Mechanistic Diagnostics of Spatial Lexical Bias in Multimodal Large Language Model Spatial Reasoning
Pith reviewed 2026-06-28 14:27 UTC · model grok-4.3
The pith
Multimodal models' spatial errors often trace to language-side lexical bias where added option words override internally available correct relations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
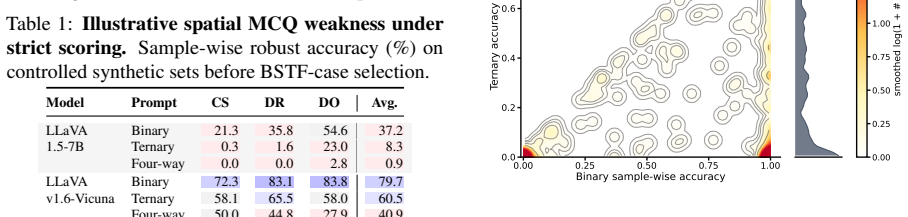
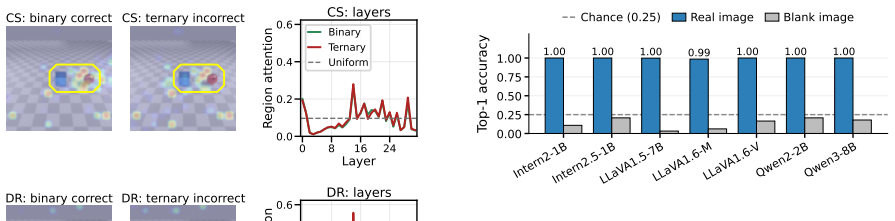
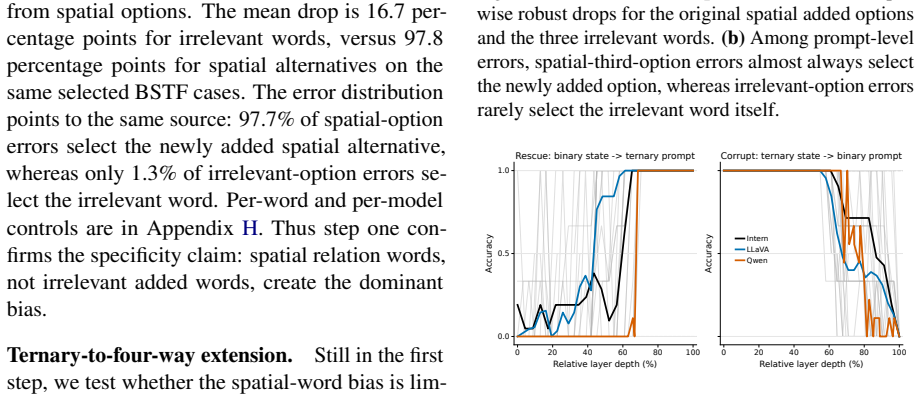
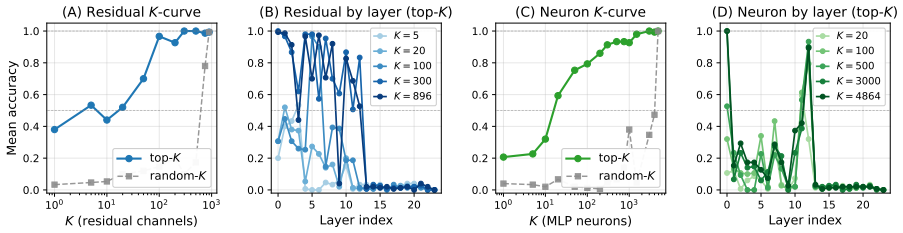
The paper establishes that a substantial share of MLLM spatial multiple-choice failures stems from spatial lexical bias on the language side. In diagnostic cases the model selects the correct binary answer but consistently picks a newly introduced incorrect spatial option; visual attention and residual-stream analyses confirm the proper relation stays internally represented, while irrelevant-option controls, activation patching, and sparse component interventions localize the bias to particular LLM-side channels and neurons. A targeted LLM-only DPO step on minimal single-object-pair synthetic data then mitigates the bias, producing large accuracy gains that transfer to broader datasets.
What carries the argument
Binary-stable but ternary-fragile diagnostic cases, tracked via visual attention maps, residual-stream probes, activation patching, and sparse interventions that isolate LLM-side channels and neurons.
