ReSkill: Reconciling Skill Creation with Policy Optimization in Agentic RL
Pith reviewed 2026-06-28 14:47 UTC · model grok-4.3
The pith
ReSkill embeds skill creation inside policy optimization so skills evolve with the agent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
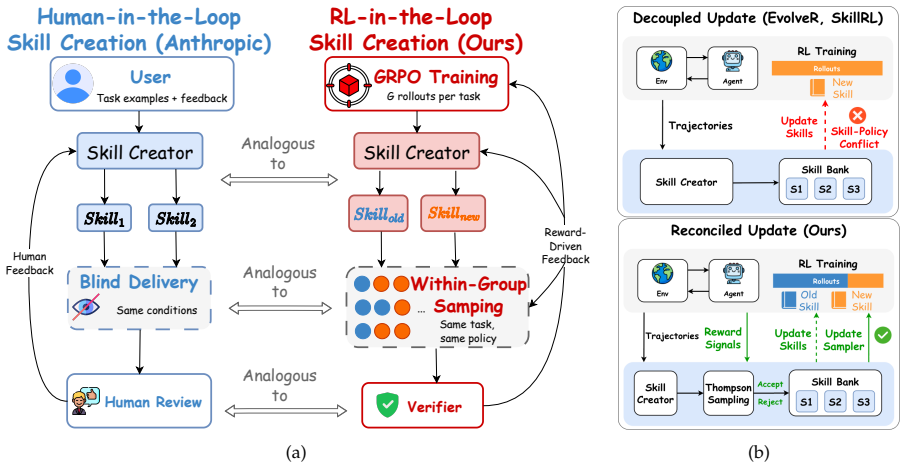
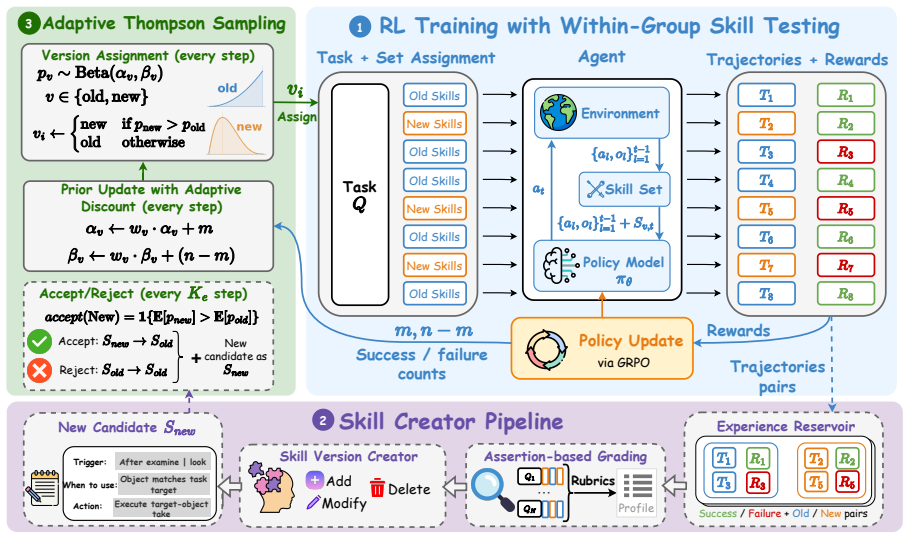
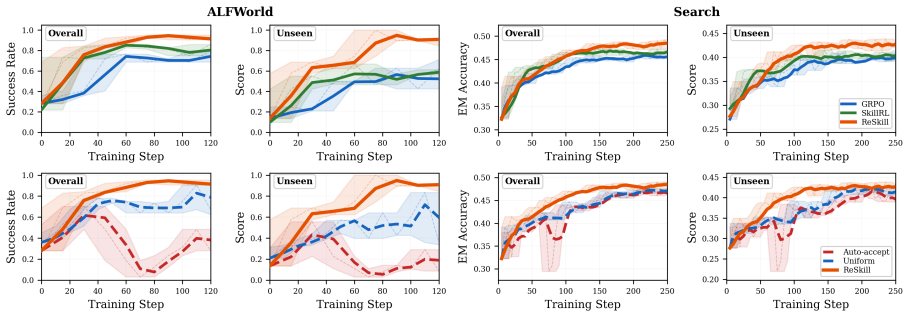
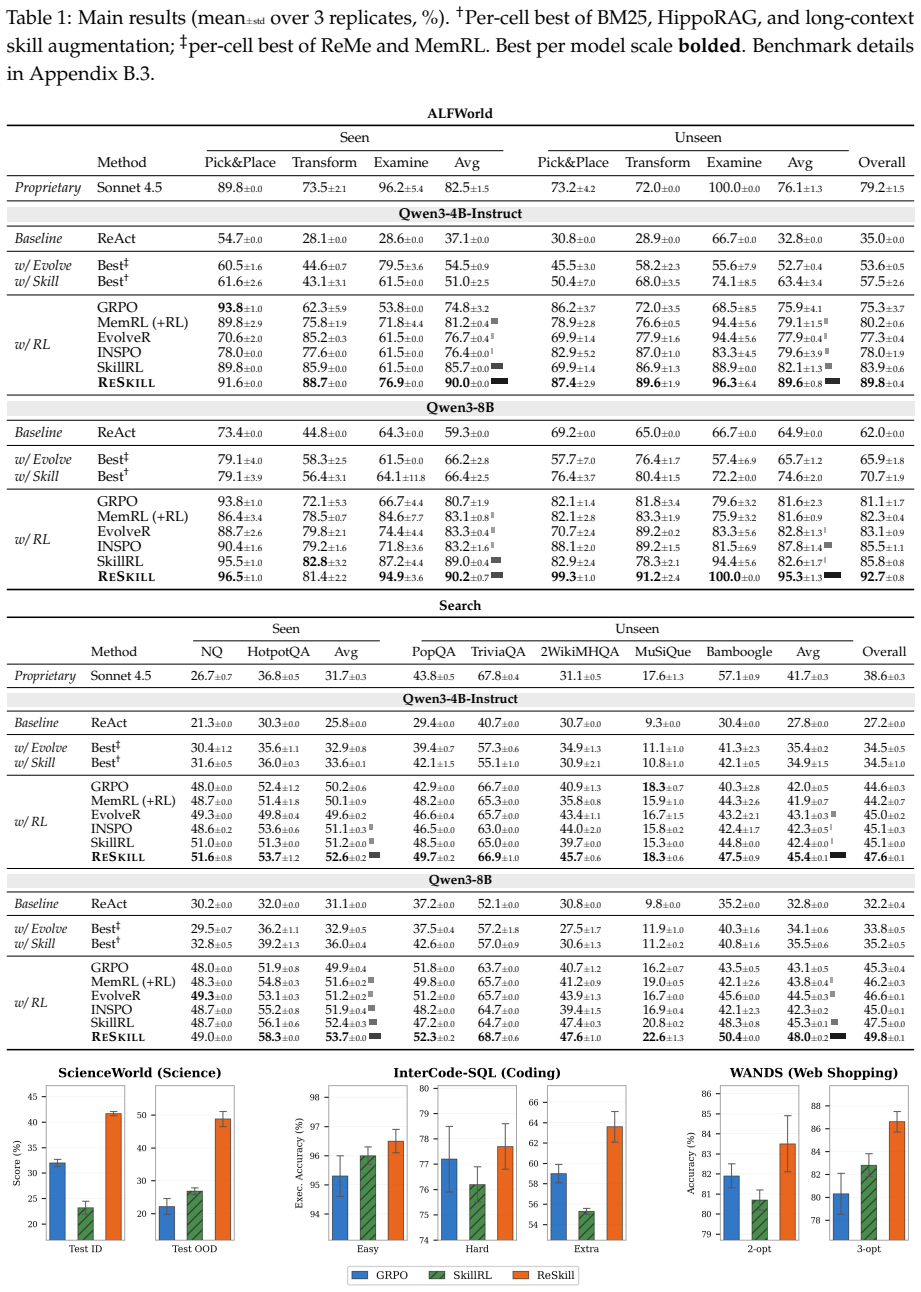
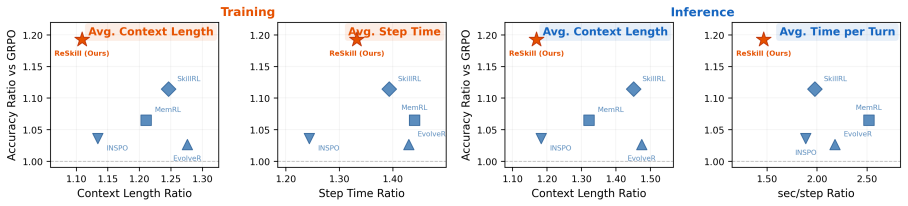
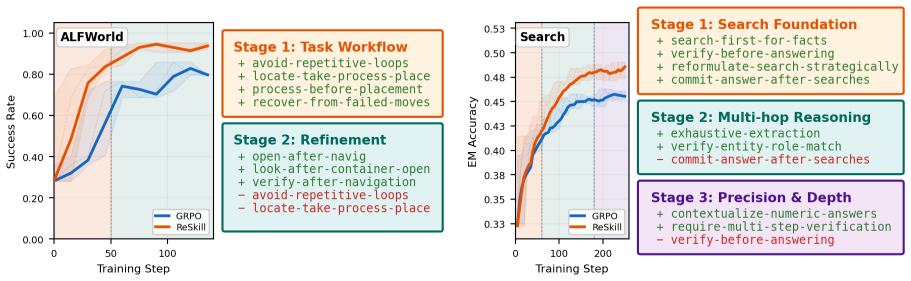
ReSkill is an RL-in-the-loop skill creation framework that reconciles skill evolution with policy learning by exploiting the group-wise structure of GRPO to embed three mechanisms with marginal overhead: an assertion-driven skill creator that diagnoses failures and proposes conditional trigger-based revisions, within-group rollout sampling that compares skill versions during learning, and Thompson Sampling with adaptive discounting that balances exploration and exploitation in skill selection. Across domains this produces consistent outperformance over memory and skill-based RL baselines, with the largest gains on unseen tasks, while skills are created, tested, refined, and pruned automatica
What carries the argument
The group-wise structure of GRPO that naturally embeds the assertion-driven creator, within-group sampling, and Thompson Sampling with adaptive discounting.
If this is right
- Skills are created automatically from diagnoses of past failures.
- Within-group sampling allows direct comparison of skill versions during rollouts.
- Thompson Sampling with adaptive discounting selects skill versions while the policy changes.
