What to Format and How: A Benchmark and Workflow Approach for Document Formatting
Pith reviewed 2026-06-28 14:19 UTC · model grok-4.3
The pith
Decoupling target localization from modification execution improves formatting accuracy and reduces token consumption.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
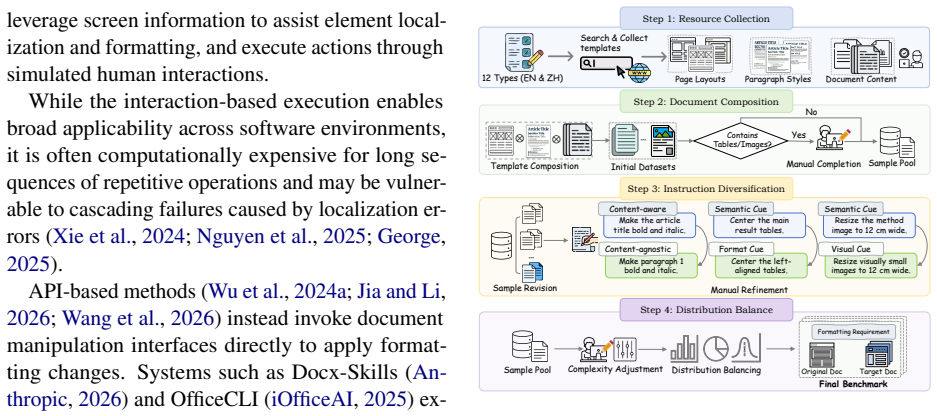
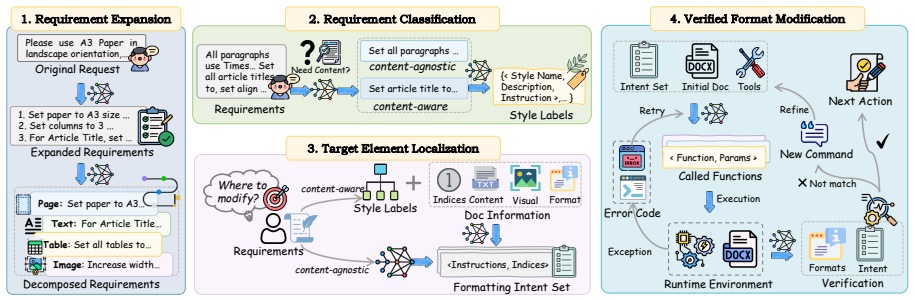
DocFormBench provides an evaluation dataset and metrics for realistic content-aware document formatting, while DocFormFlow decouples target localization from modification execution to avoid redundant document reading, resulting in improved formatting accuracy and reduced token consumption compared to baselines, with localization precision as the primary performance factor.
What carries the argument
DocFormFlow, a workflow method that decouples target localization from modification execution.
If this is right
- Formatting accuracy improves consistently across multiple LLMs and multimodal models.
- Token consumption decreases relative to representative baselines.
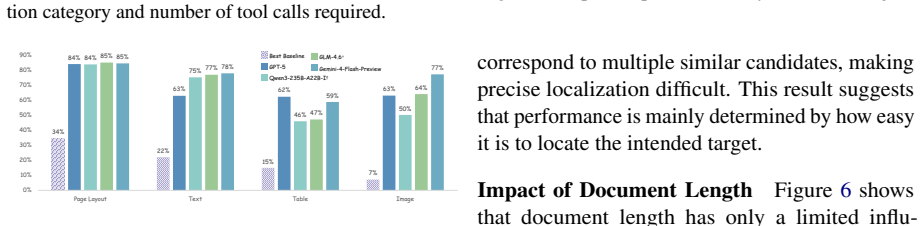
- Precise target localization emerges as the primary factor influencing overall formatting performance.
- The benchmark enables systematic evaluation in content-aware scenarios previously underexplored.
Where Pith is reading between the lines
- The decoupling pattern could extend to other content-dependent LLM tasks such as selective editing or extraction.
- Production document systems might add verification steps at the localization phase to increase reliability.
