Computation-Aware Kalman Filtering with Model Selection for Neural Dynamics
Pith reviewed 2026-06-28 15:55 UTC · model grok-4.3
The pith
A new computation-aware state-space model performs model selection during Kalman filtering for neural dynamics in large state spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
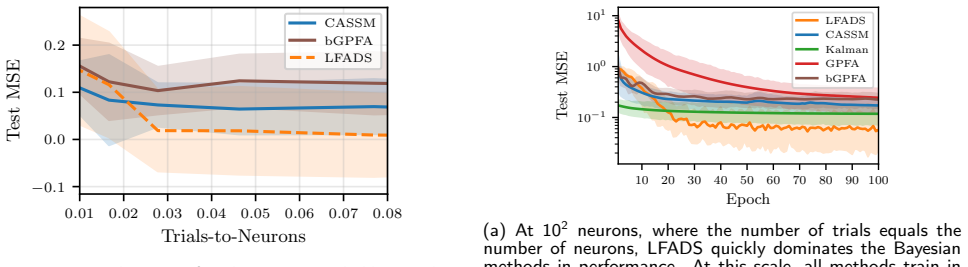
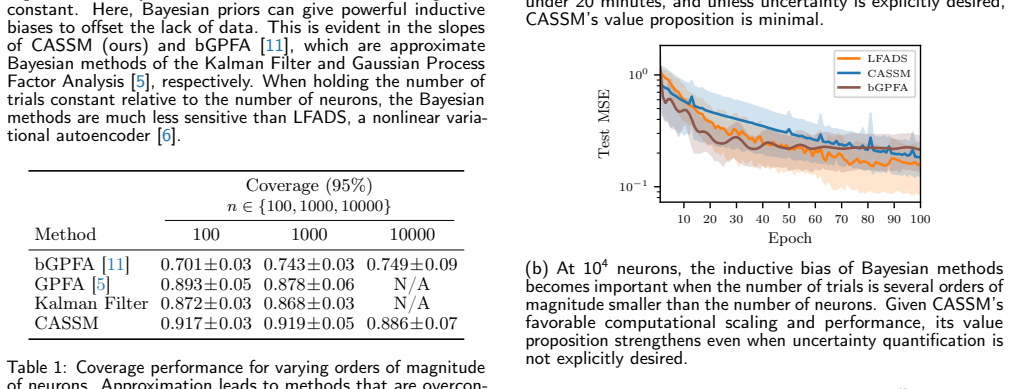
The Computation-Aware State-Space Model (CASSM) incorporates model selection into computation-aware Kalman filtering through a novel training loss and optimization scheme, yielding tractable inference in large state-spaces for scale-imbalanced neural data; in this regime the approach is competitive with deep networks yet shows significantly improved uncertainty calibration over earlier scaled Bayesian methods.
What carries the argument
The Computation-Aware State-Space Model (CASSM), which augments computation-aware Kalman filtering with an integrated model-selection loss and optimizer to remain tractable at scale.
If this is right
- Bayesian latent-variable models become practical choices for neural dynamics even when the number of trials is far smaller than the number of neurons.
- Model selection occurs automatically during filtering rather than through separate hyperparameter search.
- Uncertainty estimates remain better calibrated than those from earlier attempts to scale Bayesian methods to the same regime.
- Researchers obtain explicit guidance on selecting among dynamical models according to the trial-to-neuron ratio and related dataset properties.
Where Pith is reading between the lines
- The same computation-aware loss construction may transfer to other high-dimensional time-series domains where posterior approximations must stay cheap.
- The reported roadmap for model choice could be tested as a general decision procedure when deciding between Bayesian and deep-network approaches on scientific datasets of varying scale.
- Further experiments could check whether the calibration advantage persists when the method is applied to multi-region or multi-subject recordings.
Load-bearing premise
The novel training loss and optimization scheme can fold model selection into computation-aware filtering without restoring quadratic complexity or demanding fixed hyperparameters.
What would settle it
A head-to-head evaluation on held-out single-cell neural recordings that measures whether predictive accuracy matches deep networks while uncertainty calibration metrics (such as expected calibration error) improve over prior computation-aware Bayesian baselines.
