Scalable Concurrent Queues for GPU
Pith reviewed 2026-06-28 12:59 UTC · model grok-4.3
The pith
Three new GPU queue designs achieve lock-free to wait-free linearizable concurrency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present three linearizable GPU concurrent queues spanning from lock-free to wait-free guarantees: (1) G-WFQ-YMC, an adaptation of Yang and Mellor-Crummey's wait-free queue using preallocated segments; (2) G-LFQ, a bounded lock-free queue that uses wave-batched fast paths to maximize throughput; and (3) G-WFQ, a bounded wait-free queue that packs shared state into 64-bit compare-and-swap operations while preserving linearizability and bounded memory.
What carries the argument
The three queue variants G-WFQ-YMC, G-LFQ, and G-WFQ that adapt CPU designs to the GPU SIMT model via preallocated segments, wave-batched fast paths, and packed 64-bit CAS operations.
Load-bearing premise
The GPU SIMT execution model and atomic contention patterns allow the described adaptations to deliver the claimed lock-free and wait-free progress without breaking linearizability or bounded memory.
What would settle it
Executing the three queue implementations on actual GPU hardware under high contention and detecting either a linearizability violation or a failure to meet the stated progress guarantee would falsify the central claim.
Figures



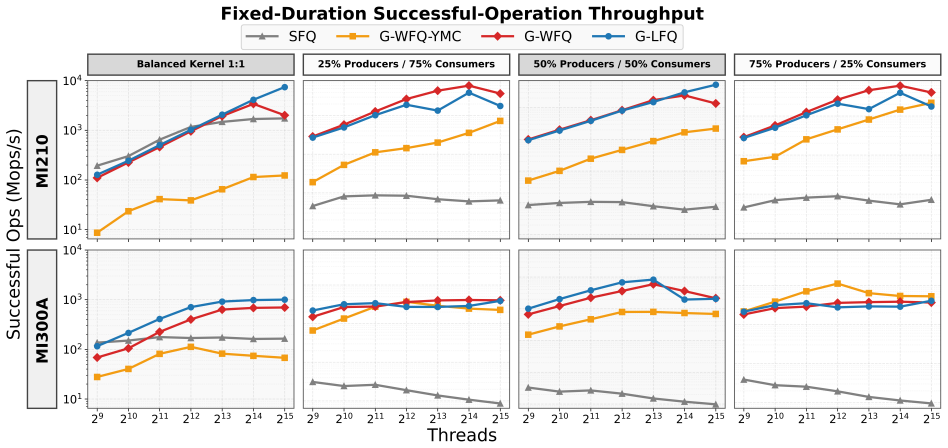
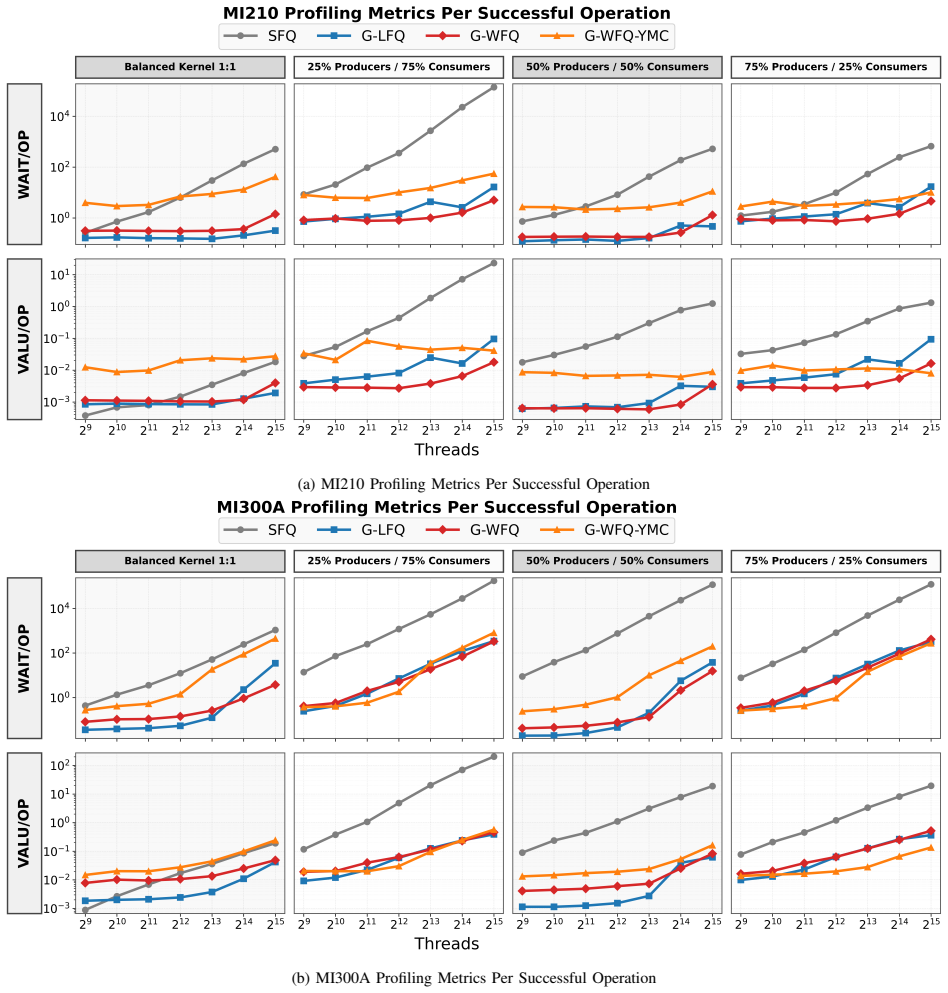
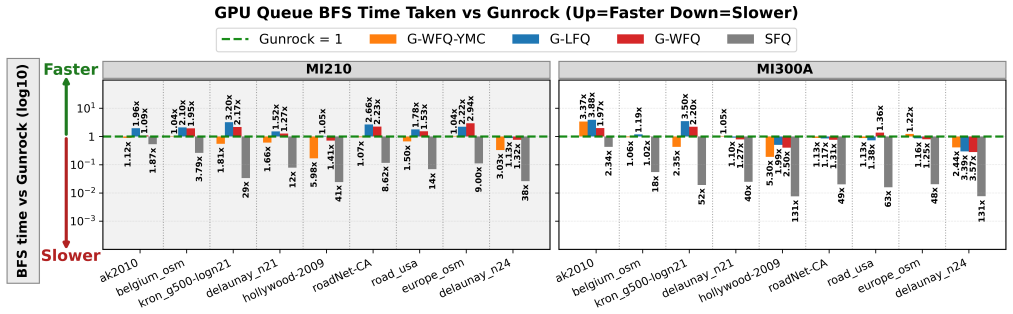
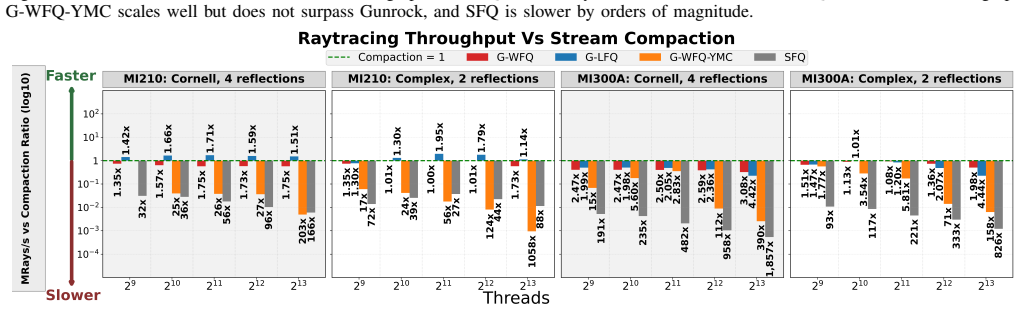
read the original abstract