- Future benchmarks could prioritize localization-specific metrics to isolate bottlenecks more clearly.
Load-bearing premise
DocFormBench adequately represents real-world content-aware formatting scenarios and the chosen accuracy and efficiency metrics capture practical performance.
What would settle it
A new collection of real-world documents where DocFormFlow shows no gains in accuracy or token reduction over direct baseline methods.
Figures


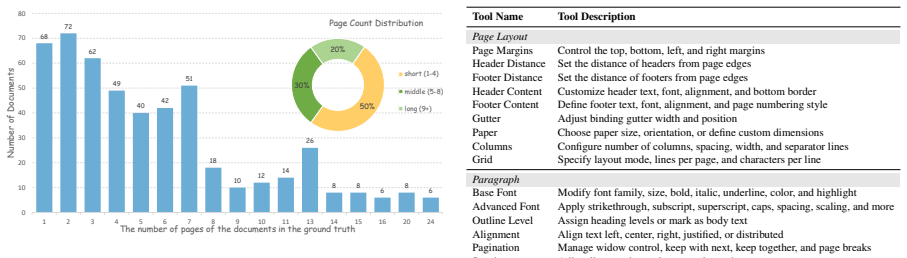

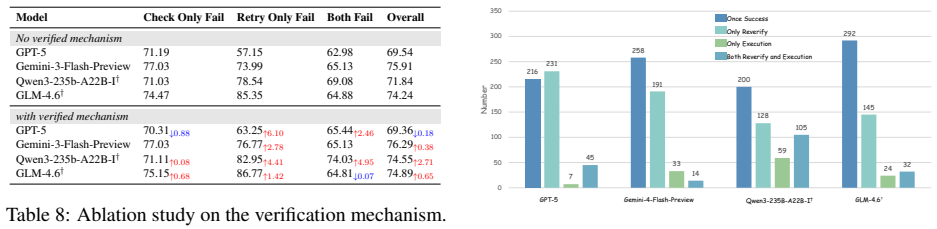
read the original abstract
Recent advances in large language models (LLMs) have opened up new possibilities for automated document formatting. However, real-world formatting often requires identifying targets based on document content. This content-aware setting remains challenging and underexplored, primarily due to the lack of dedicated evaluation datasets.To enable evaluation in realistic content-aware scenarios, we introduce DocFormBench, a benchmark that extends Text-to-Format evaluation to diverse formatting requirements, along with metrics for both accuracy and efficiency.To mitigate redundant document reading in existing methods during formatting, we propose DocFormFlow, a workflow formatting method that decouples target localization from modification execution into what to format and how. Extensive experiments across multiple LLMs and multimodal models show that DocFormFlow consistently improves formatting accuracy while reducing token consumption compared to representative baselines. Further analysis reveals that precise target localization is the primary factor influencing formatting performance. We hope DocFormBench and DocFormFlow will facilitate future research toward more intelligent and reliable document formatting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DocFormBench, a benchmark extending Text-to-Format evaluation to content-aware document formatting scenarios with diverse requirements, and proposes DocFormFlow, a workflow that decouples target localization ('what to format') from modification execution ('how to format') to reduce redundant document reading. It reports extensive experiments across LLMs and multimodal models demonstrating that DocFormFlow improves formatting accuracy while lowering token consumption relative to baselines, with further analysis identifying precise target localization as the primary performance factor.
Significance. If the experimental claims hold, the work offers a practical workflow for efficiency in LLM-based document formatting and a benchmark to support evaluation in content-aware settings, which could aid applications requiring semantic target identification. The decoupling approach directly targets a known inefficiency in sequential LLM prompting.
major comments (2)
- [DocFormBench (benchmark construction)] The construction and validation of DocFormBench (described in the abstract and presumably detailed in the benchmark section) lacks concrete information on document sourcing, formatting requirement generation process, and any inter-annotator agreement or quality controls. This is load-bearing for the central experimental claim, as the headline improvements in accuracy and efficiency on 'extensive experiments' cannot be assessed without evidence that the benchmark instantiates realistic content-aware scenarios rather than synthetic or narrow cases.
