Splatshot: 3D Face Avatar Generation from a Single Unconstrained Photo
Pith reviewed 2026-06-28 16:58 UTC · model grok-4.3
The pith
SplatShot generates 3D face avatars from one photo by feeding diffusion predictions back into a 3D Gaussian Splatting model at each denoising step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
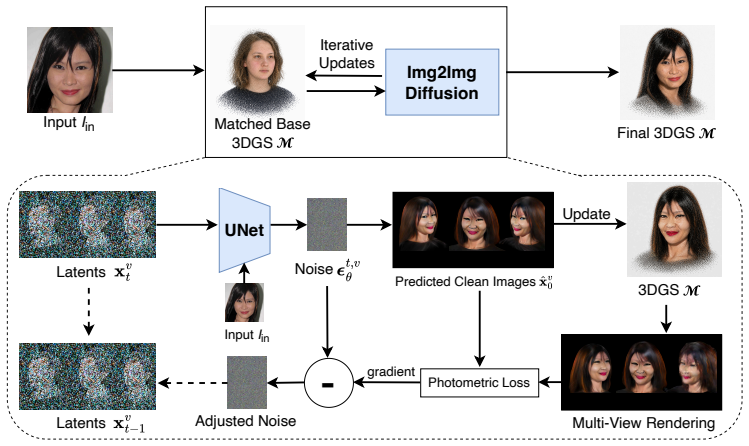
Given a base 3DGS face model and a single reference image, SplatShot jointly denoises all target views using a per-step 3D feedback loop. At each timestep, it predicts clean images from noisy latents, refits the 3DGS to these predictions, and back-propagates the photometric discrepancy between 3DGS re-renderings and 2D predictions into the noise estimate to steer the sampling toward 3D-coherent outputs.
What carries the argument
The per-step 3D feedback loop that refits the 3D Gaussian Splatting model to multi-view diffusion predictions and back-propagates photometric discrepancy to correct the noise estimates.
If this is right
- Produces 3D avatars with superior identity preservation compared to base methods.
- Achieves high photorealism from the diffusion prior while maintaining geometric consistency from 3DGS.
- Works without any training or fine-tuning on the input image.
- Handles diverse in-the-wild images effectively.
- Ensures multi-view consistency in the generated avatars.
Where Pith is reading between the lines
- Similar feedback mechanisms could improve consistency in other 3D generation tasks beyond faces.
- The approach might reduce the need for large multi-view training datasets in avatar creation.
- Extending the loop to handle dynamic expressions or head poses could be a natural next step.
Load-bearing premise
That the photometric discrepancy between 3DGS re-renderings and 2D diffusion predictions can be back-propagated to produce geometrically consistent outputs without any training on the input image.
What would settle it
Observing multi-view inconsistencies or identity mismatches in the output avatars when tested on a set of unconstrained photos where the base 3DGS model performs poorly.
Figures















read the original abstract
Reconstructing a photorealistic 3D face avatar from a single unconstrained photograph is challenging: feed-forward 3D Gaussian Splatting (3DGS) models degrade on out-of-distribution inputs, while pretrained diffusion models produce high-fidelity images but lack multi-view consistency. We observe that these paradigms are fundamentally complementary: explicit 3D representations guarantee geometric consistency, whereas 2D diffusion priors ensure photorealism. Building on this, we propose SplatShot, a training-free framework that couples these representations directly within the denoising process. Given a base 3DGS face model and a single reference image, we jointly denoise all target views using a per-step 3D feedback loop. At each timestep, we predict clean images from the noisy latents, refit the 3DGS to these multi-view predictions, and back-propagate the photometric discrepancy between the 3DGS re-renderings and 2D predictions into the noise estimate. This steers the sampling trajectory toward strictly 3D-coherent, identity-faithful outputs. Experiments on diverse in-the-wild images demonstrate that SplatShot produces 3D avatars with superior identity preservation, photorealism, and multi-view consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SplatShot, a training-free framework for generating 3D face avatars from a single unconstrained photograph. It starts from a base 3D Gaussian Splatting (3DGS) face model and a reference image, then jointly denoises multiple target views by means of a per-step feedback loop: at each timestep the diffusion model predicts clean images from noisy latents, the 3DGS is refit to those multi-view predictions, and the photometric discrepancy between the 3DGS re-renders and the 2D predictions is back-propagated to adjust the noise estimate. The authors claim this steers sampling toward outputs that are simultaneously 3D-coherent and identity-faithful. Experiments on diverse in-the-wild images are said to demonstrate superior identity preservation, photorealism, and multi-view consistency.
