EvoPool: Evolutionary Programmatic Annotation for Label-Efficient Specialized Supervision
Pith reviewed 2026-06-28 15:27 UTC · model grok-4.3
The pith
An evolutionary search over executable annotator code produces training labels that beat direct LLM annotation on seven of eight specialized tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
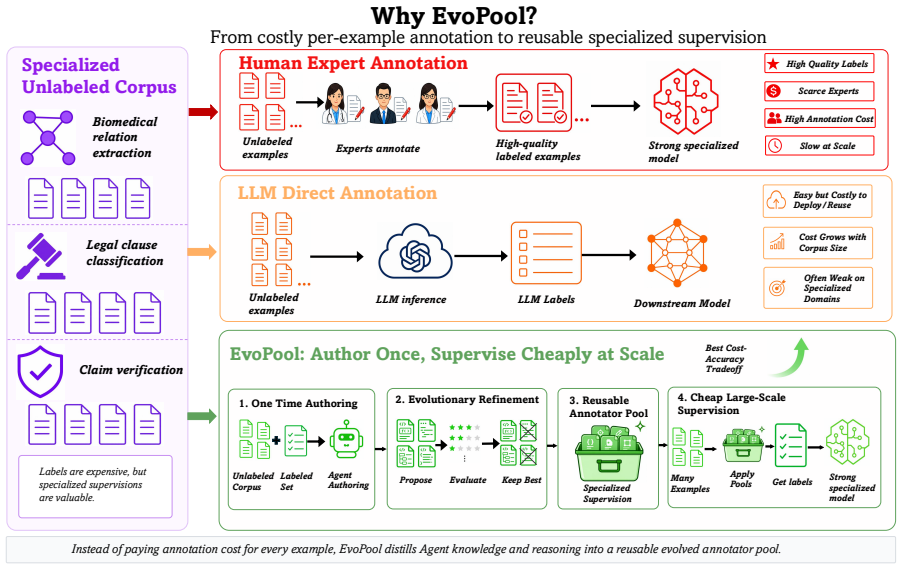
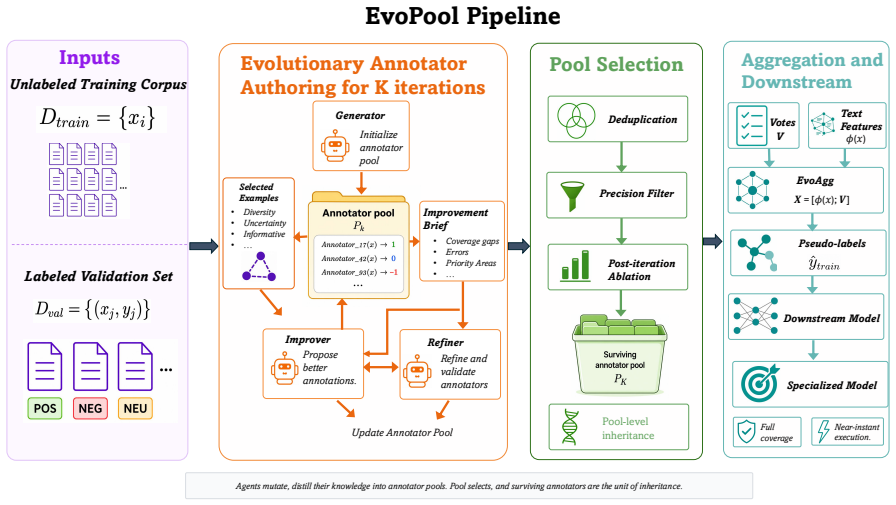
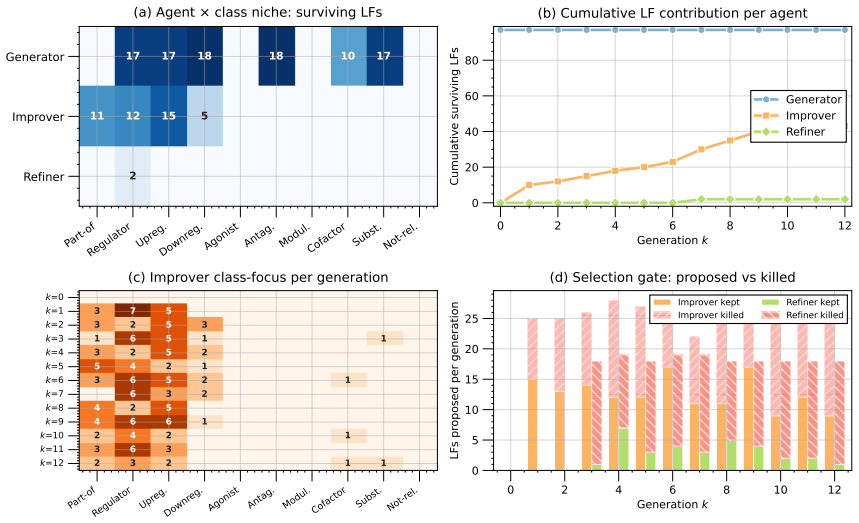
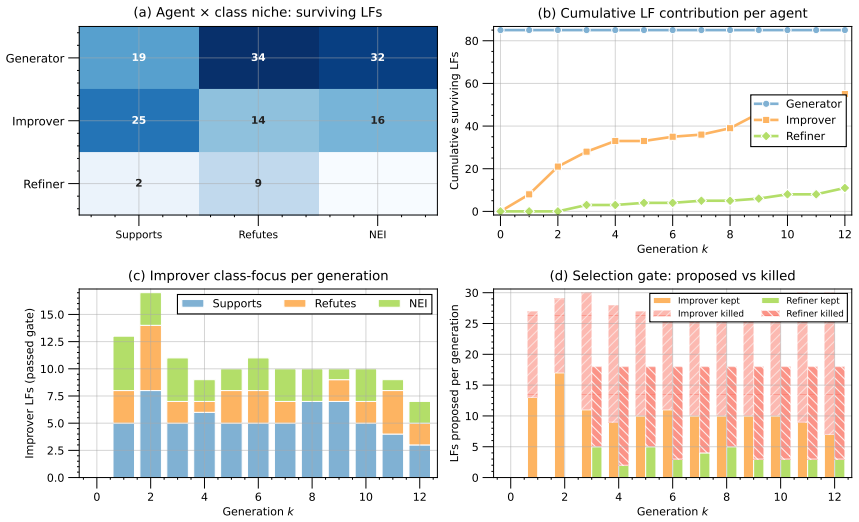
EvoPool maintains a population of programmatic annotators that are refined over generations by three cooperating agents: one proposes new code, one evaluates fitness on a held-out validation slice, and deterministic gates discard programs that fail viability, diversity, or