Algorithmic algorithm development with LLMs: A Case Study on LLM-Usage for Contraction Order Optimization in Tensor Networks
Pith reviewed 2026-06-28 14:33 UTC · model grok-4.3
The pith
Verifier-guided LLM agents show promise for developing better tensor contraction algorithms while human validation stays essential
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Verifier-guided evolutionary coding agents that use LLMs can develop and improve algorithms for contraction order optimization in tensor networks, yet the process still requires human evaluation, validation, and interpretation to ensure the results are reliable and meaningful.
What carries the argument
Verifier-guided evolutionary coding agents that iteratively propose, test, and refine code for tensor-network contraction ordering
If this is right
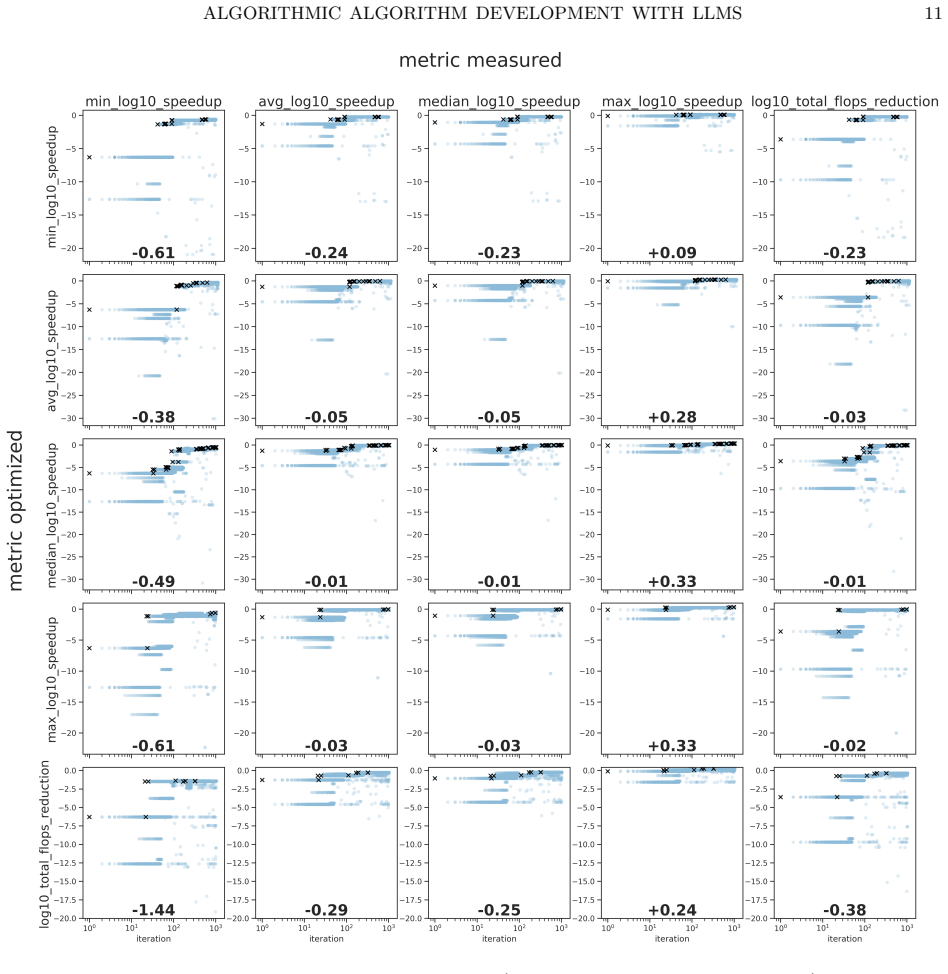
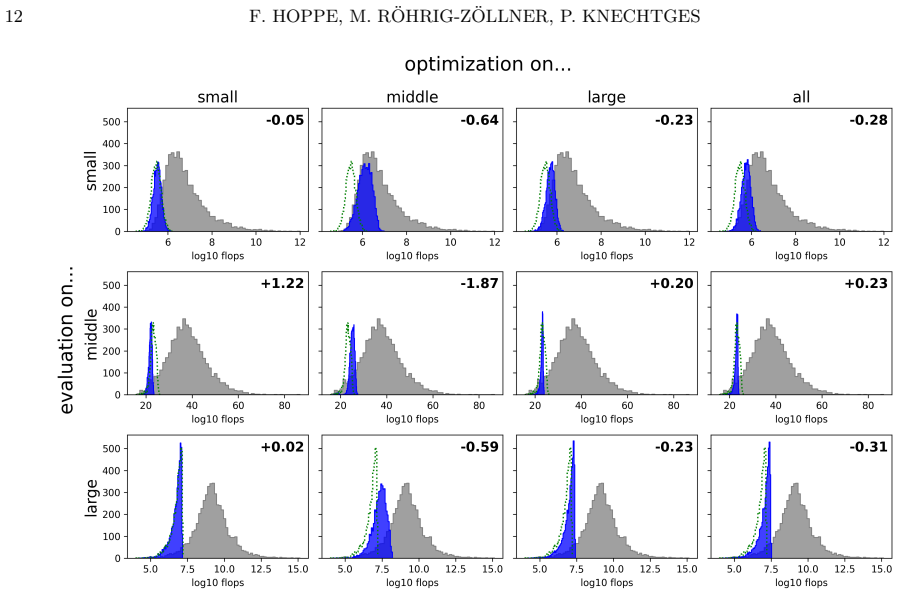
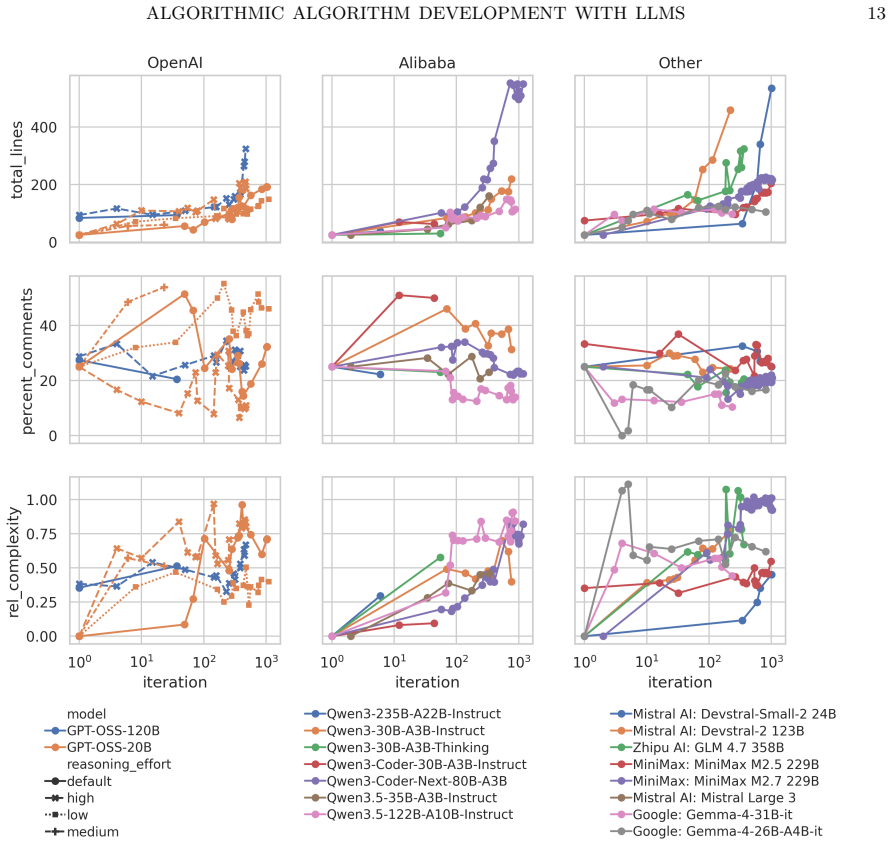
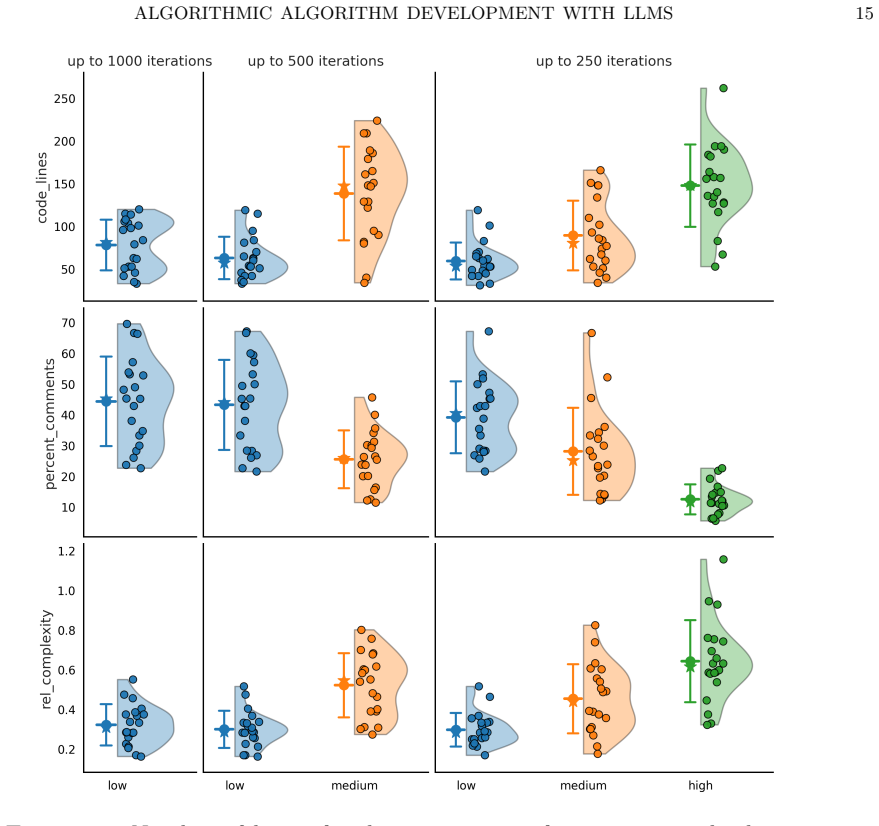
- Design choices for the evaluation metric and test instances directly influence the quality of algorithms generated by the agents
- The same verifier-guided approach can be used to attempt algorithmic improvements on other tensor-network related tasks
- Human oversight remains necessary to interpret agent outputs and confirm they solve the intended scientific problem
Where Pith is reading between the lines
