OctoT2I: A Self-Evolving Agentic Text-to-Image Router
Pith reviewed 2026-06-28 14:20 UTC · model grok-4.3
The pith
OctoT2I builds a knowledge base from scratch so a stateful router can pick the right text-to-image tool for each prompt without human rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
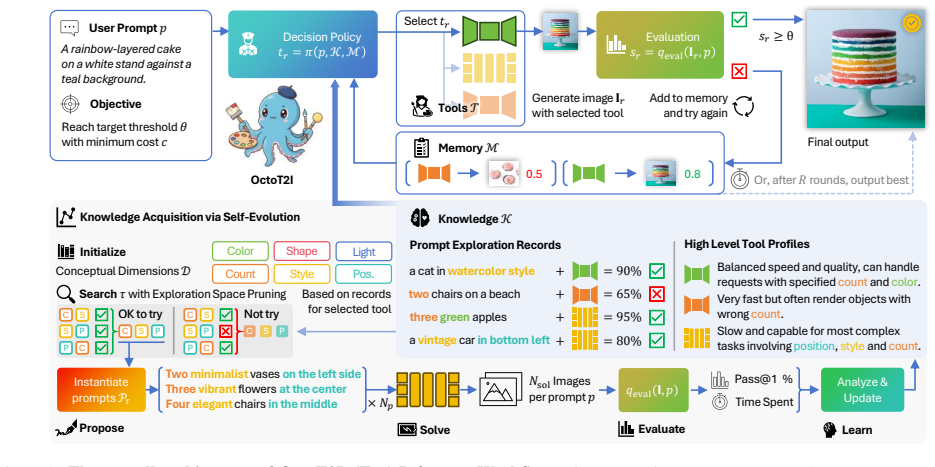
OctoT2I reformulates the T2I task as a joint optimization of generation quality and inference efficiency. It implements a stateful, multi-round routing strategy that adaptively selects the most suitable tool based on its knowledge and memory. This strategy is enabled by a knowledge base built from scratch by the Self-Evolving Mechanism, which autonomously defines foundational Conceptual Dimensions and explores their combinations via the iterative PSEL loop to discover each tool's capability frontier without external guidance.
What carries the argument
The Self-Evolving Mechanism that uses the PSEL (Propose-Solve-Evaluate-Learn) loop to define Conceptual Dimensions and map tool capability frontiers autonomously.
If this is right
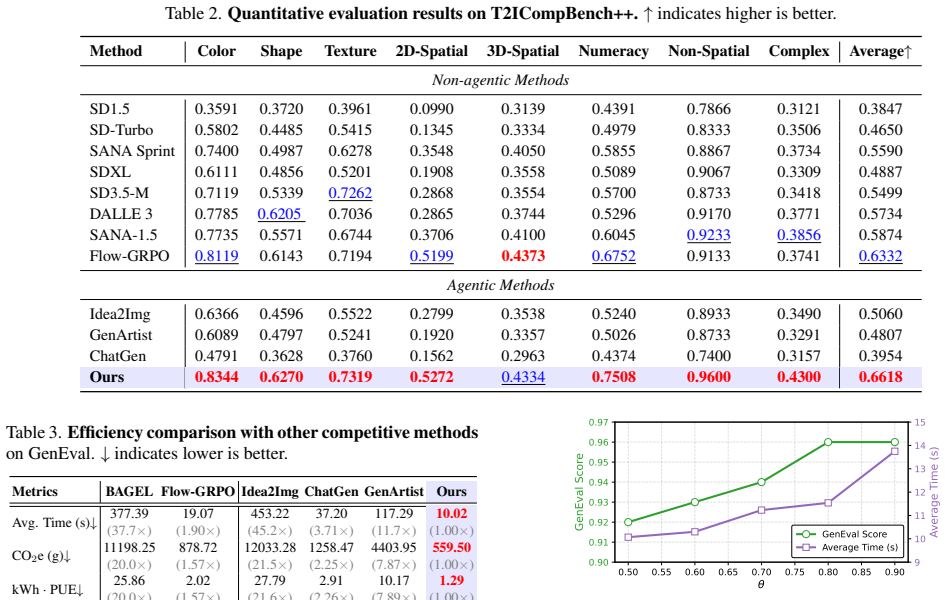
- The router reaches a GenEval score of 0.96.