Significance. If the feedback mechanism reliably enforces geometric consistency without any per-image training or fine-tuning, the work would constitute a meaningful advance in single-image 3D reconstruction by directly coupling an explicit 3D representation with a pretrained 2D diffusion prior. The training-free character and the explicit use of photometric discrepancy as a corrective signal during sampling are clear strengths that distinguish the approach from purely feed-forward or purely generative baselines.
major comments (2)
- [Abstract; Method (per-step 3D feedback loop)] The central claim rests on the assumption that refitting the 3DGS model to diffusion x0 predictions supplies a usable geometric prior at every timestep, including high-noise regimes. No analysis, ablation, or stability argument is supplied to counter the possibility that early-timestep x0 estimates (dominated by the diffusion prior) produce degenerate or unstable 3DGS fits whose photometric discrepancy signal is noisy or contradictory (see the per-step loop description in the abstract and the method section).
- [Experiments] The assertion that SplatShot produces “superior” identity preservation, photorealism, and multi-view consistency is supported solely by qualitative statements. No quantitative metrics, ablation studies, error analysis, or baseline comparisons appear in the reported experiments, leaving the effectiveness of the back-propagation step unquantified (see Experiments section).
minor comments (2)
- [Method] The precise mathematical form of the back-propagation step (how photometric discrepancy modifies the noise estimate) should be stated explicitly, ideally with a short equation or pseudocode block.
- [Figures] Figure captions and axis labels in the qualitative results should indicate the exact viewpoints and reference image used so that multi-view consistency claims can be visually verified.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract; Method (per-step 3D feedback loop)] The central claim rests on the assumption that refitting the 3DGS model to diffusion x0 predictions supplies a usable geometric prior at every timestep, including high-noise regimes. No analysis, ablation, or stability argument is supplied to counter the possibility that early-timestep x0 estimates (dominated by the diffusion prior) produce degenerate or unstable 3DGS fits whose photometric discrepancy signal is noisy or contradictory (see the per-step loop description in the abstract and the method section).
Authors: We acknowledge that the manuscript does not include explicit analysis, ablations, or stability arguments for 3DGS refitting behavior specifically in high-noise regimes. The approach is designed around iterative refinement, where the photometric feedback progressively improves consistency as denoising proceeds from noisy to clean states. To directly address this concern, we will add a dedicated discussion of the feedback loop's behavior across timesteps along with an ablation examining the effect of initiating the 3D refitting at different noise levels. revision: yes
-
Referee: [Experiments] The assertion that SplatShot produces “superior” identity preservation, photorealism, and multi-view consistency is supported solely by qualitative statements. No quantitative metrics, ablation studies, error analysis, or baseline comparisons appear in the reported experiments, leaving the effectiveness of the back-propagation step unquantified (see Experiments section).