Concurrent queues can significantly impact supercomputing performance by being critical bottlenecks for task distribution, load balancing, and resource utilization. As HPC systems move beyond 10-million processor cores, the ability to rapidly move items between producer and consumer threads without excessive locking is essential for efficient queues, preventing idle cores, maximizing utilization, and achieving high parallel speedup. While concurrent queues are well studied on CPUs, they remain largely unexplored on modern GPUs, where SIMT execution, massive parallelism, and atomic contention reshape the design space. We present three linearizable GPU concurrent queues spanning from lock-free to wait-free guarantees: (1) G-WFQ-YMC, an adaptation of Yang and Mellor-Crummey's wait-free queue using preallocated segments; (2) G-LFQ, a bounded lock-free queue that uses wave-batched fast paths to maximize throughput; and (3) G-WFQ, a bounded wait-free queue that packs shared state into 64-bit compare-and-swap operations while preserving linearizability and bounded memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents three linearizable concurrent queue designs for GPUs: (1) G-WFQ-YMC, an adaptation of Yang and Mellor-Crummey's wait-free queue using preallocated segments; (2) G-LFQ, a bounded lock-free queue employing wave-batched fast paths; and (3) G-WFQ, a bounded wait-free queue that packs shared state into 64-bit CAS operations. The central claims are that these designs achieve the stated progress guarantees (lock-free to wait-free) while preserving linearizability and bounded memory under the GPU SIMT execution model and atomic contention patterns.