If this is right
- Correct spatial relations remain internally available from vision on the identified failure cases.
- Irrelevant-option controls and patching experiments localize the bias to specific LLM channels and neurons rather than vision modules.
- An LLM-only DPO update on tiny synthetic single-object-pair data raises four-way robust accuracy by up to 100 points on synthetic tests.
- The same update produces gains of 68.0, 32.6, and 20.1 points on the WhatsUp, SpatialMQA-Direct, and VSR benchmarks.
- The lexical bias pattern appears consistently across nine open-weight MLLMs.
Where Pith is reading between the lines
- The same diagnostic cases and patching methods could be applied to detect lexical biases in non-spatial multiple-choice tasks.
- If the bias originates in language channels, similar option-word effects may appear in other multimodal reasoning domains such as temporal or causal questions.
- The lightweight DPO recipe suggests a practical route for targeted debiasing without retraining the vision encoder.
Load-bearing premise
The binary-stable ternary-fragile cases represent the main spatial failures and the DPO fix on tiny synthetic data generalizes to real distributions without creating new biases.
What would settle it
Running the DPO update on the synthetic data and then measuring whether four-way accuracy on SpatialMQA-Direct or VSR remains unchanged or drops would directly test the generalization claim.
Figures




read the original abstract
Multimodal large language models (MLLMs) remain unreliable on spatial multiple-choice questions, and their failures are often attributed to poorly attended visual information. In this work, we identify a complementary failure mode, spatial lexical bias: adding a spatial relation word to the answer options can attract the model's decision and make the newly added option likely to be selected. Using nine open-weight MLLMs, we show that this phenomenon is widely observed. In particular, models can answer a binary spatial question correctly, yet consistently select an incorrect third spatial option once it is added to the answer set. We isolate such binary-stable but ternary-fragile cases as diagnostic examples and leverage mechanistic interpretability tools, revealing that a substantial part of the failure instead originates on the language side rather than the visual side: visual attention analyses and residual-stream probes show the correct spatial relation remains internally available on these failures, while irrelevant-option controls, activation patching, and sparse component interventions trace the bias to specific LLM-side channels and neurons. Based on this finding, we show that a lightweight LLM-only DPO update on tiny single-object-pair synthetic data mitigates the bias, lifting four-way robust accuracy by up to 100 points on synthetic data, and by 68.0, 32.6, and 20.1 points on broader evaluation datasets WhatsUp, SpatialMQA-Direct, and VSR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a 'spatial lexical bias' in nine open-weight MLLMs on multiple-choice spatial questions: models that correctly answer binary spatial queries often select an incorrect third option when a spatial relation word is added to the answer set. Using visual attention, residual-stream probes, activation patching, and sparse interventions on isolated 'binary-stable but ternary-fragile' cases, the authors argue that the bias originates primarily on the language side rather than the visual side. They further show that a lightweight LLM-only DPO update trained on tiny synthetic single-object-pair data lifts robust accuracy by up to 100 points on synthetic tests and by 68.0, 32.6, and 20.1 points on WhatsUp, SpatialMQA-Direct, and VSR.
Significance. If the language-side attribution and the effectiveness of the narrow DPO intervention hold under broader scrutiny, the work supplies concrete mechanistic evidence that lexical option bias can dominate spatial failures even when visual information is internally available, together with a low-cost mitigation that transfers to held-out benchmarks. The combination of diagnostic case isolation, multiple interpretability methods, and measurable accuracy gains on real datasets would be a useful contribution to the growing literature on MLLM failure modes.
major comments (2)
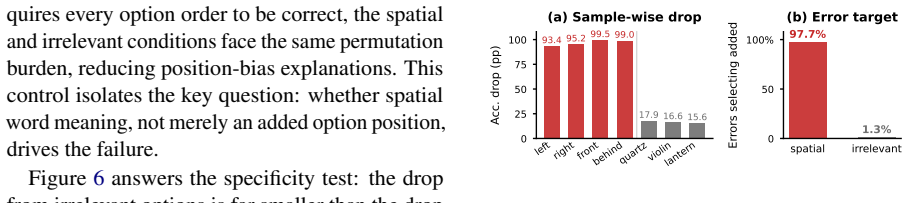
- [§4 and §5.1] §4 (Diagnostic Case Construction) and §5.1 (Evaluation on Broader Datasets): The paper isolates binary-stable/ternary-fragile examples for mechanistic analysis and reports large accuracy lifts on WhatsUp/SpatialMQA-Direct/VSR after DPO, but provides no breakdown of what fraction of total errors on those benchmarks fall into the binary-stable/ternary-fragile category. Without this statistic or an error-mode analysis showing that the selected cases dominate overall failures, the claim that language-side lexical bias constitutes 'a substantial part' of spatial reasoning errors rests on an unverified representativeness assumption.
