieyu Zhang, Zixian Ma, Aniruddha Kembhavi, and Ranjay Krishna. SugarCrepe: Fixing hackable benchmarks for vision-language compositionality.Advances in Neural Information Processing Systems, 36:31096–31116, 2023
2023
-
[14]
Hsiao Yuan Hsu, Xiangteng He, Yuxin Peng, Hao Kong, and Qing Zhang. PosterLay- out: A new benchmark and approach for content-aware visual-textual presentation layout. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, pages 6018–6026, June 2023. doi: 10.1109/CVPR52729.2023.00583. URL https: //openaccess.thecvf.com/conte...
-
[15]
Promptcap: Prompt- guided image captioning for vqa with gpt-3
Yushi Hu, Hang Hua, Zhengyuan Yang, Weijia Shi, Noah A Smith, and Jiebo Luo. Promptcap: Prompt- guided image captioning for vqa with gpt-3. InProceedings of the IEEE/CVF international conference on computer vision, pages 2963–2975, 2023
2023
-
[16]
FineMatch: Aspect-based fine-grained image and text mismatch detection and correction
Hang Hua, Jing Shi, Kushal Kafle, Simon Jenni, Daoan Zhang, John Collomosse, Scott Cohen, and Jiebo Luo. FineMatch: Aspect-based fine-grained image and text mismatch detection and correction. In European Conference on Computer Vision, pages 474–491. Springer, 2024
2024
-
[17]
Hang Hua, Yunlong Tang, Ziyun Zeng, Liangliang Cao, Zhengyuan Yang, Hangfeng He, Chenliang Xu, and Jiebo Luo. MMCOMPOSITION: Revisiting the compositionality of pre-trained vision-language models.arXiv preprint arXiv:2410.09733, 2024. doi: 10.48550/arXiv.2410.09733. URL https://arxiv. org/abs/2410.09733. 12
-
[18]
V2Xum-LLM: Cross-modal video summarization with temporal prompt instruction tuning
Hang Hua, Yolo Yunlong Tang, Chenliang Xu, and Jiebo Luo. V2Xum-LLM: Cross-modal video summarization with temporal prompt instruction tuning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 3599–3607, 2025. doi: 10.1609/aaai.v39i4.32374. URL https://arxiv.org/abs/2404.12353
-
[19]
Aliaga, Wei Xiong, and Jiebo Luo
Hang Hua, Ziyun Zeng, Yizhi Song, Yunlong Tang, Liu He, Daniel G. Aliaga, Wei Xiong, and Jiebo Luo. MMIG-Bench: Towards comprehensive and explainable evaluation of multi-modal image generation models.arXiv preprint arXiv:2505.19415, 2025. doi: 10.48550/arXiv.2505.19415. URL https://arxiv. org/abs/2505.19415
-
[20]
Yue Huang, Hang Hua, Yujun Zhou, Pengcheng Jing, Manish Nagireddy, Inkit Padhi, Greta Dolcetti, Zhangchen Xu, Subhajit Chaudhury, Ambrish Rawat, et al. Building a foundational guardrail for general agentic systems via synthetic data.arXiv preprint arXiv:2510.09781, 2025
-
[21]
LangChain. Agents. https://docs.langchain.com/oss/python/langchain/agents, 2026. URL https://docs.langchain.com/oss/python/langchain/agents. Documentation; accessed 2026- 05-03
2026
-
[22]
Jill H. Larkin and Herbert A. Simon. Why a diagram is (sometimes) worth ten thousand words.Cognitive Science, 11(1):65–100, 1987. doi: 10.1111/j.1551-6708.1987.tb00863.x. URL https://doi.org/10. 1111/j.1551-6708.1987.tb00863.x
-
[23]
Hugo Laurençon, Léo Tronchon, and Victor Sanh. Unlocking the conversion of web screenshots into HTML code with the WebSight dataset, 2024. URLhttps://arxiv.org/abs/2403.09029
-
[24]
JobBench: Aligning Agent Work With Human Will
