LALE: Lightweight-Transformer Architecture for Land-Cover Estimation
Pith reviewed 2026-06-28 12:20 UTC · model grok-4.3
The pith
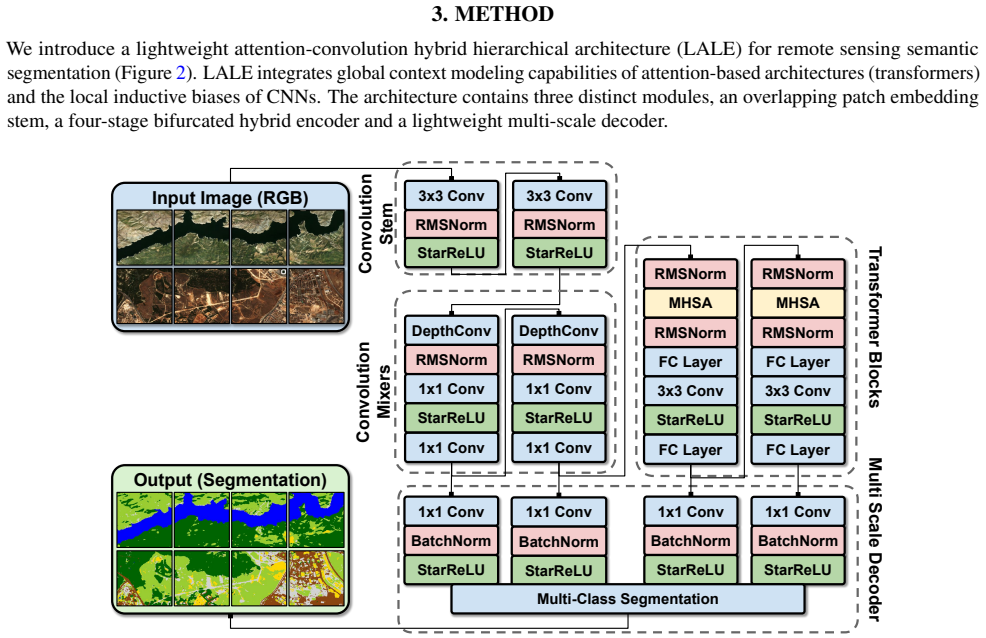
LALE splits its encoder by resolution so lightweight convolutions handle high-resolution details while transformers capture global context only at low resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LALE is an end-to-end segmentation architecture whose encoder is bifurcated by resolution: lightweight ConvMixer stages process high-resolution local features while transformer stages process low-resolution global context, confining the quadratic cost of self-attention to deep downsampled maps; an all-MLP multi-scale decoder, RMSNorm, and StarReLU are used throughout to further cut compute and parameters, producing a strong efficiency-performance trade-off against CNN, transformer, and hybrid baselines on the ARAS400k benchmark.
What carries the argument
Bifurcated encoder that applies ConvMixer at high resolution and confines transformer self-attention to low-resolution downsampled feature maps.