- Inference runs 90.3 percent faster than the Flow-GRPO baseline.
- Energy use drops by 56.6 percent relative to the same baseline.
- Continuous PSEL iteration produces ongoing improvement in routing decisions without added human input.
Where Pith is reading between the lines
- The same unsupervised mapping process could be applied to select among video or audio generators once their capability frontiers are defined.
- Production systems could keep the PSEL loop running online to adapt routing as new model versions appear.
- If the discovered dimensions prove stable, manual benchmark suites for T2I tools might be replaced by automated frontier maps.
- The stateful memory could support prompt refinement across rounds rather than one-shot selection.
Load-bearing premise
The self-evolving mechanism can autonomously define Conceptual Dimensions and explore their combinations via the PSEL loop to accurately discover each tool's capability frontier with no human supervision or external guidance.
What would settle it
Run the PSEL loop on the same set of T2I tools, then measure whether the resulting routing decisions match or exceed the performance of routes chosen by human experts on a fixed test prompt set; a large gap would falsify the autonomy claim.
Figures


read the original abstract
The explosive growth of Text-to-Image (T2I) models, from large-scale versions to lightweight, real-time ones, now faces diminishing marginal returns from single-model scaling. Agentic T2I methods emerged to alleviate this bottleneck by using multiple models. However, existing agentic T2I methods suffer from three key challenges: reliance on expensive handcrafted priors or human annotations, rigid single-path decision mechanisms, and a neglect of inference efficiency. To address these challenges, we introduce OctoT2I, a novel agentic framework that reformulates the T2I task as a joint optimization of generation quality and inference efficiency. OctoT2I implements a stateful, multi-round routing strategy that adaptively selects the most suitable tool based on its knowledge and memory. This strategy is enabled by a knowledge base built from scratch by our novel Self-Evolving Mechanism. This mechanism, which requires no human supervision, first autonomously defines foundational Conceptual Dimensions (eg, style, color, count) and then intelligently explores their combinations via an iterative" Propose--Solve--Evaluate--Learn"(PSEL) loop. The PSEL loop efficiently discovers each tool's capability frontier, driving continuous improvement without external guidance. Extensive experiments demonstrate that OctoT2I achieves competitive performance (0.96) on GenEval while delivering a 90.3% inference speedup and a 56.6% energy-efficiency gain over the leading baseline (Flow-GRPO), striking an exceptional balance between performance and efficiency. Code and models will be made available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents OctoT2I, an agentic text-to-image routing framework that reformulates T2I as joint optimization of quality and efficiency. It introduces a self-evolving mechanism that autonomously defines Conceptual Dimensions (e.g., style, color, count) and iteratively explores tool capability frontiers via a stateful PSEL (Propose–Solve–Evaluate–Learn) loop with no human supervision, building a knowledge base from scratch to enable adaptive multi-round routing. The paper reports that this yields a GenEval score of 0.96 together with a 90.3% inference speedup and 56.6% energy-efficiency gain relative to the Flow-GRPO baseline.
Significance. If the self-evolving PSEL mechanism can be shown to operate without implicit priors or external guidance, the work would constitute a meaningful advance in agentic T2I systems by removing reliance on handcrafted priors and rigid single-path routing while simultaneously improving inference efficiency. The reported combination of competitive quality and large efficiency gains would be notable for practical deployment of multi-model T2I pipelines.
major comments (2)
- [Abstract] Abstract: the central performance claims (0.96 GenEval, 90.3% speedup, 56.6% energy gain) rest on the assertion that the PSEL loop autonomously defines Conceptual Dimensions and accurately discovers each tool’s capability frontier from scratch. No technical specification is given for the initial state before the first Propose step, the precise evaluation criteria inside Evaluate, or any safeguards against drift or incomplete coverage; without these the reported numbers cannot be verified as arising from the claimed mechanism rather than from base-LLM priors.