- ReSkill outperforms existing memory and skill-based RL methods, with largest gains on unseen tasks.
- Skills are created, tested, refined, and pruned as the policy improves.
Where Pith is reading between the lines
- The same embedding idea could extend to other group-based RL methods if they support controlled version comparison.
- Agents might sustain longer task horizons by growing a library of trigger-based skills without external memory modules.
- The co-evolution dynamic could be tested by measuring how often pruned skills are later re-proposed after policy shifts.
- Environments with greater non-stationarity would stress-test whether adaptive discounting prevents premature skill fixation.
Load-bearing premise
The group-wise structure of GRPO can embed the three mechanisms without introducing conflicts as the policy evolves.
What would settle it
A controlled experiment on one of the paper's benchmarks in which enabling the three embedded mechanisms causes average policy return to fall below the no-skill-creation baseline.
Figures

read the original abstract
Agentic reinforcement learning (RL) enables LLM agents to improve continuously from environment rewards, yet the resulting policies do not systematically accumulate reusable strategies that generalize across tasks. Modular skills can provide such reusable strategies, yet existing skill-augmented RL methods decouple skill creation from policy optimization, risking adopting skills that conflict with the evolving policy. Inspired by Anthropic's Skill Creator, we introduce ReSkill, an RL-in-the-loop skill creation framework