- The method could be applied to contraction optimization in other scientific computing domains that rely on similar ordering problems
- Results may change if different LLMs or verification procedures are substituted in the evolutionary loop
- Longer-term use might require new benchmarks that better capture real-world tensor network performance beyond the study instances
Load-bearing premise
That conclusions drawn from this single tensor-network case study with its chosen metrics, test instances, and LLM will generalize to algorithmic development tasks in other domains
What would settle it
An experiment in which the contraction-order algorithms produced by the LLM agents are shown to be inferior to established human-written methods when measured on a broader collection of tensor networks outside the original test set
Figures
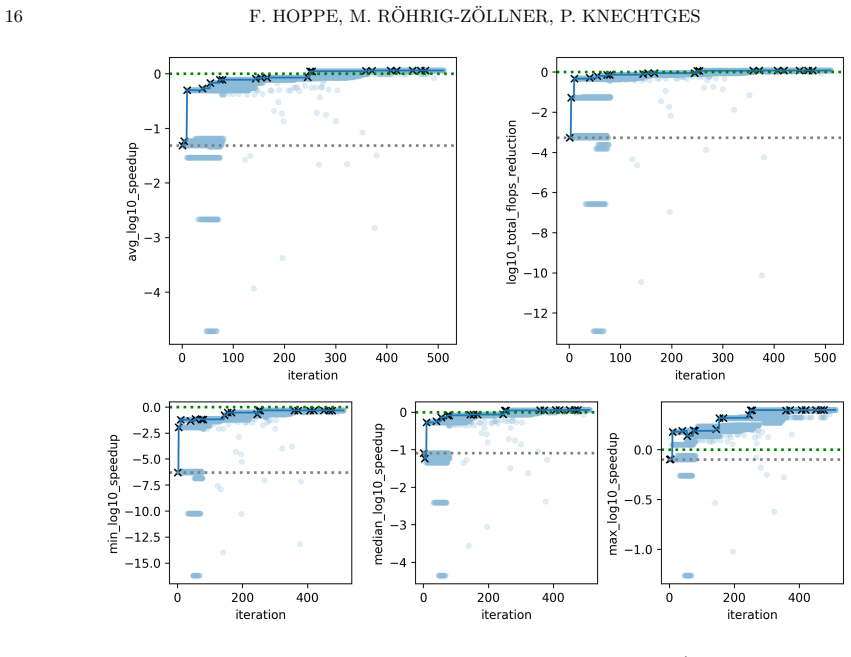
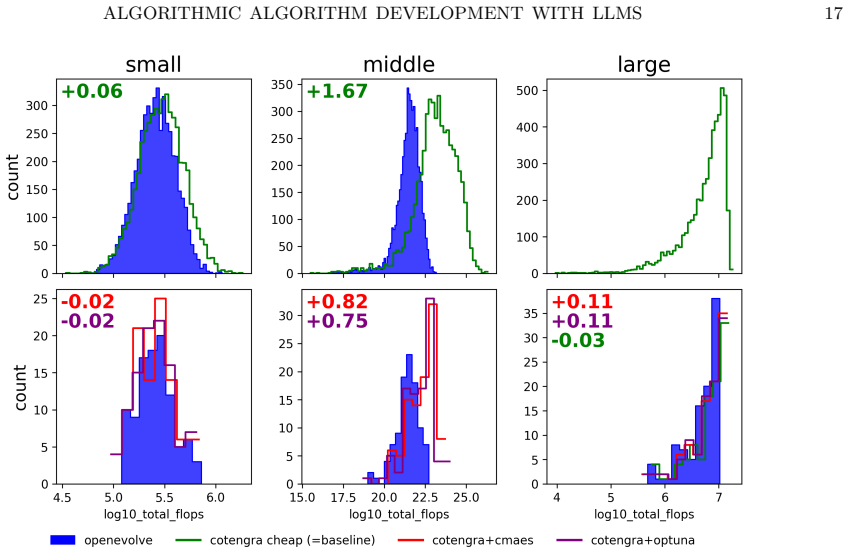
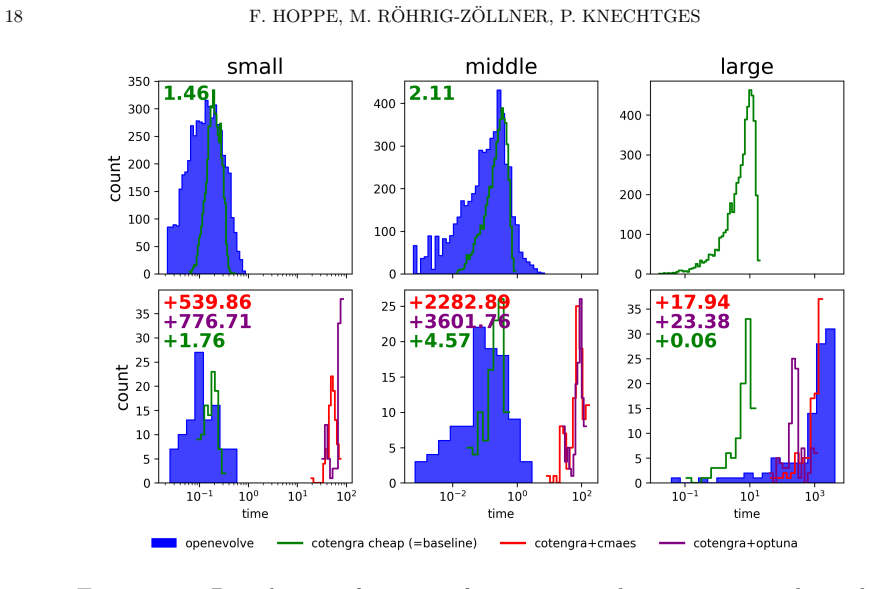
read the original abstract
We consider LLM-based algorithm development through a case study on contractionorder optimisation for tensor networks with OpenEvolve. We pay particular attention to the choice of the LLM as well as design choices such as evaluation metric and test instances. Our results highlight both the promise of verifier-guided evolutionary coding agents for algorithm development/improvement and the continuing importance of evaluation, validation, and interpretation -- and corresponding challenges -- by the human scientist.