- [Abstract] Abstract: the claim that the knowledge base is “built from scratch” with “no human supervision” is load-bearing for the generalization of the routing decisions. The manuscript provides no description of how the loop initializes, whether seeded examples or LLM-internal knowledge are used, or how the iterative process guarantees exhaustive frontier discovery; this directly affects whether the efficiency numbers are reproducible or generalizable.
minor comments (1)
- The abstract states that code and models will be made available but supplies no repository link, license, or expected release date, which would facilitate verification of the reported results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments correctly identify that the abstract (and, by extension, the current manuscript) lacks sufficient technical detail on the PSEL loop's initialization, evaluation criteria, and safeguards. We will revise the manuscript to supply these specifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (0.96 GenEval, 90.3% speedup, 56.6% energy gain) rest on the assertion that the PSEL loop autonomously defines Conceptual Dimensions and accurately discovers each tool’s capability frontier from scratch. No technical specification is given for the initial state before the first Propose step, the precise evaluation criteria inside Evaluate, or any safeguards against drift or incomplete coverage; without these the reported numbers cannot be verified as arising from the claimed mechanism rather than from base-LLM priors.
Authors: We agree that the current manuscript does not provide these specifications at the level of detail required for verification. In the revised version we will add an explicit subsection (new Section 3.2.1) that states: (1) the loop begins with an empty knowledge base and no seeded examples or task-specific priors; (2) the Evaluate step uses only automated, reference-free metrics (GenEval-style scoring plus measured latency/energy) with no human judgment; and (3) drift and coverage safeguards consist of a termination condition that halts when three consecutive Propose steps yield no new frontier dimensions and a consistency check that re-evaluates a random sample of prior frontiers. These additions will allow readers to confirm that the reported numbers arise from the described mechanism. revision: yes
-
Referee: [Abstract] Abstract: the claim that the knowledge base is “built from scratch” with “no human supervision” is load-bearing for the generalization of the routing decisions. The manuscript provides no description of how the loop initializes, whether seeded examples or LLM-internal knowledge are used, or how the iterative process guarantees exhaustive frontier discovery; this directly affects whether the efficiency numbers are reproducible or generalizable.
Authors: We concur that the manuscript currently omits these initialization and coverage details. The revision will include a precise account of the zero-shot start (empty memory, no human-provided seeds or annotations), clarification that the base LLM supplies only general reasoning capacity rather than pre-loaded task knowledge, and the exhaustive-discovery guarantee (iterative expansion continues until the Propose step produces no novel Conceptual Dimensions for a fixed number of rounds, with an explicit coverage metric reported in the experiments). These changes will directly support the reproducibility and generalizability claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical agentic framework whose performance claims (GenEval score, speedup, energy gains) rest on external benchmarks and experimental comparisons rather than any internal derivation. The PSEL loop and autonomous dimension definition are described as building a knowledge base from scratch, but the abstract and provided text contain no equations, fitted parameters renamed as predictions, or self-referential reductions that would make the reported results equivalent to the loop's own outputs by construction. No self-citation load-bearing steps or ansatz smuggling are identifiable from the given material. The derivation is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption T2I models possess distinct and discoverable capability frontiers across prompt dimensions such as style, color, and count.
invented entities (2)
-
Conceptual Dimensions
no independent evidence
-
PSEL loop
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Improving image generation with better captions.Computer Science