Authors: We agree that the current experiments section relies on qualitative demonstrations and lacks quantitative support for the superiority claims. The manuscript focuses on visual results across diverse in-the-wild inputs to highlight the method's practical advantages. In revision we will add quantitative metrics (e.g., identity similarity via ArcFace, multi-view consistency via cross-view PSNR/LPIPS), error analysis, and comparisons against relevant baselines, together with ablations isolating the contribution of the photometric feedback. revision: yes
Circularity Check
No significant circularity; method is a heuristic loop without reduction to inputs
full rationale
The paper describes an algorithmic procedure (per-step prediction, refit of 3DGS, photometric back-propagation into noise) rather than a derivation claiming first-principles predictions or uniqueness. No equations or steps reduce by construction to fitted parameters, self-citations, or renamed inputs. The framework is presented as training-free and externally testable via experiments on in-the-wild images, with no load-bearing self-citation chains or self-definitional elements visible in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Explicit 3D representations guarantee geometric consistency while 2D diffusion priors ensure photorealism.
Reference graph
Works this paper leans on
-
[1]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[2]
Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65 (1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65 (1):99–106, 2021
2021
-
[3]
Generalizable and animatable gaussian head avatar.Advances in Neural Information Processing Systems, 37:57642–57670, 2024
Xuangeng Chu and Tatsuya Harada. Generalizable and animatable gaussian head avatar.Advances in Neural Information Processing Systems, 37:57642–57670, 2024
2024
-
[4]
Fastavatar: Instant 3d gaussian splatting for faces from single unconstrained poses
Hao Liang, Zhixuan Ge, Soumendu Majee, Ashish Tiwari, GM Godaliyadda, Ashok Veeraraghavan, and Guha Balakrishnan. Fastavatar: Instant 3d gaussian splatting for faces from single unconstrained poses. arXiv preprint arXiv:2508.18389, 2025
-
[5]
Efficient geometry-aware 3d generative adversarial networks
Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, et al. Efficient geometry-aware 3d generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16123–16133, 2022
2022
-
[6]
Arc2avatar: Generating expressive 3d avatars from a single image via id guidance
Dimitrios Gerogiannis, Foivos Paraperas Papantoniou, Rolandos Alexandros Potamias, Alexandros Lattas, and Stefanos Zafeiriou. Arc2avatar: Generating expressive 3d avatars from a single image via id guidance. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10770–10782, 2025
2025
-
[7]
Human-3diffusion: realistic avatar creation via explicit 3d consistent diffusion models.Advances in Neural Information Processing Systems, 37:99601–99645, 2024
Yuxuan Xue, Xianghui Xie, Riccardo Marin, and Gerard Pons-Moll. Human-3diffusion: realistic avatar creation via explicit 3d consistent diffusion models.Advances in Neural Information Processing Systems, 37:99601–99645, 2024
2024
-
[8]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Face recognition based on fitting a 3d morphable model.IEEE Transactions on pattern analysis and machine intelligence, 25(9):1063–1074, 2003
V olker Blanz and Thomas Vetter. Face recognition based on fitting a 3d morphable model.IEEE Transactions on pattern analysis and machine intelligence, 25(9):1063–1074, 2003
2003
-
[10]
Learning to generate conditional tri-plane for 3d-aware expression controllable portrait animation