- [§5.3] §5.3 (DPO Mitigation): The DPO update is performed exclusively on tiny synthetic single-object-pair data, yet the reported gains on VSR and WhatsUp (which contain multi-object, occluded, and relational scenes) are presented without controls for distribution shift or new failure modes. An ablation measuring performance on held-out multi-object or out-of-distribution spatial queries before and after the update would be required to establish that the mitigation removes the claimed mechanism rather than exploiting a narrow synthetic-to-real shortcut.
minor comments (2)
- [Table 1, Figure 3] Table 1 and Figure 3: The caption and axis labels should explicitly state the number of models and the exact option-set sizes used for the 'binary' vs. 'ternary' conditions so that readers can assess the scale of the reported consistency.
- [§3.2] §3.2 (Irrelevant-Option Controls): The description of how 'irrelevant' options are constructed is brief; adding one sentence on whether lexical overlap with the query or visual grounding was controlled would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§4 and §5.1] §4 (Diagnostic Case Construction) and §5.1 (Evaluation on Broader Datasets): The paper isolates binary-stable/ternary-fragile examples for mechanistic analysis and reports large accuracy lifts on WhatsUp/SpatialMQA-Direct/VSR after DPO, but provides no breakdown of what fraction of total errors on those benchmarks fall into the binary-stable/ternary-fragile category. Without this statistic or an error-mode analysis showing that the selected cases dominate overall failures, the claim that language-side lexical bias constitutes 'a substantial part' of spatial reasoning errors rests on an unverified representativeness assumption.
Authors: We agree that a quantitative breakdown would strengthen the representativeness argument. In the revised manuscript we will add an error-mode analysis on WhatsUp, SpatialMQA-Direct, and VSR that reports the fraction of total errors matching the binary-stable/ternary-fragile pattern, thereby grounding the claim that language-side lexical bias forms a substantial part of observed spatial failures. revision: yes
-
Referee: [§5.3] §5.3 (DPO Mitigation): The DPO update is performed exclusively on tiny synthetic single-object-pair data, yet the reported gains on VSR and WhatsUp (which contain multi-object, occluded, and relational scenes) are presented without controls for distribution shift or new failure modes. An ablation measuring performance on held-out multi-object or out-of-distribution spatial queries before and after the update would be required to establish that the mitigation removes the claimed mechanism rather than exploiting a narrow synthetic-to-real shortcut.
Authors: We acknowledge that explicit controls for distribution shift are needed. In revision we will add an ablation that evaluates the DPO-updated model on held-out multi-object synthetic queries (generated from the same procedure but excluded from training) before and after the update, confirming that gains arise from removal of the identified language-side bias rather than a narrow shortcut. revision: yes
Circularity Check
No circularity: empirical diagnostics and standard DPO mitigation are self-contained
full rationale
The paper performs empirical identification of spatial lexical bias via attention analysis, residual probes, activation patching, and sparse interventions on binary-stable/ternary-fragile cases, followed by LLM-only DPO on held-out synthetic single-object-pair data. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the central claims rest on direct measurement and standard alignment techniques rather than any reduction to inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Binary spatial questions have an unambiguous correct answer that remains valid when a third option is added.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Yang, Kaiyu and Russakovsky, Olga and Deng, Jia , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
-
[2]
Goyal, Ankit and Yang, Kaiyu and Yang, Dawei and Deng, Jia , booktitle =
-
[6]
Proceedings of the Asian Conference on Computer Vision (ACCV) , month =
Rahmanzadehgervi, Pooyan and Bolton, Logan and Taesiri, Mohammad Reza and Nguyen, Anh Totti , title =. Proceedings of the Asian Conference on Computer Vision (ACCV) , month =. 2024 , pages =
2024