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions.Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023. 6
2023
-
[3]
Adversarial diffusion compression for real-world image super-resolution
Bin Chen, Gehui Li, Rongyuan Wu, Xindong Zhang, Jie Chen, Jian Zhang, and Lei Zhang. Adversarial diffusion compression for real-world image super-resolution. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 28208–28220, 2025. 2
2025
-
[4]
Bin Chen, Weiqi Li, Shijie Zhao, Xuanyu Zhang, Junlin Li, Li Zhang, and Jian Zhang. Improved adversarial diffusion compression for real-world video super-resolution.arXiv preprint arXiv:2603.00458, 2026. 2
-
[5]
T2i-copilot: A training-free multi-agent text-to-image sys- tem for enhanced prompt interpretation and interactive gen- eration
Chieh-Yun Chen, Min Shi, Gong Zhang, and Humphrey Shi. T2i-copilot: A training-free multi-agent text-to-image sys- tem for enhanced prompt interpretation and interactive gen- eration. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 19396–19405, 2025. 2, 3
2025
-
[6]
Autoagents: A framework for automatic agent generation.arXiv preprint arXiv:2309.17288, 2023
Guangyao Chen, Siwei Dong, Yu Shu, Ge Zhang, Jaward Sesay, B¨orje F Karlsson, Jie Fu, and Yemin Shi. Autoagents: A framework for automatic agent generation.arXiv preprint arXiv:2309.17288, 2023. 2, 3
-
[7]
Pixart-α: Fast training of diffusion trans-former for photorealistic text-to-image syn- thesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-α: Fast training of diffusion trans-former for photorealistic text-to-image syn- thesis. 2
-
[8]
Junsong Chen, Shuchen Xue, Yuyang Zhao, Jincheng Yu, Sayak Paul, Junyu Chen, Han Cai, Song Han, and Enze Xie. Sana-sprint: One-step diffusion with continuous-time con- sistency distillation.arXiv preprint arXiv:2503.09641, 2025. 2, 3, 6
-
[9]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus- pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[12]
Geneval: An object-focused framework for evaluating text- to-image alignment.Advances in Neural Information Pro- cessing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text- to-image alignment.Advances in Neural Information Pro- cessing Systems, 36:52132–52152, 2023. 5, 6
2023
-
[13]
Chatllm network: More brains, more intel- ligence.arXiv preprint arXiv:2304.12998, 2023
Rui Hao, Linmei Hu, Weijian Qi, Qingliu Wu, Yirui Zhang, and Liqiang Nie. Chatllm network: More brains, more intel- ligence.arXiv preprint arXiv:2304.12998, 2023
-
[14]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, et al. Metagpt: Meta pro- gramming for multi-agent collaborative framework.arXiv preprint arXiv:2308.00352, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Yujie Hu, Zecheng Tang, Xu Jiang, Weiqi Li, and Jian Zhang. Talkphoto: A versatile training-free conversa- tional assistant for intelligent image editing.arXiv preprint arXiv:2601.01915, 2026. 3
-
[16]
T2I-CompBench++: An Enhanced and Comprehensive Benchmark for Compositional Text-to- Image Generation .IEEE Transactions on Pattern Analysis Machine Intelligence, (01):1–17, 5555
Kaiyi Huang, Chengqi Duan, Kaiyue Sun, Enze Xie, Zhen- guo Li, and Xihui Liu. T2I-CompBench++: An Enhanced and Comprehensive Benchmark for Compositional Text-to- Image Generation .IEEE Transactions on Pattern Analysis Machine Intelligence, (01):1–17, 5555. 5, 6
-
[17]
UniShield: An Adaptive Multi-Agent Framework for Unified Forgery Image Detection and Localization
Qing Huang, Zhipei Xu, Xuanyu Zhang, and Jian Zhang. Unishield: An adaptive multi-agent framework for unified forgery image detection and localization.arXiv preprint arXiv:2510.03161, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Edward Hughes, Michael Dennis, Jack Parker-Holder, Feryal Behbahani, Aditi Mavalankar, Yuge Shi, Tom Schaul, and Tim Rocktaschel. Open-endedness is essen- tial for artificial superhuman intelligence.arXiv preprint arXiv:2406.04268, 2024. 2
-
[19]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Chengyou Jia, Changliang Xia, Zhuohang Dang, Weijia Wu, Hangwei Qian, and Minnan Luo. Chatgen: Automatic text- to-image generation from freestyle chatting.arXiv preprint arXiv:2411.17176, 2024. 2, 3, 6, 8
-
[21]
Multi-agent image restoration.arXiv preprint arXiv:2503.09403, 2025
Xu Jiang, Gehui Li, Bin Chen, and Jian Zhang. Multi-agent image restoration.arXiv preprint arXiv:2503.09403, 2025. 3
-
[22]
DGPO: Distribution Guided Policy Optimization for Fine Grained Credit Assignment