marginal-contribution tests; the final pool's votes are combined by EvoAgg, which fuses semantic text features with annotator reliability signals to produce soft training labels that let downstream supervised models surpass LLM annotation baselines on seven of eight LLM-weak specialized tasks.
What carries the argument
The evolutionary multi-agent loop that proposes, gates, and retains executable annotator code using a small validation set as the sole fitness signal.
If this is right
- Supervised models for high-stakes domains can be trained without large expert-labeled corpora or repeated expensive LLM calls.
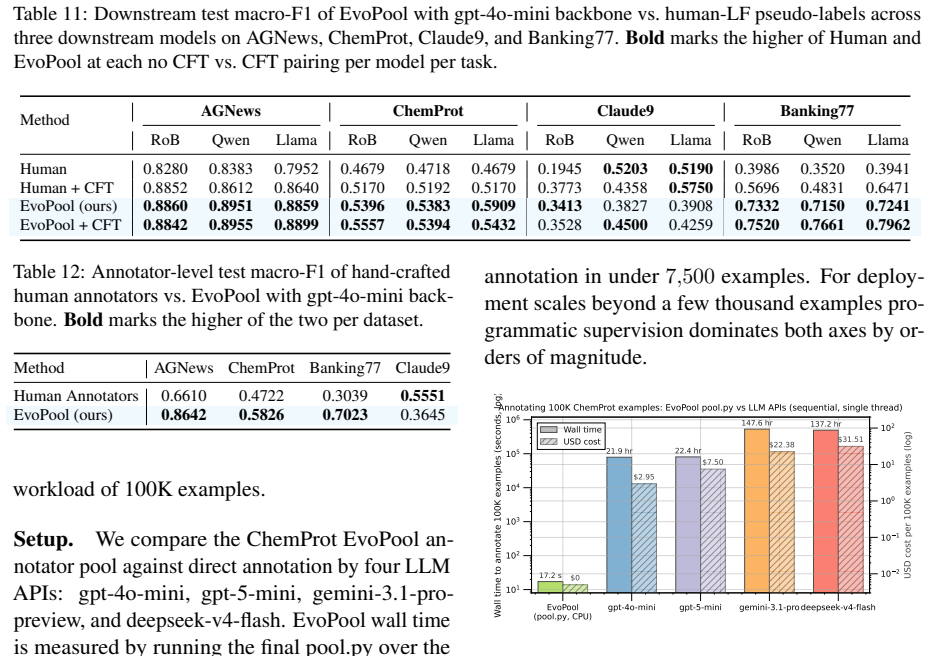
- Once the annotator pool exists, labeling 100,000 examples costs near zero compute and finishes orders of magnitude faster than LLM annotation.