- [Experiments and metrics] No ablation studies, correlation analyses, or downstream usability validation are referenced for the chosen accuracy and token-consumption metrics (abstract and experiments section). Without this, it is unclear whether the reported gains track practical utility, undermining the claim that DocFormFlow 'consistently improves formatting accuracy while reducing token consumption'.
minor comments (1)
- [Abstract and experiments] The abstract refers to 'representative baselines' without naming them or their relation to prior Text-to-Format work; this should be clarified in the experiments section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on DocFormBench construction and the experimental metrics. We address each major comment below and will revise the manuscript accordingly to provide greater transparency and validation.
read point-by-point responses
-
Referee: [DocFormBench (benchmark construction)] The construction and validation of DocFormBench (described in the abstract and presumably detailed in the benchmark section) lacks concrete information on document sourcing, formatting requirement generation process, and any inter-annotator agreement or quality controls. This is load-bearing for the central experimental claim, as the headline improvements in accuracy and efficiency on 'extensive experiments' cannot be assessed without evidence that the benchmark instantiates realistic content-aware scenarios rather than synthetic or narrow cases.
Authors: We agree that the manuscript would benefit from more explicit details on benchmark construction to substantiate its realism. In the revised version, we will expand the relevant section to describe: document sourcing from a combination of public corpora (e.g., arXiv papers, Wikipedia dumps, and legal documents) with filtering for diversity in length and structure; the requirement generation process, which combines automated template-based creation of content-aware formatting rules with manual review by two annotators; and quality controls, including inter-annotator agreement (Cohen's kappa > 0.8 on a 20% sample) and exclusion criteria for ambiguous cases. These additions will clarify that DocFormBench targets realistic scenarios. revision: yes
-
Referee: [Experiments and metrics] No ablation studies, correlation analyses, or downstream usability validation are referenced for the chosen accuracy and token-consumption metrics (abstract and experiments section). Without this, it is unclear whether the reported gains track practical utility, undermining the claim that DocFormFlow 'consistently improves formatting accuracy while reducing token consumption'.
Authors: We concur that additional analyses would better link the metrics to practical utility. The revised experiments section will incorporate: (1) ablation studies isolating the contribution of the localization step versus modification; (2) correlation analysis between localization precision and end-to-end accuracy/token savings across models; and (3) a brief discussion relating the metrics to downstream tasks such as automated report generation. These will be presented with quantitative results to support the efficiency and accuracy claims. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces DocFormBench as a new benchmark and DocFormFlow as a workflow that decouples localization from execution. No equations, fitted parameters, or predictions appear in the provided text. The experimental claims rest on comparisons to external baselines rather than any self-referential fitting or self-citation chain. DocFormBench construction is presented as an independent contribution, not derived from the method itself. This matches the default case of a non-circular benchmark/workflow paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Foundations and Trends
Readability research: An interdisciplinary approach , author=. Foundations and Trends. 2022 , publisher=
2022
-
[2]
PLoS One , volume=
Scientific sinkhole: The pernicious price of formatting , author=. PLoS One , volume=. 2019 , publisher=
2019
-
[3]
PLoS Computational Biology , volume=
Ten simple rules for typographically appealing scientific texts , author=. PLoS Computational Biology , volume=. 2020 , publisher=
2020
-
[4]
Free your mouse! Command Large Language Models to Generate Code to Format Word Documents
Rao, Shihao and Li, Liang and Liu, Jiapeng and Weixin, Guan and Gao, Xiyan and Lim, Bing and Ma, Can. Free your mouse! Command Large Language Models to Generate Code to Format Word Documents. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.902
-
[5]
arXiv preprint arXiv:2410.21311 , year=
Mmdocbench: Benchmarking large vision-language models for fine-grained visual document understanding , author=. arXiv preprint arXiv:2410.21311 , year=
-
