WorldCoder-Bench: Benchmarking Physically Grounded 3D World Synthesis
Pith reviewed 2026-06-28 15:00 UTC · model grok-4.3
The pith
Frontier language models reach only 27.8% verification coverage when asked to generate executable 3D interactive worlds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
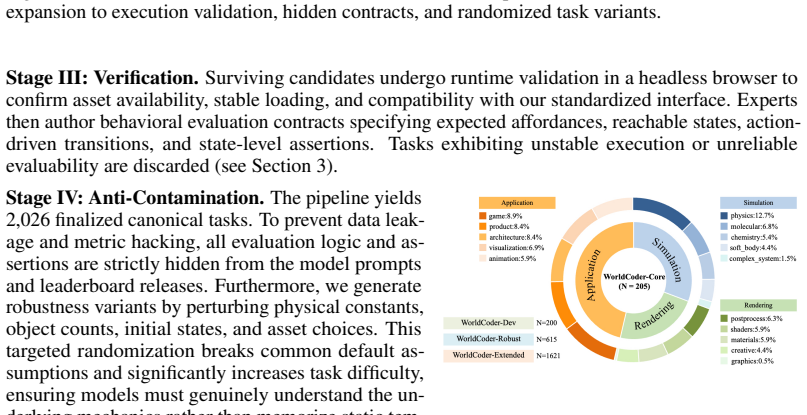
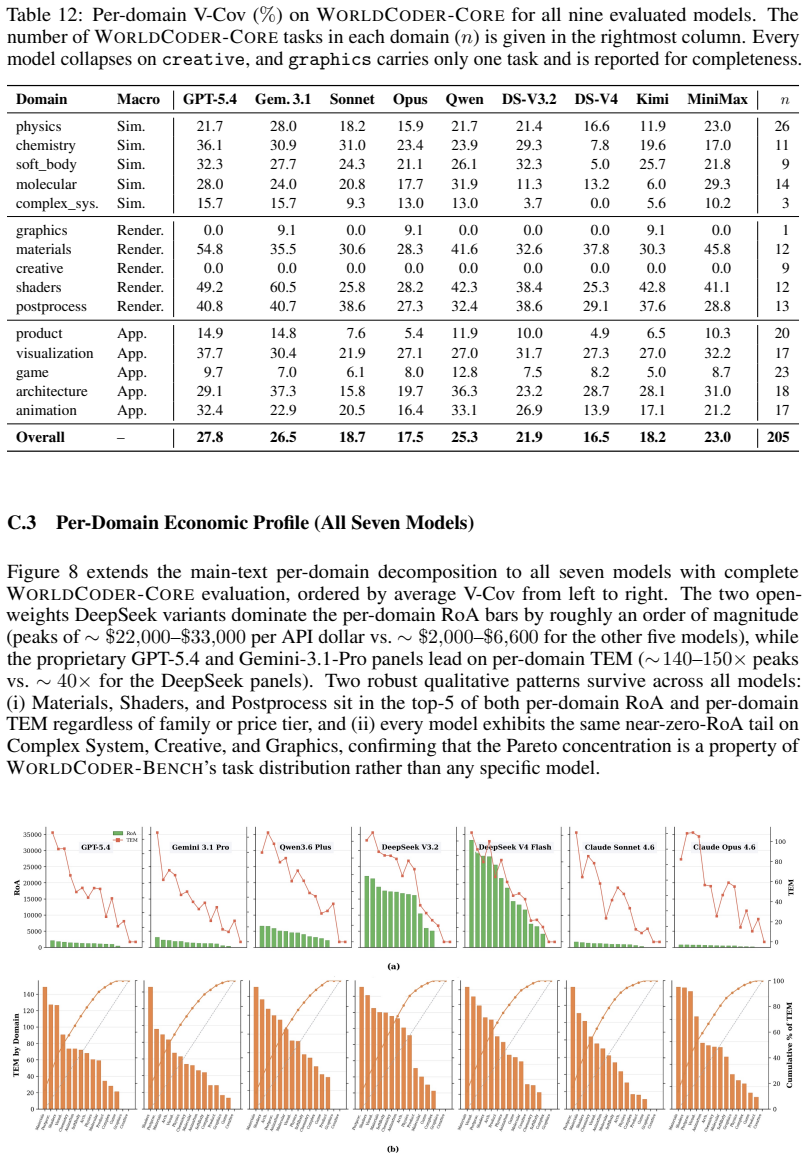