- The same evolutionary process applies across biomedical relation extraction, legal clause classification, complex reasoning, and dense multi-label classification.
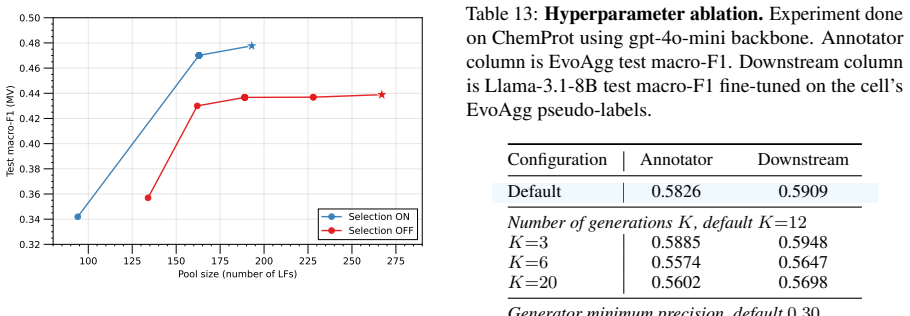
- Soft labels from the aggregated pool improve macro-F1 by 0.141 on average and up to 0.3 on individual tasks compared with the strongest LLM baseline.
Where Pith is reading between the lines
- Programmatic annotators allow human inspection and editing of the exact rules being applied, unlike opaque LLM outputs.
- The method could be paired with active learning to choose the smallest possible validation set that still guides useful evolution.
- Because the annotators are code, the same pool can be reused or fine-tuned for related tasks without restarting the evolutionary search.
Load-bearing premise
A small validation set is representative enough that annotators selected by the evolutionary process will label the full unlabeled corpus without overfitting to the validation distribution.
What would settle it
Retraining the same downstream models on EvoPool labels and measuring performance on a fresh expert-labeled test set yields no gain or a loss relative to the LLM annotation baseline.
Figures
read the original abstract
Large language models excel at general tasks but underperform smaller supervised models in specialized, high-stakes domains where training labels are costly. We address this regime with EvoPool, an evolutionary multi-agent framework inspired by Darwinian evolution. Three specialized agents iteratively propose executable annotator code, a small validation set provides a fitness signal, and a deterministic gate keeps only annotators that pass viability, diversity, and marginal-contribution checks across generations. Pool votes are mapped to soft training labels by EvoAgg, a text-aware aggregator combining semantic features with annotator-vote features. The authored pool runs at near-zero per-example cost and is 4500 to 31000x faster than LLM annotation on 100K examples. Across 7 of 8 LLM-weak specialized and complex tasks spanning biomedical relation extraction, legal-clause classification, complex reasoning, and dense multi-label biomedical classification, EvoPool beats the strongest LLM annotation baseline by an average +0.141 macro-F1, peaking at +0.301 on ChemProt and +0.265 on PubMed. Code is available at: https://github.com/tianyi0216/EvoPool
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EvoPool, an evolutionary multi-agent system that iteratively generates executable annotator code, uses a small validation set for fitness evaluation under viability/diversity/marginal-contribution gates, and aggregates votes via the text-aware EvoAgg module to produce soft labels. It reports that the resulting pools outperform the strongest LLM annotation baselines by an average +0.141 macro-F1 (peaking at +0.301 on ChemProt) across 7 of 8 specialized tasks in biomedical, legal, and reasoning domains, while delivering 4500–31000× speedups on 100K examples. Public code is released.
