S-SPPO: Semantic-Calibrated Self-Play Preference Optimization
Pith reviewed 2026-06-28 14:56 UTC · model grok-4.3
The pith
S-SPPO stabilizes self-play preference optimization by annealing win rates on semantically similar responses and adding latent repulsion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
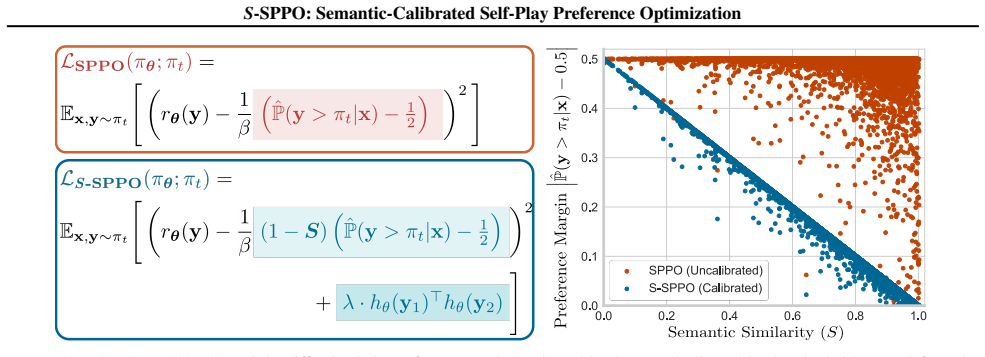
S-SPPO introduces supervision calibration via semantic gating that anneals win-rate targets toward the maximum-entropy baseline as overlap increases, together with representation calibration via latent repulsion that maintains geometric diversity between chosen and rejected samples; together these steps prevent manifold collapse while preserving the constant-sum game property that supports convergence to Nash equilibrium.
What carries the argument
Dual-space semantic calibration framework consisting of semantic gating for win-rate annealing and latent repulsion for geometric diversity between responses.
If this is right
- The method reaches 52.19% win rate and 47.46% length-controlled win rate on AlpacaEval 2.0.
- Iterative self-play training avoids the performance drop seen in prior SPPO variants.
- Convergence to Nash equilibrium remains guaranteed under the calibrated game structure.
- No additional human-annotated preference data is required during training.
Where Pith is reading between the lines
- The same overlap-based annealing could be tested on other iterative alignment procedures that generate their own training pairs.
- Latent repulsion might be adapted to maintain diversity in non-preference tasks such as continued pretraining or instruction tuning.
- Semantic gating could be combined with length-controlled evaluation to isolate content quality from surface features.
Load-bearing premise
Semantic overlap between responses can be measured reliably enough to adjust win-rate targets without distorting the underlying preference signal.
What would settle it
Training the same Llama-3-8B model with the semantic gating and latent repulsion components removed and measuring whether the AlpacaEval 2.0 win rate falls below 52% or shows progressive degradation across iterations.
Figures

read the original abstract
Aligning Large Language Models (LLMs) with human preferences is often formulated via Direct Preference Optimization (DPO). However, the standard Bradley-Terry instantiation of DPO is limited in modeling common departures from transitivity in human preferences. To address this, recent work has introduced Self-Play Preference Optimization (SPPO), which iteratively refines the policy by training on self-generated win-lose pairs. Our investigation, however, reveals a critical instability in SPPO: the optimization is prone to policy degeneration when the preference oracle assigns overly confident wins to semantically indistinguishable responses. To mitigate this, we propose S-SPPO, a dual-space semantic calibration framework comprising: i) Supervision Calibration via semantic gating, which anneals win rate targets toward the maximum-entropy baseline as semantic overlap increases; and ii) Representation Calibration via latent repulsion to enforce geometric diversity to prevent manifold collapse and maintain latent diversity between chosen and rejected samples. Theoretically, we show that the calibration preserves the constant-sum game structure, facilitating convergence to a Nash Equilibrium. Empirically, S-SPPO avoids the performance degradation seen in prior methods, achieving 52.19% win rate and 47.46% length-controlled win rate on AlpacaEval 2.0 with Llama-3-8B, without using additional human-annotated preferences during training. The code will be available at https://github.com/xiwenc1/s-sppo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes S-SPPO as an extension to Self-Play Preference Optimization (SPPO) for LLM alignment. It identifies an instability in SPPO arising when the preference oracle assigns high-confidence wins to semantically indistinguishable responses, and introduces a dual-space semantic calibration framework consisting of (i) supervision calibration via semantic gating that anneals win-rate targets toward a maximum-entropy baseline as overlap increases and (ii) representation calibration via a latent repulsion term to enforce geometric diversity. The method is claimed to preserve the constant-sum game structure, enabling convergence to a Nash equilibrium, and is reported to achieve 52.19% win rate and 47.46% length-controlled win rate on AlpacaEval 2.0 with Llama-3-8B without additional human-annotated preferences.
