Unveiling the Limits of Large Language Models in Inferring Pragmatic Meaning from Non-Verbal Responses
Pith reviewed 2026-06-28 14:35 UTC · model grok-4.3
The pith
Large language models struggle to infer pragmatic meaning from non-verbal responses alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
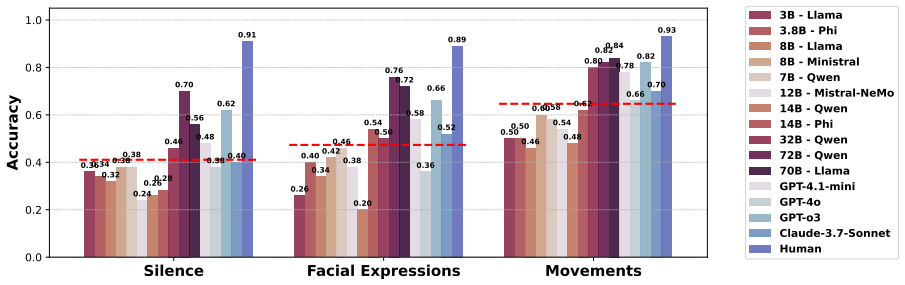
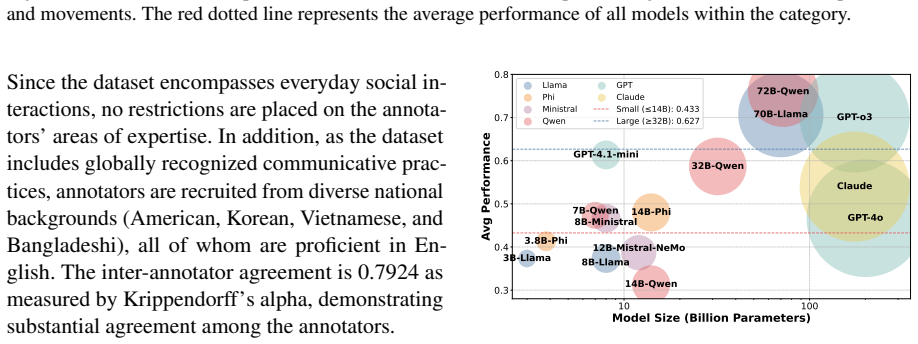
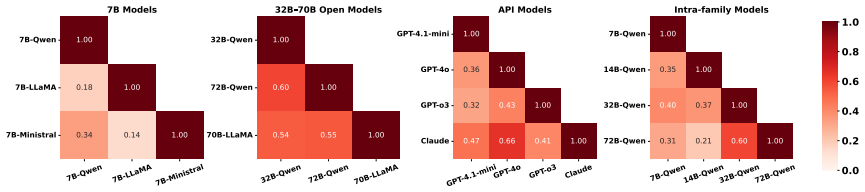
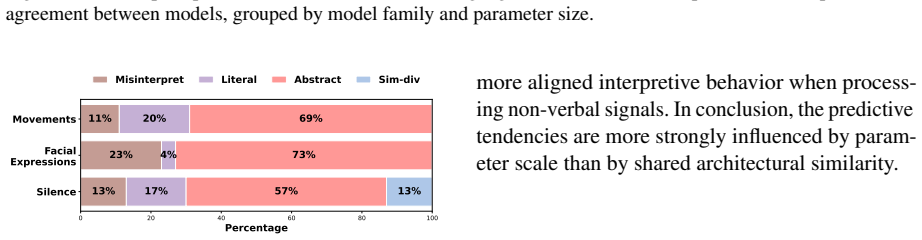
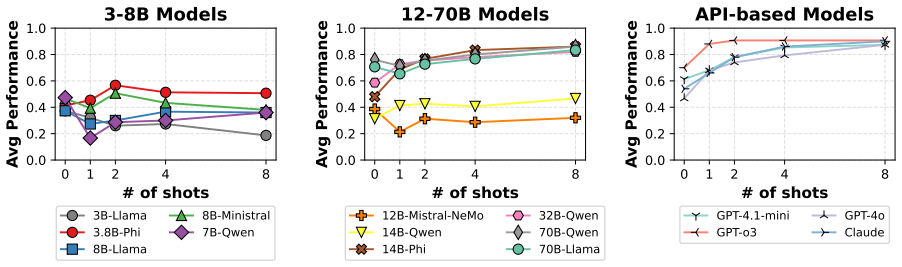
The central finding is that LLMs have difficulty recognizing indirect intent when conveyed through non-verbal responses in dialogue. Their accuracy drops by up to 60 percentage points compared to when the same intent is expressed verbally. The models exhibit specific behavioral patterns in their interpretations, and providing in-context examples helps them better capture the non-verbal intent.