Significance. If the reported gains prove robust, the work would be significant for label-efficient supervision in high-stakes specialized domains, demonstrating a practical route to custom, near-zero-cost annotator pools that avoid repeated LLM calls. The explicit code release and emphasis on deterministic gates are strengths that support reproducibility and controlled experimentation.
major comments (1)
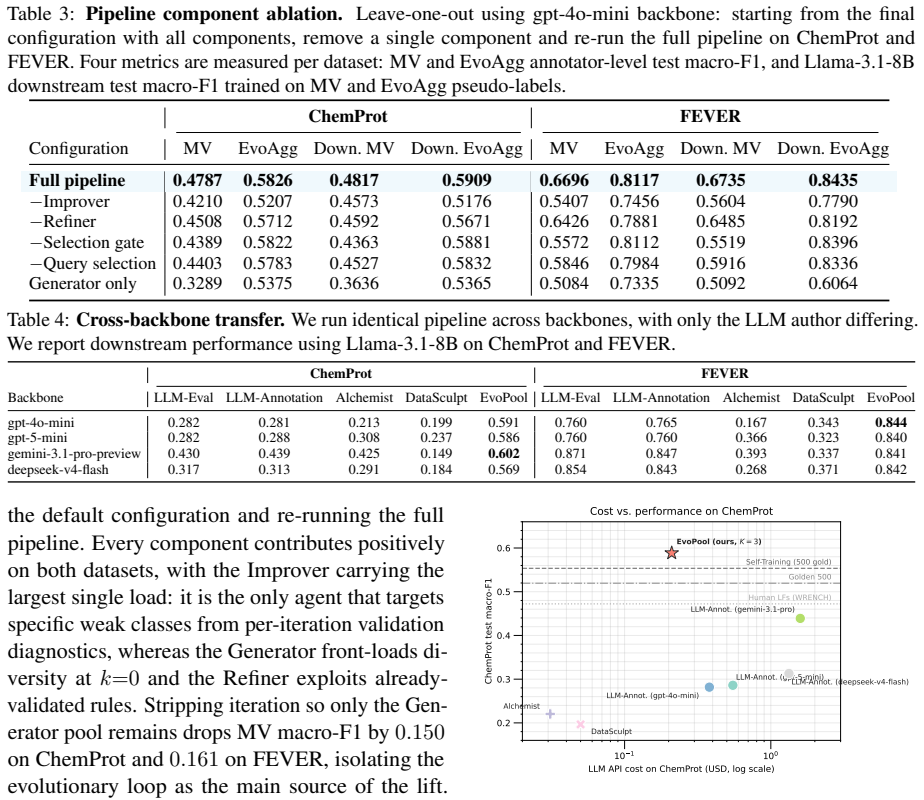
- [Abstract / §3] Abstract and §3 (method): the central empirical claim—that evolved annotators produce generalizable soft labels for the full unlabeled corpus—rests on fitness evaluation performed exclusively on a small validation set. No information is supplied on validation-set size, sampling procedure, label-distribution match to the corpus, or any post-selection generalization diagnostics (e.g., held-out test performance of the final pool or ablation of gate thresholds). This leaves the risk of overfitting to validation-specific artifacts unaddressed and directly undermines the reported +0.141 average improvement.
minor comments (1)
- [Abstract] The abstract states results on “7 of 8” tasks but does not name the eighth task or report its outcome; adding this detail would improve completeness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript accordingly to improve clarity on validation and generalization.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method): the central empirical claim—that evolved annotators produce generalizable soft labels for the full unlabeled corpus—rests on fitness evaluation performed exclusively on a small validation set. No information is supplied on validation-set size, sampling procedure, label-distribution match to the corpus, or any post-selection generalization diagnostics (e.g., held-out test performance of the final pool or ablation of gate thresholds). This leaves the risk of overfitting to validation-specific artifacts unaddressed and directly undermines the reported +0.141 average improvement.