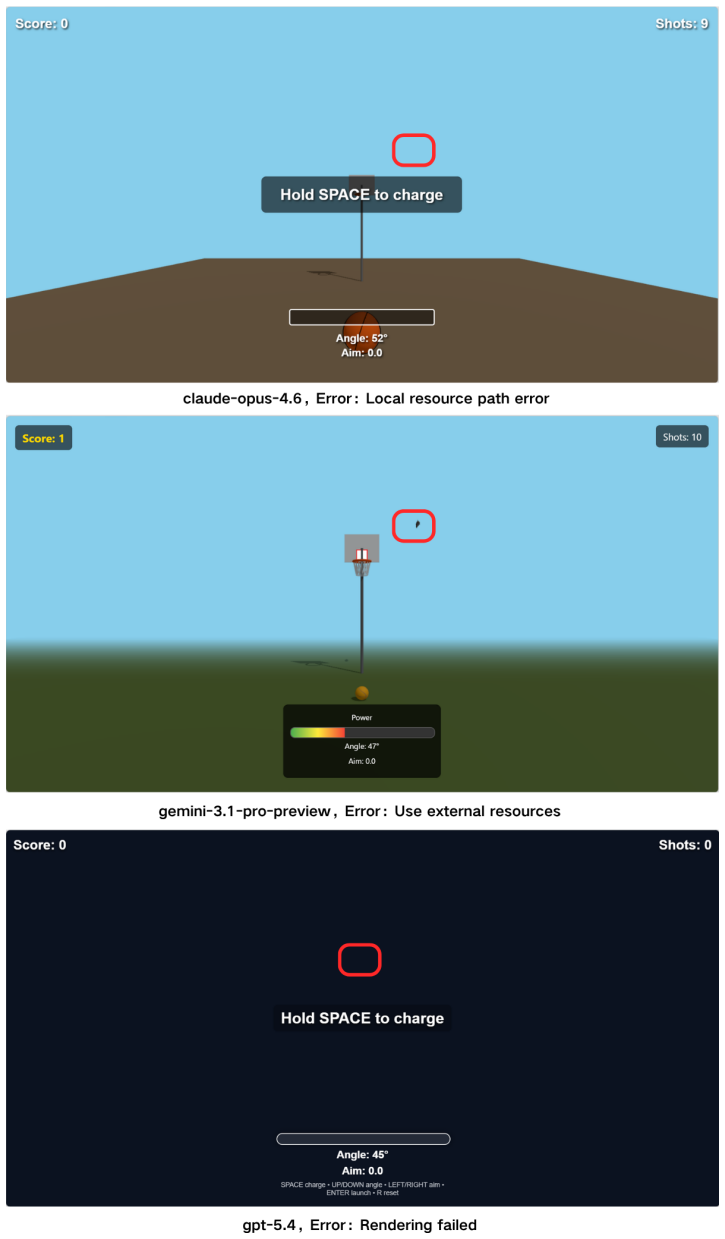
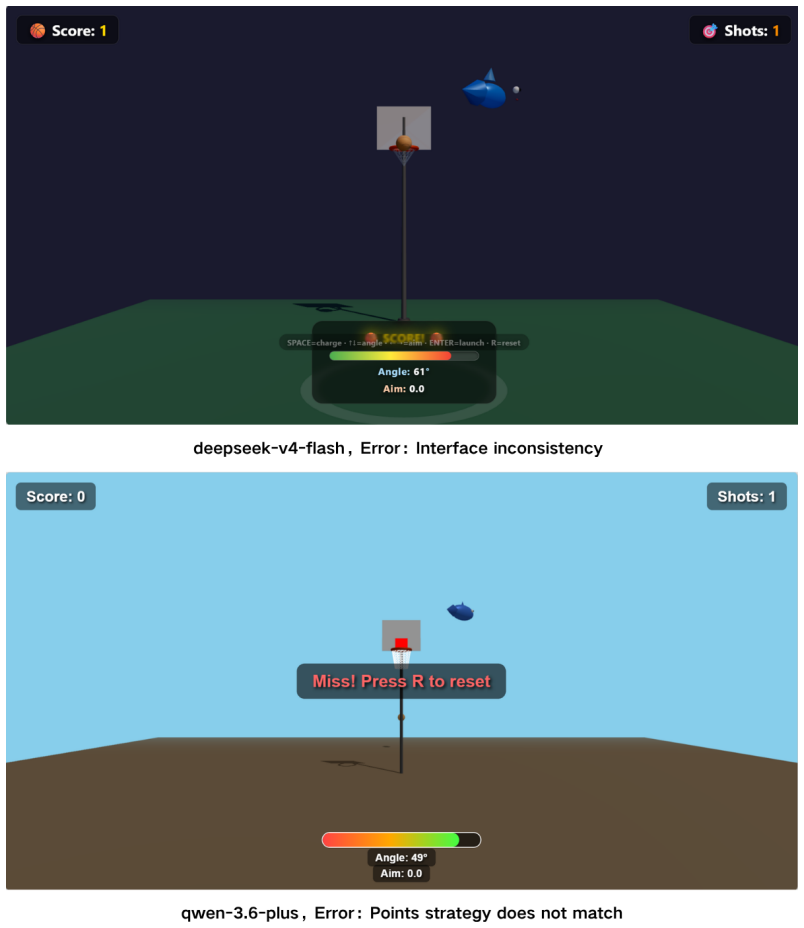
The central claim is that across nine frontier models, the best reaches only 27.8% verification coverage on WorldCoder-Core and 19.9% on WorldCoder-Robust, with failures dominated by state-schema drift and broken interaction chains rather than missing scene elements.