that reconciles skill evolution with policy learning. ReSkill exploits the group-wise structure of GRPO to naturally embed three mechanisms with only marginal additional overhead: (1) an assertion-driven skill creator that diagnoses failures from past experience and proposes conditional, trigger-based skill revisions; (2) within-group rollout sampling that enables controlled comparison of skill versions, capturing which version best supports the policy's ongoing learning; and (3) Thompson Sampling with adaptive discounting to balance exploration and exploitation in skill version selection as the policy evolves. Across several domains, ReSkill consistently outperforms existing memory and skill-based RL methods, with the largest gains on unseen tasks. Analysis of the skill lifecycle shows skills being automatically created, tested, refined, and pruned as the policy improves, demonstrating reconciled skill-policy co-evolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ReSkill, an RL-in-the-loop skill creation framework for agentic RL that reconciles skill evolution with policy optimization. It exploits GRPO's group-wise rollouts to embed three mechanisms—an assertion-driven skill creator that proposes conditional revisions from failure diagnoses, within-group sampling for controlled version comparison, and Thompson Sampling with adaptive discounting for version selection—claiming only marginal overhead. The work reports consistent outperformance over memory and skill-based RL baselines, with largest gains on unseen tasks, alongside automatic skill creation, testing, refinement, and pruning as the policy improves.
