AlphaToken: Decoupling Adaptation and Stability for Path-Aware Response Token Valuation in LLM Post-Training
Pith reviewed 2026-06-28 15:22 UTC · model grok-4.3
The pith
AlphaToken values response tokens by separating adaptation from stability with path-aware signals to guide masking in LLM post-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
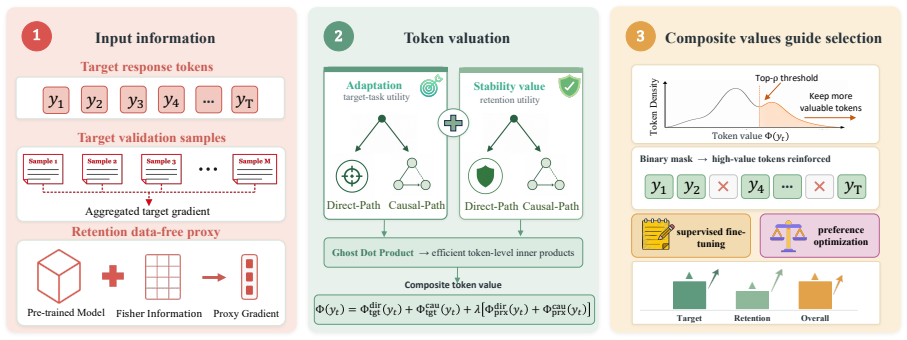
AlphaToken decouples adaptation and stability for path-aware response token valuation by combining direct-path gradients with downstream causal-path signals in autoregressive generation and approximates stability via a Fisher-drift proxy anchored at the pre-trained reference model. The resulting token values are used to mask low-value response tokens during fine-tuning and preference optimization, thereby concentrating training signals on more valuable positions.
What carries the argument
AlphaToken token valuation that decouples adaptation and stability objectives, computes each with direct and causal path signals, and uses a Fisher-drift proxy for stability together with Ghost Dot-Product for token-level efficiency.
If this is right
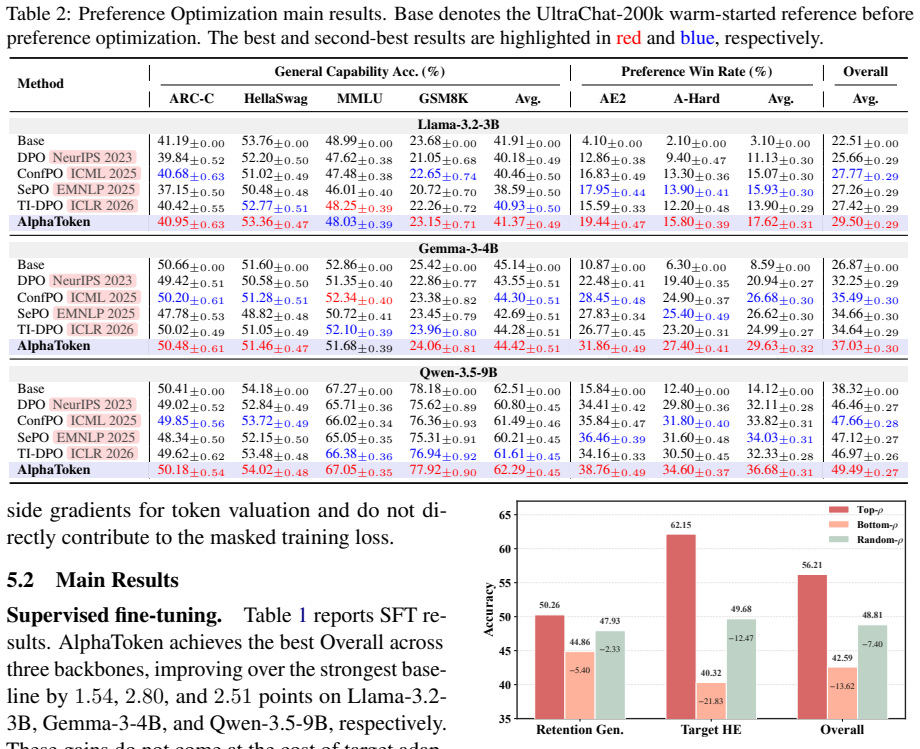
- Masking low-value tokens improves target-task performance in both supervised fine-tuning and preference optimization.
- The same masking step reduces loss of pre-trained capabilities compared with unmasked baselines.