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a case study on LLM-based algorithm development using verifier-guided evolutionary coding agents (OpenEvolve) for contraction-order optimization in tensor networks. It examines the impact of LLM choice, evaluation metrics, and test instances, concluding that such agents show promise for algorithmic improvement while underscoring the essential role of human evaluation, validation, and interpretation.
Significance. If the case study demonstrates measurable improvements over baselines with the described setup, the work would illustrate a concrete application of LLMs to a combinatorial optimization task in tensor networks and reinforce the value of hybrid human-AI workflows. However, the single narrow domain limits broader significance for algorithmic development in general without evidence of transfer.
major comments (2)
- [Abstract] Abstract: the central claim that verifier-guided evolutionary coding agents show promise for algorithm development/improvement rests on results from one tensor-network case study using one LLM, one set of test instances, and one evaluation metric. No evidence is supplied that the observed improvements or necessity of human interpretation would hold for other problems.
- [Abstract] Abstract: no quantitative results, error bars, baseline comparisons, or description of how improvements were measured are supplied, so it is impossible to judge whether the central claim is supported by data.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments. We address the major comments point by point below, agreeing where revisions to the abstract are warranted to better reflect the case-study nature of the work and to include quantitative details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that verifier-guided evolutionary coding agents show promise for algorithm development/improvement rests on results from one tensor-network case study using one LLM, one set of test instances, and one evaluation metric. No evidence is supplied that the observed improvements or necessity of human interpretation would hold for other problems.
Authors: The manuscript is explicitly framed as a case study on contraction-order optimization in tensor networks, as stated in the abstract and introduction. The central claim concerns the observed promise and the essential role of human validation within this specific setting; we do not claim or provide evidence that the results transfer to other algorithmic problems. We will revise the abstract to more clearly emphasize the case-study scope and the absence of broader transfer evidence. revision: yes
-
Referee: [Abstract] Abstract: no quantitative results, error bars, baseline comparisons, or description of how improvements were measured are supplied, so it is impossible to judge whether the central claim is supported by data.