What carries the argument
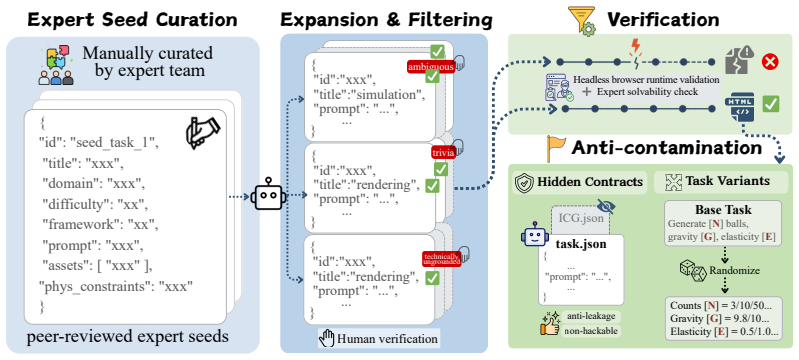
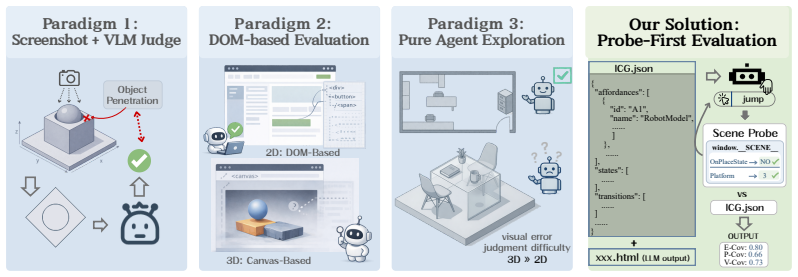
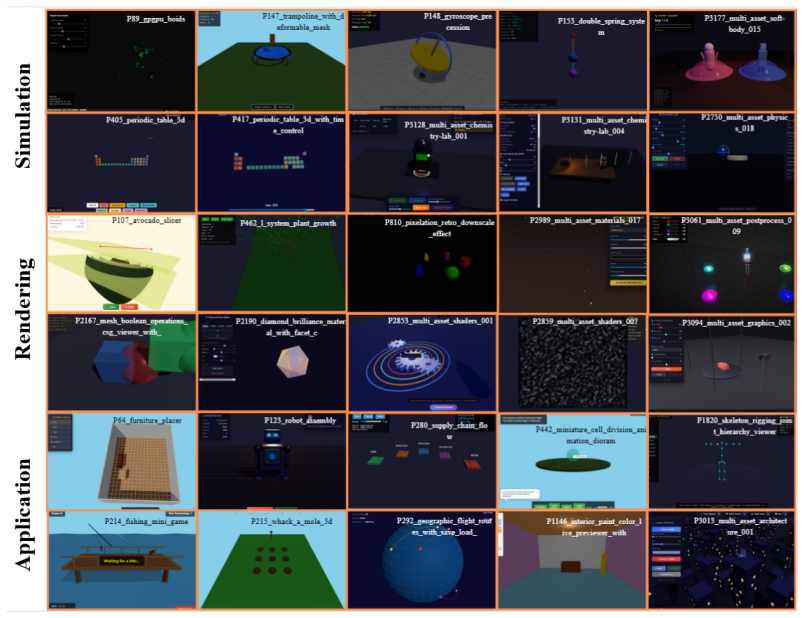
WorldCoder-Bench with its 2,026 expert-curated tasks and StateProbe protocol that verifies hidden behavioral contracts over runtime states in sandboxed browser execution.