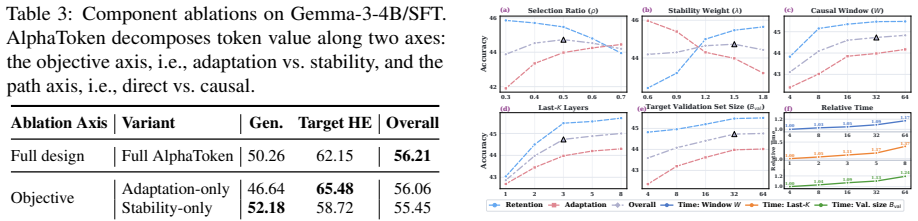
- Path-aware combination of direct and causal signals yields more effective token values than local heuristics alone.
- The Fisher-drift approximation enables the method to operate in standard post-training pipelines that lack retention data.
Where Pith is reading between the lines
- The decoupling could be tested at earlier training stages such as continued pre-training to stabilize updates over longer horizons.
- Varying the relative weighting of adaptation and stability terms might reveal task-specific optima for different domains.
- Extending the proxy to track drift relative to multiple checkpoints could handle non-stationary training dynamics.
Load-bearing premise
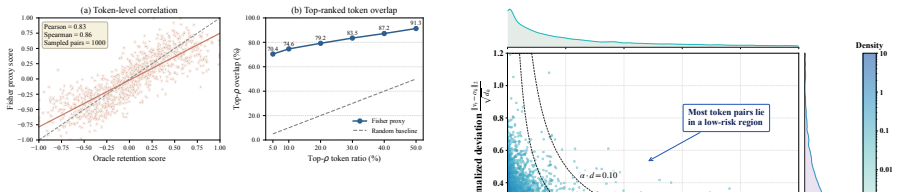
Stability can be adequately approximated by a Fisher-drift proxy anchored at the pre-trained reference model without retention data.
What would settle it
A controlled comparison in which models trained with AlphaToken masking show neither higher target-task performance nor lower catastrophic forgetting than identical training without the masking step.
Figures

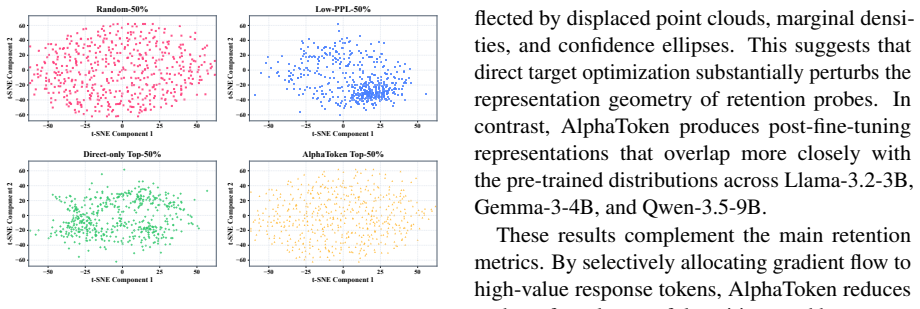
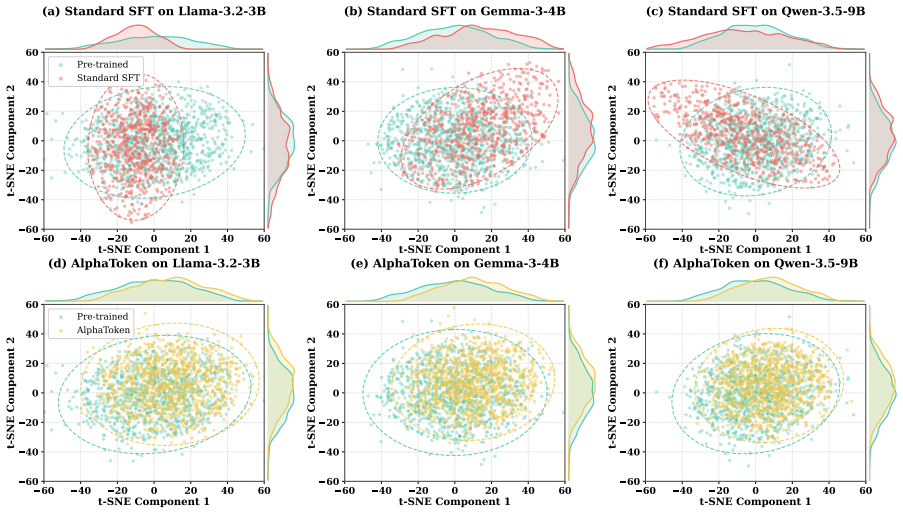

read the original abstract
Token selection is pivotal for effective LLM post-training. However, existing methods mostly rely on local heuristics and rarely formulate token selection as a principled valuation of individual response tokens. We introduce $\textbf{AlphaToken}$, a response token valuation framework that decouples valuation into $\textbf{adaptation}$ (promoting target-task learning) and $\textbf{stability}$ (preserving pre-trained capabilities), and makes each objective $\textbf{path-aware}$ by combining the direct-path signal from local token gradients with the downstream causal-path signal in autoregressive generation. Since retention data are typically unavailable, AlphaToken approximates stability via a $\textbf{Fisher-drift proxy}$ anchored at the pre-trained reference model. For efficient computation, we extend Ghost Dot-Product to token-level valuation. AlphaToken masks low-value response tokens during fine-tuning and preference optimization, concentrating training signals on more valuable positions. Experiments show that AlphaToken improves post-training performance and mitigates catastrophic forgetting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AlphaToken, a response token valuation framework for LLM post-training that decouples adaptation (promoting target-task learning via direct-path gradients) from stability (preserving pre-trained capabilities), with both made path-aware by incorporating downstream causal-path signals in autoregressive generation. Stability is approximated via a Fisher-drift proxy anchored at the pre-trained reference model, since retention data are unavailable. The method extends Ghost Dot-Product for efficient token-level computation, then masks low-value tokens during fine-tuning and preference optimization to concentrate training signals. Experiments are claimed to show improved post-training performance and mitigation of catastrophic forgetting.
