JenBridge: Adaptive Long-Form Video Soundtracking across Scene Transitions
Pith reviewed 2026-06-28 13:08 UTC · model grok-4.3
The pith
JenBridge uses an LLM agent to choose transition styles from a toolkit so long video soundtracks stay coherent across scene changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
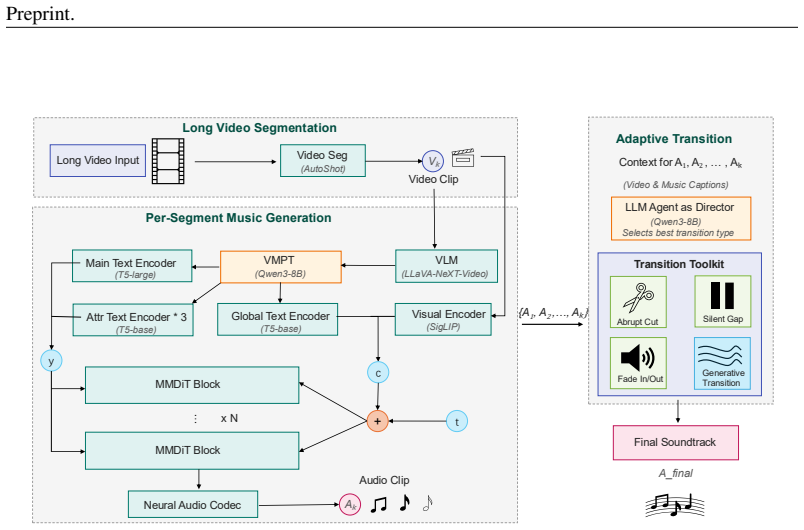
JenBridge is a modular framework built around a Transformer-based generative model trained with a flow-matching objective in two stages—pretraining on large-scale text-audio corpora followed by adaptation to the video domain with dual text-visual conditioning—augmented by an adaptive transition mechanism that maintains long-form coherence through a versatile toolkit of transition styles and an LLM Agent that selects the appropriate style for each narrative shift.
What carries the argument
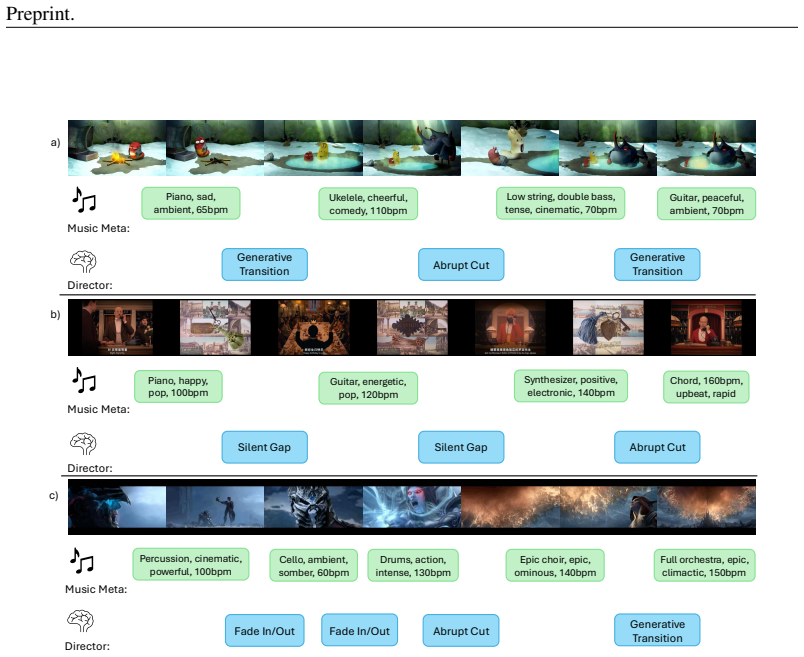
The LLM Agent that selects transition styles from a toolkit of options including generative transitions, acting as a director to match narrative shifts.
If this is right
- Long-form video soundtracks can maintain narrative coherence across diverse scene changes rather than breaking at each cut.
- The two-stage training produces both strong musical priors and precise cross-modal alignment for video-conditioned generation.