If this is right
- Models can still deliver substantial value on easier domains even if overall scores are low.
- Utility metrics like Return on Automation and Time Efficiency Multiplier indicate correctness-adjusted cost and time savings are possible with current systems.
- Failures stem primarily from maintaining consistent state and interaction logic over time.
Where Pith is reading between the lines
- Future work on LLMs for code generation should prioritize better state tracking mechanisms for dynamic environments.
- The benchmark approach could apply to evaluating world-building in other programming environments beyond browser 3D.
- Low performance suggests that training data for LLMs may lack sufficient examples of complex interactive 3D systems.
Load-bearing premise
The 2,026 tasks and hidden behavioral contracts accurately capture the requirements for physically grounded 3D world synthesis without introducing biases.
What would settle it
A model that consistently achieves verification coverage above 50% across the full set of tasks while preserving physical constraints and interaction chains would indicate the current limitations are overstated.
Figures



read the original abstract
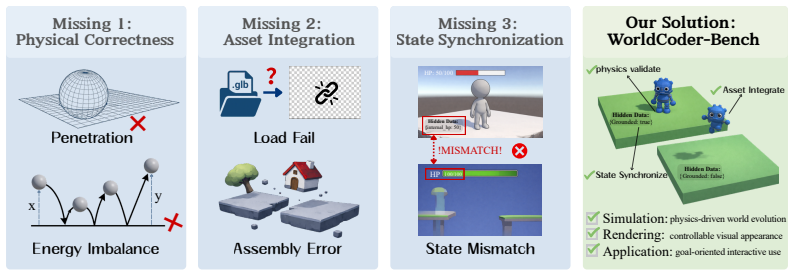
Large language models (LLMs) are increasingly asked not only to write static interfaces, but to construct executable interactive worlds from natural language. Browser-native 3D, commonly built with Three.js, is a natural next frontier: generated programs must integrate assets, obey spatial and physical constraints, and keep user-facing controls synchronized with hidden runtime state. Existing web-generation benchmarks and evaluators, however, largely observe only pixels or DOM nodes, while the mechanics of a Three.js world unfold inside an opaque <canvas>. We introduce WorldCoder-Bench, a benchmark for autonomous, physically grounded 3D world synthesis. WorldCoder-Bench contains 2,026 expert-curated tasks across Simulation, Rendering, and Application scenarios, with optional .glb assets and hidden behavioral contracts. We further propose StateProbe, an execution-based protocol that probes generated programs in a sandboxed browser and verifies hidden, mutation-hardened contracts over runtime states and transitions. Beyond verification coverage, we report Return on Automation and Time Efficiency Multiplier to measure correctness-adjusted cost and time savings. Across nine frontier models, the best system reaches only 27.8% verification coverage on WorldCoder-Core and 19.9% on WorldCoder-Robust, with failures dominated by state-schema drift and broken interaction chains rather than missing scene elements. Utility metrics further show that cheap or fast models can still provide substantial value on easier domains. WorldCoder-Bench is available at https://anonymous.4open.science/r/WorldCoder-Bench/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WorldCoder-Bench, a benchmark containing 2,026 expert-curated tasks across Simulation, Rendering, and Application scenarios for evaluating LLMs on generating executable, physically grounded 3D interactive worlds in Three.js from natural language. It proposes StateProbe, an execution-based verification protocol that runs generated programs in a sandboxed browser to check hidden, mutation-hardened behavioral contracts over runtime states and transitions. The evaluation of nine frontier models reports that the best system achieves only 27.8% verification coverage on WorldCoder-Core and 19.9% on WorldCoder-Robust, with failures dominated by state-schema drift and broken interaction chains; it also introduces Return on Automation and Time Efficiency Multiplier metrics to quantify correctness-adjusted cost and time savings. The benchmark is made publicly available.
Significance. If the task curation and StateProbe protocol hold up under scrutiny, the work provides a meaningful advance by shifting evaluation of 3D world synthesis from pixel/DOM observation to functional verification of hidden runtime behavior and physical constraints. The reported performance ceilings and failure-mode analysis usefully quantify current LLM limitations in this domain, while the utility metrics offer a practical lens on when cheaper or faster models remain valuable. Public release of the benchmark supports reproducibility and community follow-up.
major comments (2)
- [StateProbe protocol description] The abstract and high-level description leave the exact definition and implementation of StateProbe (including how behavioral contracts are encoded, how mutation-hardening is achieved, and how sandbox probing interacts with Three.js runtime state) insufficiently specified; this is load-bearing for the central claim that failures are dominated by state-schema drift rather than verification artifacts.