Figures
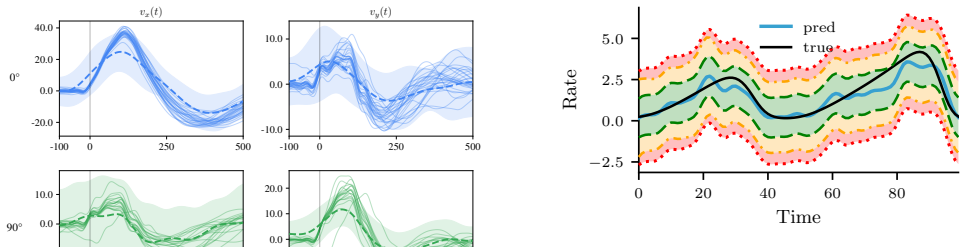
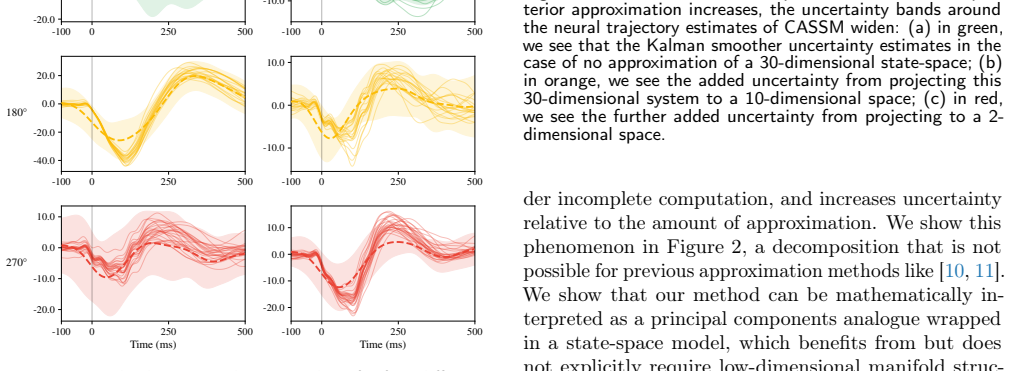
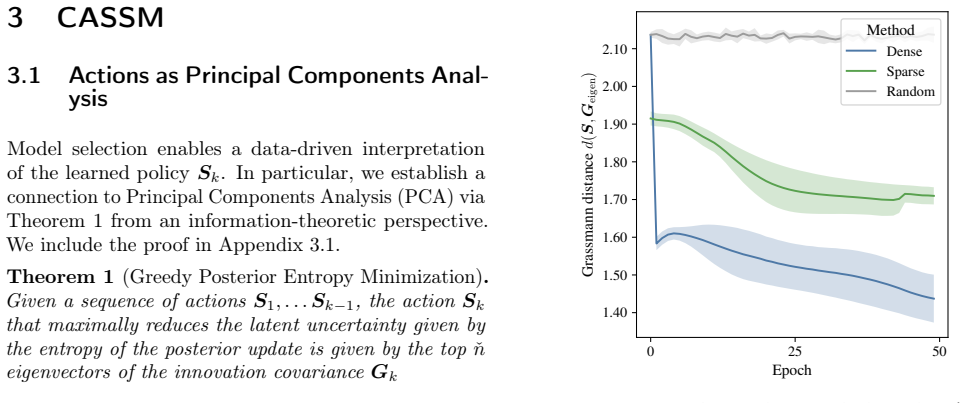
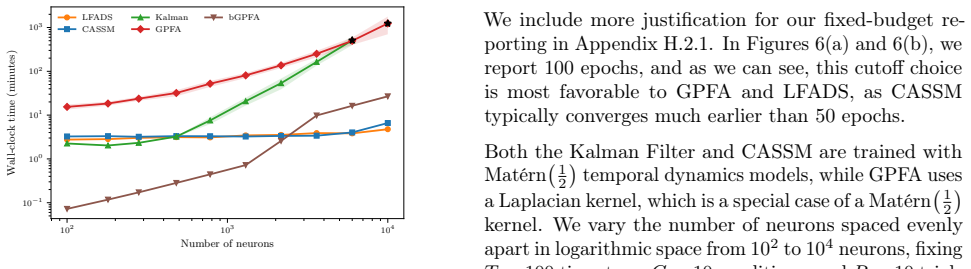
read the original abstract
Due to their explicit priors and ability to model uncertainty, Bayesian methods have played a major role in dynamical latent variable modeling of single-cell neural recordings. However, modern-sized datasets have made overparameterized deep networks the preferred methods of choice due to their predictive power and favorable computational scaling. While many posterior approximations exist, all incur approximation errors. Recent work accounts for this error in the form of computational uncertainty but comes at the cost of quadratic complexity and assumes fixed model hyperparameters. Here we extend this development to model selection, including a novel training loss and optimization scheme, which yields tractable inference in large state-spaces. We introduce a framework, the Computation-Aware State-Space Model (CASSM), specifically designed for the scale-imbalanced regime, where the number of trials is significantly lower than the number of recorded neurons. In this regime, for both synthetic and real data, we show that our method is competitive with data-hungry deep networks, with significantly improved uncertainty calibration over previous attempts to scale Bayesian methods. Our experiments provide a roadmap to neuroscience researchers in choosing from a host of potential dynamical latent variable models given key dataset properties and constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Computation-Aware State-Space Model (CASSM), extending prior computation-aware Kalman filtering to incorporate model selection via a novel training loss and optimization scheme. This is claimed to yield tractable inference in large state-spaces for the scale-imbalanced regime (trials << neurons) in neural dynamics modeling. On synthetic and real data, the method is asserted to be competitive with deep networks while providing significantly improved uncertainty calibration over previous Bayesian scaling attempts.