Authors: We agree that the abstract and §3 currently provide insufficient detail on the validation set used for fitness evaluation. This omission makes it harder for readers to assess overfitting risk. In the revised manuscript we will expand §3 to report, for each task: the exact validation-set size, the sampling procedure (including any stratification to approximate corpus label distribution), and post-selection generalization diagnostics consisting of (i) held-out test performance of the final selected pool and (ii) an ablation on the viability/diversity/marginal-contribution gate thresholds. These additions will directly address the concern and strengthen support for the reported gains, which are measured on held-out test data separate from the evolution validation set. revision: yes
Circularity Check
No circularity; purely empirical method with external benchmarks
full rationale
The paper describes an evolutionary multi-agent annotation framework and reports head-to-head macro-F1 results on 8 specialized tasks against LLM baselines. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim rests on observable experimental outcomes rather than any reduction to its own inputs by construction. This is the standard case of a self-contained empirical paper whose validity is tested externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Thirteenth International Conference on Learning Representations , year=
Specialized Foundation Models Struggle to Beat Supervised Baselines , author=. The Thirteenth International Conference on Learning Representations , year=
-
[2]
Data Programming: Creating Large Training Sets, Quickly , url =
Ratner, Alexander J and De Sa, Christopher and Wu, Sen and Selsam, Daniel and R\'. Data Programming: Creating Large Training Sets, Quickly , url =. Advances in Neural Information Processing Systems , editor =
-
[3]
Proceedings of the VLDB endowment
Snorkel: Rapid training data creation with weak supervision , author=. Proceedings of the VLDB endowment. International conference on very large data bases , volume=
-
[4]
Proceedings of the AAAI conference on artificial intelligence , volume=
Training complex models with multi-task weak supervision , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[5]
International conference on machine learning , pages=
Fast and three-rious: Speeding up weak supervision with triplet methods , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[6]
2021 , url=
Jieyu Zhang and Yue Yu and Yinghao Li and Yujing Wang and Yaming Yang and Mao Yang and Alexander Ratner , booktitle=. 2021 , url=
2021
-
[7]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Stronger Than You Think: Benchmarking Weak Supervision on Realistic Tasks , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[8]
Training Classifiers with Natural Language Explanations
Hancock, Braden and Varma, Paroma and Wang, Stephanie and Bringmann, Martin and Liang, Percy and R \'e , Christopher. Training Classifiers with Natural Language Explanations. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1175
-
[9]
Proceedings of the VLDB Endowment
Snuba: Automating weak supervision to label training data , author=. Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases , volume=
-
[10]
Proceedings of the 2019 International Conference on Management of Data , pages=
Snorkel drybell: A case study in deploying weak supervision at industrial scale , author=. Proceedings of the 2019 International Conference on Management of Data , pages=
2019
-
[11]
Alfred: A System for Prompted Weak Supervision
Yu, Peilin and Bach, Stephen. Alfred: A System for Prompted Weak Supervision. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). 2023. doi:10.18653/v1/2023.acl-demo.46
-
[12]
Interactive Machine Teaching by Labeling Rules and Instances
Karamanolakis, Giannis and Hsu, Daniel and Gravaano, Luis. Interactive Machine Teaching by Labeling Rules and Instances. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00707
-
[13]
Large Language Models for Data Annotation and Synthesis: A Survey
Tan, Zhen and Li, Dawei and Wang, Song and Beigi, Alimohammad and Jiang, Bohan and Bhattacharjee, Amrita and Karami, Mansooreh and Li, Jundong and Cheng, Lu and Liu, Huan. Large Language Models for Data Annotation and Synthesis: A Survey. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emn...
-
[14]
Prompt Candidates, then Distill: A Teacher-Student Framework for LLM -driven Data Annotation
Xia, Mingxuan and Wang, Haobo and Li, Yixuan and Yu, Zewei and Wang, Jindong and Zhao, Junbo and Wu, Runze. Prompt Candidates, then Distill: A Teacher-Student Framework for LLM -driven Data Annotation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.139
-
[15]
and Ross, Mike and Minton, Steven N