- [Task curation and benchmark construction] The claim that the 2,026 tasks accurately capture requirements for physically grounded synthesis without selection bias rests on expert curation whose process, inter-annotator agreement, and coverage of edge cases in spatial/physical constraints are not detailed enough to support the reported performance numbers and failure-mode conclusions.
minor comments (1)
- [Abstract] The anonymous repository link should be replaced with a permanent identifier or GitHub URL in the camera-ready version.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript to improve clarity and completeness on the specified aspects.
read point-by-point responses
-
Referee: [StateProbe protocol description] The abstract and high-level description leave the exact definition and implementation of StateProbe (including how behavioral contracts are encoded, how mutation-hardening is achieved, and how sandbox probing interacts with Three.js runtime state) insufficiently specified; this is load-bearing for the central claim that failures are dominated by state-schema drift rather than verification artifacts.
Authors: We agree that the abstract and initial high-level overview are insufficiently detailed for a load-bearing component. While the full manuscript provides additional description in the methods, we will expand both the abstract and the main text (including a new implementation subsection) to explicitly cover behavioral contract encoding, mutation-hardening mechanisms, and sandbox probing interactions with Three.js runtime state. This revision will strengthen support for the failure-mode analysis. revision: yes
-
Referee: [Task curation and benchmark construction] The claim that the 2,026 tasks accurately capture requirements for physically grounded synthesis without selection bias rests on expert curation whose process, inter-annotator agreement, and coverage of edge cases in spatial/physical constraints are not detailed enough to support the reported performance numbers and failure-mode conclusions.
Authors: We acknowledge that the current description of expert curation lacks sufficient detail on process, inter-annotator agreement, and edge-case coverage. We will add a new subsection to the benchmark construction section that specifies the curation protocol, reports agreement metrics, and describes how spatial and physical constraint edge cases were addressed. This will better substantiate the benchmark validity and performance claims. revision: yes
Circularity Check
No circularity: benchmark construction and empirical evaluation are independent of fitted inputs or self-referential derivations.
full rationale
The paper introduces a new benchmark (WorldCoder-Bench with 2,026 tasks) and an execution-based verification protocol (StateProbe) for evaluating LLM-generated 3D worlds. Performance numbers (e.g., 27.8% verification coverage) are direct empirical measurements on held-out tasks rather than predictions derived from equations, fitted parameters, or prior self-citations. No load-bearing steps reduce to self-definition, renamed known results, or uniqueness theorems imported from the authors' own work. The derivation chain consists of task curation and sandboxed execution, which are externally verifiable and do not loop back to the reported metrics by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Design2code: Benchmarking multimodal code generation for automated front-end engineering
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2code: Benchmarking multimodal code generation for automated front-end engineering. InProc. NAACL, pages 3956–3974, 2025
2025
-
[2]
Webarena: A realistic web environment for building autonomous agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents. InProc. ICLR, 2023
2023
-
[3]
Chenchen Zhang, Yuhang Li, Can Xu, Jiaheng Liu, Ao Liu, Changzhi Zhou, Ken Deng, Dengpeng Wu, Guanhua Huang, Kejiao Li, et al. Artifactsbench: Bridging the visual-interactive gap in llm code generation evaluation.arXiv preprint arXiv:2507.04952, 2025
-
[4]