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Tong, Shengbang and Liu, Zhuang and Zhai, Yuexiang and Ma, Yi and LeCun, Yann and Xie, Saining , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[8]
Why Is Spatial Reasoning Hard for
Chen, Shiqi and Zhu, Tongyao and Zhou, Ruochen and Zhang, Jinghan and Gao, Siyang and Niebles, Juan Carlos and Geva, Mor and He, Junxian and Wu, Jiajun and Li, Manling , booktitle =. Why Is Spatial Reasoning Hard for. 2025 , editor =
2025
-
[9]
The Eleventh International Conference on Learning Representations , year=
Leveraging Large Language Models for Multiple Choice Question Answering , author=. The Eleventh International Conference on Learning Representations , year=
-
[10]
The Twelfth International Conference on Learning Representations , year=
Large Language Models Are Not Robust Multiple Choice Selectors , author=. The Twelfth International Conference on Learning Representations , year=
-
[14]
2026 , url=
Mengdi Jia and Zekun Qi and Shaochen Zhang and Wenyao Zhang and XinQiang Yu and Jiawei He and He Wang and Li Yi , booktitle=. 2026 , url=
2026
-
[15]
First Conference on Language Modeling , year=
Look at the Text: Instruction-Tuned Language Models are More Robust Multiple Choice Selectors than You Think , author =. First Conference on Language Modeling , year=
-
[16]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[18]
2022 , eprint=
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small , author=. 2022 , eprint=
2022
-
[19]
Towards Automated Circuit Discovery for Mechanistic Interpretability , url =
Conmy, Arthur and Mavor-Parker, Augustine and Lynch, Aengus and Heimersheim, Stefan and Garriga-Alonso, Adri\`. Towards Automated Circuit Discovery for Mechanistic Interpretability , url =. Advances in Neural Information Processing Systems , editor =
-
[20]
International Conference on Learning Representations , volume=
Towards best practices of activation patching in language models: Metrics and methods , author=. International Conference on Learning Representations , volume=
-
[21]
Ameisen, Emmanuel and Lindsey, Jack and Pearce, Adam and Gurnee, Wes and Turner, Nicholas L. and Chen, Brian and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[22]
European Conference on Computer Vision , pages=
Blink: Multimodal large language models can see but not perceive , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Chen, Boyuan and Xu, Zhuo and Kirmani, Sean and Ichter, Brain and Sadigh, Dorsa and Guibas, Leonidas and Xia, Fei , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mitigating object hallucinations in large vision-language models through visual contrastive decoding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[28]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, and 8 others. 2025. https://transformer-circuits.pub/2025/attribution...
2025
-
[29]
Atabuzzaman, Ali Asgarov, and Chris Thomas
Md. Atabuzzaman, Ali Asgarov, and Chris Thomas. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1703 Benchmarking and mitigating MCQA selection bias of large vision-language models . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33548--33562, Suzhou, China. Association for Computational Linguistics
-
[30]
Yonatan Belinkov. 2022. https://doi.org/10.1162/coli_a_00422 Probing classifiers: Promises, shortcomings, and advances . Computational Linguistics, 48(1):207--219
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[31]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14455--14465
2024
-
[32]
Shiqi Chen, Tongyao Zhu, Ruochen Zhou, Jinghan Zhang, Siyang Gao, Juan Carlos Niebles, Mor Geva, Junxian He, Jiajun Wu, and Manling Li. 2025. https://proceedings.mlr.press/v267/chen25cr.html Why is spatial reasoning hard for VLM s? A n attention mechanism perspective on focus areas . In Proceedings of the 42nd International Conference on Machine Learning,...
2025
-
[33]
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. 2024. https://doi.org/10.52202/079017-4293 SpatialRGPT : Grounded spatial reasoning in vision-language models . In Advances in Neural Information Processing Systems, volume 37, pages 135062--135093. Curran Associates, Inc
-
[34]
Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adri\` a Garriga-Alonso. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/34e1dbe95d34d7ebaf99b9bcaeb5b2be-Paper-Conference.pdf Towards automated circuit discovery for mechanistic interpretability . In Advances in Neural Information Processing Systems, volume 36, p...