Significance. If the Fisher-drift proxy proves reliable, the framework could provide a more principled, path-aware alternative to heuristic token selection in post-training, with potential benefits for both task performance and capability retention. The decoupling and Ghost Dot-Product extension represent concrete technical contributions once the proxy is granted.
major comments (2)
- [Abstract] Abstract: The central claim that masking via the combined path-aware valuation 'mitigates catastrophic forgetting' rests on the Fisher-drift proxy being a faithful surrogate for retention of pre-trained capabilities. No equivalence proof, correlation study against held-out retention data, or ablation validating the proxy's predictive power is supplied; the proxy is motivated solely by data absence rather than shown to correlate with actual stability. This is load-bearing for the stability term and the forgetting-mitigation result.
- [Abstract] Abstract / Method: The path-aware construction (direct-path + downstream causal-path) and Ghost Dot-Product extension are well-defined once the proxy is accepted, but the manuscript provides no quantitative evidence that the resulting token valuations outperform simpler baselines (e.g., gradient magnitude alone) on both adaptation and stability metrics simultaneously.
minor comments (1)
- Abstract: No details on experimental setup (datasets, baselines, metrics, or statistical significance) are visible, making it impossible to assess the claimed performance gains.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments highlighting the need for stronger validation of the Fisher-drift proxy and explicit baseline comparisons. We address each point below and commit to revisions that strengthen the empirical grounding without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that masking via the combined path-aware valuation 'mitigates catastrophic forgetting' rests on the Fisher-drift proxy being a faithful surrogate for retention of pre-trained capabilities. No equivalence proof, correlation study against held-out retention data, or ablation validating the proxy's predictive power is supplied; the proxy is motivated solely by data absence rather than shown to correlate with actual stability. This is load-bearing for the stability term and the forgetting-mitigation result.
Authors: We agree the proxy is an approximation justified by the unavailability of retention data rather than direct validation. The manuscript presents it as a practical surrogate derived from Fisher information at the reference model, not as a proven equivalent. Experiments show empirical reductions in forgetting metrics when the proxy is used. In revision we will add a limitations subsection discussing the proxy's assumptions, include an ablation isolating its contribution to stability, and clarify that forgetting mitigation is demonstrated empirically rather than via formal equivalence. revision: partial
-
Referee: [Abstract] Abstract / Method: The path-aware construction (direct-path + downstream causal-path) and Ghost Dot-Product extension are well-defined once the proxy is accepted, but the manuscript provides no quantitative evidence that the resulting token valuations outperform simpler baselines (e.g., gradient magnitude alone) on both adaptation and stability metrics simultaneously.