Authors: The full manuscript contains quantitative results, baseline comparisons (including standard contraction-order heuristics), error bars from multiple runs, and explicit descriptions of the evaluation metric and test instances. However, the abstract does not summarize these elements. We will revise the abstract to incorporate key quantitative highlights and measurement details. revision: yes
Circularity Check
No circularity: empirical case study with no derivation chain
full rationale
The paper is a case study reporting experimental results from applying an LLM-based evolutionary coding agent (OpenEvolve) to one specific task: contraction-order optimization for tensor networks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim that such agents 'show promise' rests on direct empirical observations rather than any self-referential reduction to inputs by construction. Generalization concerns are validity issues, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi:10.18653/v1/2025.eval4nlp-1.12 [AAGa24] E. Agrawal, O. Alam, C. Goenka, et al. Code Compass: A Study on the Challenges of Navigating Unfamiliar Codebases.CoRRabs/2405.06271,
-
[2]
doi:10.48550/ARXIV.2405.06271 [AFCa25] H. Assump¸ c˜ ao, D. Ferreira, L. Campos, et al. CodeEvolve: an open source evolutionary coding agent for algorithmic discovery and optimization
-
[3]
CodeEvolve: an open source evolutionary coding agent for algorithmic discovery and optimization
doi:10.48550/arXiv.2510.14150 [AKSa24] V. Aglietti, I. Ktena, J. Schrouff, et al. FunBO: Discovering Acquisition Functions for Bayesian Optimization with FunSearch
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.14150
-
[4]
https://arxiv.org/abs/2406.04824 [ATSa26] L. A. Agrawal, S. Tan, D. Soylu, et al. GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
-
[5]
https://arxiv.org/abs/2507.19457 8In fact, a tiny and hidden approach to this has already happened when we chose 2 f in the definition of combined score based on a few experiments as indicated at the beginning of Sect. 3 22 F. HOPPE, M. R ¨OHRIG-Z ¨OLLNER, P. KNECHTGES [BB17] J. Biamonte, V. Bergholm. Tensor Networks in a Nutshell
-
[6]
https://arxiv.org/abs/1708.00006 [BCNa26] A. B¨ auerle, A. Connors, A. Novikov, et al. Intentmaking and Sensemaking: Human Interaction with AI-Guided Mathematical Discovery
-
[7]
https://arxiv.org/abs/2605.05921 [BHJa25] D. Brown, J. He, H. Jenne, et al. Even with AI, Bijection Discovery is Still Hard: The Opportu- nities and Challenges of OpenEvolve for Novel Bijection Construction
-
[8]
doi:10.48550/arXiv.2511.20987 [BK25] G. Ballard, T. G. Kolda.Tensor Decompositions for Data Science. Cambridge University Press, June
-
[9]
doi:10.1017/9781009471664 [BKB25] J. Beel, M.-Y. Kan, M. Baumgart. Evaluating Sakana’s AI Scientist: Bold Claims, Mixed Results, and a Promising Future?SIGIR Forum59(1):1–20, Oct
-
[10]
doi:10.1145/3769733.3769747 [BNL26] J. Bhan, N. Nobili, P. Langer. New Bounds for Zarankiewicz Numbers via Reinforced LLM Evolutionary Search
-
[11]
https://arxiv.org/abs/2605.01120 [CCC25] F. Caravaca, ´Angel Cuevas, R. Cuevas. From Prompts to Power: Measuring the Energy Footprint of LLM Inference
- [12]
-
[13]
doi:10.48550/arXiv.2512.14806 [CZH26] A. Cheng, L. Zhang, G. He. Re4: Scientific Computing Agent with Rewriting, Resolution, Review and Revision
-
[14]
https://arxiv.org/abs/2508.20729 [Dec99] R. Dechter. Bucket elimination: A unifying framework for reasoning.Artificial Intelligence113(1– 2):41–85,
-
[15]
doi:10.1016/S0004-3702(99)00059-4 [DFGa18] E. F. Dumitrescu, A. L. Fisher, T. D. Goodrich, et al. Benchmarking treewidth as a practical component of tensor network simulations.PLOS ONE13(12),
-
[16]
doi:10.1371/journal.pone.0207827 [FBMa24] C. Fernando, D. Banarse, H. Michalewski, et al. Promptbreeder: self-referential self-improvement via prompt evolution. InProceedings of the 41st International Conference on Machine Learning. ICML’24. JMLR.org,
-
[17]
https://dl.acm.org/doi/10.5555/3692070.3692611 [Fei22] D. G. Feitelson. Considerations and Pitfalls for Reducing Threats to the Validity of Controlled Experiments on Code Comprehension.Empirical Software Engineering27(6):123, Jun
-
[18]
doi:10.1007/s10664-022-10160-3 [FGGa25] M. Felderer, M. Goedicke, L. Grunske, et al. Investigating Research Software Engineering: Toward RSE Research.Commun. ACM68(2):20–23, Jan
-
[19]
doi:10.1145/3685265 [FKSa26] D. Fisher, V. Khrulkov, M. Saygin, et al. LLM-Guided Evolutionary Search for Algebraic T- Count Optimization
- [20]
-
[21]
https://arxiv.org/abs/2604.15468 [FLXa26] R. Fu, Y. Liu, Q. Xu, et al. MappingEvolve: LLM-Driven Code Evolution for Technology Map- ping
-
[22]
https://arxiv.org/abs/2604.26591 [GBC16] I. Goodfellow, Y. Bengio, A. Courville.Deep Learning. MIT Press, 2016.http://www. deeplearningbook.org. ALGORITHMIC ALGORITHM DEVELOPMENT WITH LLMS 23 [GD04] V. Gogate, R. Dechter. A complete anytime algorithm for treewidth. InProceedings of the 20th Conference on Uncertainty in Artificial Intelligence. UAI ’04, p....