Taekyung Ki, Dongchan Min, and Gyeongsu Chae. Learning to generate conditional tri-plane for 3d-aware expression controllable portrait animation. InEuropean Conference on Computer Vision, pages 476–493. Springer, 2024
2024
-
[11]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[12]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019
2019
-
[13]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 10
2022
-
[14]
Next3d: Generative neural texture rasterization for 3d-aware head avatars
Jingxiang Sun, Xuan Wang, Lizhen Wang, Xiaoyu Li, Yong Zhang, Hongwen Zhang, and Yebin Liu. Next3d: Generative neural texture rasterization for 3d-aware head avatars. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20991–21002, 2023
2023
-
[15]
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for efficient 3d content creation.arXiv preprint arXiv:2309.16653, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
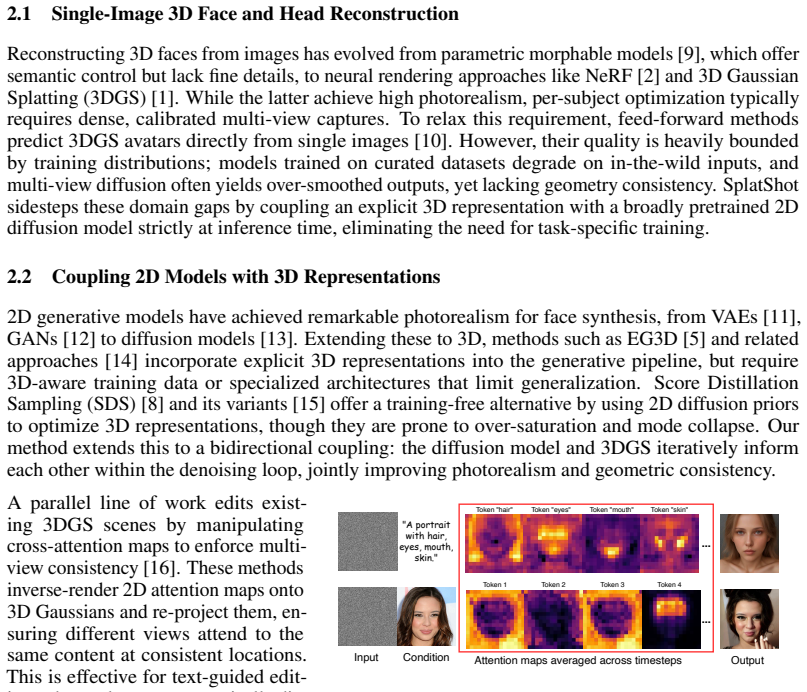
Intergsedit: Interactive 3d gaussian splatting editing with 3d geometry-consistent attention prior
Minghao Wen, Shengjie Wu, Kangkan Wang, and Dong Liang. Intergsedit: Interactive 3d gaussian splatting editing with 3d geometry-consistent attention prior. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 26136–26145, 2025
2025
-
[17]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[19]
Lam: large avatar model for one-shot animatable gaussian head
Yisheng He, Xiaodong Gu, Xiaodan Ye, Chao Xu, Zhengyi Zhao, Yuan Dong, Weihao Yuan, Zilong Dong, and Liefeng Bo. Lam: large avatar model for one-shot animatable gaussian head. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–13, 2025
2025
-
[20]
Facelift: Learning generalizable single image 3d face reconstruction from synthetic heads
Weijie Lyu, Yi Zhou, Ming-Hsuan Yang, and Zhixin Shu. Facelift: Learning generalizable single image 3d face reconstruction from synthetic heads. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12691–12701, 2025
2025
-
[21]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of the IEEE international conference on computer vision, pages 3730–3738, 2015
2015
-
[22]
Nersemble: Multi-view radiance field reconstruction of human heads.ACM Transactions on Graphics (TOG), 42(4): 1–14, 2023
Tobias Kirschstein, Shenhan Qian, Simon Giebenhain, Tim Walter, and Matthias Nießner. Nersemble: Multi-view radiance field reconstruction of human heads.ACM Transactions on Graphics (TOG), 42(4): 1–14, 2023
2023
-
[23]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[24]
gsplat: An open-source library for gaussian splatting
Vickie Ye, Ruilong Li, Justin Kerr, Matias Turkulainen, Brent Yi, Zhuoyang Pan, Otto Seiskari, Jianbo Ye, Jeffrey Hu, Matthew Tancik, and Angjoo Kanazawa. gsplat: An open-source library for gaussian splatting. Journal of Machine Learning Research, 26(34):1–17, 2025
2025
-
[25]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Xue Niannan, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InCVPR, 2019
2019
-
[26]
Yao Feng, Haiwen Feng, Michael J. Black, and Timo Bolkart. Learning an animatable detailed 3d face model from in-the-wild images.ACM Trans. Graph., 40(4), July 2021. ISSN 0730-0301. doi: 10.1145/3450626.3459936. URLhttps://doi.org/10.1145/3450626.3459936
-
[27]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[28]
Exploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 2555–2563, 2023
2023
-
[29]
Perflow: Piecewise rectified flow as universal plug-and-play accelerator.Advances in Neural Information Processing Systems, 37:78630–78652, 2024
Hanshu Yan, Xingchao Liu, Jiachun Pan, Jun Hao Liew, Qiang Liu, and Jiashi Feng. Perflow: Piecewise rectified flow as universal plug-and-play accelerator.Advances in Neural Information Processing Systems, 37:78630–78652, 2024