Yuetai Li, Yichen Feng, Zhangchen Xu, Zixian Ma, Kaiyuan Zheng, Fengqing Jiang, Xinghua Sun, Rulin Shao, Zichen Chen, Yue Huang, et al. Jobbench: Aligning agent work with human will.arXiv preprint arXiv:2605.26329, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Richard E. Mayer and Roxana Moreno. Nine ways to reduce cognitive load in multimedia learning. Educational Psychologist, 38(1):43–52, 2003. doi: 10.1207/S15326985EP3801_6
-
[26]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023. doi: 10.48550/arXiv.2303.08774. URL https://arxiv. org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[27]
Teaching CLIP to count to ten.arXiv preprint arXiv:2302.12066, 2023
Roni Paiss, Ariel Ephrat, Omer Tov, Shiran Zada, Inbar Mosseri, Michal Irani, and Tali Dekel. Teaching CLIP to count to ten.arXiv preprint arXiv:2302.12066, 2023. doi: 10.48550/arXiv.2302.12066. URL https://arxiv.org/abs/2302.12066
-
[28]
Number 9 in Oxford Psychology Series
Allan Paivio.Mental Representations: A Dual Coding Approach. Number 9 in Oxford Psychology Series. Oxford University Press, New York, 1986. ISBN 0-19-503936-X. URL https://academic.oup.com/ book/10932
1986
-
[29]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems, volume 36, pages 68539–68551, 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/ha...
2023
-
[30]
Claude E. Shannon. Coding theorems for a discrete source with a fidelity criterion. InIRE National Convention Record, Part 4, pages 142–163, 1959
1959
-
[31]
Design2Code: Benchmarking multimodal code generation for automated front-end engineering
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2Code: Benchmarking multimodal code generation for automated front-end engineering. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3956...
-
[32]
Latent chain-of-thought for visual reasoning.Advances in neural information processing systems, 38:103739–103762, 2026
Guohao Sun, Hang Hua, Jian Wang, Jiebo Luo, Sohail Dianat, Majid Rabbani, Raghuveer Rao, and Zhiqiang Tao. Latent chain-of-thought for visual reasoning.Advances in neural information processing systems, 38:103739–103762, 2026
2026
-
[33]
Cognitive load during problem solving: Effects on learning.Cognitive Science, 12(2): 257–285, 1988
John Sweller. Cognitive load during problem solving: Effects on learning.Cognitive Science, 12(2): 257–285, 1988. doi: 10.1207/s15516709cog1202_4. 13
-
[34]
John Sweller, Jeroen J. G. van Merrienboer, and Fred G. W. C. Paas. Cognitive architecture and instructional design.Educational Psychology Review, 10(3):251–296, 1998. doi: 10.1023/A:1022193728205
-
[35]
Winoground: Probing vision and language models for visio-linguistic compositionality
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5238–5248, 2022
2022
-
[36]
The information bottleneck method
Naftali Tishby, Fernando C. Pereira, and William Bialek. The information bottleneck method. In Proceedings of the 37th Annual Allerton Conference on Communication, Control, and Computing, pages 368–377, Monticello, IL, USA, 1999. URLhttps://arxiv.org/abs/physics/0004057
work page internal anchor Pith review Pith/arXiv arXiv 1999
-
[37]
Iris Vessey. Cognitive fit: A theory-based analysis of the graphs versus tables literature.Decision Sciences, 22(2):219–240, 1991. doi: 10.1111/j.1540-5915.1991.tb00344.x. URL https://doi.org/10.1111/j. 1540-5915.1991.tb00344.x
-
[38]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversations. InProceedings of the First Conference on Language Modeling, 2024. URL https://openreview.net/...