- A dedicated LVS Benchmark with transition-aware metrics enables systematic comparison of coherence in long-form audio.
- Objective and subjective scores improve most on transition naturalness and overall narrative flow compared with existing short-clip systems.
Where Pith is reading between the lines
- The agent-based selection pattern could extend to other sequential creative tasks such as dialogue or visual effect continuity.
- If the LLM selection proves stable, the framework reduces reliance on human post-editing for soundtrack assembly.
- The separation of pretraining and video adaptation may allow the same musical priors to support additional modalities without retraining from scratch.
Load-bearing premise
The LLM Agent can intelligently and reliably select the most appropriate transition style for each narrative shift from the toolkit of options.
What would settle it
Replace the LLM Agent with random style selection on the LVS Benchmark and measure whether transition naturalness and narrative coherence metrics fall to the level of prior methods.
Figures



read the original abstract
We address the challenge of generating high-fidelity, long-form soundtracks that remain coherent across scene transitions. Existing AI music systems are mainly designed for short, isolated clips and lack mechanisms to ensure narrative continuity. We present JenBridge, a modular and interpretable framework for adaptive long-form video soundtracking that ensures both high-fidelity audio generation and transition naturalness. The core architecture is a Transformer-based generative model trained with a flow-matching objective, following a two-stage paradigm: pretraining on large-scale text-audio corpora to establish robust musical priors, then adapting to the video domain with dual text-visual conditioning for precise cross-modal alignment. Crucially, to achieve long-form coherence across diverse scene changes, JenBridge incorporates a novel adaptive transition mechanism. This system features a versatile toolkit of transition styles, including a generative transition method, and uniquely employs a Large Language Model (LLM) Agent that acts as a director to select the most appropriate transition for each narrative shift intelligently. To rigorously assess this task, we propose the LVS Benchmark, a new benchmark that includes a curated dataset and novel evaluation metrics focusing on holistic and transition-aware assessment. Extensive experiments on the proposed benchmark demonstrate that JenBridge significantly outperforms existing methods in both objective and subjective metrics, particularly in terms of transition naturalness and overall narrative coherence. JenBridge represents a significant step towards fully automated, professional-quality video soundtracking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JenBridge, a Transformer-based generative model trained with flow-matching and dual text-visual conditioning for long-form video soundtracking. It incorporates an LLM Agent acting as a 'director' to select from a toolkit of transition styles (including a generative method) to ensure coherence across scene changes, and proposes the LVS Benchmark with new metrics for holistic and transition-aware evaluation. The central claim is that JenBridge significantly outperforms prior methods on objective and subjective metrics, especially transition naturalness and narrative coherence.
Significance. If the empirical results and the contribution of the LLM Agent hold after proper validation, the work would address a clear gap in extending short-clip music generation to long-form narrative video soundtracks. The modular design and two-stage training paradigm are potentially reusable, but the current lack of reported numbers, ablations, or independent validation limits assessment of whether the adaptive selection mechanism drives the claimed gains over the base flow-matching model.
major comments (3)
- [Abstract] Abstract: the assertion that JenBridge 'significantly outperforms existing methods in both objective and subjective metrics, particularly in terms of transition naturalness and overall narrative coherence' is presented with no numerical values, baseline comparisons, statistical tests, dataset sizes, or p-values, rendering the headline empirical claim unevidenced within the provided text.
- [Adaptive transition mechanism] LLM Agent transition selection (described in the adaptive transition mechanism section): the paper states that the LLM Agent 'intelligently' selects the most appropriate transition style for each narrative shift, yet supplies no prompting strategy, decision criteria, ablation against random/heuristic/always-same baselines, failure-mode analysis, or human/proxy validation; because this component is presented as crucial for the transition-naturalness gains, its unvalidated status is load-bearing for the central claim.