Significance. If the tractability and empirical results hold, this would provide a valuable Bayesian alternative for neural latent variable modeling that scales computationally while retaining explicit uncertainty quantification, bridging gaps between traditional Bayesian methods and deep networks in neuroscience applications.
major comments (1)
- [Abstract] Abstract and Introduction: the central claim that the novel training loss and optimization scheme incorporates model selection while remaining tractable (linear in state dimension) is load-bearing but unsupported by any complexity analysis, equation, or pseudocode showing that quadratic terms from prior methods are avoided; without this, the extension to the scale-imbalanced regime cannot be evaluated.
minor comments (1)
- [Abstract] Abstract: the assertions of competitiveness and improved calibration would be strengthened by inclusion of key quantitative metrics, baselines, and error bars.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for highlighting this important point about supporting the tractability claim. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and Introduction: the central claim that the novel training loss and optimization scheme incorporates model selection while remaining tractable (linear in state dimension) is load-bearing but unsupported by any complexity analysis, equation, or pseudocode showing that quadratic terms from prior methods are avoided; without this, the extension to the scale-imbalanced regime cannot be evaluated.
Authors: We agree that the abstract and introduction would be strengthened by explicit support for the tractability claim. The full manuscript contains the relevant derivations in Section 3.3 and Algorithm 1, but these are not summarized in the abstract or introduction. In the revised version we will add a short paragraph (with one equation and a reference to the algorithm) in the introduction that states the per-iteration complexity is O(N D) rather than O(N D^2), shows the key cancellation that removes the quadratic term from the earlier computation-aware filter, and notes that model selection is performed via a single forward pass over the same linear-time quantities. This addition will make the extension to the scale-imbalanced regime immediately evaluable from the front matter. revision: yes
Circularity Check
No circularity: derivation chain not visible and no self-referential reductions in provided text
full rationale
The abstract and excerpt describe an extension of prior computation-aware filtering to model selection via a novel loss and optimizer, claiming tractability in large state spaces. No equations, fitting procedures, or derivation steps are shown that reduce a claimed prediction or result to its own inputs by construction. No self-citations are quoted as load-bearing for uniqueness or ansatz. The central claim of improved calibration and competitiveness remains independent of any visible circular step; external benchmarks (synthetic/real data experiments) are referenced but not shown to be tautological. This is the expected non-finding when no load-bearing reduction can be exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural manifolds for the control of movement.Neuron, 94(5):978–984, 2017
Juan A Gallego, Matthew G Perich, Lee E Miller, and Sara A Solla. Neural manifolds for the control of movement.Neuron, 94(5):978–984, 2017
2017
-
[2]
Siegle, Xiaoxuan Jia, and Severine Durand
J.H. Siegle, Xiaoxuan Jia, and Severine Durand. Survey of spiking in the mouse visual system reveals functional hierarchy.Nature, 2021
2021
-
[3]
Distributed coding of choice, action, and engagement across the mouse brain.Nature, 2019
Nicholas Steinmetz, Peter Zatka-Haas, Matteo Carandini, and Kenneth Harris. Distributed coding of choice, action, and engagement across the mouse brain.Nature, 2019
2019
-
[4]
Raj Magesh Gauthaman, Brice Ménard, and Michael F. Bonner. Universal scale-free repre- sentations in human visual cortex.PLOS Com- putational Biology, 21(11):e1013714, 2025. doi: 10.1371/journal.pcbi.1013714. URL https://doi. org/10.1371/journal.pcbi.1013714
-
[5]
Gaussian-process factor analysis for low-dimensional single- trial analysis of neural population activ- ity
Byron M Yu, John P Cunningham, Gopal San- thanam, Stephen Ryu, Krishna V Shenoy, and Maneesh Sahani. Gaussian-process factor analysis for low-dimensional single- trial analysis of neural population activ- ity. 21, 2008. URL https://proceedings. neurips.cc/paper_files/paper/2008/file/ ad972f10e0800b49d76fed33a21f6698-Paper. pdf
2008
-
[6]
O’Shea, Jasmine Collins, Rafal Jozefowicz, Sergey D
Chethan Pandarinath, Daniel J. O’Shea, Jasmine Collins, Rafal Jozefowicz, Sergey D. Stavisky, Jonathan C. Kao, Eric M. Trautmann, Matthew T. Kaufman, Stephen I. Ryu, Leigh R. Hochberg, Jaimie M. Henderson, Krishna V. Shenoy, L. F. Abbott, and David Sussillo. Inferring single-trial neural population dynamics using sequential auto- encoders.Nature Methods, ...