Openclaw research: A systematic survey of large language model agents in open deployment
Shuo Lu, Kecheng Yu, Siru Jiang, Yinuo Xu, Bing Zhan, Yanbo Wang, Changxin Ke, Yuan Xu, Xin Xiong, Xinyun Zhou, et al. Openclaw research: A systematic survey of large language model agents in open deployment. 2026
2026
-
[5]
Thomas Steenbergen and Michael S Lew. Analysis of using browser-native technology to build rich internet applications for image manipulation.arXiv preprint arXiv:1101.0235, 2010
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
3d virtual worlds and the metaverse: Current status and future possibilities.ACM computing surveys (CSUR), 45(3):1–38, 2013
John David N Dionisio, William G Burns Iii, and Richard Gilbert. 3d virtual worlds and the metaverse: Current status and future possibilities.ACM computing surveys (CSUR), 45(3):1–38, 2013
2013
-
[7]
Hydro3djs: A modular web- based library for real-time 3d visualization of watershed dynamics and digital twin integration
Ramteja Sajja, Omer Mermer, Yusuf Sermet, and Ibrahim Demir. Hydro3djs: A modular web- based library for real-time 3d visualization of watershed dynamics and digital twin integration. Environmental Modelling & Software, page 106853, 2025
2025
-
[8]
Ahmed Fawzy, Amjed Tahir, and Kelly Blincoe. Vibe coding in practice: Motivations, chal- lenges, and a future outlook–a grey literature review.arXiv preprint arXiv:2510.00328, 2025
-
[9]
Prentice Hall Professional, 2004
Michael Feathers.Working effectively with legacy code. Prentice Hall Professional, 2004
2004
-
[10]
Out-of- distribution detection: A task-oriented survey of recent advances.ACM Computing Surveys, 58 (2):1–39, 2025
Shuo Lu, Yingsheng Wang, Lijun Sheng, Lingxiao He, Aihua Zheng, and Jian Liang. Out-of- distribution detection: A task-oriented survey of recent advances.ACM Computing Surveys, 58 (2):1–39, 2025
2025
-
[11]
Hugo Laurençon, Léo Tronchon, and Victor Sanh. Unlocking the conversion of web screenshots into html code with the websight dataset.arXiv preprint arXiv:2403.09029, 2024
-
[12]
Hongda Zhu, Yiwen Zhang, Bing Zhao, Jingzhe Ding, Siyao Liu, Tong Liu, Dandan Wang, Yanan Liu, and Zhaojian Li. Frontendbench: A benchmark for evaluating llms on front-end development via automatic evaluation.arXiv preprint arXiv:2506.13832, 2025
-
[13]
Kai Xu, YiWei Mao, XinYi Guan, and ZiLong Feng. Web-bench: A llm code benchmark based on web standards and frameworks.arXiv preprint arXiv:2505.07473, 2025
-
[14]
Yang Chen, Minghao Liu, Yufan Shen, Yunwen Li, Tianyuan Huang, Xinyu Fang, Tianyu Zheng, Wenxuan Huang, Cheng Yang, Daocheng Fu, et al. Iwr-bench: Can lvlms reconstruct interactive webpage from a user interaction video?arXiv preprint arXiv:2509.24709, 2025
-
[15]
Gamedevbench: Evaluating agentic capabilities through game development
Wayne Chi, Yixiong Fang, Arnav Yayavaram, Siddharth Yayavaram, Seth Karten, Qiuhong Anna Wei, Runkun Chen, Alexander Wang, Valerie Chen, Ameet Talwalkar, et al. Gamedevbench: Evaluating agentic capabilities through game development. InProc. ICML, 2026
2026
-
[16]
Wei Zhang, Jack Yang, Renshuai Tao, Lingzheng Chai, Shawn Guo, Jiajun Wu, Xiaoming Chen, Ganqu Cui, Ning Ding, Xander Xu, et al. V-gamegym: Visual game generation for code large language models.arXiv preprint arXiv:2509.20136, 2025. 10
-
[17]
Uni-layout: Integrating human feedback in unified layout generation and evaluation
Shuo Lu, Yanyin Chen, Wei Feng, Jiahao Fan, Fengheng Li, Zheng Zhang, Jingjing Lv, Junjie Shen, Ching Law, and Jian Liang. Uni-layout: Integrating human feedback in unified layout generation and evaluation. InProceedings of the 33rd ACM International Conference on Multimedia, pages 7709–7718, 2025
2025
-
[18]
pix2code: Generating code from a graphical user interface screenshot
Tony Beltramelli. pix2code: Generating code from a graphical user interface screenshot. In Proc. CHI, pages 1–6, 2018
2018
-
[19]
Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping
Jingyu Xiao, Yuxuan Wan, Yintong Huo, Zixin Wang, Xinyi Xu, Wenxuan Wang, Zhiyao Xu, Yuhang Wang, and Michael R Lyu. Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping. InProc. ASE. IEEE, 2025