- [LVS Benchmark] LVS Benchmark section: the new benchmark and metrics are introduced by the same authors who define the evaluation rules and curate the dataset, creating dependence between the proposed method and the evaluation protocol; without external validation or comparison on established benchmarks, the outperformance claim risks circularity.
minor comments (1)
- [Abstract] The abstract and introduction use the term 'director' for the LLM Agent without clarifying whether this is a metaphor or a formal component name; consistent terminology would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights areas where the presentation of empirical claims and component validation can be strengthened. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that JenBridge 'significantly outperforms existing methods in both objective and subjective metrics, particularly in terms of transition naturalness and overall narrative coherence' is presented with no numerical values, baseline comparisons, statistical tests, dataset sizes, or p-values, rendering the headline empirical claim unevidenced within the provided text.
Authors: The abstract serves as a high-level summary and conventionally omits detailed statistics to preserve conciseness. All numerical results, baseline comparisons, dataset sizes, and statistical details appear in Section 4 (Experiments) and the supplementary material. We will revise the abstract to include key quantitative highlights, such as relative improvements on transition naturalness and narrative coherence metrics, to better ground the claim within the abstract text itself. revision: yes
-
Referee: [Adaptive transition mechanism] LLM Agent transition selection (described in the adaptive transition mechanism section): the paper states that the LLM Agent 'intelligently' selects the most appropriate transition style for each narrative shift, yet supplies no prompting strategy, decision criteria, ablation against random/heuristic/always-same baselines, failure-mode analysis, or human/proxy validation; because this component is presented as crucial for the transition-naturalness gains, its unvalidated status is load-bearing for the central claim.
Authors: We agree that the LLM Agent requires stronger empirical support given its role in the claimed gains. The current section describes the overall mechanism and toolkit, but lacks the requested details. In the revision we will add the exact prompting strategy and decision criteria, ablations against random, heuristic, and fixed baselines, failure-mode analysis, and results from a human or proxy validation study to substantiate the adaptive selection. revision: yes
-
Referee: [LVS Benchmark] LVS Benchmark section: the new benchmark and metrics are introduced by the same authors who define the evaluation rules and curate the dataset, creating dependence between the proposed method and the evaluation protocol; without external validation or comparison on established benchmarks, the outperformance claim risks circularity.
Authors: The LVS Benchmark was created because no prior benchmark evaluates long-form soundtracking across scene transitions with transition-aware metrics. The curation process and metric definitions are fully documented for reproducibility. While the benchmark is new, evaluations compare JenBridge against multiple existing methods using both the new metrics and standard objective measures. To reduce circularity concerns we will add results on established short-form benchmarks and release the dataset and evaluation code for independent use. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an empirical system: a Transformer flow-matching model pretrained on text-audio then adapted with dual conditioning, plus an LLM agent selecting from a transition toolkit, evaluated on a newly proposed LVS benchmark. No equations, first-principles derivations, or parameter-fitting steps are presented that reduce a claimed prediction or result to the inputs by construction. The benchmark and metrics are introduced as a contribution rather than used to force an equivalence; outperformance statements are experimental comparisons, not definitional. No self-citation load-bearing, uniqueness theorems, or ansatz smuggling appear in the architecture or claims. The work is self-contained as a standard ML system paper against its own benchmark.
Axiom & Free-Parameter Ledger