-
[7]
Feng Zhu, Andrew R. Sedler, Harrison A. Grier, Nauman Ahad, Mark A. Davenport, Matthew T. Kaufman, Andrea Giovannucci, and Chethan Pan- darinath. Deep inference of latent dynamics with spatio-temporal super-resolution using selective backpropagation through time. 2021. URLhttps: //arxiv.org/abs/2111.00070
-
[8]
Brianna M. Karpowicz, Yahia H. Ali, Lahiru N. Wimalasena, Andrew R. Sedler, Mohammad Reza Keshtkaran, Kevin Bodkin, Xuan Ma, Lee E. Miller, and Chethan Pandarinath. Stabilizing brain- computer interfaces through alignment of latent dynamics.bioRxiv, 2022. doi: 10.1101/2022.04.06. 487388
-
[9]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hen- dricks, Johannes Welbl, Aidan Clark, Tom Henni- gan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent S...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Temporal align- ment and latent gaussian process factor inference in population spike trains.Advances in Neural In- formation Processing Systems (NeurIPS), 31, 2018
Lea Duncker and Maneesh Sahani. Temporal align- ment and latent gaussian process factor inference in population spike trains.Advances in Neural In- formation Processing Systems (NeurIPS), 31, 2018
2018
-
[11]
Jensen, Ta-Chu Kao, Jasmine T
Kristopher T. Jensen, Ta-Chu Kao, Jasmine T. Stone, and Guillaume Hennequin. Scalable Bayesian GPFA with automatic relevance de- termination and discrete noise models.bioRxiv,
-
[12]
URL https://www.biorxiv.org/content/early/ 2021/06/03/2021.06.03.446788
doi: 10.1101/2021.06.03.446788. URL https://www.biorxiv.org/content/early/ 2021/06/03/2021.06.03.446788
-
[13]
Batched Large-scale Bayesian Optimization in High-dimensional Spaces
Zi Wang, Clement Gehring, Pushmeet Kohli, and Stefanie Jegelka. Batched large-scale bayesian op- timization in high-dimensional spaces. 2018. URL https://arxiv.org/abs/1706.01445
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Cunningham
Jonathan Wenger, Geoff Pleiss, Marvin Pförtner, Philipp Hennig, and John P. Cunningham. Pos- terior and computational uncertainty in Gaussian processes. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2022
2022
-
[16]
Gardner, Geoff Pleiss, and John P
Jonathan Wenger, Kaiwen Wu, Philipp Hennig, Jacob R. Gardner, Geoff Pleiss, and John P. Cun- ningham. Computation-aware gaussian processes: Model selection and linear-time inference. 2024
2024
-
[17]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-Time Se- quence Modeling with Selective State Spaces, 2023. URLhttp://arxiv.org/abs/2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Cambridge Uni- versity Press, 2nd edition, 2023
Simo Särkkä and Lennart Svensson.Bayesian Fil- tering and Smoothing, volume 17. Cambridge Uni- versity Press, 2nd edition, 2023. ISBN 978-1-108- 91230-3
2023
-
[19]
Pnevmatikakis, Kamiar Rahnama Rad, Justin Huggins, and Liam Paninski
Eftychios A. Pnevmatikakis, Kamiar Rahnama Rad, Justin Huggins, and Liam Paninski. Fast kalman filtering and forward–backward smoothing via a low-rank perturbative approach.Journal of Com- putational and Graphical Statistics, 22(3):671–690,
-
[20]
doi: 10.1080/10618600.2012.760461
-
[21]
Fast kalman filtering on quasi- linear dendritic trees.Journal of Computational Neuroscience, 28(2):211–228, 2010
Liam Paninski. Fast kalman filtering on quasi- linear dendritic trees.Journal of Computational Neuroscience, 28(2):211–228, 2010. doi: 10.1007/ s10827-009-0200-4
2010
-
[22]