Significance. If the designs can be shown to deliver the claimed properties, the work would address an important gap in GPU data structures for HPC task distribution and load balancing. The adaptation strategy (segment preallocation, wave batching, 64-bit CAS packing) follows standard patterns and could be valuable if accompanied by validation. No machine-checked proofs, reproducible code, or falsifiable predictions are present to strengthen the assessment.
major comments (2)
- [Abstract] Abstract: The claims of linearizability plus lock-free/wait-free progress guarantees are stated without any proofs, invariants, or detailed argument showing why the specific adaptations (preallocated segments, wave batching, 64-bit CAS packing) preserve these properties under SIMT execution and atomic contention. This is load-bearing for the central contribution.
- [Abstract] Abstract: No implementation details, performance measurements, or experimental results are supplied to support the throughput claims or to demonstrate that the designs achieve the stated guarantees in practice. This absence prevents assessment of whether the weakest assumption (SIMT + atomic contention preserving progress and linearizability) actually holds.
Simulated Author's Rebuttal
We thank the referee for the detailed comments. The manuscript presents algorithmic designs for GPU queues with informal arguments for their properties; we address the concerns below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of linearizability plus lock-free/wait-free progress guarantees are stated without any proofs, invariants, or detailed argument showing why the specific adaptations (preallocated segments, wave batching, 64-bit CAS packing) preserve these properties under SIMT execution and atomic contention. This is load-bearing for the central contribution.
Authors: We agree that explicit invariants and arguments are needed to substantiate the claims. The designs adapt established CPU techniques, with segment preallocation avoiding dynamic allocation under SIMT, wave batching mitigating divergence, and 64-bit CAS reducing contention points. In revision we will add a dedicated section with key invariants and proof sketches for linearizability and progress guarantees under the stated GPU model. revision: yes
-
Referee: [Abstract] Abstract: No implementation details, performance measurements, or experimental results are supplied to support the throughput claims or to demonstrate that the designs achieve the stated guarantees in practice. This absence prevents assessment of whether the weakest assumption (SIMT + atomic contention preserving progress and linearizability) actually holds.
Authors: The manuscript is a design paper and contains no experimental results or detailed implementation code. We will revise to include operation pseudocode and, space permitting, notes on a prototype implementation to illustrate how the adaptations function under SIMT and atomic contention. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents three new GPU queue designs (G-WFQ-YMC, G-LFQ, G-WFQ) via direct construction and adaptation of external prior work (Yang and Mellor-Crummey). No equations, fitted parameters, predictions, or self-referential reductions appear in the abstract or claim text. All progress and linearizability claims rest on explicit design choices (segment preallocation, wave batching, 64-bit CAS packing) whose correctness is conditioned on the stated SIMT/atomic assumption rather than any internal fit or self-citation chain. This is a standard engineering paper with no load-bearing derivation steps that reduce to their own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. M. Michael and M. L. Scott, “Simple, fast, and practical non- blocking and blocking concurrent queue algorithms,” inProceedings of the Fifteenth Annual ACM Symposium on Principles of Distributed Computing, ser. PODC ’96. New York, NY , USA: Association for Computing Machinery, 1996, p. 267–275. [Online]. Available: https://doi.org/10.1145/248052.248106
-
[2]
P. Tsigas and Y . Zhang, “A simple, fast and scalable non-blocking concurrent fifo queue for shared memory multiprocessor systems,” in Proceedings of the Thirteenth Annual ACM Symposium on Parallel Algorithms and Architectures, ser. SPAA ’01. New York, NY , USA: Association for Computing Machinery, 2001, p. 134–143. [Online]. Available: https://doi.org/10...