If this is right
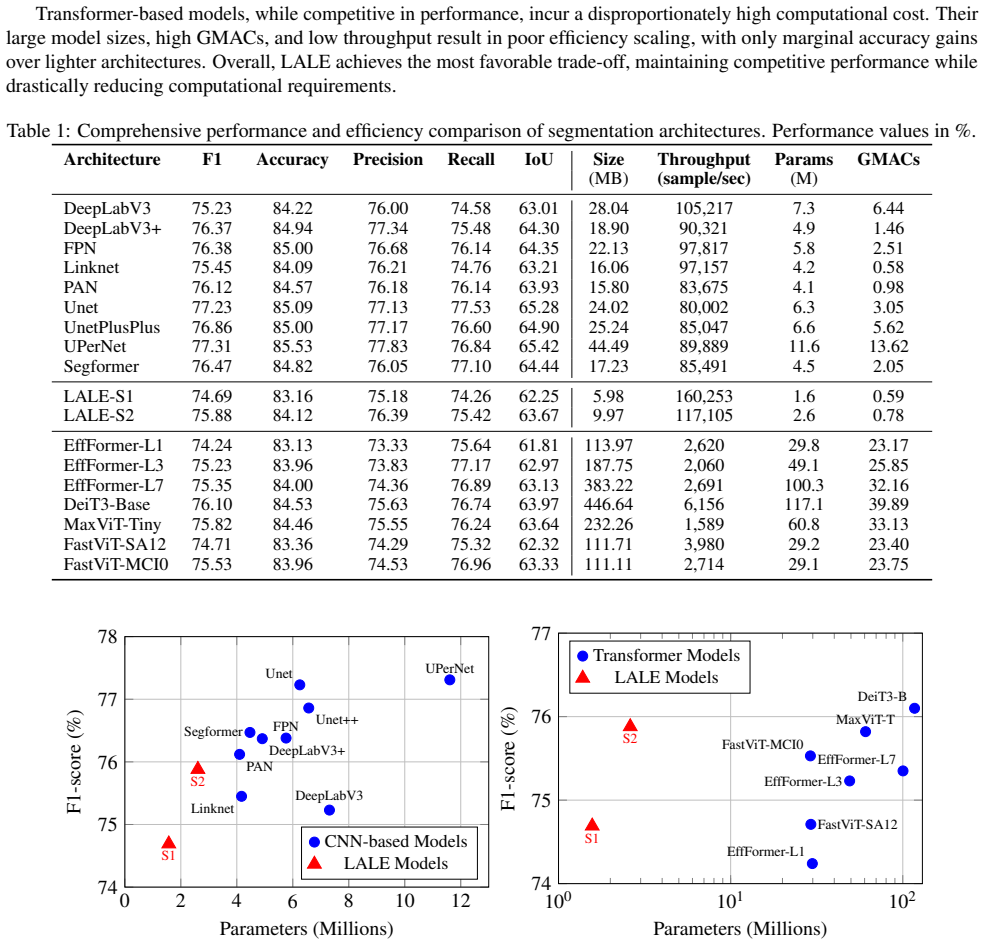
- A 1.6 M parameter model can reach within 2.6 F1 points of UPerNet on ARAS400k.
- The same model uses 4.5 times fewer parameters, 7 times less storage, and 17 times fewer GMACs while delivering 1.8 times higher throughput.
- Hybrid CNN-transformer segmentation can be made efficient by restricting attention to low-resolution maps.
- All-MLP multi-scale decoders can replace heavier decoder heads without large accuracy loss.
Where Pith is reading between the lines
- If low-resolution global context proves sufficient here, the same split could be tested on other dense-prediction tasks that need both fine detail and scene-level understanding.
- The results suggest that full-resolution attention is often unnecessary for remote-sensing land-cover maps because spatial redundancy is high after modest downsampling.
- Deployment on satellites or edge devices becomes more practical once parameter counts drop below a few million while retaining near state-of-the-art F1 scores.
Load-bearing premise
Global context captured by self-attention only after heavy downsampling is sufficient for accurate land-cover segmentation without needing attention at higher resolutions.
What would settle it
If inserting attention layers at higher resolutions in an otherwise identical architecture produces a statistically significant F1 gain on ARAS400k that exceeds the added compute cost, the claim that low-resolution global context suffices would be falsified.
Figures

read the original abstract
Semantic segmentation of remote sensing imagery requires models that capture both global context and local detail under tight computational budgets. Prior work typically optimizes for one of these axes: attention for global context, convolution for local detail, or compactness for efficiency. While hybrid approaches aim to capture both, they require architectural changes and encoder backbones with computational overhead, limiting efficiency and performance. We present LALE (Lightweight-transformer Architecture for Land-cover Estimation), an end-to-end remote sensing image segmentation architecture, that bifurcates its encoder by resolution: lightweight ConvMixer stages handle high-resolution local features, while transformer stages handle low-resolution global context, confining the quadratic cost of self-attention to deep, downsampled feature maps. An all-MLP multi-scale decoder, together with RMSNorm and StarReLU throughout, further reduces compute and parameter count. On the large-scale ARAS400k remote-sensing segmentation benchmark, LALE establishes a strong efficiency-performance trade-off against CNN, transformer, and hybrid baselines. Our smallest variant, (just 1.6M parameters), reaches within 2.6 F1 points of the best baseline (UPerNet) while using 4.5x fewer parameters, 7x less storage, 17x fewer GMACs, and delivering 1.8x higher throughput. The codebase for LALE is publicly available at https://github.com/caglarmert/LALE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LALE, an end-to-end architecture for semantic segmentation of remote-sensing imagery. Its encoder bifurcates by resolution (ConvMixer stages at high resolution for local features; transformer stages at low resolution for global context), paired with an all-MLP multi-scale decoder and uniform use of RMSNorm and StarReLU. On the ARAS400k benchmark the smallest variant (1.6 M parameters) is reported to lie within 2.6 F1 points of UPerNet while using 4.5× fewer parameters, 7× less storage, 17× fewer GMACs and 1.8× higher throughput; public code is provided.