The geometry of low-rank kalman filters.arXiv preprint,
Silvère Bonnabel and Rodolphe Sepulchre. The geometry of low-rank kalman filters.arXiv preprint,
-
[23]
The geometry of low-rank Kalman filters
URL https://arxiv.org/abs/1203.4049. Revised version: 2013. 9
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[24]
Metamorphictestingoflarge languagemodelsfornaturallanguageprocessing.doi:10.48550/arXiv
Daniel Y. Fu, Tri Dao, Khaled K. Saab, Armin W. Thomas, Atri Rudra, and Christopher Ré. Hun- gry hungry hippos: Towards language model- ing with state space models.arXiv preprint arXiv:2212.14052, 2022. doi: 10.48550/arXiv. 2212.14052. URL https://arxiv.org/abs/2212. 14052. ICLR 2023
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[25]
Kalman filtering and smoothing so- lutions to temporal gaussian process regression models
Simo Sarkka. Kalman filtering and smoothing so- lutions to temporal gaussian process regression models. 2010. URL https://users.aalto.fi/ ~ssarkka/pub/gp-ts-kfrts.pdf
2010
-
[26]
Wei Wang, Zheng Dang, Yinlin Hu, Pascal Fua, and Mathieu Salzmann. Robust differentiable svd. arXiv preprint arXiv:2104.03821, 2021. doi: 10. 1109/TPAMI.2021.3072422
-
[27]
Differentiable svd based on moore-penrose pseudoinverse for inverse imaging problems
Yinghao Zhang and Yue Hu. Differentiable svd based on moore-penrose pseudoinverse for inverse imaging problems. 2024
2024
-
[28]
YuanZhaoandIlMemmingPark. Variationallatent gaussian process for recovering single-trial dynamics from population spike trains.Neural Computation, 29(5):1293–1316, may 2017. doi: 10.1162/neco_a_ 00953
-
[29]
Felix Pei, Joel Ye, David M. Zoltowski, Anqi Wu, Raeed H. Chowdhury, Hansem Sohn, Joseph E. O’Doherty, Krishna V. Shenoy, Matthew T. Kauf- man, Mark Churchland, Mehrdad Jazayeri, Lee E. Miller, Jonathan Pillow, Il Memming Park, Eva L. Dyer, and Chethan Pandarinath. Neural latents benchmark ’21: Evaluating latent variable mod- els of neural population acti...
-
[30]
Macke, Lars Büsing, John P
Jakob H. Macke, Lars Büsing, John P. Cun- ningham, Byron M. Yu, Krishna V. Shenoy, and Maneesh Sahani. Empirical models of spiking in neural populations. InAdvances in Neural Information Processing Systems 24 (NIPS 2011), pages 1350–1358, 2011. URL https://papers.nips.cc/paper/2011/file/ 7143d7fbadfa4693b9eec507d9d37443-Paper. pdf
2011
-
[31]
X. Chen, Y. Mu, Y. Hu, A. T. Kuan, M. Nikitchenko, O. Randlett, A. B. Chen, J. P. Gavornik, H. Sompolinsky, F. Engert, and M. B. Ahrens. Brain-wide organization of neuronal activ- ity and convergent sensorimotor transformations in larval zebrafish.Neuron, 100(4):876–890.e5, 2018. doi: 10.1016/j.neuron.2018.09.064
-
[32]
Mohammad Reza Keshtkaran, Andrew R. Sedler, Raeed H. Chowdhury, Raghav Tandon, Diya Basrai, Sarah L. Nguyen, Hansem Sohn, Mehrdad Jazay- eri, Lee E. Miller, and Chethan Pandarinath. A large-scale neural network training framework for generalized estimation of single-trial population dy- namics.Nature Methods, 19(12):1572–1577, 2022. doi: 10.1038/s41592-02...
-
[33]
David Sussillo, Rafal Jozefowicz, L. F. Abbott, and Chethan Pandarinath. Lfads - latent factor analysis via dynamical systems. 2016. URLhttps://arxiv. org/abs/1608.06315. 10 Supplementary Material The supplementary materials contain derivations for our theoretical framework and proofs for the mathematical statements in the main text. We also provide imple...
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.