2024
-
[30]
Retinaface: Single-shot multi-level face localisation in the wild
Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou. Retinaface: Single-shot multi-level face localisation in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5203–5212, 2020
2020
-
[31]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021. 11
2021
-
[32]
Gaussianeditor: Swift and controllable 3d editing with gaussian splatting
Yiwen Chen, Zilong Chen, Chi Zhang, Feng Wang, Xiaofeng Yang, Yikai Wang, Zhongang Cai, Lei Yang, Huaping Liu, and Guosheng Lin. Gaussianeditor: Swift and controllable 3d editing with gaussian splatting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21476–21485, 2024
2024
-
[33]
View-consistent 3d editing with gaussian splatting
Yuxuan Wang, Xuanyu Yi, Zike Wu, Na Zhao, Long Chen, and Hanwang Zhang. View-consistent 3d editing with gaussian splatting. InEuropean conference on computer vision, pages 404–420. Springer, 2024
2024
-
[34]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to- prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
A morphable face albedo model
William AP Smith, Alassane Seck, Hannah Dee, Bernard Tiddeman, Joshua B Tenenbaum, and Bernhard Egger. A morphable face albedo model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5011–5020, 2020
2020
-
[37]
A morphable model for the synthesis of 3d faces
V olker Blanz and Thomas Vetter. A morphable model for the synthesis of 3d faces. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 157–164. 2023
2023
-
[38]
Learning formation of physically-based face attributes
Ruilong Li, Karl Bladin, Yajie Zhao, Chinmay Chinara, Owen Ingraham, Pengda Xiang, Xinglei Ren, Pratusha Prasad, Bipin Kishore, Jun Xing, et al. Learning formation of physically-based face attributes. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3410–3419, 2020
2020
-
[39]
Non-rigid neural radiance fields: Reconstruction and novel view synthesis of a dynamic scene from monocular video
Edgar Tretschk, Ayush Tewari, Vladislav Golyanik, Michael Zollhöfer, Christoph Lassner, and Christian Theobalt. Non-rigid neural radiance fields: Reconstruction and novel view synthesis of a dynamic scene from monocular video. InProceedings of the IEEE/CVF international conference on computer vision, pages 12959–12970, 2021
2021
-
[40]
Nerfies: Deformable neural radiance fields
Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Steven M Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. InProceedings of the IEEE/CVF international conference on computer vision, pages 5865–5874, 2021
2021
-
[41]
Mofanerf: Morphable facial neural radiance field
Yiyu Zhuang, Hao Zhu, Xusen Sun, and Xun Cao. Mofanerf: Morphable facial neural radiance field. In European conference on computer vision, pages 268–285. Springer, 2022
2022
-
[42]
Headnerf: A real-time nerf-based parametric head model
Yang Hong, Bo Peng, Haiyao Xiao, Ligang Liu, and Juyong Zhang. Headnerf: A real-time nerf-based parametric head model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20374–20384, 2022
2022
-
[43]
Dynamic neural radiance fields for monocular 4d facial avatar reconstruction
Guy Gafni, Justus Thies, Michael Zollhofer, and Matthias Nießner. Dynamic neural radiance fields for monocular 4d facial avatar reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8649–8658, 2021
2021
-
[44]
Marcel C. Buehler, Gengyan Li, Erroll Wood, Leonhard Helminger, Xu Chen, Tanmay Shah, Daoye Wang, Stephan Garbin, Sergio Orts-Escolano, Otmar Hilliges, Dmitry Lagun, Jérémy Riviere, Paulo Gotardo, Thabo Beeler, Abhimitra Meka, and Kripasindhu Sarkar. Cafca: High-quality novel view synthesis of expressive faces from casual few-shot captures. InACM SIGGRAPH...