Significance. If the claimed integration of the three mechanisms into GRPO proceeds without selection bias or policy-skill conflicts, the result would address a central limitation of prior skill-augmented RL by enabling systematic accumulation of reusable, generalizable strategies. The design choice to leverage an existing group-wise structure rather than introduce separate skill and policy loops is a conceptual strength that could reduce overhead if empirically validated.
major comments (2)
- [Abstract] Abstract: the central claim that the three mechanisms 'naturally embed' into GRPO's group-wise structure 'with only marginal additional overhead' and 'without introducing conflicts' is load-bearing for the reconciled co-evolution result, yet the text provides no derivation or analysis showing that (a) failure assertions can be computed from within-group trajectories without altering advantage estimates, (b) version sampling remains unbiased during ongoing policy updates, or (c) the adaptive discount in Thompson Sampling does not interact with GRPO group normalization.
- [Abstract] The reported largest gains on unseen tasks are presented as evidence that skills generalize via reconciled co-evolution, but without explicit checks that within-group version comparison avoids favoring revisions that merely exploit transient policy states, the gains could be artifacts of the particular GRPO implementation rather than a general property of the framework.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where we will revise the manuscript to strengthen the presentation of the framework's properties.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the three mechanisms 'naturally embed' into GRPO's group-wise structure 'with only marginal additional overhead' and 'without introducing conflicts' is load-bearing for the reconciled co-evolution result, yet the text provides no derivation or analysis showing that (a) failure assertions can be computed from within-group trajectories without altering advantage estimates, (b) version sampling remains unbiased during ongoing policy updates, or (c) the adaptive discount in Thompson Sampling does not interact with GRPO group normalization.
Authors: We agree that the abstract's claims would be strengthened by explicit analysis. The design computes assertions only after full group trajectories are collected, leaving GRPO advantage estimates unchanged; version sampling draws from a separate historical performance buffer updated between policy steps; and the adaptive discount modulates only the prior over skill versions, independent of intra-group normalization. We will add a short formal subsection in Section 3 deriving these separation properties. revision: yes
-
Referee: [Abstract] The reported largest gains on unseen tasks are presented as evidence that skills generalize via reconciled co-evolution, but without explicit checks that within-group version comparison avoids favoring revisions that merely exploit transient policy states, the gains could be artifacts of the particular GRPO implementation rather than a general property of the framework.