invented entities (1)
-
LLM Agent as director
no independent evidence
Reference graph
Works this paper leans on
-
[1]
MusicLM: Generating Music From Text
Andrea Agostinelli, Timo I Denk, Zal ´an Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, et al. Musiclm: Generating music from text.arXiv preprint arXiv:2301.11325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Ye Bai, Haonan Chen, Jitong Chen, Zhuo Chen, Yi Deng, Xiaohong Dong, Lamtharn Hantrakul, Weituo Hao, Qingqing Huang, Zhongyi Huang, et al. Seed-music: A unified framework for high quality and controlled music generation.arXiv preprint arXiv:2409.09214,
-
[3]
Ke Chen, Yusong Wu, Haohe Liu, Marianna Nezhurina, Taylor Berg-Kirkpatrick, and Shlomo Dub- nov
URLhttps: //www.scenedetect.com. Ke Chen, Yusong Wu, Haohe Liu, Marianna Nezhurina, Taylor Berg-Kirkpatrick, and Shlomo Dub- nov. Musicldm: Enhancing novelty in text-to-music generation using beat-synchronous mixup strategies. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP), pp. 1206–1210. IEEE,
2024
-
[4]
Xiaowei Chi, Yatian Wang, Aosong Cheng, Pengjun Fang, Zeyue Tian, Yingqing He, Zhaoyang Liu, Xingqun Qi, Jiahao Pan, Rongyu Zhang, et al. Mmtrail: A multimodal trailer video dataset with language and music descriptions.arXiv preprint arXiv:2407.20962,
-
[5]
High Fidelity Neural Audio Compression
Alexandre D ´efossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression.arXiv preprint arXiv:2210.13438,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Video background music generation with controllable music transformer
Shangzhe Di, Zeren Jiang, Si Liu, Zhaokai Wang, Leyan Zhu, Zexin He, Hongming Liu, and Shuicheng Yan. Video background music generation with controllable music transformer. In Proceedings of the 29th ACM International Conference on Multimedia, pp. 2037–2045,
2037
-
[7]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al
Accessed: 2025-09-18. Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
2025
-
[8]
Stable audio open
Zach Evans, Julian D Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons. Stable audio open. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2025
-
[9]
Cot-vtm: Visual-to-music genera- tion with chain-of-thought reasoning
Xikang Guan, Zheng Gu, Jing Huo, Tianyu Ding, and Yang Gao. Cot-vtm: Visual-to-music genera- tion with chain-of-thought reasoning. InFindings of the Association for Computational Linguis- tics: ACL 2025, pp. 12493–12510,
2025
-
[10]
10 Preprint. Qingqing Huang, Daniel S Park, Tao Wang, Timo I Denk, Andy Ly, Nanxin Chen, Zhengdong Zhang, Zhishuai Zhang, Jiahui Yu, Christian Frank, et al. Noise2music: Text-conditioned music generation with diffusion models.arXiv preprint arXiv:2302.03917,
-
[11]
Max WY Lam, Yijin Xing, Weiya You, Jingcheng Wu, Zongyu Yin, Fuqiang Jiang, Hangyu Liu, Feng Liu, Xingda Li, Wei-Tsung Lu, et al. Analyzable chain-of-musical-thought prompting for high-fidelity music generation.arXiv preprint arXiv:2503.19611,
-
[12]
Jen-1: Text- guided universal music generation with omnidirectional diffusion models
Peike Patrick Li, Boyu Chen, Yao Yao, Yikai Wang, Allen Wang, and Alex Wang. Jen-1: Text- guided universal music generation with omnidirectional diffusion models. In2024 IEEE Confer- ence on Artificial Intelligence (CAI), pp. 762–769. IEEE, 2024a. Ruiqi Li, Siqi Zheng, Xize Cheng, Ziang Zhang, Shengpeng Ji, and Zhou Zhao. Muvi: Video- to-music generation ...
-
[13]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Shansong Liu, Atin Sakkeer Hussain, Qilong Wu, Chenshuo Sun, and Ying Shan. Mumu-llama: Multi-modal music understanding and generation via large language models.arXiv preprint arXiv:2412.06660, 3(5):6,
-
[15]
Extending visual dynamics for video-to- music generation.arXiv preprint arXiv:2504.07594,
Xiaohao Liu, Teng Tu, Yunshan Ma, and Tat-Seng Chua. Extending visual dynamics for video-to- music generation.arXiv preprint arXiv:2504.07594,
-
[16]
Mustango: Toward controllable text-to-music generation.arXiv preprint arXiv:2311.08355,
Jan Melechovsky, Zixun Guo, Deepanway Ghosal, Navonil Majumder, Dorien Herremans, and Soujanya Poria. Mustango: Toward controllable text-to-music generation.arXiv preprint arXiv:2311.08355,
-
[17]
Javier Nistal, Marco Pasini, Cyran Aouameur, Maarten Grachten, and Stefan Lattner. Diff- a-riff: Musical accompaniment co-creation via latent diffusion models.arXiv preprint arXiv:2406.08384,