What carries the argument
The set of constructed test dialogues that consist only of non-verbal responses, used to probe the models' ability to infer pragmatic meaning.
If this is right
- Models require additional techniques like in-context learning to handle non-verbal pragmatic inference effectively.
- Analysis of failure patterns can guide improvements in model training for better communication understanding.
- Non-verbal responses pose a distinct challenge separate from verbal pragmatic understanding.
Where Pith is reading between the lines
- The results may indicate that current training corpora lack sufficient examples of non-verbal pragmatic contexts.
- This could affect the reliability of LLMs in applications like virtual assistants that need to handle indirect human cues.
- Testing on real-world video or audio data with non-verbal elements would provide further validation.
Load-bearing premise
That the artificial dialogues created for the test accurately represent how non-verbal responses convey meaning in actual human conversations.
What would settle it
If models achieve similar accuracy on non-verbal and verbal versions of the dialogues when tested on independently collected real-world examples.
Figures

read the original abstract
Although large language models (LLMs) have shown considerable progress in pragmatic language understanding, prior research has focused mainly on their comprehension of verbal behavior. Nonetheless, non-verbal behavior remains a fundamental component of human communication, especially when deliberately utilized in isolation to convey indirect meanings. In this work, we present the first systematic evaluation of LLMs' ability to infer pragmatic meaning in dialogue consisting solely of non-verbal responses. We explore three research questions: (1) Can LLMs recognize indirect intent conveyed through non-verbal responses? (2) When and how do LLMs fail to capture non-verbal intent? (3) How can we improve LLMs' ability to interpret non-verbal intent?. Through the evaluation, we observe that LLMs struggle to infer underlying meaning from non-verbal responses, with accuracy dropping by up to 60% points compared to verbal ones. Further extensive analysis reveals a behavioral pattern in LLMs' interpretations of non-verbal behavior and demonstrates that in-context learning facilitates pragmatic inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to provide the first systematic evaluation of LLMs' ability to infer pragmatic meaning from dialogues consisting only of non-verbal responses. It poses three research questions on intent recognition, failure modes, and improvement strategies, reporting that LLMs show accuracy drops of up to 60 percentage points relative to verbal responses, exhibit identifiable behavioral patterns in their interpretations, and improve via in-context learning.
Significance. If the results hold after addressing methodological gaps, the work would offer timely evidence on LLM limitations in non-verbal pragmatic inference, a relatively underexplored area with relevance to dialogue systems and human-AI communication modeling.
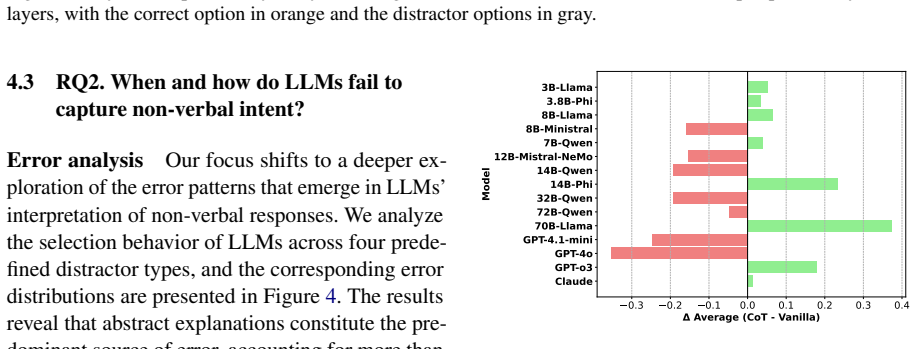
major comments (2)
- [Abstract] Abstract: the central claim of an up to 60 percentage point accuracy drop (and the ICL benefit) is presented without any reported dataset size, model count, statistical tests, variance across prompts, or baseline controls, rendering the empirical result impossible to assess from the given information.
- [Section 3] Section 3 (Evaluation Setup): the construction of the test dialogues is not described in enough detail to establish that isolated non-verbal responses (e.g., bracketed gesture or silence descriptions) isolate pragmatic difficulty rather than prompt-format rarity or author-assigned label bias; this assumption is load-bearing for the reported performance gap and behavioral-pattern analysis.