Hongbo Jin, Rongpeng Zhu, Zhongjing Du, Xu Jiang, Jingqi Tian, Qiaoman Zhang, and Jiayu Ding. Dgpo: Distribu- tion guided policy optimization for fine grained credit assign- ment.arXiv preprint arXiv:2605.03327, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
An llm compiler for parallel function calling.arXiv preprint arXiv:2312.04511, 2023
Sehoon Kim, Suhong Moon, Ryan Tabrizi, Nicholas Lee, Michael W Mahoney, Kurt Keutzer, and Amir Gholami. An llm compiler for parallel function calling.arXiv preprint arXiv:2312.04511, 2023
-
[24]
Flux, 2024
Black Forest Labs. Flux, 2024. 2, 3, 6
2024
-
[25]
Camel: Communicative agents for” mind” exploration of large language model society
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for” mind” exploration of large language model society. Advances in Neural Information Processing Systems, 36: 51991–52008, 2023. 2
2023
-
[26]
SDXL-Lightning: Progressive Adversarial Diffusion Distillation
Shanchuan Lin, Anran Wang, and Xiao Yang. Sdxl- lightning: Progressive adversarial diffusion distillation. arXiv preprint arXiv:2402.13929, 2024. 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text gen- eration.arXiv preprint arXiv:2404.01291, 2024. 4
-
[28]
Bingchen Liu, Ehsan Akhgari, Alexander Visheratin, Aleks Kamko, Linmiao Xu, Shivam Shrirao, Chase Lambert, Joao Souza, Suhail Doshi, and Daiqing Li. Playground v3: Im- proving text-to-image alignment with deep-fusion large lan- guage models.arXiv preprint arXiv:2409.10695, 2024. 2, 3
-
[29]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via on- line rl.arXiv preprint arXiv:2505.05470, 2025. 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Nvila: Efficient frontier visual language models, 2024
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yux- ian Gu, Dacheng Li, Xiuyu Li, Yunhao Fang, Yukang Chen, Cheng-Yu Hsieh, De-An Huang, An-Chieh Cheng, Vish- wesh Nath, Jinyi Hu, Sifei Liu, Ranjay Krishna, Daguang Xu, Xiaolong Wang, Pavlo Molchanov, Jan Kautz, Hongxu Yin, Song Han, and Yao Lu. Nvila:...
2024
-
[31]
Zheyuan Liu, Munan Ning, Qihui Zhang, Shuo Yang, Zhongrui Wang, Yiwei Yang, Xianzhe Xu, Yibing Song, Weihua Chen, Fan Wang, et al. Cot-lized diffusion: Let’s reinforce t2i generation step-by-step.arXiv preprint arXiv:2507.04451, 2025
-
[32]
Janusflow: Harmonizing autore- gression and rectified flow for unified multimodal under- standing and generation
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai Yu, et al. Janusflow: Harmonizing autore- gression and rectified flow for unified multimodal under- standing and generation. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 7739–7751,
-
[33]
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Yuwei Niu, Munan Ning, Mengren Zheng, Weiyang Jin, Bin Lin, Peng Jin, Jiaqi Liao, Kunpeng Ning, Chaoran Feng, Bin Zhu, and Li Yuan. Wise: A world knowledge-informed semantic evaluation for text-to-image generation.arXiv preprint arXiv:2503.07265, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
R OpenAI. Gpt-4 technical report. arxiv 2303.08774.View in Article, 2(5):1, 2023. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
2023
-
[36]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2, 3, 6
2022
-
[39]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean Conference on Computer Vision, pages 87–103. Springer,
-
[40]
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36, 2024
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36, 2024. 3
2024
-
[41]
Xuhan Sheng, Runyi Li, Bin Chen, Weiqi Li, Xu Jiang, and Jian Zhang. Realosr: Latent guidance boosts diffusion-based real-world omnidirectional image super-resolutions.arXiv preprint arXiv:2412.09646, 2024. 2
-
[42]
Energy and policy considerations for modern deep learning research
Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for modern deep learning research. InProceedings of the AAAI conference on artificial intelligence, pages 13693–13696, 2020. 6
2020
-
[43]
Sequence to sequence learning with neural networks.Advances in neural information processing systems, 27, 2014
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks.Advances in neural information processing systems, 27, 2014. 2
2014
-
[44]
Position: Will we run out of data? limits of llm scaling based on human- generated data
Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Be- siroglu, Lennart Heim, and Marius Hobbhahn. Position: Will we run out of data? limits of llm scaling based on human- generated data. InForty-first International Conference on Machine Learning, 2024. 2
2024
-