2023
-
[35]
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. 2022. https://doi.org/10.18653/v1/2022.acl-long.581 Knowledge neurons in pretrained transformers . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8493--8502, Dublin, Ireland. Association for Computational Linguistics
-
[36]
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. 2024. Blink: Multimodal large language models can see but not perceive. In European Conference on Computer Vision, pages 148--166. Springer
2024
-
[37]
Ankit Goyal, Kaiyu Yang, Dawei Yang, and Jia Deng. 2020. https://proceedings.neurips.cc/paper_files/paper/2020/file/76dc611d6ebaafc66cc0879c71b5db5c-Paper.pdf Rel3D : A minimally contrastive benchmark for grounding spatial relations in 3D . In Advances in Neural Information Processing Systems, volume 33, pages 10514--10525. Curran Associates, Inc
2020
-
[38]
John Hewitt and Percy Liang. 2019. https://doi.org/10.18653/v1/D19-1275 Designing and interpreting probes with control tasks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2733--2743, Hong Kong, China. Association fo...
-
[39]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. 2024. Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13418--13427
2024
-
[40]
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, XinQiang Yu, Jiawei He, He Wang, and Li Yi. 2026. https://openreview.net/forum?id=6nZKT2rL0H OmniSpatial : Towards comprehensive spatial reasoning benchmark for vision language models . In The Fourteenth International Conference on Learning Representations
2026
-
[41]
Amita Kamath, Jack Hessel, and Kai-Wei Chang. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.568 What ' s ``up'' with vision-language models? investigating their struggle with spatial reasoning . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9161--9175, Singapore. Association for Computational Linguistics
-
[42]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. 2024. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872--13882
2024
-
[43]
Fangyu Liu, Guy Emerson, and Nigel Collier. 2023. https://doi.org/10.1162/tacl_a_00566 Visual spatial reasoning . Transactions of the Association for Computational Linguistics, 11:635--651
-
[44]
Jingping Liu, Ziyan Liu, Zhedong Cen, Yan Zhou, Yinan Zou, Weiyan Zhang, Haiyun Jiang, and Tong Ruan. 2025. https://doi.org/10.18653/v1/2025.acl-long.31 Can multimodal large language models understand spatial relations? In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 620--632, Vienn...
-
[45]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt. Advances in neural information processing systems, 35:17359--17372
2022
-
[46]
Pouya Pezeshkpour and Estevam Hruschka. 2024. https://doi.org/10.18653/v1/2024.findings-naacl.130 Large language models sensitivity to the order of options in multiple-choice questions . In Findings of the Association for Computational Linguistics: NAACL 2024, pages 2006--2017, Mexico City, Mexico. Association for Computational Linguistics
-
[47]
Pooyan Rahmanzadehgervi, Logan Bolton, Mohammad Reza Taesiri, and Anh Totti Nguyen. 2024. Vision language models are blind. In Proceedings of the Asian Conference on Computer Vision (ACCV), pages 18--34
2024
-
[48]
Joshua Robinson and David Wingate. 2023. https://openreview.net/forum?id=yKbprarjc5B Leveraging large language models for multiple choice question answering . In The Eleventh International Conference on Learning Representations
2023
-
[49]
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. 2024. Eyes wide shut? exploring the visual shortcomings of multimodal llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9568--9578
2024
-
[50]
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. 2022. https://arxiv.org/abs/2211.00593 Interpretability in the wild: a circuit for indirect object identification in gpt-2 small . Preprint, arXiv:2211.00593
Pith/arXiv arXiv 2022
-
[51]
Xinpeng Wang, Chengzhi Hu, Bolei Ma, Paul R \"o ttger, and Barbara Plank. 2024. https://openreview.net/forum?id=qHdSA85GyZ Look at the text: Instruction-tuned language models are more robust multiple choice selectors than you think . In First Conference on Language Modeling
2024
-
[52]
Kaiyu Yang, Olga Russakovsky, and Jia Deng. 2019. SpatialSense : An adversarially crowdsourced benchmark for spatial relation recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2019
-
[53]
Fred Zhang and Neel Nanda. 2024. Towards best practices of activation patching in language models: Metrics and methods. In International Conference on Learning Representations, volume 2024, pages 1651--1678
2024
-
[54]
Chujie Zheng, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. 2024. https://openreview.net/forum?id=shr9PXz7T0 Large language models are not robust multiple choice selectors . In The Twelfth International Conference on Learning Representations
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.