minor comments (1)
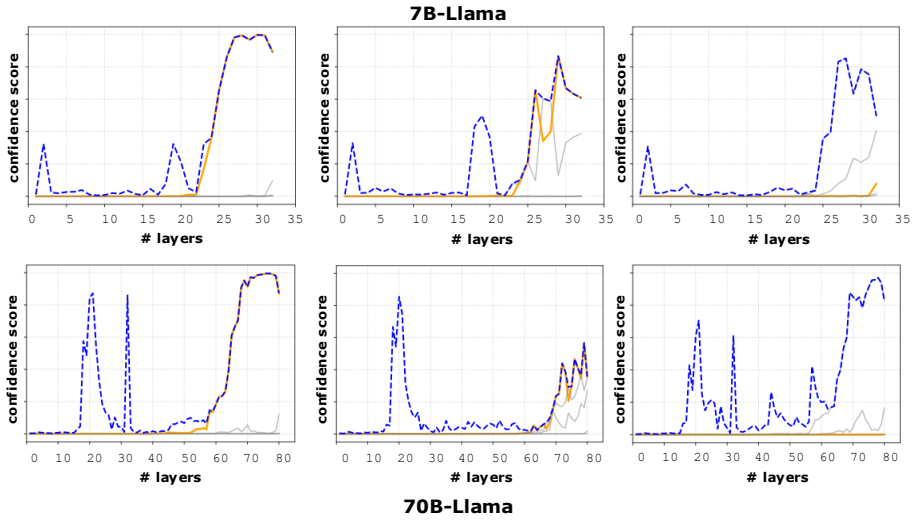
- [Section 4] The description of the three research questions and the behavioral-pattern analysis would be clearer if accompanied by a small number of concrete dialogue examples in the main text rather than only in an appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the major comments below and will make revisions to improve the clarity and completeness of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of an up to 60 percentage point accuracy drop (and the ICL benefit) is presented without any reported dataset size, model count, statistical tests, variance across prompts, or baseline controls, rendering the empirical result impossible to assess from the given information.
Authors: We agree with this observation. The abstract as currently written does not include sufficient methodological details to support the central claims. In the revised manuscript, we will update the abstract to report the dataset size, the number of models evaluated, mention of statistical tests, and any analysis of variance across prompts or baselines. This will allow readers to better assess the empirical results. revision: yes
-
Referee: [Section 3] Section 3 (Evaluation Setup): the construction of the test dialogues is not described in enough detail to establish that isolated non-verbal responses (e.g., bracketed gesture or silence descriptions) isolate pragmatic difficulty rather than prompt-format rarity or author-assigned label bias; this assumption is load-bearing for the reported performance gap and behavioral-pattern analysis.
Authors: We acknowledge that additional details are required in Section 3 to address potential confounds. We will expand the description of how the test dialogues were constructed, including the criteria for selecting non-verbal responses, the process for assigning labels, and any steps taken to mitigate prompt-format effects or bias. We will also discuss why we believe the setup isolates pragmatic difficulty. If necessary, we can add controls or ablations in the revision. revision: yes
Circularity Check
No circularity: empirical evaluation on held-out test cases
full rationale
The paper is an empirical evaluation study that constructs test dialogues, measures LLM accuracy on verbal vs. non-verbal responses, analyzes behavioral patterns, and tests in-context learning improvements. No equations, fitted parameters, predictions, or derivations appear in the provided text. Results derive directly from model outputs on the constructed cases rather than any self-referential definitions or self-citation chains. Any potential self-citations are not load-bearing for the accuracy-drop claims, satisfying the criteria for a self-contained empirical result with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM outputs on constructed non-verbal dialogue examples reflect genuine limits in pragmatic inference rather than artifacts of text-only prompting.