Significance. If the reported trade-off holds under full verification, the work supplies a concrete, reproducible efficiency baseline for land-cover segmentation that could be directly useful for edge deployment. The public GitHub repository supplies an independent verification path, which strengthens the contribution.
major comments (2)
- [Experiments] Experiments section: the headline F1 deltas (2.6 points) and efficiency ratios are presented as single-point estimates without standard deviations, number of runs, or statistical tests; this directly affects confidence in the central claim that the 1.6 M-parameter variant is competitive.
- [Methods] Methods / §3: training protocol, optimizer schedule, data augmentations, and exact hyper-parameter values for the ARAS400k runs are not stated in the text (only referenced to the repository); these details are load-bearing for reproducing the reported GMAC and throughput numbers.
minor comments (2)
- [Architecture] The description of the bifurcated encoder would benefit from an explicit diagram or equation showing the resolution at which the transformer branch begins.
- [Tables] Table captions should explicitly state whether the reported throughput is measured on the same hardware as the GMAC counts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. The comments identify clear opportunities to strengthen the statistical robustness and reproducibility of the reported results. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline F1 deltas (2.6 points) and efficiency ratios are presented as single-point estimates without standard deviations, number of runs, or statistical tests; this directly affects confidence in the central claim that the 1.6 M-parameter variant is competitive.
Authors: We agree that single-point estimates reduce confidence in the performance claims. In the revised manuscript we will rerun the key models (including the 1.6 M variant) with multiple random seeds, report mean F1 scores together with standard deviations, and add a short discussion of observed variance. Efficiency metrics such as GMACs and throughput are deterministic given the architecture and hardware; we will clarify this distinction in the text. revision: yes
-
Referee: [Methods] Methods / §3: training protocol, optimizer schedule, data augmentations, and exact hyper-parameter values for the ARAS400k runs are not stated in the text (only referenced to the repository); these details are load-bearing for reproducing the reported GMAC and throughput numbers.
Authors: We concur that the main text should be self-contained for reproducibility. Section 3 will be expanded to include the full training protocol (optimizer, learning-rate schedule, data augmentations, batch size, and all hyper-parameters) used for the ARAS400k experiments. The public repository link will remain for the implementation code. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper proposes an empirical architecture (bifurcated ConvMixer+transformer encoder plus all-MLP decoder) and reports measured F1, parameter, GMAC, and throughput deltas versus named external baselines on the public ARAS400k benchmark. No derivation chain, equation, or fitted parameter is shown to reduce to its own inputs by construction; the central efficiency claim is a direct empirical comparison whose sufficiency is externally verifiable via the cited public codebase. No self-citation is load-bearing for the reported numbers.