Pith/arXiv arXiv 2016
-
[23]
https://dl.acm.org/doi/10.5555/1036843.1036868 [GGTa25] B. Georgiev, J. G´ omez-Serrano, T. Tao, et al. Mathematical exploration and discovery at scale
-
[24]
https://arxiv.org/abs/2511.02864 [GK21] J. Gray, S. Kourtis. Hyper-optimized tensor network contraction.Quantum5:410,
-
[25]
doi:10.22331/q-2021-03-15-410 [GRSa25] P. W. Goncalves, P. Rani, M.-A. Storey, et al. Code Review Comprehension: Reviewing Strategies Seen Through Code Comprehension Theories . In2025 IEEE/ACM 33rd International Conference on Program Comprehension (ICPC). Pp. 589–601. IEEE Computer Society, Los Alamitos, CA, USA, Apr
-
[26]
doi:10.1109/ICPC66645.2025.00068 [GWDa25] J. Gottweis, W.-H. Weng, A. Daryin, et al. Towards an AI co-scientist
-
[27]
https://arxiv.org/abs/2502.18864 [IHIa] Y. Imajuku, K. Horie, Y. Iwata, et al. ALE-Bench: A Benchmark for Long-Horizon Objective- Driven Algorithm Engineering. NeurIPS
-
[28]
https://arxiv.org/abs/2506.09050 [ILHa22] C. Ibrahim, D. Lykov, Z. He, et al. Constructing Optimal Contraction Trees for Tensor Network Quantum Circuit Simulation
-
[29]
https://arxiv.org/abs/2209.02895 [IZLa25] G. Iacovides, W. Zhou, C. Li, et al. Domain-Aware Tensor Network Structure Search
- [30]
-
[31]
doi:10.1145/3747588 [KGBa25] V. Khrulkov, A. Galichin, D. Bashkirov, et al. GigaEvo: An Open Source Optimization Frame- work Powered By LLMs And Evolution Algorithms
-
[32]
https://arxiv.org/abs/2511.17592 [Kjæ90] U. B. Kjærulff. Triangulation of Graphs – Algorithms Giving Small Total State Space. Technical report R 90-09, Aalborg University,
-
[33]
Kumar, A
https://cse.unl.edu/~choueiry/Documents/Kjaerulff-TR-1990.pdf [KSNa26] U. Kumar, A. Saito, H. Niranjani, et al. Evolving Interpretable Constitutions for Multi-Agent Coordination
1990
-
[34]
https://arxiv.org/abs/2602.00755 [KT26] T. Klowden, T. Tao. Mathematical methods and human thought in the age of AI
-
[35]
https://arxiv.org/abs/2603.26524 [LGWa26] Z. Liu, X. Guo, X. Wei, et al. Escher-Loop: Mutual Evolution by Closed-Loop Self-Referential Optimization
-
[36]
https://arxiv.org/abs/2604.23472 [LIC25] R. T. Lange, Y. Imajuku, E. Cetin. ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
-
[37]
https://arxiv.org/abs/2509.19349 [LLLa26] C. Lu, C. Lu, R. T. Lange, et al. Towards end-to-end automation of AI research.Nature 651(8107):914–919, Mar
-
[38]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
See alsohttps://arxiv.org/abs/2408.06292. doi:10.1038/s41586-026-10265-5 [LMSa26] K.-A. Lie, O. Møyner, E. Svee, et al. Agentic Scientific Simulation: Execution-Grounded Model Construction and Reconstruction
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-026-10265-5
-
[39]
https://arxiv.org/abs/2603.00214 [LTYa24] F. Liu, X. Tong, M. Yuan, et al. Evolution of heuristics: towards efficient automatic algorithm design using large language model. InProceedings of the 41st International Conference on Ma- chine Learning. ICML’24. JMLR.org,
-
[40]
https://dl.acm.org/doi/abs/10.5555/3692070.3693374 24 F. HOPPE, M. R ¨OHRIG-Z ¨OLLNER, P. KNECHTGES [LYFa26] H. Lin, H. Ye, W. Feng, et al. Can Language Models Discover Scaling Laws?