Reference graph
Works this paper leans on
-
[1]
1992 , publisher=
The power of silence: Social and pragmatic perspectives , author=. 1992 , publisher=
1992
-
[2]
The Twelfth International Conference on Learning Representations , year=
Overthinking the Truth: Understanding how Language Models Process False Demonstrations , author=. The Twelfth International Conference on Learning Representations , year=
-
[3]
, author=
Interpreting gpt: the logit lens, 2020. , author=. , year=
2020
-
[4]
A fine-grained comparison of pragmatic language understanding in humans and language models
Hu, Jennifer and Floyd, Sammy and Jouravlev, Olessia and Fedorenko, Evelina and Gibson, Edward. A fine-grained comparison of pragmatic language understanding in humans and language models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.230
-
[5]
Advances in Neural Information Processing Systems , editor=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[6]
Rethinking Pragmatics in Large Language Models: Towards Open-Ended Evaluation and Preference Tuning
Wu, Shengguang and Yang, Shusheng and Chen, Zhenglun and Su, Qi. Rethinking Pragmatics in Large Language Models: Towards Open-Ended Evaluation and Preference Tuning. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1258
-
[7]
M ulti P rag E val: Multilingual Pragmatic Evaluation of Large Language Models
Park, Dojun and Lee, Jiwoo and Park, Seohyun and Jeong, Hyeyun and Koo, Youngeun and Hwang, Soonha and Park, Seonwoo and Lee, Sungeun. M ulti P rag E val: Multilingual Pragmatic Evaluation of Large Language Models. Proceedings of the 2nd GenBench Workshop on Generalisation (Benchmarking) in NLP. 2024. doi:10.18653/v1/2024.genbench-1.7
-
[8]
Pragmatic Metacognitive Prompting Improves LLM Performance on Sarcasm Detection
Lee, Joshua and Fong, Wyatt and Le, Alexander and Shah, Sur and Han, Kevin and Zhu, Kevin. Pragmatic Metacognitive Prompting Improves LLM Performance on Sarcasm Detection. Proceedings of the 1st Workshop on Computational Humor (CHum). 2025
2025
-
[9]
GRICE : A Grammar-based Dataset for Recovering Implicature and Conversational r E asoning
Zheng, Zilong and Qiu, Shuwen and Fan, Lifeng and Zhu, Yixin and Zhu, Song-Chun. GRICE : A Grammar-based Dataset for Recovering Implicature and Conversational r E asoning. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.182
-
[10]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[11]
Transactions on Machine Learning Research , issn=
Emergent Abilities of Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
2022
-
[12]
Nature Human Behaviour , volume=
Emergent analogical reasoning in large language models , author=. Nature Human Behaviour , volume=. 2023 , publisher=
2023
-
[13]
2010 , publisher=
Kinesics and context: Essays on body motion communication , author=. 2010 , publisher=
2010
-
[14]
2009 , publisher=
Pragmatics and non-verbal communication , author=. 2009 , publisher=
2009
-
[15]
Speech acts , pages=
Logic and conversation , author=. Speech acts , pages=. 1975 , publisher=
1975
-
[16]
1975 , publisher=
How to do things with words , author=. 1975 , publisher=
1975
-
[17]
Speech acts , pages=
Indirect speech acts , author=. Speech acts , pages=. 1975 , publisher=
1975
-
[18]
2023 , url=
Large language models are not zero-shot communicators , author=. 2023 , url=
2023
-
[19]
P ragmati CQA : A Dataset for Pragmatic Question Answering in Conversations
Qi, Peng and Du, Nina and Manning, Christopher and Huang, Jing. P ragmati CQA : A Dataset for Pragmatic Question Answering in Conversations. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.385
-
[20]
PUB : A Pragmatics Understanding Benchmark for Assessing LLM s' Pragmatics Capabilities
Sravanthi, Settaluri and Doshi, Meet and Tankala, Pavan and Murthy, Rudra and Dabre, Raj and Bhattacharyya, Pushpak. PUB : A Pragmatics Understanding Benchmark for Assessing LLM s' Pragmatics Capabilities. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.719
-
[21]
The Goldilocks of Pragmatic Understanding: Fine-Tuning Strategy Matters for Implicature Resolution by
Laura Eline Ruis and Akbir Khan and Stella Biderman and Sara Hooker and Tim Rockt. The Goldilocks of Pragmatic Understanding: Fine-Tuning Strategy Matters for Implicature Resolution by. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[22]
1983 , publisher=
Pragmatics , author=. 1983 , publisher=
1983
-
[23]
1972 , publisher=
Nonverbal communication in human interaction , author=. 1972 , publisher=
1972
-
[24]
Annual review of psychology , volume=
Nonverbal communication , author=. Annual review of psychology , volume=. 2019 , publisher=
2019
-
[25]
the 32nd IEEE International Conference on Robot and Human Interactive Communication (RO-MAN) , pages=
Developing Social Robots with Empathetic Non-Verbal Cues Using Large Language Models.(2023) , author=. the 32nd IEEE International Conference on Robot and Human Interactive Communication (RO-MAN) , pages=
2023
-
[26]