Authors: The within-group design ensures that all skill versions are evaluated under identical policy parameters and environment conditions for that rollout batch, which directly controls for transient state effects. The larger gains on unseen tasks are therefore measured under this controlled comparison. We will add a paragraph and supplementary figure in Section 4 clarifying this control and showing version-selection stability across consecutive policy updates. revision: partial
Circularity Check
No circularity: framework leverages external GRPO structure without self-referential reductions
full rationale
The paper proposes ReSkill as an integration that exploits the pre-existing group-wise structure of GRPO to embed assertion-driven creation, within-group sampling, and Thompson Sampling. No equations, fitted parameters, or derivations are shown that reduce by construction to their own inputs. The approach is explicitly inspired by external Anthropic work rather than self-citation chains, and performance claims rest on empirical results across domains rather than any uniqueness theorem or ansatz smuggled via prior author work. The derivation chain is therefore self-contained as a proposed engineering reconciliation rather than a tautological re-labeling or statistical forcing.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural Bandit Based Optimal LLM Selection for a Pipeline of Subtasks
GitHub repository. Baran Atalar, Eddie Zhang, and Carlee Joe-Wong. Neural bandit based optimal LLM selection for a pipeline of tasks.arXiv preprint arXiv:2508.09958, 2025. Djallel Bouneffouf and Raphael Feraud. Survey: Multi-armed bandits meet large language models, 2025. URLhttps://arxiv.org/abs/2505.13355. Zouying Cao, Jiaji Deng, Li Yu, Weikang Zhou, Z...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
URLhttps://arxiv.org/abs/2506.11425. Xiangxiang Dai, Jin Li, Xutong Liu, Anqi Yu, and John Lui. Cost-effective online multi-LLM selection with versatile reward models.arXiv preprint arXiv:2405.16587, 2024. Jiazhan Feng, Shang Huang, Xin Qu, Ge Zhang, Yujia Qin, Bing Zhong, Chaojie Jiang, Jiangjie Chi, and Weiwen Zhong. Retool: Reinforcement learning for s...
-
[3]
URLhttps://arxiv.org/abs/2505.16421. 13 Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, et al. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079, 2025. Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Si...
-
[4]
guiding principles
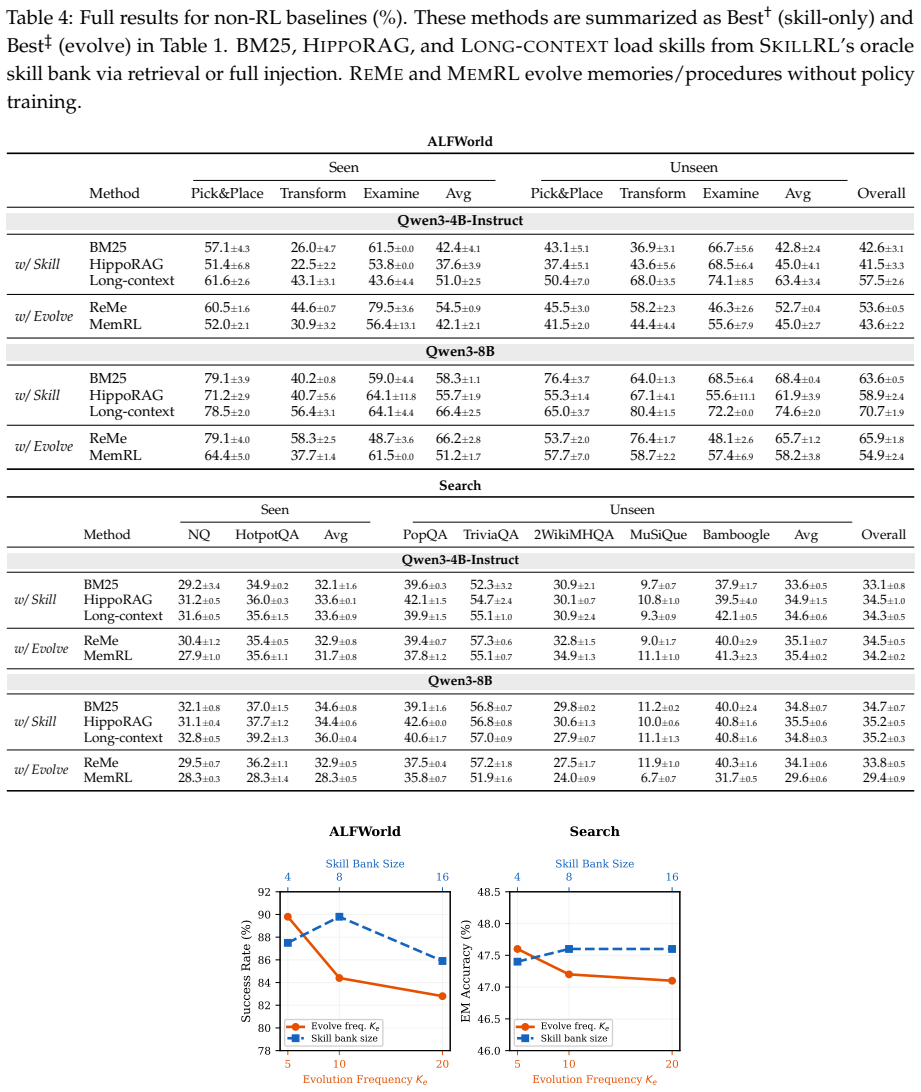
prompts the base model with a reasoning-plus-action format, interleaving chain-of-thought traces with environment actions.Claude Sonnet 4.5uses the same ReAct prompt under identical evaluation protocols, serving as a proprietary reference. Evolvement Methods.REME(Cao et al., 2025) is a dynamic procedural memory framework that extracts, stores, and retriev...