-
[45]
Real-time radiance fields for single-image portrait view synthesis.ACM Transactions on Graphics (TOG), 42(4):1–15, 2023
Alex Trevithick, Matthew Chan, Michael Stengel, Eric Chan, Chao Liu, Zhiding Yu, Sameh Khamis, Manmohan Chandraker, Ravi Ramamoorthi, and Koki Nagano. Real-time radiance fields for single-image portrait view synthesis.ACM Transactions on Graphics (TOG), 42(4):1–15, 2023
2023
-
[46]
3d gaussian parametric head model
Yuelang Xu, Lizhen Wang, Zerong Zheng, Zhaoqi Su, and Yebin Liu. 3d gaussian parametric head model. InEuropean Conference on Computer Vision, pages 129–147. Springer, 2024
2024
-
[47]
Headgas: Real-time animatable head avatars via 3d gaussian splatting
Helisa Dhamo, Yinyu Nie, Arthur Moreau, Jifei Song, Richard Shaw, Yiren Zhou, and Eduardo Pérez- Pellitero. Headgas: Real-time animatable head avatars via 3d gaussian splatting. InEuropean Conference on Computer Vision, pages 459–476. Springer, 2024
2024
-
[48]
Graphavatar: Compact head avatars with gnn-generated 3d gaussians
Xiaobao Wei, Peng Chen, Ming Lu, Hui Chen, and Feng Tian. Graphavatar: Compact head avatars with gnn-generated 3d gaussians. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 8295–8303, 2025. 12
2025
-
[49]
3d gaussian blendshapes for head avatar animation
Shengjie Ma, Yanlin Weng, Tianjia Shao, and Kun Zhou. 3d gaussian blendshapes for head avatar animation. InACM SIGGRAPH 2024 Conference Papers, pages 1–10, 2024
2024
-
[50]
Gaussianavatars: Photorealistic head avatars with rigged 3d gaussians
Shenhan Qian, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Simon Giebenhain, and Matthias Nießner. Gaussianavatars: Photorealistic head avatars with rigged 3d gaussians. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20299–20309, 2024
2024
-
[51]
Splattingavatar: Realistic real-time human avatars with mesh-embedded gaussian splatting
Zhijing Shao, Zhaolong Wang, Zhuang Li, Duotun Wang, Xiangru Lin, Yu Zhang, Mingming Fan, and Zeyu Wang. Splattingavatar: Realistic real-time human avatars with mesh-embedded gaussian splatting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1606–1616, 2024
2024
-
[52]
Flashavatar: High-fidelity head avatar with efficient gaussian embedding
Jun Xiang, Xuan Gao, Yudong Guo, and Juyong Zhang. Flashavatar: High-fidelity head avatar with efficient gaussian embedding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1802–1812, 2024
2024
-
[53]
Hugs: Human gaussian splats
Muhammed Kocabas, Jen-Hao Rick Chang, James Gabriel, Oncel Tuzel, and Anurag Ranjan. Hugs: Human gaussian splats. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 505–515, 2024
2024
-
[54]
Gaussian head avatar: Ultra high-fidelity head avatar via dynamic gaussians
Yuelang Xu, Benwang Chen, Zhe Li, Hongwen Zhang, Lizhen Wang, Zerong Zheng, and Yebin Liu. Gaussian head avatar: Ultra high-fidelity head avatar via dynamic gaussians. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1931–1941, 2024
1931
-
[55]
3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting
Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, and Siyu Tang. 3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5020–5030, 2024
2024
-
[56]
Gasp: Gaussian avatars with synthetic priors
Jack Saunders, Charlie Hewitt, Yanan Jian, Marek Kowalski, Tadas Baltrusaitis, Yiye Chen, Darren Cosker, Virginia Estellers, Nicholas Gydé, Vinay P Namboodiri, et al. Gasp: Gaussian avatars with synthetic priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 271–280, 2025
2025
-
[57]