-
[41]
https://arxiv.org/abs/2507.21184 [LZ] X.-Y. Liu, Z. Zhang. Classical Simulation of Quantum Circuits Using Reinforcement Learning: Parallel Environments and Benchmark. InNeurIPS
-
[42]
https://proceedings.neurips.cc/paper_files/paper/2023/file/ d41b70011dd21ec3de5e019302279551-Paper-Datasets_and_Benchmarks.pdf [LZCa25] G. Liu, Y. Zhu, J. Chen, et al. Scientific Algorithm Discovery by Augmenting AlphaEvolve with Deep Research
2023
-
[43]
https://arxiv.org/abs/2510.06056 [LZX+24] F. Liu, R. Zhang, Z. Xie, R. Sun, K. Li, X. Lin, Z. Wang, Z. Lu, Q. Zhang. LLM4AD: A Platform for Algorithm Design with Large Language Model
-
[44]
https://arxiv.org/abs/2412.17287 [MMMa] E. A. Meirom, H. Maron, S. Mannor, et al. Optimizing Tensor Network Contraction Using Re- inforcement Learning. InProceedings of the 39th International Conference on Machine Learning (ICML 2022). https://proceedings.mlr.press/v162/meirom22a.html [MS08] I. L. Markov, Y. Shi. Simulating Quantum Computation by Contract...
arXiv 2022
-
[45]
doi:10.1137/050644756 [MYCa25] L. Mitchener, A. Yiu, B. Chang, et al. Kosmos: An AI Scientist for Autonomous Discovery
-
[46]
https://arxiv.org/abs/2511.02824 [MZKa26] V. A. Mazin, M. A. Zorin, D. S. Korzh, et al. LLM-Guided Prompt Evolution for Password Guessing
-
[47]
https://arxiv.org/abs/2604.12601 [NGWI25] K. Nagaitsev, L. Grbcic, S. Williams, C. Iancu. Optimizing PyTorch Inference with LLM-Based Multi-Agent Systems
-
[48]
Optimizing PyTorch Inference with LLM-Based Multi-Agent Systems
https://arxiv.org/abs/2511.16964 [NRT] D. Neum¨ uller, A. Raschke, M. Tichy. Providing Information About Implemented Algorithms Improves Program Comprehension: A Controlled Experiment. InProceedings of the 29th Inter- national Conference on Evaluation and Assessment in Software Engineering. EASE ’25. doi:10.1145/3756681.3756968 [NVEa25] A. Novikov, N. V˜ ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3756681.3756968
-
[49]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
https://arxiv.org/abs/2506.13131 [O’G] B. O’Gorman. Parameterization of Tensor Network Contraction. In14th Conference on the The- ory of Quantum Computation, Communication and Cryptography (TQC 2019). doi:10.4230/LIPIcs.TQC.2019.10 [Or´ u14] R. Or´ us. A Practical Introduction to Tensor Networks: Matrix Product States and Projected Entangled Pair States.A...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.4230/lipics.tqc.2019.10 2019
-
[50]
doi:10.1016/j.aop.2014.06.013 [PA+25] O. Press, B. Amos et al. AlgoTune: Can Language Models Speed Up General-Purpose Numerical Programs?
-
[51]
https://arxiv.org/abs/2507.15887 [RBNa24] B. Romera-Paredes, M. Barekatain, A. Novikov, et al. Mathematical discoveries from program search with large language models.Nature625:468–475,
-
[52]
Pawan Kumar, Emilien Dupont, Francisco J
doi:10.1038/s41586-023-06924-6 [RBSa25] P. Rajput, A. A. Bonkoungou, Y. Song, et al. Dynamic Stability of LLM-Generated Code
-
[53]
https://arxiv.org/abs/2511.07463 [RTL76] D. J. Rose, R. E. Tarjan, G. S. Lueker. Algorithmic Aspects of Vertex Elimination on Graphs. SIAM Journal on Computing5(2):266–283,
-
[54]
doi:10.1137/0205021 [SBK+] C. Staudt, M. Blacher, J. Klaus, F. Lippmann, J. Giesen. Improved Cut Strategy for Tensor Net- work Contraction Orders. In22nd International Symposium on Experimental Algorithms (SEA ALGORITHMIC ALGORITHM DEVELOPMENT WITH LLMS 25 2024). doi:10.4230/LIPIcs.SEA.2024.27 [SG18] D. G. A. Smith, J. Gray. opt einsum - A Python package ...