Authors: The current experiments compare AlphaToken against prior token-selection methods and report gains on both task performance and forgetting. However, we acknowledge the absence of a direct head-to-head ablation against gradient magnitude alone for the combined adaptation-stability valuation. We will add this ablation in the revision, reporting adaptation and stability metrics for the full path-aware valuation versus gradient magnitude and other simple heuristics. revision: yes
Circularity Check
No significant circularity; derivation self-contained via explicit proxy and gradient definitions
full rationale
The paper introduces AlphaToken by explicitly decoupling adaptation (target-task gradients) from stability (Fisher-drift proxy anchored at pre-trained model) because retention data are unavailable; this is presented as an approximation rather than a quantity fitted to or defined from the evaluation data. Path-aware signals combine direct local gradients with downstream causal paths in autoregressive generation, with no equations shown reducing either term to the other or to the final masking outcome by construction. No self-citations are load-bearing for the central premise, and the Ghost Dot-Product extension is a computational device. The method therefore rests on independent empirical validation rather than internal equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradient signals at a token can be meaningfully combined with downstream causal effects to produce a scalar token value.
invented entities (1)
-
Fisher-drift proxy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Thirteenth International Conference on Learning Representations , year=
Data Shapley in One Training Run , author=. The Thirteenth International Conference on Learning Representations , year=
-
[2]
International conference on machine learning , pages=
Understanding black-box predictions via influence functions , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[3]
Advances in neural information processing systems , volume=
A unified approach to interpreting model predictions , author=. Advances in neural information processing systems , volume=
-
[4]
International conference on machine learning , pages=
Data shapley: Equitable valuation of data for machine learning , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[5]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[6]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[7]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[8]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=. 2017 , publisher=
2017
-
[9]
IEEE transactions on pattern analysis and machine intelligence , volume=
Learning without forgetting , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2017 , publisher=
2017
-
[10]
Token Cleaning: Fine-Grained Data Selection for
Jinlong Pang and Na Di and Zhaowei Zhu and Jiaheng Wei and Hao Cheng and Chen Qian and Yang Liu , booktitle=. Token Cleaning: Fine-Grained Data Selection for
-
[11]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Memory-efficient fine-tuning of transformers via token selection , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[12]
Advances in neural information processing systems , volume=
Deep learning on a data diet: Finding important examples early in training , author=. Advances in neural information processing systems , volume=
-
[13]
International Conference on Machine Learning , pages=
Grad-match: Gradient matching based data subset selection for efficient deep model training , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[14]
arXiv preprint arXiv:2602.01227 , year=
Supervised Fine-Tuning Needs to Unlock the Potential of Token Priority , author=. arXiv preprint arXiv:2602.01227 , year=
-
[15]
International conference on machine learning , pages=
Learning to reweight examples for robust deep learning , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[16]
Advances in neural information processing systems , volume=
Meta-weight-net: Learning an explicit mapping for sample weighting , author=. Advances in neural information processing systems , volume=
-
[17]
International Conference on Learning Representations , year=
An Empirical Study of Example Forgetting during Deep Neural Network Learning , author=. International Conference on Learning Representations , year=
-
[18]
arXiv preprint arXiv:2601.09195 , year=
ProFit: Leveraging High-Value Signals in SFT via Probability-Guided Token Selection , author=. arXiv preprint arXiv:2601.09195 , year=
-
[19]
The Fourteenth International Conference on Learning Representations , year=
How Do Transformers Learn to Associate Tokens: Gradient Leading Terms Bring Mechanistic Interpretability , author=. The Fourteenth International Conference on Learning Representations , year=
-
[20]
ssToken: Self-modulated and Semantic-aware Token Selection for
Xiaohan Qin and Xiaoxing Wang and Ning Liao and Cancheng Zhang and Xiangdong Zhang and Mingquan Feng and Jingzhi Wang and Junchi Yan , booktitle=. ssToken: Self-modulated and Semantic-aware Token Selection for
-
[21]
arXiv preprint arXiv:2510.07118 , year=
TRIM: Token-wise Attention-Derived Saliency for Data-Efficient Instruction Tuning , author=. arXiv preprint arXiv:2510.07118 , year=
-
[22]