2025
-
[20]
Shuo Lu, Yinuo Xu, Jianjie Cheng, Lingxiao He, Meng Wang, and Jian Liang. Deepresearch- slice: Bridging the retrieval-utilization gap via explicit text slicing.arXiv preprint arXiv:2601.03261, 2025
-
[21]
Shuo Lu, Haohan Wang, Wei Feng, Weizhen Wang, Shen Zhang, Yaoyu Li, Ao Ma, Zheng Zhang, Jingjing Lv, Junjie Shen, et al. One size, many fits: Aligning diverse group-wise click preferences in large-scale advertising image generation.arXiv preprint arXiv:2602.02033, 2026
-
[22]
Webdevjudge: Evaluating (m) llms as critiques for web development quality
Chunyang Li, Yilun Zheng, Xinting Huang, Tianqing Fang, Jiahao Xu, Lihui Chen, Yangqiu Song, and Han Hu. Webdevjudge: Evaluating (m) llms as critiques for web development quality. InProc. ICLR, 2025
2025
-
[23]
Do MLLMs Really Understand Space? A Mathematical Reasoning Evaluation
Shuo Lu, Jianjie Cheng, Yinuo Xu, Yongcan Yu, Lijun Sheng, Peijie Wang, Siru Jiang, Yongguan Hu, Run Ling, Yihua Shao, et al. Do mllms really understand space? a mathematical reasoning evaluation.arXiv preprint arXiv:2602.11635, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
An analysis and survey of the development of mutation testing
Yue Jia and Mark Harman. An analysis and survey of the development of mutation testing. IEEE transactions on software engineering, 37(5):649–678, 2010
2010
-
[25]
Webgl developer salary in web development startups
Wellfound. Webgl developer salary in web development startups. https://wellfound.com/ hiring-data/i/web-development/s/webgl, 2025. Accessed 2026-05-07
2025
-
[26]
Web developer salary in united states
Talent.com. Web developer salary in united states. https://www.talent.com/salary? job=web%2Bdeveloper, 2026. Accessed 2026-05-07
2026
-
[27]
Introducing gpt -5.4, 2026
openai. Introducing gpt -5.4, 2026. URL https://openai.com/index/ introducing-gpt-5-4/. Accessed: 2026-03-05
2026
-
[28]
Introducing claude opus 4.6, 2026
anthropic. Introducing claude opus 4.6, 2026. URL https://www.anthropic.com/news/ claude-opus-4-6. Accessed: 2026-02-17
2026
-
[29]
Introducing claude sonnet 4.6, 2026
anthropic. Introducing claude sonnet 4.6, 2026. URL https://www.anthropic.com/news/ claude-sonnet-4-6. Accessed: 2026-02-17
2026
-
[30]
Gemini 3.1 pro: A smarter model for your most complex tasks,
google. Gemini 3.1 pro: A smarter model for your most complex tasks,
-
[31]
Accessed: 2026-02-19
URL https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro. Accessed: 2026-02-19
2026
-
[32]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Qwen3.6-plus: Towards real world agents, 2026
Alibaba. Qwen3.6-plus: Towards real world agents, 2026. URL https://qwen.ai/blog? id=qwen3.6. Accessed: 2026-04-02
2026
-
[34]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Minimax m2.7 deep dive: Why minimax m2.7 is becoming a core agentic productivity model, 2026
Xiaomi. Minimax m2.7 deep dive: Why minimax m2.7 is becoming a core agentic productivity model, 2026. URLhttps://minimax-m2.com/minimax-m27. Accessed: 2026-03. 11
2026
-
[36]
Deepseek-v4 preview: Entering the era of millions of contexts for everyone, 2026
deepseek. Deepseek-v4 preview: Entering the era of millions of contexts for everyone, 2026. URL https://mp.weixin.qq.com/s/8bxXqS2R8Fx5-1TLDBiEDg. Accessed: 2026-04-24
2026
-
[37]
Webuibench: a comprehensive benchmark for evaluating multimodal large language models in webui-to-code
Zhiyu Lin, Zhengda Zhou, Zhiyuan Zhao, Tianrui Wan, Yilun Ma, Junyu Gao, and Xuelong Li. Webuibench: a comprehensive benchmark for evaluating multimodal large language models in webui-to-code. InProc. ACL, pages 15780–15797, 2025
2025
-
[38]
Jingyu Xiao, Man Ho Lam, Ming Wang, Yuxuan Wan, Junliang Liu, Yintong Huo, and Michael R Lyu. Designbench: A comprehensive benchmark for mllm-based front-end code generation.arXiv preprint arXiv:2506.06251, 2025
-
[39]
Chenxu Liu, Yingjie Fu, Wei Yang, Ying Zhang, and Tao Xie. Webcoderbench: Benchmarking web application generation with comprehensive and interpretable evaluation metrics.arXiv preprint arXiv:2601.02430, 2026
-
[40]