Gaussian deja-vu: Creating controllable 3d gaussian head-avatars with enhanced generalization and personalization abilities
Peizhi Yan, Rabab Ward, Qiang Tang, and Shan Du. Gaussian deja-vu: Creating controllable 3d gaussian head-avatars with enhanced generalization and personalization abilities. InProceedings of the Winter Conference on Applications of Computer Vision (WACV), pages 276–286, February 2025
2025
-
[58]
Gaussianavatar: Towards realistic human avatar modeling from a single video via animatable 3d gaussians
Liangxiao Hu, Hongwen Zhang, Yuxiang Zhang, Boyao Zhou, Boning Liu, Shengping Zhang, and Liqiang Nie. Gaussianavatar: Towards realistic human avatar modeling from a single video via animatable 3d gaussians. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 634–644, 2024
2024
-
[59]
Mega: Hybrid mesh-gaussian head avatar for high-fidelity rendering and head editing
Cong Wang, Di Kang, Heyi Sun, Shenhan Qian, Zixuan Wang, Linchao Bao, and Song-Hai Zhang. Mega: Hybrid mesh-gaussian head avatar for high-fidelity rendering and head editing. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26274–26284, 2025
2025
-
[60]
Npga: Neural parametric gaussian avatars
Simon Giebenhain, Tobias Kirschstein, Martin Rünz, Lourdes Agapito, and Matthias Nießner. Npga: Neural parametric gaussian avatars. InSIGGRAPH Asia 2024 Conference Papers (SA Conference Papers ’24), December 3-6, Tokyo, Japan, 2024. ISBN 979-8-4007-1131-2/24/12. doi: 10.1145/3680528.3687689
-
[61]
Generalizable one-shot 3d neural head avatar.Advances in Neural Information Processing Systems, 36:47239–47250, 2023
Xueting Li, Shalini De Mello, Sifei Liu, Koki Nagano, Umar Iqbal, and Jan Kautz. Generalizable one-shot 3d neural head avatar.Advances in Neural Information Processing Systems, 36:47239–47250, 2023
2023
-
[62]
Otavatar: One-shot talking face avatar with controllable tri-plane rendering
Zhiyuan Ma, Xiangyu Zhu, Guo-Jun Qi, Zhen Lei, and Lei Zhang. Otavatar: One-shot talking face avatar with controllable tri-plane rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16901–16910, 2023
2023
-
[63]
V oodoo 3d: V olumetric portrait disentanglement for one-shot 3d head reenactment
Phong Tran, Egor Zakharov, Long-Nhat Ho, Anh Tuan Tran, Liwen Hu, and Hao Li. V oodoo 3d: V olumetric portrait disentanglement for one-shot 3d head reenactment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10336–10348, 2024
2024
-
[64]
Facescape: a large-scale high quality 3d face dataset and detailed riggable 3d face prediction
Haotian Yang, Hao Zhu, Yanru Wang, Mingkai Huang, Qiu Shen, Ruigang Yang, and Xun Cao. Facescape: a large-scale high quality 3d face dataset and detailed riggable 3d face prediction. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, pages 601–610, 2020
2020
-
[65]
Towards metrical reconstruction of human faces
Wojciech Zielonka, Timo Bolkart, and Justus Thies. Towards metrical reconstruction of human faces. In European conference on computer vision, pages 250–269. Springer, 2022. 13
2022
-
[66]
Talkinggaussian: Structure- persistent 3d talking head synthesis via gaussian splatting
Jiahe Li, Jiawei Zhang, Xiao Bai, Jin Zheng, Xin Ning, Jun Zhou, and Lin Gu. Talkinggaussian: Structure- persistent 3d talking head synthesis via gaussian splatting. InEuropean Conference on Computer Vision, pages 127–145. Springer, 2024
2024
-
[67]
Pointavatar: Deformable point-based head avatars from videos
Yufeng Zheng, Wang Yifan, Gordon Wetzstein, Michael J Black, and Otmar Hilliges. Pointavatar: Deformable point-based head avatars from videos. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21057–21067, 2023