-
[18]
Musicflow: Cascaded flow matching for text guided music generation.arXiv preprint arXiv:2410.20478,
KR Prajwal, Bowen Shi, Matthew Lee, Apoorv Vyas, Andros Tjandra, Mahi Luthra, Baishan Guo, Huiyu Wang, Triantafyllos Afouras, David Kant, et al. Musicflow: Cascaded flow matching for text guided music generation.arXiv preprint arXiv:2410.20478,
-
[19]
11 Preprint
Accessed: 2025-09-18. 11 Preprint. Fan Qi, Kunsheng Ma, and Changsheng Xu. Customized condition controllable generation for video soundtrack. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 23914–23924,
2025
-
[20]
AudioX: A Unified Framework for Anything-to-Audio Generation
Accessed: 2025-09-18. Zeyue Tian, Yizhu Jin, Zhaoyang Liu, Ruibin Yuan, Xu Tan, Qifeng Chen, Wei Xue, and Yike Guo. Audiox: Diffusion transformer for anything-to-audio generation.arXiv preprint arXiv:2503.10522, 2025a. Zeyue Tian, Zhaoyang Liu, Ruibin Yuan, Jiahao Pan, Qifeng Liu, Xu Tan, Qifeng Chen, Wei Xue, and Yike Guo. Vidmuse: A simple video-to-musi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Zhifeng Xie, Qile He, Youjia Zhu, Qiwei He, and Mengtian Li
Accessed: 2025-09-18. Zhifeng Xie, Qile He, Youjia Zhu, Qiwei He, and Mengtian Li. Filmcomposer: Llm-driven music production for silent film clips. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 13519–13528,
2025
-
[22]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Yue: Scaling open foundation models for long-form music generation.arXiv preprint arXiv:2503.08638,
Ruibin Yuan, Hanfeng Lin, Shuyue Guo, Ge Zhang, Jiahao Pan, Yongyi Zang, Haohe Liu, Yiming Liang, Wenye Ma, Xingjian Du, et al. Yue: Scaling open foundation models for long-form music generation.arXiv preprint arXiv:2503.08638,
-
[24]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
URL https://llava-vl.github.io/blog/2024-04-30-llava-next-video/. Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Llamafactory: Unified efficient fine-tuning of 100+ language models.arXiv preprint arXiv:2403.13372,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Pengfei Zhu, Chao Pang, Yekun Chai, Lei Li, Shuohuan Wang, Yu Sun, Hao Tian, and Hua Wu. Ernie-music: Text-to-waveform music generation with diffusion models.arXiv preprint arXiv:2302.04456, 2023a. Wentao Zhu, Yufang Huang, Xiufeng Xie, Wenxian Liu, Jincan Deng, Debing Zhang, Zhangyang Wang, and Ji Liu. Autoshot: A short video dataset and state-of-the-art...
-
[26]
A STATEMENTS ANDBROADERIMPACT A.1 ETHICSSTATEMENT Data Usage.Our work adheres to strict ethical guidelines regarding data usage
13 Preprint. A STATEMENTS ANDBROADERIMPACT A.1 ETHICSSTATEMENT Data Usage.Our work adheres to strict ethical guidelines regarding data usage. The foundational text-to-music model was trained on a private, curated dataset. This dataset consists exclusively of high-fidelity, professionally produced songs for which we have secured the necessary licenses from...
2024
-
[27]
However, to facilitate further research and application, we will provide public API ac- cess to our foundational text-to-music model
and its private, licensed training data will not be released. However, to facilitate further research and application, we will provide public API ac- cess to our foundational text-to-music model. The inference codebase for the v2m stage, including scripts for data processing, will also be made publicly available. A.3 LLM USAGESTATEMENT In the preparation ...
2020
-
[28]
This configuration allows us to partition long videos into a sequence of meaningful, temporally substantial clips suitable for individual soundtracking
Further- more, to avoid generating overly short and musically impractical segments, we enforce a minimum scene length of 8 seconds. This configuration allows us to partition long videos into a sequence of meaningful, temporally substantial clips suitable for individual soundtracking. It is noted that our video segmentation module is replaceable with some ...
2025
-
[29]
ground-truth
B.4 VMPT PROMPTEXAMPLES The VMPT is fine-tuned using a structured prompt designed to teach the model how to translate raw video captions into musical metadata. Figure 3 illustrates the complete prompt structure and an example used in our training. 15 Preprint. ### SYSTEM INSTRUCTION ### You are a professional music analyst, you need to analysis the given ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.