[45]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Z Wang, S Mao, W Wu, T Ge, F Wei, and H Ji. Unleashing cognitive synergy in large language models: A task-solving agent through multi-persona selfcollaboration. arxiv 2023. arXiv preprint arXiv:2307.05300, 2023
-
[48]
Genartist: Multimodal llm as an agent for unified image gen- eration and editing.Advances in Neural Information Pro- cessing Systems, 37:128374–128395, 2024
Zhenyu Wang, Aoxue Li, Zhenguo Li, and Xihui Liu. Genartist: Multimodal llm as an agent for unified image gen- eration and editing.Advances in Neural Information Pro- cessing Systems, 37:128374–128395, 2024. 2, 3, 6, 7, 8
2024
-
[49]
Wang, Evan Montoya, David Munechika, Haoyang Yang, Benjamin Hoover, and Duen Horng Chau
Zijie J. Wang, Evan Montoya, David Munechika, Haoyang Yang, Benjamin Hoover, and Duen Horng Chau. Diffu- sionDB: A large-scale prompt gallery dataset for text-to- image generative models.arXiv:2210.14896 [cs], 2022. 6
-
[50]
Tiif-bench: How does your t2i model follow your instructions?, 2025
Xinyu Wei, Jinrui Zhang, Zeqing Wang, Hongyang Wei, Zhen Guo, and Lei Zhang. Tiif-bench: How does your t2i model follow your instructions?, 2025. 5
2025
-
[51]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models.arXiv preprint arXiv:2303.04671, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Autogen: Enabling next-gen llm ap- plications via multi-agent conversation framework.arXiv preprint arXiv:2308.08155, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng Yu, Ligeng Zhu, Chengyue Wu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, et al. Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer. arXiv preprint arXiv:2501.18427, 2025. 2, 3, 5, 6
-
[55]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Auto-gpt for on- line decision making: Benchmarks and additional opinions
Hui Yang, Sifu Yue, and Yunzhong He. Auto-gpt for on- line decision making: Benchmarks and additional opinions. arXiv preprint arXiv:2306.02224, 2023
-
[57]
Gpt4tools: Teaching large language model to use tools via self-instruction.Advances in Neural Information Processing Systems, 36, 2024
Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, and Ying Shan. Gpt4tools: Teaching large language model to use tools via self-instruction.Advances in Neural Information Processing Systems, 36, 2024. 2, 3
2024
-
[58]
Difflle: Diffusion-based do- main calibration for weak supervised low-light image en- hancement.International Journal of Computer Vision, 133 (5):2527–2546, 2025
Shuzhou Yang, Xuanyu Zhang, Yinhuai Wang, Jiwen Yu, Yuhan Wang, and Jian Zhang. Difflle: Diffusion-based do- main calibration for weak supervised low-light image en- hancement.International Journal of Computer Vision, 133 (5):2527–2546, 2025
2025
-
[59]
Gencompositor: Generative video compositing with diffusion transformer
Shuzhou Yang, Xiaoyu Li, Xiaodong Cun, Guangzhi Wang, Lingen Li, Ying Shan, and Jian Zhang. Gencompositor: Generative video compositing with diffusion transformer. In The Fourteenth International Conference on Learning Rep- resentations, 2026. 2
2026
-
[60]
Zhengyuan Yang, Jianfeng Wang, Linjie Li, Kevin Lin, Chung-Ching Lin, Zicheng Liu, and Lijuan Wang. Idea2img: Iterative self-refinement with gpt-4v(ision) for automatic im- age design and generation.arXiv preprint arXiv:2310.08541,
-
[61]
Alignedgen: Aligning style across generated images.arXiv preprint arXiv:2509.17088, 2025
Jiexuan Zhang, Yiheng Du, Qian Wang, Weiqi Li, Yu Gu, and Jian Zhang. Alignedgen: Aligning style across generated images.arXiv preprint arXiv:2509.17088, 2025. 2
-
[62]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reason- ing with zero data.arXiv preprint arXiv:2505.03335, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Diffagent: Fast and accurate text-to-image api selection with large lan- guage model
Lirui Zhao, Yue Yang, Kaipeng Zhang, Wenqi Shao, Yuxin Zhang, Yu Qiao, Ping Luo, and Rongrong Ji. Diffagent: Fast and accurate text-to-image api selection with large lan- guage model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6390– 6399, 2024. 2, 3
2024
-
[64]
Mindstorms in natural language- based societies of mind.arXiv preprint arXiv:2305.17066, 2023
Mingchen Zhuge, Haozhe Liu, Francesco Faccio, Dylan R Ashley, R ´obert Csord ´as, Anand Gopalakrishnan, Abdullah Hamdi, Hasan Abed Al Kader Hammoud, Vincent Her- rmann, Kazuki Irie, et al. Mindstorms in natural language- based societies of mind.arXiv preprint arXiv:2305.17066, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.