-
[55]
doi:10.21105/joss.00753 [SHGa23] S. Schlag, T. Heuer, L. Gottesb¨ uren, et al. High-Quality Hypergraph Partitioning.ACM J. Exp. Algorithmics27, Feb
-
[56]
doi:10.1145/3529090 [SISa25] M. L. Siddiq, A. Islam-Gomes, N. Sekerak, et al. Large Language Models for Software Engineering: A Reproducibility Crisis
-
[57]
https://arxiv.org/abs/2512.00651 [SJ20] F. Schindler, A. S. Jermyn. Algorithms for tensor network contraction ordering.Machine Learn- ing: Science and Technology1(3):035001,
-
[58]
doi:10.1088/2632-2153/ab94c5 [SMM24] M. Stoian, R. M. Milbradt, C. B. Mendl. On the Optimal Linear Contraction Order of Tree Tensor Networks, and Beyond.SIAM Journal on Scientific Computing46(5):B647–B668,
-
[59]
doi:10.1137/23M161286X [ˇSMQa25] A. ˇSurina, A. Mansouri, L. C. P. M. Quaedvlieg, et al. Algorithm Discovery With LLMs: Evolu- tionary Search Meets Reinforcement Learning
-
[60]
https://arxiv.org/abs/2504.05108 [SS15] J. Siegmund, J. Schumann. Confounding parameters on program comprehension: a literature survey.Empirical Software Engineering20(4):1159–1192, Aug
-
[61]
doi:10.1007/s10664-014-9318-8 [Str17] B. Strasser. Computing Tree Decompositions with FlowCutter: PACE 2017 Submission
-
[62]
https://arxiv.org/abs/1709.08949 [Tam] H. Tamaki. Positive-instance driven dynamic programming for treewidth. In25th Annual Euro- pean Symposium on Algorithms (ESA 2017). doi:10.4230/LIPIcs.ESA.2017.68 [TDPa26] A. Torri, P. Dominikowski, B. Pointal, et al. Near-Optimal Contraction Strategies for the Scalar Product in the Tensor-Train Format. In Nagel et a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.4230/lipics.esa.2017.68 2017
-
[63]
doi:10.1007/978-3-031-99872-0 5 [TGZa24] M. Tian, L. Gao, S. D. Zhang, et al. SciCode: A Research Coding Benchmark Curated by Scientists
- [64]
-
[65]
https://arxiv.org/abs/2505.20242 [VPC04] F. Verstraete, D. Porras, J. I. Cirac. Density Matrix Renormalization Group and Periodic Bound- ary Conditions: A Quantum Information Perspective.Phys. Rev. Lett.93:227205, Nov
-
[66]
doi:10.1103/PhysRevLett.93.227205 [WQBa26] J. Wen, L. Qiu, J. Benton, et al. Automated Weak-to-Strong Researcher
-
[67]
https://alignment.anthropic.com/2026/automated-w2s-researcher/ [WSZa25] Y
Anthropic Align- ment Science Blog. https://alignment.anthropic.com/2026/automated-w2s-researcher/ [WSZa25] Y. Wang, S.-R. Su, Z. Zeng, et al. ThetaEvolve: Test-time Learning on Open Problems
2026
-
[68]
https://arxiv.org/abs/2511.23473 [XZLa23] J. Xu, H. Zhang, L. Liang, et al. NP-Hardness of Tensor Network Contraction Ordering
-
[69]
https://arxiv.org/abs/2310.06140 [YLDa25] J. Yuan, H. Li, X. Ding, et al. Understanding and Mitigating Numerical Sources of Nondetermin- ism in LLM Inference. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
- [70]
-
[71]
https://arxiv.org/abs/2504.08066 [YWCa24] H. Ye, J. Wang, Z. Cao, et al. ReEvo: large language models as hyper-heuristics with reflective evolution. InProceedings of the 38th International Conference on Neural Information Processing Systems. NIPS ’24. Curran Associates Inc., Red Hook, NY, USA,
-
[72]
https://dl.acm.org/doi/10.5555/3737916.3739297 [YZLL24] J. Yang, K. Zhou, Y. Li, Z. Liu. Generalized Out-of-Distribution Detection: A Survey.Interna- tional Journal of Computer Vision132:5635–5662,
-
[73]
doi:10.1007/s11263-024-02117-4 [ZLSa24] J. Zeng, C. Li, Z. Sun, et al. tnGPS: Discovering Unknown Tensor Network Structure Search Algorithms via Large Language Models (LLMs). InProceedings of the 41st International Confer- ence on Machine Learning
-
[74]
https://arxiv.org/abs/2602.08253 ALGORITHMIC ALGORITHM DEVELOPMENT WITH LLMS 27 System Message for OpenEvolve You are an expert programmer and expert in tensor networks. Your goal is to evolve and improve the code of the function ‘find_edge_path‘ in between the markers "EVOLVE-BLOCK-START" and "EVOLVE- BLOCK-END". CONTEXT: The function ‘find_edge_path‘ ge...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.