Significance. If the claimed preservation of game structure and the reported win rates are substantiated, the work would address a practically relevant instability in self-play preference methods and demonstrate gains without extra annotation cost. The identification of the degeneration issue on indistinguishable pairs is a useful diagnostic observation.
major comments (3)
- [Abstract] Abstract: the claim that the calibration 'preserves the constant-sum game structure' is asserted without any derivation, proof sketch, or reference to modified payoff matrices or equilibrium conditions, so it is impossible to verify whether the annealing and repulsion terms maintain the property or alter the effective game.
- [Abstract] Abstract: the overlap metric (embedding model, similarity function, gating schedule), the exact functional form of the latent repulsion loss, and its relative weighting to the preference loss are undefined; these quantities are load-bearing for the central claim that the added terms prevent collapse without weakening the preference gradient.
- [Abstract] Abstract: the empirical results (52.19% win rate, 47.46% LC win rate) are stated without experimental protocol, number of evaluation runs, statistical details, baseline comparisons, or ablation evidence, preventing assessment of whether the dual-space components are responsible for the reported improvement over prior SPPO degradation.
minor comments (1)
- The abstract states that code will be released but supplies no repository link or reproducibility details.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where the abstract could better support verification of our claims. We address each point below and will make targeted revisions to the abstract and related sections for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the calibration 'preserves the constant-sum game structure' is asserted without any derivation, proof sketch, or reference to modified payoff matrices or equilibrium conditions, so it is impossible to verify whether the annealing and repulsion terms maintain the property or alter the effective game.
Authors: The full manuscript (Section 4) provides a proof that the added calibration terms are symmetric with respect to the two players and thus preserve the constant-sum property of the original SPPO game; the effective payoff matrix remains unchanged up to an additive constant that cancels in the Nash analysis. We will revise the abstract to include a one-sentence reference to this section and a brief statement that the terms do not modify relative payoffs. revision: yes
-
Referee: [Abstract] Abstract: the overlap metric (embedding model, similarity function, gating schedule), the exact functional form of the latent repulsion loss, and its relative weighting to the preference loss are undefined; these quantities are load-bearing for the central claim that the added terms prevent collapse without weakening the preference gradient.
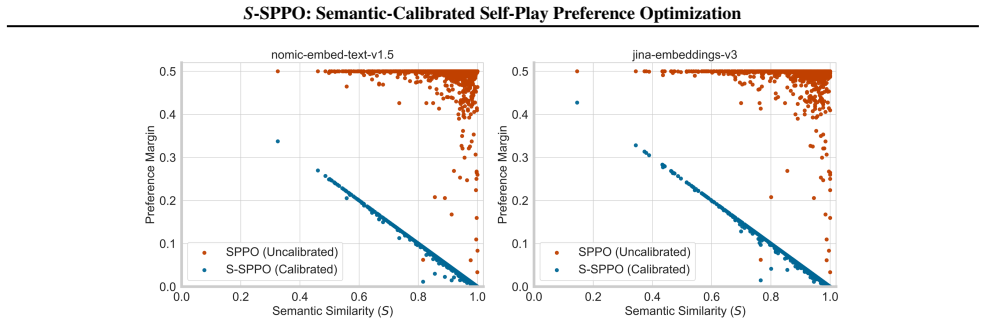
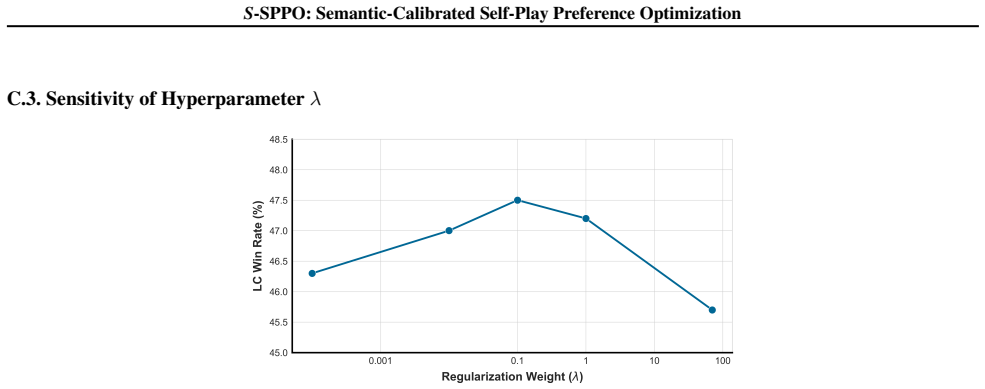
Authors: These specifications appear in Section 3: cosine similarity on sentence-transformer embeddings, linear gating schedule with threshold 0.85, repulsion loss as an InfoNCE term in the latent space, and weighting coefficient 0.1. We agree the abstract should briefly name the embedding model and loss form; we will add a short clause to that effect. revision: yes
-
Referee: [Abstract] Abstract: the empirical results (52.19% win rate, 47.46% LC win rate) are stated without experimental protocol, number of evaluation runs, statistical details, baseline comparisons, or ablation evidence, preventing assessment of whether the dual-space components are responsible for the reported improvement over prior SPPO degradation.