2024
-
[39]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, and Yu Qiao. OS-ATLAS: A foundation action model for generalist GUI agents.arXiv preprint arXiv:2410.23218, 2024. doi: 10.48550/arXiv.2410.23218. URL https: //arxiv.org/abs/2410.23218
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.23218 2024
-
[40]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. Re- Act: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023. doi: 10.48550/arXiv.2210.03629. URL https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03629 2023
-
[41]
Mobile-Agent-v3: Fundamental Agents for GUI Automation
Jiabo Ye, Xi Zhang, Haiyang Xu, Haowei Liu, Junyang Wang, Zhaoqing Zhu, Ziwei Zheng, Feiyu Gao, Junjie Cao, Zhengxi Lu, et al. Mobile-agent-v3: Fundamental agents for GUI automation.arXiv preprint arXiv:2508.15144, 2025. doi: 10.48550/arXiv.2508.15144. URL https://arxiv.org/abs/2508. 15144
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.15144 2025
-
[42]
Aurora: Unified Video Editing with a Tool-Using Agent
Yongsheng Yu, Ziyun Zeng, Zhiyuan Xiao, Zhenghong Zhou, Hang Hua, Wei Xiong, and Jiebo Luo. Aurora: Unified video editing with a tool-using agent.arXiv preprint arXiv:2605.18748, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
MIRA: Multimodal iterative reasoning agent for image editing
Ziyun Zeng, Hang Hua, and Jiebo Luo. MIRA: Multimodal iterative reasoning agent for image editing. arXiv preprint arXiv:2511.21087, 2025. doi: 10.48550/arXiv.2511.21087. URL https://arxiv.org/ abs/2511.21087
-
[44]
MementoGUI: Learning Agentic Multimodal Memory Control for Long-Horizon GUI Agents
Ziyun Zeng, Hang Hua, Bocheng Zou, Mu Cai, Rogerio Feris, and Jiebo Luo. Mementogui: Learning agentic multimodal memory control for long-horizon gui agents.arXiv preprint arXiv:2605.18652, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
AppAgent: Multimodal Agents as Smartphone Users
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. Ap- pAgent: Multimodal agents as smartphone users, 2023. URLhttps://arxiv.org/abs/2312.13771
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
AgentStudio: A toolkit for building general virtual agents, 2024
Longtao Zheng, Zhiyuan Huang, Zhenghai Xue, Xinrun Wang, Bo An, and Shuicheng Yan. AgentStudio: A toolkit for building general virtual agents, 2024. URL https://arxiv.org/abs/2403.17918. ICLR 2025
-
[47]
Hanzhang Zhou, Xu Zhang, Panrong Tong, Jianan Zhang, Liangyu Chen, Quyu Kong, Chenglin Cai, Chen Liu, Yue Wang, Jingren Zhou, and Steven Hoi. MAI-UI technical report: Real-world centric foundation GUI agents.arXiv preprint arXiv:2512.22047, 2025. doi: 10.48550/arXiv.2512.22047. URL https://arxiv.org/abs/2512.22047
-
[48]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations, 2024. doi: 10. 48550/arXiv.2307.13854. URL https://proceedings.iclr.cc/pa...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
If nested in a row/card, choose the smallest child action, not the parent con- tainer
-
[50]
20 Table 4:Dynamic Visual Skill for CountBenchQA.The visual skill converts counting into point- anchored enumeration
Return the hitbox center and a tight bbox_2d in the task screenshot coordi- nate space. 20 Table 4:Dynamic Visual Skill for CountBenchQA.The visual skill converts counting into point- anchored enumeration. ♂¶ap-¶arker-altPoint-Anchored Enumeration for Visual Counting Description Count dense or ambiguous objects by producing one spatial anchor per valid ta...
-
[51]
Ignore legends, labels, embedded media, reflections, fragments, and sub-parts unless explicitly requested
-
[52]
Scan exhaustively; low-contrast or partially occluded valid instances still receive anchors
-
[53]
Dynamic Prior The prior is not a fixed image template
Report points_2d and total_count; the count is the length of the an- chored instance list. Dynamic Prior The prior is not a fixed image template. It is generatedduring inferenceby overlaying numberedgreen anchorson the task image. This makes the model’s counting process visual, auditable, and reusable across object categories. 21 1 Text-only rules Use whe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.