Bibal, Adrien and Gerlek, Nathaniel and Muric, Goran and Boschee, Elizabeth and Fincke, Steven C. and Ross, Mike and Minton, Steven N. Automating Annotation Guideline Improvements using LLM s: A Case Study. Proceedings of Context and Meaning: Navigating Disagreements in NLP Annotation. 2025
2025
-
[16]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
DALL: Data Labeling via Data Programming and Active Learning Enhanced by Large Language Models , author=. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
2026
-
[17]
2021 , eprint=
Program Synthesis with Large Language Models , author=. 2021 , eprint=
2021
-
[18]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[19]
Thirty-seventh Conference on Neural Information Processing Systems , year=
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[20]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Wang, Yizhong and Kordi, Yeganeh and Mishra, Swaroop and Liu, Alisa and Smith, Noah A. and Khashabi, Daniel and Hajishirzi, Hannaneh. Self-Instruct: Aligning Language Models with Self-Generated Instructions. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.754
-
[21]
Advances in Neural Information Processing Systems , editor=
Generating Training Data with Language Models: Towards Zero-Shot Language Understanding , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[22]
Want To Reduce Labeling Cost? GPT -3 Can Help
Wang, Shuohang and Liu, Yang and Xu, Yichong and Zhu, Chenguang and Zeng, Michael. Want To Reduce Labeling Cost? GPT -3 Can Help. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.354
-
[23]
Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor
Honovich, Or and Scialom, Thomas and Levy, Omer and Schick, Timo. Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.806
-
[24]
Tzu-Heng Huang and Catherine Cao and Vaishnavi Bhargava and Frederic Sala , booktitle=. The. 2024 , url=
2024
-
[25]
, author=
DataSculpt: Cost-Efficient Label Function Design via Prompting Large Language Models. , author=. EDBT , pages=
-
[26]
Knowledge-Based Systems , pages=
Structured exploration and exploitation of label functions for automated data annotation , author=. Knowledge-Based Systems , pages=. 2026 , publisher=
2026
-
[27]
2025 , eprint=
WeShap: Weak Supervision Source Evaluation with Shapley Values , author=. 2025 , eprint=
2025
-
[28]
Sirui Hong and Mingchen Zhuge and Jonathan Chen and Xiawu Zheng and Yuheng Cheng and Jinlin Wang and Ceyao Zhang and Zili Wang and Steven Ka Shing Yau and Zijuan Lin and Liyang Zhou and Chenyu Ran and Lingfeng Xiao and Chenglin Wu and J. Meta. The Twelfth International Conference on Learning Representations , year=
-
[29]
AutoGen: Enabling Next-Gen
Qingyun Wu and Gagan Bansal and Jieyu Zhang and Yiran Wu and Beibin Li and Erkang Zhu and Li Jiang and Xiaoyun Zhang and Shaokun Zhang and Jiale Liu and Ahmed Hassan Awadallah and Ryen W White and Doug Burger and Chi Wang , booktitle=. AutoGen: Enabling Next-Gen. 2024 , url=
2024
-
[30]
C hat D ev: Communicative Agents for Software Development
Qian, Chen and Liu, Wei and Liu, Hongzhang and Chen, Nuo and Dang, Yufan and Li, Jiahao and Yang, Cheng and Chen, Weize and Su, Yusheng and Cong, Xin and Xu, Juyuan and Li, Dahai and Liu, Zhiyuan and Sun, Maosong. C hat D ev: Communicative Agents for Software Development. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguist...
-
[31]
2023 , url=
Guohao Li and Hasan Abed Al Kader Hammoud and Hani Itani and Dmitrii Khizbullin and Bernard Ghanem , booktitle=. 2023 , url=
2023
-
[32]
Zijun Liu and Yanzhe Zhang and Peng Li and Yang Liu and Diyi Yang , year=. Dynamic
-
[33]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Reflexion: language agents with verbal reinforcement learning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[34]
Transactions on Machine Learning Research , issn=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[35]
2024 , eprint=
MemGPT: Towards LLMs as Operating Systems , author=. 2024 , eprint=
2024
-
[36]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[37]
The Eleventh International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[38]
2026 , eprint=
EVOCHAMBER: Test-Time Co-evolution of Multi-Agent System at Individual, Team, and Population Scales , author=. 2026 , eprint=
2026
-
[39]
2026 , eprint=
Data Darwinism Part II: DataEvolve -- AI can Autonomously Evolve Pretraining Data Curation , author=. 2026 , eprint=
2026
-
[40]
2026 , eprint=
Data Darwinism Part I: Unlocking the Value of Scientific Data for Pre-training , author=. 2026 , eprint=
2026
-
[41]
E vo A gent: Towards Automatic Multi-Agent Generation via Evolutionary Algorithms
Yuan, Siyu and Song, Kaitao and Chen, Jiangjie and Tan, Xu and Li, Dongsheng and Yang, Deqing. E vo A gent: Towards Automatic Multi-Agent Generation via Evolutionary Algorithms. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 20...