Authors: Section 5 details the protocol (three random seeds, AlpacaEval 2.0 with GPT-4 judge, length-controlled metric), reports standard deviations, compares against SPPO/DPO baselines, and includes ablations isolating each calibration component. We will expand the abstract by one sentence to note that results are averaged over three runs and that ablations confirm both terms contribute to stability. revision: partial
Circularity Check
No circularity: new calibration terms introduced without reduction to fitted inputs or self-citation chains
full rationale
The paper introduces S-SPPO as an extension of SPPO with two new components (semantic gating for supervision calibration and latent repulsion for representation calibration) plus a theoretical claim that these preserve constant-sum structure. No equations are visible in the supplied text that would allow any claimed result (Nash convergence, win-rate targets, or performance metrics) to reduce by construction to the inputs or to a self-citation. The overlap metric, repulsion loss form, and weighting are presented as design choices rather than derived quantities. No self-citation is used to justify uniqueness or to smuggle an ansatz. The derivation chain therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y ., Jones, A., Ndousse, K., Askell, A., Chen, A., Das- Sarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with rein- forcement learning from human feedback.arXiv preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Chen, Y ., Zhu, W., Chen, X., Wang, Z., Li, X., Qiu, P., Wang, H., Dong, X., Xiong, Y ., Schneider, A., et al. Aha: Aligning large audio-language models for reasoning hallucinations via counterfactual hard negatives.arXiv preprint arXiv:2512.24052,
-
[3]
Ultrafeedback: Boosting language models with scaled ai feedback
Cui, G., Yuan, L., Ding, N., Yao, G., He, B., Zhu, W., Ni, Y ., Xie, G., Xie, R., Lin, Y ., et al. Ultrafeedback: Boosting language models with scaled ai feedback. InForty-first International Conference on Machine Learning. Dong, H., Xiong, W., Pang, B., Wang, H., Zhao, H., Zhou, Y ., Jiang, N., Sahoo, D., Xiong, C., and Zhang, T. Rlhf workflow: From rewa...