Webgen-bench: Evaluating llms on generating interactive and functional websites from scratch
Zimu Lu, Yunqiao Yang, Houxing Ren, Haotian Hou, Han Xiao, Ke Wang, Weikang Shi, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Webgen-bench: Evaluating llms on generating interactive and functional websites from scratch. InProc. NeurIPS, 2025
2025
-
[41]
Mind2web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. InProc. NeurIPS, 2023
2023
-
[42]
Weblinx: Real-world website navigation with multi-turn dialogue
Xing Han Lù, Zdenˇek Kasner, and Siva Reddy. Weblinx: Real-world website navigation with multi-turn dialogue. InProc. ICML, 2024
2024
-
[43]
Xiao Cai, Sitong Su, Jingkuan Song, Pengpeng Zeng, Ji Zhang, Qinhong Du, Mengqi Li, Heng Tao Shen, and Lianli Gao. Gt23d-bench: A comprehensive general text-to-3d generation benchmark.arXiv preprint arXiv:2412.09997, 2024
-
[44]
Relscene: A benchmark and baseline for spatial relations in text-driven 3d scene generation
Zhaoda Ye, Xinhan Zheng, Yang Liu, and Yuxin Peng. Relscene: A benchmark and baseline for spatial relations in text-driven 3d scene generation. InProc. ACM-MM, pages 10563–10571, 2024
2024
-
[45]
Scenethesis: A language and vision agentic framework for 3d scene generation
Lu Ling, Chen-Hsuan Lin, Tsung-Yi Lin, Yifan Ding, Yu Zeng, Yichen Sheng, Yunhao Ge, Ming-Yu Liu, Aniket Bera, and Zhaoshuo Li. Scenethesis: A language and vision agentic framework for 3d scene generation. InProc. ICLR, 2025
2025
-
[46]
Physcene: Physically interactable 3d scene synthesis for embodied ai
Yandan Yang, Baoxiong Jia, Peiyuan Zhi, and Siyuan Huang. Physcene: Physically interactable 3d scene synthesis for embodied ai. InProc. CVPR, pages 16262–16272, 2024
2024
-
[47]
Intphys: A framework and benchmark for visual intuitive physics reasoning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018
Ronan Riochet, Mario Ynocente Castro, Mathieu Bernard, Adam Lerer, Rob Fergus, Véronique Izard, and Emmanuel Dupoux. Intphys: A framework and benchmark for visual intuitive physics reasoning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018
2018
-
[48]
Physion: Evaluating physical prediction from vision in humans and machines
Daniel M Bear, Elias Wang, Damian Mrowca, Felix J Binder, Hsiao-Yu Fish Tung, RT Pramod, Cameron Holdaway, Sirui Tao, Kevin Smith, Fan-Yun Sun, et al. Physion: Evaluating physical prediction from vision in humans and machines. InProc. NeurIPS, 2021
2021
-
[49]
Phyre: A new benchmark for physical reasoning
Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, and Ross Girshick. Phyre: A new benchmark for physical reasoning. InProc. NeurIPS, 2019
2019
-
[50]
Morpheus: Towards automated {SLOs} for enterprise clusters
Sangeetha Abdu Jyothi, Carlo Curino, Ishai Menache, Shravan Matthur Narayanamurthy, Alexey Tumanov, Jonathan Yaniv, Ruslan Mavlyutov, Inigo Goiri, Subru Krishnan, Janardhan Kulkarni, et al. Morpheus: Towards automated {SLOs} for enterprise clusters. InProc. OSDI, pages 117–134, 2016. 12 A Related Work A.1 Benchmarks for Web, Frontend, and Game Code Genera...
2016
-
[51]
Behavioral contracts (SIG, action sequence, assertions) are never included in the model prompt
-
[52]
Different parameter instances reference different 3D asset files, preventing memorization of asset filenames
-
[53]
Physical constants (gravity, elasticity), object counts, prompt phrasing, and initial states are randomized per variant in WORLDCODER-ROBUST
-
[54]
Tasks are original designs authored by 3D-graphics experts; they are not reproductions of publicThree.jstutorials or example galleries
-
[55]
id ": " P 2 5 3 _ b a s k e t b a l l _ f r e e _ t h r o w _ w i t h _ p a r t i c l e _ e f f e
Hidden-split contracts and reference outputs are kept strictly private; only WORLDCODER- DEVreleases reference traces for evaluator integration. 15 C Extended Experimental Results C.1 Cost / Time Accounting and Hourly-Rate Sensitivity The RoA and TEM values in Table 1 are computed directly from per-task evidence rather than aggregate estimates. We documen...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.