arXiv preprint arXiv:2509.23873 , year=
Winning the pruning gamble: A unified approach to joint sample and token pruning for efficient supervised fine-tuning , author=. arXiv preprint arXiv:2509.23873 , year=
-
[23]
arXiv preprint arXiv:2512.21017 , year=
Rethinking Supervised Fine-Tuning: Emphasizing Key Answer Tokens for Improved LLM Accuracy , author=. arXiv preprint arXiv:2512.21017 , year=
-
[24]
The Fourteenth International Conference on Learning Representations , year=
Token-Importance Guided Direct Preference Optimization , author=. The Fourteenth International Conference on Learning Representations , year=
-
[25]
The 22nd international conference on artificial intelligence and statistics , pages=
Towards efficient data valuation based on the shapley value , author=. The 22nd international conference on artificial intelligence and statistics , pages=. 2019 , organization=
2019
-
[26]
International Conference on Artificial Intelligence and Statistics , pages=
Beta Shapley: a Unified and Noise-reduced Data Valuation Framework for Machine Learning , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2022 , organization=
2022
-
[27]
Advances in Neural Information Processing Systems , volume=
Robust data valuation with weighted banzhaf values , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Mitigating Forgetting in
Chao-Chung Wu and Zhi Rui Tam and Chieh-Yen Lin and Yun-Nung Chen and Shao-Hua Sun and Hung-yi Lee , booktitle=. Mitigating Forgetting in
-
[29]
Advances in Neural Information Processing Systems , volume=
Not all tokens are what you need for pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
IEEE Signal Processing Letters , year=
Large model empowered multi-modal semantic communication with selective tokens for training , author=. IEEE Signal Processing Letters , year=
-
[31]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Token-level self-play with importance-aware guidance for large language models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[32]
2020 25th International Conference on Pattern Recognition (ICPR) , pages=
A multilinear sampling algorithm to estimate shapley values , author=. 2020 25th International Conference on Pattern Recognition (ICPR) , pages=. 2021 , organization=
2020
-
[33]
Journal of Machine Learning Research , volume=
Sampling permutations for shapley value estimation , author=. Journal of Machine Learning Research , volume=
-
[34]
International conference on artificial intelligence and statistics , pages=
Data banzhaf: A robust data valuation framework for machine learning , author=. International conference on artificial intelligence and statistics , pages=. 2023 , organization=
2023
-
[35]
International Conference on Learning Representations , year=
Influence Functions in Deep Learning Are Fragile , author=. International Conference on Learning Representations , year=
-
[36]
Advances in Neural Information Processing Systems , volume=
A bayesian approach to analysing training data attribution in deep learning , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Proceedings of the VLDB Endowment , volume=
Efficient task-specific data valuation for nearest neighbor algorithms , author=. Proceedings of the VLDB Endowment , volume=. 2019 , publisher=
2019
-
[38]
International Conference on Machine Learning , pages=
A distributional framework for data valuation , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[39]
Federated Learning: Privacy and Incentive , pages=
A principled approach to data valuation for federated learning , author=. Federated Learning: Privacy and Incentive , pages=. 2020 , publisher=
2020
-
[40]
The journal of machine learning research , volume=
A kernel two-sample test , author=. The journal of machine learning research , volume=. 2012 , publisher=
2012
-
[41]
The Twelfth International Conference on Learning Representations , year=
Detecting Machine-Generated Texts by Multi-Population Aware Optimization for Maximum Mean Discrepancy , author=. The Twelfth International Conference on Learning Representations , year=
-
[42]
2025 6th International Conference on Computer Vision and Data Mining (ICCVDM) , pages=
Federated fine-tuning of large language models with privacy preservation and cross-domain semantic alignment , author=. 2025 6th International Conference on Computer Vision and Data Mining (ICCVDM) , pages=. 2025 , organization=
2025
-
[43]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[44]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[45]
Qwen3.5: Towards Native Multimodal Agents , author =
-
[46]
Proceedings of the Conference on Health, Inference, and Learning , pages =
MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering , author =. Proceedings of the Conference on Health, Inference, and Learning , pages =. 2022 , volume =
2022
-
[47]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[48]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[49]
Commonsenseqa: A question answering challenge targeting commonsense knowledge , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
-
[50]
2023 , publisher =
OpenHermes 2.5: An Open Dataset of Synthetic Data for Generalist LLM Assistants , author =. 2023 , publisher =
2023
-
[51]
Explainable Token-level Noise Filtering for