Felbo, Bjarke and Mislove, Alan and S gaard, Anders and Rahwan, Iyad and Lehmann, Sune. Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017. doi:10.18653/v1/D17-1169
-
[27]
and Hendley, Robert and Smith, Phillip
Hakami, Shatha Ali A. and Hendley, Robert and Smith, Phillip. A r S arcas M oji Dataset: The Emoji Sentiment Roles in A rabic Ironic Contexts. Proceedings of ArabicNLP 2023. 2023. doi:10.18653/v1/2023.arabicnlp-1.18
-
[28]
Clinical psychology review , volume=
Silence as communication in psychodynamic psychotherapy , author=. Clinical psychology review , volume=. 2002 , publisher=
2002
-
[29]
Western Journal of Communication (includes Communication Reports) , volume=
The functions of silence: A plea for communication research , author=. Western Journal of Communication (includes Communication Reports) , volume=. 1974 , publisher=
1974
-
[30]
Communication theory , volume=
Functions of the nonverbal in CMC: Emoticons and illocutionary force , author=. Communication theory , volume=. 2010 , publisher=
2010
-
[31]
What A Sunny Day ☔: Toward Emoji-Sensitive Irony Detection
Hayati, Shirley Anugrah and Chaudhary, Aditi and Otani, Naoki and Black, Alan W. What A Sunny Day ☔: Toward Emoji-Sensitive Irony Detection. Proceedings of the 5th Workshop on Noisy User-generated Text (W-NUT 2019). 2019. doi:10.18653/v1/D19-5527
-
[32]
2012 , publisher=
Nonverbal behavior: A functional perspective , author=. 2012 , publisher=
2012
-
[33]
2021 , publisher=
Nonverbal communication , author=. 2021 , publisher=
2021
-
[34]
Psychiatry , volume=
Nonverbal leakage and clues to deception , author=. Psychiatry , volume=. 1969 , publisher=
1969
-
[35]
2022 , publisher=
Choices & connections: An introduction to communication , author=. 2022 , publisher=
2022
-
[36]
Current Opinion in Psychology , volume=
Connecting cues: The role of nonverbal cues in perceived responsiveness , author=. Current Opinion in Psychology , volume=. 2023 , publisher=
2023
-
[37]
ACM Transactions on Human-Robot Interaction , volume=
Nonverbal cues in human--robot interaction: A communication studies perspective , author=. ACM Transactions on Human-Robot Interaction , volume=. 2023 , publisher=
2023
-
[38]
1952 , publisher=
Introduction to kinesics:(An annotation system for analysis of body motion and gesture) , author=. 1952 , publisher=
1952
-
[39]
M. Danesi , abstract =. Kinesics , editor =. Encyclopedia of Language & Linguistics (Second Edition) , publisher =. 2006 , isbn =. doi:https://doi.org/10.1016/B0-08-044854-2/01421-8 , url =
-
[40]
Journal of communication , volume=
Communicative silences: Forms and functions , author=. Journal of communication , volume=. 1973 , publisher=
1973
-
[41]
ETC: A Review of General Semantics , pages=
Communicative functions of silence , author=. ETC: A Review of General Semantics , pages=. 1973 , publisher=
1973
-
[42]
Do Large Language Models Understand Conversational Implicature- A case study with a C hinese sitcom
Yue, Shisen and Song, Siyuan and Cheng, Xinyuan and Hu, Hai. Do Large Language Models Understand Conversational Implicature- A case study with a C hinese sitcom. Proceedings of the 23rd Chinese National Conference on Computational Linguistics (Volume 1: Main Conference). 2024
2024
-
[43]
M u T ual: A Dataset for Multi-Turn Dialogue Reasoning
Cui, Leyang and Wu, Yu and Liu, Shujie and Zhang, Yue and Zhou, Ming. M u T ual: A Dataset for Multi-Turn Dialogue Reasoning. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.130
-
[44]
Cogent Arts & Humanities , volume=
‘Yet his silence said volumes’: a pragmatic analysis of conversational silence in rapport management , author=. Cogent Arts & Humanities , volume=. 2025 , publisher=
2025
-
[45]
D aily D ialog: A Manually Labelled Multi-turn Dialogue Dataset
Li, Yanran and Su, Hui and Shen, Xiaoyu and Li, Wenjie and Cao, Ziqiang and Niu, Shuzi. D aily D ialog: A Manually Labelled Multi-turn Dialogue Dataset. Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2017
2017
-
[46]
Proceedings of the international AAAI conference on web and social media , volume=
Spice up your chat: the intentions and sentiment effects of using emojis , author=. Proceedings of the international AAAI conference on web and social media , volume=
-
[47]
CtrlGen: Controllable Generative Modeling in Language and Vision Workshop at NeurIPS 2021 , year =
Dirik, Alara and Donmez, Hilal and Yanardag, Pinar , title =. CtrlGen: Controllable Generative Modeling in Language and Vision Workshop at NeurIPS 2021 , year =
2021
-
[48]
S umm S creen: A Dataset for Abstractive Screenplay Summarization
Chen, Mingda and Chu, Zewei and Wiseman, Sam and Gimpel, Kevin. S umm S creen: A Dataset for Abstractive Screenplay Summarization. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.589
-
[49]
Royal Society Open Science , volume=
Generalization bias in large language model summarization of scientific research , author=. Royal Society Open Science , volume=. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.