2025
-
[5]
The trigger condition serves the routing role, andwhen_to_useserves the relevance-filtering role
In-context applicability: The when_to_use field tells the policy when the loaded guidance should be followed. The trigger condition serves the routing role, andwhen_to_useserves the relevance-filtering role. C.4.3 Trigger Validation and Optimization Motivated by Skill Creator’s description optimization phase, we validate proposed triggers before the versi...
-
[6]
Initializeα 0 =1,β p,0 =1 (uniform Beta(1, 1)prior)
-
[7]
,T: (a) Discount: ˜αt = M M+nt ·α t−1, ˜βp,t = M M+nt ·β p,t−1
Fort=1, . . . ,T: (a) Discount: ˜αt = M M+nt ·α t−1, ˜βp,t = M M+nt ·β p,t−1. (b) Score:ℓ t =logP(m t |n t, ˜αt, ˜βp,t)(Eq. 11). (c) Update:α t = ˜αt +m t,β p,t = ˜βp,t + (nt −m t)
-
[8]
insight":
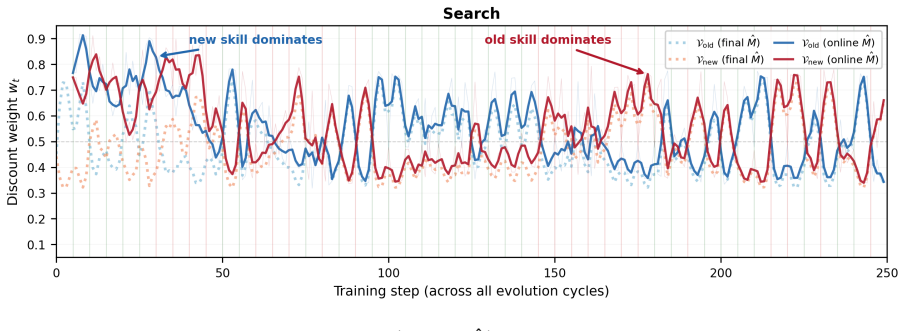
Returnℓ(M;d) = ∑T t=1 ℓt. 22 Figure 8: Per-arm discount weights wt = 1/(1 +n t/ ˆM) during training on Search. Solid lines use the online ˆMk; dotted lines use the final ˆM. The two arms’ weights are anti-correlated: Thompson Sampling allocates more episodes to the favored arm, lowering its wt (more forgetting), while the minority arm retains more history...
2000
-
[9]
search[Iittala bowl white porcelain] [2] click[w21216]
limit-search-retriesfires. search[Iittala bowl white porcelain] [2] click[w21216]
-
[10]
click[back to search]
require-color-selectionfires — white NOT in available colors. click[back to search]
-
[11]
click[w19864]
no-description-tabsprevents tab exploration. click[w19864]
-
[12]
I am applying the skill:require-color-selectionbecause the task specifies ‘color: white’ and the color dropdown is visible
require-color-selectionfires — white IS available. “I am applying the skill:require-color-selectionbecause the task specifies ‘color: white’ and the color dropdown is visible.” click[color: white]
-
[13]
click[material: porcelain china]
no-back-after-optionsfires. click[material: porcelain china]
-
[14]
Count the number of countries in Asia
buy-immediately-after-optionsfires. click[buy now] SUCCESS Five distinct skills compose into a conditional state machine with branching: require-color-selection plays a dual role, blocking premature purchase when color is available but providing the only legitimate escape when color is unavailable. F.5 InterCode-SQL Structured Verification Database:world_...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.