Yuchen Yang and Wenze Lin and Enhao Huang and Zhixuan Chu and Hongbin zhou and Lan Tao and Yiming Li and Zhan Qin and Kui Ren , booktitle=. Explainable Token-level Noise Filtering for
-
[52]
The Thirteenth International Conference on Learning Representations , year=
Capturing the Temporal Dependence of Training Data Influence , author=. The Thirteenth International Conference on Learning Representations , year=
-
[53]
Proceedings of the 34th ACM International Conference on Information and Knowledge Management , pages=
LiveVal: Real-time and Trajectory-based Data Valuation via Adaptive Reference Points , author=. Proceedings of the 34th ACM International Conference on Information and Knowledge Management , pages=
-
[54]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[55]
2023 , publisher=
Stanford alpaca: An instruction-following llama model , author=. 2023 , publisher=
2023
-
[56]
Forty-first International Conference on Machine Learning , year=
Dora: Weight-decomposed low-rank adaptation , author=. Forty-first International Conference on Machine Learning , year=
-
[57]
Advances in Neural Information Processing Systems , volume=
Selectit: Selective instruction tuning for llms via uncertainty-aware self-reflection , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Capturing the Temporal Dependence of Training Data Influence , author=
-
[59]
Advances in Neural Information Processing Systems , volume=
Greats: Online selection of high-quality data for llm training in every iteration , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Scalable Valuation of Human Feedback through Provably Robust Model Alignment , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[61]
arXiv preprint arXiv:2410.05102 , year=
Sparsepo: Controlling preference alignment of llms via sparse token masks , author=. arXiv preprint arXiv:2410.05102 , year=
-
[62]
Hasegawa-Johnson and Sungwoong Kim and Chang D
Hee Suk Yoon and Eunseop Yoon and Mark A. Hasegawa-Johnson and Sungwoong Kim and Chang D. Yoo , booktitle=. Conf
-
[63]
Magicoder: Empowering Code Generation with
Yuxiang Wei and Zhe Wang and Jiawei Liu and Yifeng Ding and LINGMING ZHANG , booktitle=. Magicoder: Empowering Code Generation with
-
[64]
Mengzhou Xia and Sadhika Malladi and Suchin Gururangan and Sanjeev Arora and Danqi Chen , booktitle=
-
[65]
GitHub Repository , howpublished =
Alvaro Bartolome and Gabriel Martin and Daniel Vila , title =. GitHub Repository , howpublished =. 2023 , publisher =
2023
-
[66]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[67]
Hashimoto , title =
Xuechen Li and Tianyi Zhang and Yann Dubois and Rohan Taori and Ishaan Gulrajani and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , month =
2023
-
[68]
Gonzalez and Ion Stoica , month =
Tianle Li and Wei-Lin Chiang and Evan Frick and Lisa Dunlap and Banghua Zhu and Joseph E. Gonzalez and Ion Stoica , month =. From Live Data to High-Quality Benchmarks: The
-
[69]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Hellaswag: Can a machine really finish your sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[70]
Social IQa: Commonsense reasoning about social interactions , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[71]
arXiv preprint arXiv:2110.14168 , year =
Training verifiers to solve math word problems , author =. arXiv preprint arXiv:2110.14168 , year =
-
[72]
arXiv preprint arXiv:1803.05457 , year =
Think you have solved question answering? try arc, the ai2 reasoning challenge , author =. arXiv preprint arXiv:1803.05457 , year =
-
[73]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
TokenShapley: Token Level Context Attribution with Shapley Value , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[74]
Proceedings of the 1st Workshop on NLP for Science (NLP4Science) , pages=
Tokenshap: Interpreting large language models with monte carlo shapley value estimation , author=. Proceedings of the 1st Workshop on NLP for Science (NLP4Science) , pages=
-
[75]
Forty-second International Conference on Machine Learning , year=
Upweighting Easy Samples in Fine-Tuning Mitigates Forgetting , author=. Forty-second International Conference on Machine Learning , year=
-
[76]
Journal of Machine Learning Research , volume=
New insights and perspectives on the natural gradient method , author=. Journal of Machine Learning Research , volume=
-
[77]
Advances in neural information processing systems , volume=
Limitations of the empirical fisher approximation for natural gradient descent , author=. Advances in neural information processing systems , volume=
-
[78]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Enhancing chat language models by scaling high-quality instructional conversations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[79]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Selective preference optimization via token-level reward function estimation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[80]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wortsman, Mitchell and Ilharco, Gabriel and Kim, Jong Wook and Li, Mike and Kornblith, Simon and Roelofs, Rebecca and Lopes, Raphael Gontijo and Hajishirzi, Hannaneh and Farhadi, Ali and Namkoong, Hongseok and Schmidt, Ludwig , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.