-
[42]
Chi and Denny Zhou and Swaroop Mishra and Steven Zheng , booktitle=
Pei Zhou and Jay Pujara and Xiang Ren and Xinyun Chen and Heng-Tze Cheng and Quoc V Le and Ed H. Chi and Denny Zhou and Swaroop Mishra and Steven Zheng , booktitle=. 2024 , url=
2024
-
[43]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Self-Refine: Iterative Refinement with Self-Feedback , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[44]
2017 , url=
Overview of the BioCreative VI chemical-protein interaction Track , author=. 2017 , url=
2017
-
[45]
María Herrero-Zazo and Isabel Segura-Bedmar and Paloma Martínez and Thierry Declerck , keywords =. The DDI corpus: An annotated corpus with pharmacological substances and drug–drug interactions , journal =. 2013 , issn =. doi:https://doi.org/10.1016/j.jbi.2013.07.011 , url =
-
[46]
FEVER: a large-scale dataset for Fact Extraction and VERification
Thorne, James and Vlachos, Andreas and Christodoulopoulos, Christos and Mittal, Arpit. FEVER : a Large-scale Dataset for Fact Extraction and VER ification. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1074
work page internal anchor Pith review doi:10.18653/v1/n18-1074 2018
-
[47]
Get Your Vitamin C ! Robust Fact Verification with Contrastive Evidence
Schuster, Tal and Fisch, Adam and Barzilay, Regina. Get Your Vitamin C ! Robust Fact Verification with Contrastive Evidence. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.52
-
[48]
Fact or Fiction: Verifying Scientific Claims
Wadden, David and Lin, Shanchuan and Lo, Kyle and Wang, Lucy Lu and van Zuylen, Madeleine and Cohan, Arman and Hajishirzi, Hannaneh. Fact or Fiction: Verifying Scientific Claims. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.609
-
[49]
Character-level Convolutional Networks for Text Classification , url =
Zhang, Xiang and Zhao, Junbo and LeCun, Yann , booktitle =. Character-level Convolutional Networks for Text Classification , url =
-
[50]
Efficient Intent Detection with Dual Sentence Encoders
Casanueva, I \ n igo and Tem c inas, Tadas and Gerz, Daniela and Henderson, Matthew and Vuli \'c , Ivan. Efficient Intent Detection with Dual Sentence Encoders. Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI. 2020. doi:10.18653/v1/2020.nlp4convai-1.5
-
[51]
Hersh, William and Buckley, Chris and Leone, T. J. and Hickam, David. OHSUMED: An Interactive Retrieval Evaluation and New Large Test Collection for Research. SIGIR '94. 1994
1994
-
[52]
P ub M ed 200k RCT : a Dataset for Sequential Sentence Classification in Medical Abstracts
Dernoncourt, Franck and Lee, Ji Young. P ub M ed 200k RCT : a Dataset for Sequential Sentence Classification in Medical Abstracts. Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers). 2017
2017
-
[53]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[54]
2026 , howpublished =
2026
-
[55]
2026 , eprint=
OpenAI GPT-5 System Card , author=. 2026 , eprint=
2026
-
[56]
Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov , year=. Ro
-
[57]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[58]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[59]
Sentence-bert: Sentence embeddings using siamese bert-networks
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[60]
BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning , url =
Kirsch, Andreas and van Amersfoort, Joost and Gal, Yarin , booktitle =. BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning , url =
-
[61]
Mathematical programming , volume=
An analysis of approximations for maximizing submodular set functions—I , author=. Mathematical programming , volume=. 1978 , publisher=
1978
-
[62]
Pengcheng He and Jianfeng Gao and Weizhu Chen , booktitle=. De. 2023 , url=
2023
-
[63]
The Fourteenth International Conference on Learning Representations , year=
Darwin G\"odel Machine: Open-Ended Evolution of Self-Improving Agents , author=. The Fourteenth International Conference on Learning Representations , year=
-
[64]
2026 , eprint=
Hyperagents , author=. 2026 , eprint=
2026
-
[65]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle =. Lo. 2022 , url =
2022
-
[66]
, title =
Xie, Qizhe and Luong, Minh-Thang and Hovy, Eduard and Le, Quoc V. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[67]
Wang, Shaobo and Ouyang, Xuan and Xu, Tianyi and Hu, Yuzheng and Liu, Jialin and Chen, Guo and Zhang, Tianyu and Zheng, Junhao and Yang, Kexin and Ren, Xingzhang and Liu, Dayiheng and Zhang, Linfeng , year=. 2602.05400 , archivePrefix=
-
[68]
London: John Murray , year=
On the origin of species by means of natural selection, or the preservation of favoured races in the struggle for life , author=. London: John Murray , year=
-
[69]
, author=
Philosophie zoologique... , author=. 1873 , publisher=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.