2024
-
[4]
Dubois, Y ., Galambosi, B., Liang, P., and Hashimoto, T. B. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
KTO: Model Alignment as Prospect Theoretic Optimization
9 S-SPPO: Semantic-Calibrated Self-Play Preference Optimization Ethayarajh, K., Xu, W., Muennighoff, N., Jurafsky, D., and Kiela, D. Kto: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
K., Guzman, S., Mastrapas, G., Sturua, S., Wang, B., et al
G¨unther, M., Ong, J., Mohr, I., Abdessalem, A., Abel, T., Akram, M. K., Guzman, S., Mastrapas, G., Sturua, S., Wang, B., et al. Jina embeddings 2: 8192-token general- purpose text embeddings for long documents.arXiv preprint arXiv:2310.19923,
-
[7]
Orpo: Monolithic prefer- ence optimization without reference model
Hong, J., Lee, N., and Thorne, J. Orpo: Monolithic prefer- ence optimization without reference model. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 11170–11189,
2024
-
[8]
Ji, X., Kulkarni, S., Wang, M., and Xie, T. Self-play with adversarial critic: Provable and scalable offline alignment for language models.arXiv preprint arXiv:2406.04274,
-
[9]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.- A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. Mistral 7b, 2023a. URL https: //arxiv.org/abs/2310.06825. Jiang, D., Ren, X., and Lin, B. Y . Llm-blender...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Tilted empir- ical risk minimization.arXiv preprint arXiv:2007.01162,
Li, T., Beirami, A., Sanjabi, M., and Smith, V . Tilted empir- ical risk minimization.arXiv preprint arXiv:2007.01162,
-
[11]
Liu, T., Zhao, Y ., Joshi, R., Khalman, M., Saleh, M., Liu, P., and Liu, J
URL https: //openreview.net/forum?id=KfTf9vFvSn. Liu, T., Zhao, Y ., Joshi, R., Khalman, M., Saleh, M., Liu, P., and Liu, J. Statistical rejection sampling improves preference optimization. InInternational conference on learning representations, volume 2024, pp. 54605–54624,
2024
-
[12]
Nomic Embed: Training a Reproducible Long Context Text Embedder
Nussbaum, Z., Morris, J. X., Duderstadt, B., and Mulyar, A. Nomic embed: Training a reproducible long context text embedder.arXiv preprint arXiv:2402.01613,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
K., and Krause, A
P´asztor, B., Buening, T. K., and Krause, A. Stackelberg learning from human feedback: Preference optimization as a sequential game. InNeurIPS 2025 Workshop: Second Workshop on Aligning Reinforcement Learning Experi- mentalists and Theorists,
2025
-
[14]
Direct nash optimization: Teaching language models to self-improve with general preferences
Rosset, C., Cheng, C.-A., Mitra, A., Santacroce, M., Awadal- lah, A., and Xie, T. Direct nash optimization: Teaching language models to self-improve with general preferences. arXiv preprint arXiv:2404.03715,
-
[15]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
K., G¨unther, M., Wang, B., Krimmel, M., Wang, F., Mastrapas, G., Koukounas, A., Wang, N., et al
Sturua, S., Mohr, I., Akram, M. K., G¨unther, M., Wang, B., Krimmel, M., Wang, F., Mastrapas, G., Koukounas, A., Wang, N., et al. jina-embeddings-v3: Multilingual embed- dings with task lora.arXiv preprint arXiv:2409.10173,
-
[17]
Aligning large multi- modal models with factually augmented rlhf
Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y ., Gan, C., Gui, L., Wang, Y .-X., Yang, Y ., et al. Aligning large multi- modal models with factually augmented rlhf. InFindings 10 S-SPPO: Semantic-Calibrated Self-Play Preference Optimization of the Association for Computational Linguistics: ACL 2024, pp. 13088–13110,
2024
-
[18]
Tang, X., Yoon, S., Son, S., Yuan, H., Gu, Q., and Bogunovic, I. Game-theoretic regularized self-play alignment of large language models.arXiv preprint arXiv:2503.00030,
-
[19]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Magnetic preference optimization: Achieving last-iterate conver- gence for language model alignment
Wang, M., Ma, C., Chen, Q., Meng, L., Han, Y ., Xiao, J., Zhang, Z., Huo, J., Su, W., and Yang, Y . Magnetic preference optimization: Achieving last-iterate conver- gence for language model alignment. InInternational Conference on Learning Representations, volume 2025, pp. 35759–35790,
2025
-
[21]
Xiang, H., Yu, B., Lin, H., Lu, K., Lu, Y ., Han, X., He, B., Sun, L., Zhou, J., and Lin, J
URL https:// openreview.net/forum?id=a3PmRgAB5T. Xiang, H., Yu, B., Lin, H., Lu, K., Lu, Y ., Han, X., He, B., Sun, L., Zhou, J., and Lin, J. Self-steering optimization: Autonomous preference optimization for large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 9073–9085,
2025
- [22]
-
[23]
Proof A.1
11 S-SPPO: Semantic-Calibrated Self-Play Preference Optimization A. Proof A.1. Proof of Lemma 3.1 Proof. By definition, the policy-level win rate is the expectation of the calibrated pairwise preference. Thus, it suffices to show that the calibrated pairwise probabilitybPc maintains the antisymmetry property of the original preference oracle. For any resp...
1999
-
[24]
We chooseall-MiniLM-L6-v2as our default lightweight encoder model. B.2. Response Generation and Probability Estimation During the generation phase of each iteration, we sample K= 5 responses for each prompt from the current policy using a temperature of 1.0 and top-p= 1.0 . To estimate the winning probability distribution bP(y i ≻π t|x), we calculate the ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.