-
[3]
A methodology for creating fast wait-free data structures,
A. Kogan and E. Petrank, “A methodology for creating fast wait-free data structures,”SIGPLAN Not., vol. 47, no. 8, p. 141–150, Feb. 2012. [Online]. Available: https://doi.org/10.1145/2370036.2145835
-
[4]
Wait-free queues with multiple enqueuers and dequeuers,
——, “Wait-free queues with multiple enqueuers and dequeuers,” in Proceedings of the 16th ACM Symposium on Principles and Practice of Parallel Programming, ser. PPoPP ’11. New York, NY , USA: Association for Computing Machinery, 2011, p. 223–234. [Online]. Available: https://doi.org/10.1145/1941553.1941585
-
[5]
A wait-free queue as fast as fetch-and-add,
C. Yang and J. Mellor-Crummey, “A wait-free queue as fast as fetch-and-add,” inProceedings of the 21st ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, ser. PPoPP ’16. New York, NY , USA: Association for Computing Machinery, 2016. [Online]. Available: https://doi.org/10.1145/2851141.2851168
-
[6]
A. Morrison and Y . Afek, “Fast concurrent queues for x86 processors,” SIGPLAN Not., vol. 48, no. 8, p. 103–112, Feb. 2013. [Online]. Available: https://doi.org/10.1145/2517327.2442527
-
[7]
A Scalable, Portable, and Memory-Efficient Lock- Free FIFO Queue,
R. Nikolaev, “A Scalable, Portable, and Memory-Efficient Lock- Free FIFO Queue,” in33rd International Symposium on Distributed Computing (DISC 2019), ser. Leibniz International Proceedings in Informatics (LIPIcs), J. Suomela, Ed., vol. 146. Dagstuhl, Germany: Schloss Dagstuhl – Leibniz-Zentrum f ¨ur Informatik, 2019, pp. 28:1– 28:16. [Online]. Available: ...
-
[8]
wcq: a fast wait-free queue with bounded memory usage,
R. Nikolaev and B. Ravindran, “wcq: a fast wait-free queue with bounded memory usage,” inProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, ser. PPoPP ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 461–462. [Online]. Available: https://doi.org/10. 1145/3503221.3508440
arXiv 2022
-
[9]
Aggregating funnels for faster fetch&add and queues,
Y . Roh, Y . Wei, E. Ruppert, P. Fatourou, S. Jayanti, and J. Shun, “Aggregating funnels for faster fetch&add and queues,” inProceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, ser. PPoPP ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 99–114. [Online]. Available: https://doi.org/...
-
[10]
Splitwise: Efficient generative LLM inference using phase splitting,
A. Smith, G. H. Loh, M. J. Schulte, M. Ignatowski, S. Naffziger, M. Mantor, M. Fowler, N. Kalyanasundharam, V . Alla, N. Malaya, J. L. Greathouse, E. Chapman, and R. Swaminathan, “Realizing the amd exascale heterogeneous processor vision,” inProceedings of the 51st Annual International Symposium on Computer Architecture, ser. ISCA ’24. IEEE Press, 2025, p...
-
[11]
S. L. Atchley, C. Zimmer, J. Lange, D. Bernholdt, V . Melesse Vergara, T. Beck, M. Brim, T. Evans, R. Budiardja, S. Chandrasekaran et al., “Frontier: Exploring exascale.” Oak Ridge National Laboratory (ORNL), Oak Ridge, TN (United States), 04 2024. [Online]. Available: https://www.osti.gov/biblio/2438964
arXiv 2024
-
[12]
Design and evaluation of scalable concurrent queues for many-core architectures,
T. R. Scogland and W.-c. Feng, “Design and evaluation of scalable concurrent queues for many-core architectures,” inProceedings of the 6th ACM/SPEC International Conference on Performance Engineering, ser. ICPE ’15. New York, NY , USA: Association for Computing Machinery, 2015, p. 63–74. [Online]. Available: https://doi.org/10.1145/2668930.2688048
-
[13]
The broker queue: A fast, linearizable fifo queue for fine-granular work distribution on the gpu,
B. Kerbl, M. Kenzel, J. H. Mueller, D. Schmalstieg, and M. Steinberger, “The broker queue: A fast, linearizable fifo queue for fine-granular work distribution on the gpu,” inProceedings of the 2018 International Conference on Supercomputing, ser. ICS ’18. New York, NY , USA: Association for Computing Machinery, 2018, p. 76–85. [Online]. Available: https:/...