2023
-
[68]
One-shot high-fidelity talking-head synthesis with de- formable neural radiance field
Weichuang Li, Longhao Zhang, Dong Wang, Bin Zhao, Zhigang Wang, Mulin Chen, Bang Zhang, Zhongjian Wang, Liefeng Bo, and Xuelong Li. One-shot high-fidelity talking-head synthesis with de- formable neural radiance field. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17969–17978, 2023
2023
-
[69]
Cvthead: One-shot con- trollable head avatar with vertex-feature transformer
Haoyu Ma, Tong Zhang, Shanlin Sun, Xiangyi Yan, Kun Han, and Xiaohui Xie. Cvthead: One-shot con- trollable head avatar with vertex-feature transformer. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 6131–6141, 2024
2024
-
[70]
Learning dense correspondence for nerf-based face reenactment
Songlin Yang, Wei Wang, Yushi Lan, Xiangyu Fan, Bo Peng, Lei Yang, and Jing Dong. Learning dense correspondence for nerf-based face reenactment. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 6522–6530, 2024
2024
-
[71]
Gpavatar: Generalizable and precise head avatar from image (s).arXiv preprint arXiv:2401.10215, 2024
Xuangeng Chu, Yu Li, Ailing Zeng, Tianyu Yang, Lijian Lin, Yunfei Liu, and Tatsuya Harada. Gpavatar: Generalizable and precise head avatar from image (s).arXiv preprint arXiv:2401.10215, 2024
-
[72]
Zhenhui Ye, Tianyun Zhong, Yi Ren, Jiaqi Yang, Weichuang Li, Jiawei Huang, Ziyue Jiang, Jinzheng He, Rongjie Huang, Jinglin Liu, et al. Real3d-portrait: One-shot realistic 3d talking portrait synthesis.arXiv preprint arXiv:2401.08503, 2024
-
[73]
Coherent 3d portrait video reconstruction via triplane fusion
Shengze Wang, Xueting Li, Chao Liu, Matthew Chan, Michael Stengel, Henry Fuchs, Shalini De Mello, and Koki Nagano. Coherent 3d portrait video reconstruction via triplane fusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10712–10722, June 2025
2025
-
[74]
Generating diverse high-fidelity images with vq-vae-2
Ali Razavi, Aaron Van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with vq-vae-2. Advances in neural information processing systems, 32, 2019
2019
-
[75]
Analyzing and improving the image quality of stylegan
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8110–8119, 2020
2020
-
[76]
Alias-free generative adversarial networks.Advances in neural information processing systems, 34: 852–863, 2021
Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Alias-free generative adversarial networks.Advances in neural information processing systems, 34: 852–863, 2021
2021
-
[77]
Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[78]
Gram: Generative radiance manifolds for 3d-aware image generation
Yu Deng, Jiaolong Yang, Jianfeng Xiang, and Xin Tong. Gram: Generative radiance manifolds for 3d-aware image generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10673–10683, 2022
2022
-
[79]
Panohead: Geometry- aware 3d full-head synthesis in 360deg
Sizhe An, Hongyi Xu, Yichun Shi, Guoxian Song, Umit Y Ogras, and Linjie Luo. Panohead: Geometry- aware 3d full-head synthesis in 360deg. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20950–20959, 2023
2023
-
[80]
Spherehead: stable 3d full-head synthesis with spherical tri-plane representation
Heyuan Li, Ce Chen, Tianhao Shi, Yuda Qiu, Sizhe An, Guanying Chen, and Xiaoguang Han. Spherehead: stable 3d full-head synthesis with spherical tri-plane representation. InEuropean Conference on Computer Vision, pages 324–341. Springer, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.