Axiom & Free-Parameter Ledger
free parameters (1)
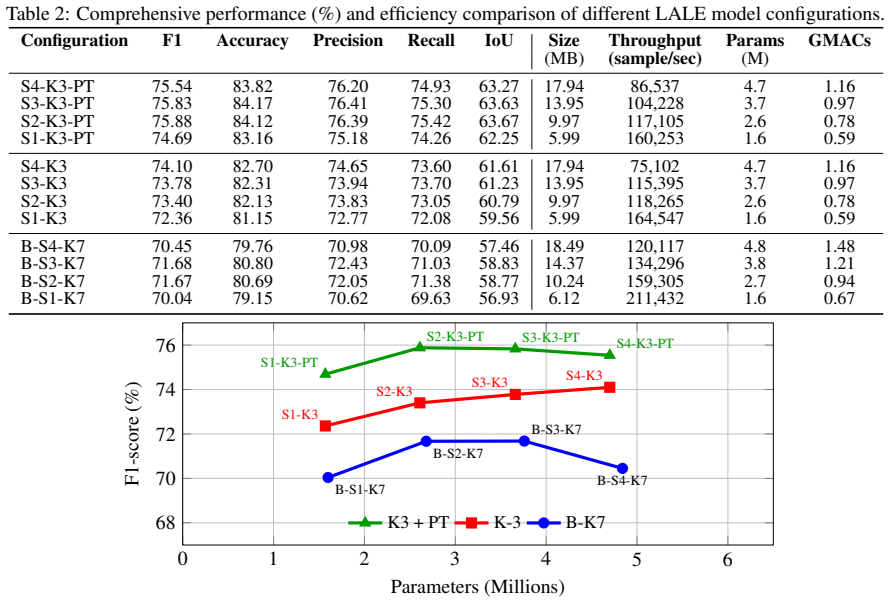
- stage counts and channel dimensions
axioms (1)
- domain assumption Standard supervised training with cross-entropy loss and data augmentation produces reliable segmentation performance on remote-sensing data.
Forward citations
Cited by 1 Pith paper
-
BELDE: Building a Large-scale Earth-observation Land-cover Dataset for Europe
Presents BELDE, one of the largest public RGB land-cover segmentation datasets for Europe (1,088,385 pairs, 7 classes) with baselines achieving 83% F1 in-domain but 58-66% cross-domain.
Reference graph
Works this paper leans on
-
[1]
U-net: Convolutional networks for biomedical image segmentation,
Ronneberger, O., Fischer, P., and Brox, T., “U-net: Convolutional networks for biomedical image segmentation,” in [International Conference on Medical image computing and computer-assisted intervention], 234–241, Springer (2015)
2015
-
[2]
Unet++: A nested u-net architecture for medical image segmentation,
Zhou, Z., Rahman Siddiquee, M. M., Tajbakhsh, N., and Liang, J., “Unet++: A nested u-net architecture for medical image segmentation,” in [International workshop on deep learning in medical image analysis], (2018)
2018
-
[3]
Linknet: Exploiting encoder representations for efficient semantic segmentation,
Chaurasia, A. and Culurciello, E., “Linknet: Exploiting encoder representations for efficient semantic segmentation,” in [2017 IEEE visual communications and image processing (VCIP)], 1–4, IEEE (2017)
2017
-
[4]
Feature pyramid networks for object detection,
Lin, T.-Y ., Doll´ar, P., Girshick, R., He, K., Hariharan, B., and Belongie, S., “Feature pyramid networks for object detection,” in [Proceedings of the IEEE conference on computer vision and pattern recognition], 2117–2125 (2017)
2017
-
[5]
Pyramid Attention Network for Semantic Segmentation
Li, H., Xiong, P., An, J., and Wang, L., “Pyramid attention network for semantic segmentation,”arXiv:1805.10180 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Rethinking Atrous Convolution for Semantic Image Segmentation
Chen, L.-C., Papandreou, G., Schroff, F., and Adam, H., “Rethinking atrous convolution for semantic image segmenta- tion,”arXiv preprint arXiv:1706.05587(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Encoder-decoder with atrous separable convolution for semantic image segmentation,
Chen, L.-C., Zhu, Y ., Papandreou, G., Schroff, F., and Adam, H., “Encoder-decoder with atrous separable convolution for semantic image segmentation,” in [ECCV], (2018)
2018
-
[8]
Unified perceptual parsing for scene understanding,
Xiao, T., Liu, Y ., Zhou, B., Jiang, Y ., and Sun, J., “Unified perceptual parsing for scene understanding,” in [Proceedings of the European conference on computer vision (ECCV)], 418–434 (2018)
2018
-
[9]
Segformer: Simple and efficient design for semantic segmentation with transformers,
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J. M., and Luo, P., “Segformer: Simple and efficient design for semantic segmentation with transformers,”Advances in neural information processing systems34, 12077–12090 (2021)
2021
-
[10]
Deit iii: Revenge of the vit,
Touvron, H., Cord, M., and J´egou, H., “Deit iii: Revenge of the vit,” in [European conference on computer vision], 516–533, Springer (2022)
2022
-
[11]
Swin transformer v2: Scaling up capacity and resolution,
Liu, Z., Hu, H., Lin, Y ., Yao, Z., Xie, Z., Wei, Y ., Ning, J., Cao, Y ., Zhang, Z., Dong, L., et al., “Swin transformer v2: Scaling up capacity and resolution,” in [Proceedings of the IEEE/CVF conference on computer vision and pattern recognition], 12009–12019 (2022)