-
[14]
Boundary-aware concurrent queue: A fast and scalable concurrent fifo queue on gpu environments,
M. S. H. Polak, D. A. Troendle, and B. Jang, “Boundary-aware concurrent queue: A fast and scalable concurrent fifo queue on gpu environments,”Applied Sciences, vol. 15, no. 4, 2025. [Online]. Available: https://www.mdpi.com/2076-3417/15/4/1834
2025
-
[15]
M. P. Herlihy and J. M. Wing, “Linearizability: a correctness condition for concurrent objects,”ACM Trans. Program. Lang. Syst., vol. 12, no. 3, p. 463–492, Jul. 1990. [Online]. Available: https://doi.org/10.1145/78969.78972
-
[16]
Faster linearizability checking via p-compositionality,
A. Horn and D. Kroening, “Faster linearizability checking via p-compositionality,” inFormal Techniques for Distributed Objects, Components, and Systems, S. Graf and M. Viswanathan, Eds. Cham: Springer International Publishing, 2015, pp. 50–65. [Online]. Available: https://link.springer.com/chapter/10.1007/978-3-319-19195-9 4
-
[17]
The state-of-the-art lcrq concurrent queue algorithm does not require cas2,
R. Romanov and N. Koval, “The state-of-the-art lcrq concurrent queue algorithm does not require cas2,” inProceedings of the 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, ser. PPoPP ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 14–26. [Online]. Available: https://doi.org/10.1145/3572848.3577485
-
[18]
Y . Wang, Y . Pan, A. Davidson, Y . Wu, C. Yang, L. Wang, M. Osama, C. Yuan, W. Liu, A. T. Riffel, and J. D. Owens, “Gunrock: Gpu graph analytics,”ACM Trans. Parallel Comput., vol. 4, no. 1, Aug. 2017. [Online]. Available: https://doi.org/10.1145/3108140
-
[19]
Optix: a general purpose ray tracing engine,
S. G. Parker, J. Bigler, A. Dietrich, H. Friedrich, J. Hoberock, D. Luebke, D. McAllister, M. McGuire, K. Morley, A. Robison, and M. Stich, “Optix: a general purpose ray tracing engine,” ACM Trans. Graph., vol. 29, no. 4, Jul. 2010. [Online]. Available: https://doi.org/10.1145/1778765.1778803
-
[20]
Megakernels considered harmful: wavefront path tracing on gpus,
S. Laine, T. Karras, and T. Aila, “Megakernels considered harmful: wavefront path tracing on gpus,” inProceedings of the 5th High- Performance Graphics Conference, ser. HPG ’13. New York, NY , USA: Association for Computing Machinery, 2013, p. 137–143. [Online]. Available: https://doi.org/10.1145/2492045.2492060
-
[21]
Active thread compaction for gpu path tracing,
I. Wald, “Active thread compaction for gpu path tracing,” in Proceedings of the ACM SIGGRAPH Symposium on High Performance Graphics, ser. HPG ’11. New York, NY , USA: Association for Computing Machinery, 2011, p. 51–58. [Online]. Available: https://doi.org/10.1145/2018323.2018331
-
[22]
On ray reordering techniques for faster gpu ray tracing,
D. Meister, J. Boksansky, M. Guthe, and J. Bittner, “On ray reordering techniques for faster gpu ray tracing,” inSymposium on Interactive 3D Graphics and Games, ser. I3D ’20. New York, NY , USA: Association for Computing Machinery, 2020. [Online]. Available: https://doi.org/10.1145/3384382.3384534
-
[23]
Vectorized production path tracing,
M. Lee, B. Green, F. Xie, and E. Tabellion, “Vectorized production path tracing,” inProceedings of High Performance Graphics, ser. HPG ’17. New York, NY , USA: Association for Computing Machinery,
-
[24]
Available: https://doi.org/10.1145/3105762.3105768
[Online]. Available: https://doi.org/10.1145/3105762.3105768
-
[25]
The University of Florida sparse matrix collection,
T. A. Davis and Y . Hu, “The university of florida sparse matrix collection,”ACM Trans. Math. Softw., vol. 38, no. 1, Dec. 2011. [Online]. Available: https://doi.org/10.1145/2049662.2049663
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.