[6]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Docedit: language-guided document editing , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[7]
Agent-DocEdit: Language-Instructed
Te-Lin Wu and Rajiv Jain and Yufan Zhou and Puneet Mathur and Vlad I Morariu , booktitle=. Agent-DocEdit: Language-Instructed. 2024 , url=
2024
-
[8]
2016 , howpublished =
Guillermo Grau Pujol , title =. 2016 , howpublished =
2016
-
[9]
2023 , howpublished =
Xiaokonglong , title =. 2023 , howpublished =
2023
-
[10]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
GLM-5: from Vibe Coding to Agentic Engineering
Glm-5: from vibe coding to agentic engineering , author=. arXiv preprint arXiv:2602.15763 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , year =
-
[15]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
arXiv preprint arXiv:2505.15182 , year=
ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State Reflection , author=. arXiv preprint arXiv:2505.15182 , year=
-
[17]
SemaClaw: A Step Towards General-Purpose Personal AI Agents through Harness Engineering
Ningyan Zhu and Huacan Wang and Jie Zhou and others , title =. arXiv preprint arXiv:2604.11548 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
OpenClaw-RL: Train Any Agent Simply by Talking
Yinjie Wang and Xuyang Chen and Xiaolong Jin and Mengdi Wang and Ling Yang , title =. arXiv preprint arXiv:2603.10165 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
arXiv preprint arXiv:2504.14603 , year=
Ufo2: The desktop agentos , author=. arXiv preprint arXiv:2504.14603 , year=
-
[21]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Gui agents: A survey , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[22]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Infiguiagent: A multimodal generalist gui agent with native reasoning and reflection , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
AutoTool: Efficient tool selection for large language model agents , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[24]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Meta-Tool: Unleash Open-World Function Calling Capabilities of General-Purpose Large Language Models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Nestful: A benchmark for evaluating llms on nested sequences of api calls , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[26]
DOCX Skill: Programmatic Creation and Editing of Word Documents , year =
-
[27]
OfficeCLI: AI-Friendly Command-Line Interface for Office Documents , year =
-
[28]
First conference on language modeling , year=
Autogen: Enabling next-gen LLM applications via multi-agent conversations , author=. First conference on language modeling , year=
-
[29]
arXiv e-prints , pages=
Agentorchestra: A hierarchical multi-agent framework for general-purpose task solving , author=. arXiv e-prints , pages=
-
[30]
arXiv preprint arXiv:2505.13516 , year=
Halo: Hierarchical autonomous logic-oriented orchestration for multi-agent llm systems , author=. arXiv preprint arXiv:2505.13516 , year=
-
[31]
arXiv preprint arXiv:2409.08264 , year=
Windows agent arena: Evaluating multi-modal os agents at scale , author=. arXiv preprint arXiv:2409.08264 , year=
-
[32]
Advances in Neural Information Processing Systems , volume=
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents
Agent s2: A compositional generalist-specialist framework for computer use agents , author=. arXiv preprint arXiv:2504.00906 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
arXiv preprint arXiv:2508.04700 , year=
Seagent: Self-evolving computer use agent with autonomous learning from experience , author=. arXiv preprint arXiv:2508.04700 , year=
-
[35]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning , author=. arXiv preprint arXiv:2509.02544 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
2025 , publisher=
George, Jeomon , title=. 2025 , publisher=
2025
-
[37]
Lost in Execution: On the Multilingual Robustness of Tool Calling in Large Language Models
Lost in Execution: On the Multilingual Robustness of Tool Calling in Large Language Models , author=. arXiv preprint arXiv:2601.05366 , year=
work page internal anchor Pith review arXiv
-
[38]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Critictool: Evaluating self-critique capabilities of large language models in tool-calling error scenarios , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[39]
2025 , note =
mario-andreschak , title =. 2025 , note =
2025
-
[40]
2026 , note =
HKUDS , title =. 2026 , note =
2026
-
[41]
2025 , howpublished =
GPT-5 System Card , author =. 2025 , howpublished =
2025
-
[42]
2025 , howpublished =
Gemini 3 Flash Model Card , author =. 2025 , howpublished =
2025
-
[43]
2025 , eprint=
GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning , author=. 2025 , eprint=
2025
-
[44]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=
-
[45]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.