2022
-
[12]
Maxvit: Multi-axis vision transformer,
Tu, Z., Talebi, H., Zhang, H., Yang, F., Milanfar, P., Bovik, A., and Li, Y ., “Maxvit: Multi-axis vision transformer,” in [European conference on computer vision], 459–479, Springer (2022)
2022
-
[13]
Rethinking vision transformers for mobilenet size and speed,
Li, Y ., Hu, J., Wen, Y ., Evangelidis, G., Salahi, K., Wang, Y ., Tulyakov, S., and Ren, J., “Rethinking vision transformers for mobilenet size and speed,” in [Proceedings of the IEEE/CVF international conference on computer vision], 16889–16900 (2023)
2023
-
[14]
Fastvit: A fast hybrid vision transformer using structural reparameterization,
Vasu, P. K. A., Gabriel, J., Zhu, J., Tuzel, O., and Ranjan, A., “Fastvit: A fast hybrid vision transformer using structural reparameterization,” in [Proceedings of the IEEE/CVF international conference on computer vision], 5785–5795 (2023)
2023
-
[15]
Root mean square layer normalization,
Zhang, B. and Sennrich, R., “Root mean square layer normalization,”Advances in neural information processing systems32(2019)
2019
-
[16]
Ba, J. L., Kiros, J. R., and Hinton, G. E., “Layer normalization,”arXiv preprint arXiv:1607.06450(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Metaformer baselines for vision,
Yu, W., Si, C., Zhou, P., Luo, M., Zhou, Y ., Feng, J., Yan, S., and Wang, X., “Metaformer baselines for vision,”IEEE Transactions on Pattern Analysis and Machine Intelligence46(2), 896–912 (2023)
2023
-
[18]
Gaussian Error Linear Units (GELUs)
Hendrycks, D. and Gimpel, K., “Gaussian error linear units (gelus),”arXiv preprint arXiv:1606.08415(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Searching for Activation Functions
Ramachandran, P., Zoph, B., and Le, Q. V ., “Searching for activation functions,”arXiv preprint arXiv:1710.05941 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Trockman, A. and Kolter, J. Z., “Patches are all you need?,”arXiv preprint arXiv:2201.09792(2022)
-
[21]
Convmlp: Hierarchical convolutional mlps for vision,
Li, J., Hassani, A., Walton, S., and Shi, H., “Convmlp: Hierarchical convolutional mlps for vision,” in [Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition], 6307–6316 (2023)
2023
-
[22]
Fully convolutional networks for semantic segmentation,
Long, J., Shelhamer, E., and Darrell, T., “Fully convolutional networks for semantic segmentation,” in [Proceedings of the IEEE conference on computer vision and pattern recognition], 3431–3440 (2015)
2015
-
[23]
Efficientnet: Rethinking model scaling for convolutional neural networks,
Tan, M. and Le, Q., “Efficientnet: Rethinking model scaling for convolutional neural networks,” in [International conference on machine learning], 6105–6114, PMLR (2019)
2019
-
[24]
Deep residual learning for image recognition,
He, K., Zhang, X., Ren, S., and Sun, J., “Deep residual learning for image recognition,” in [Proceedings of the IEEE conference on computer vision and pattern recognition], 770–778 (2016)
2016
-
[25]
The liver tumor segmentation benchmark (lits),
Bilic, P., Christ, P., Li, H. B., V orontsov, E., Ben-Cohen, A., Kaissis, G., Szeskin, A., Jacobs, C., Mamani, G. E. H., Chartrand, G., et al., “The liver tumor segmentation benchmark (lits),”Medical image analysis84, 102680 (2023)
2023
-
[26]
Grounding Synthetic Data Generation With Vision and Language Models
C ¸a˘glar, ¨U. M. and Temizel, A., “Grounding synthetic data generation with vision and language models,”arXiv preprint arXiv:2603.09625(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.