InsightVQA: High-Dimensional Emotion-Cognitive Visual Question Answering Benchmark
Pith reviewed 2026-06-28 14:55 UTC · model grok-4.3
The pith
InsightVQA supplies 725,000 question-answer pairs to test models on three levels of emotion and cognitive reasoning from images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
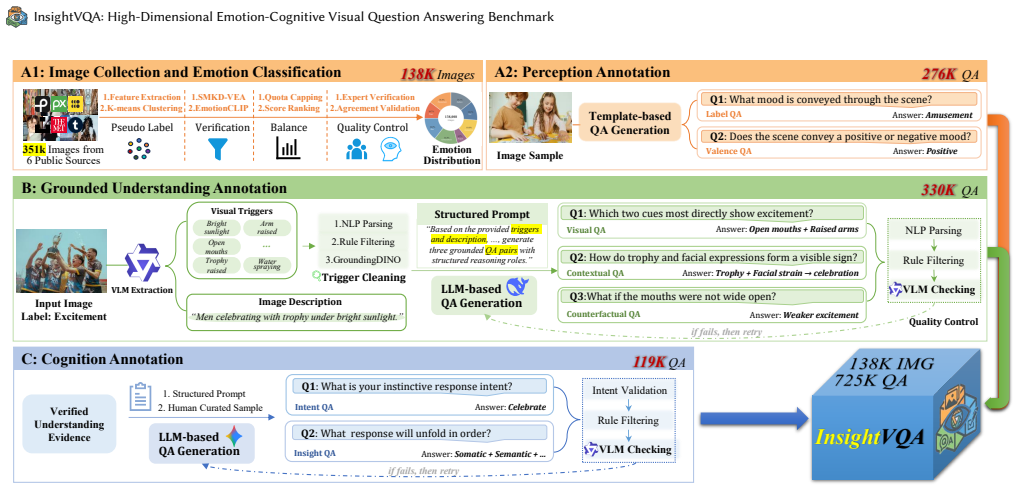
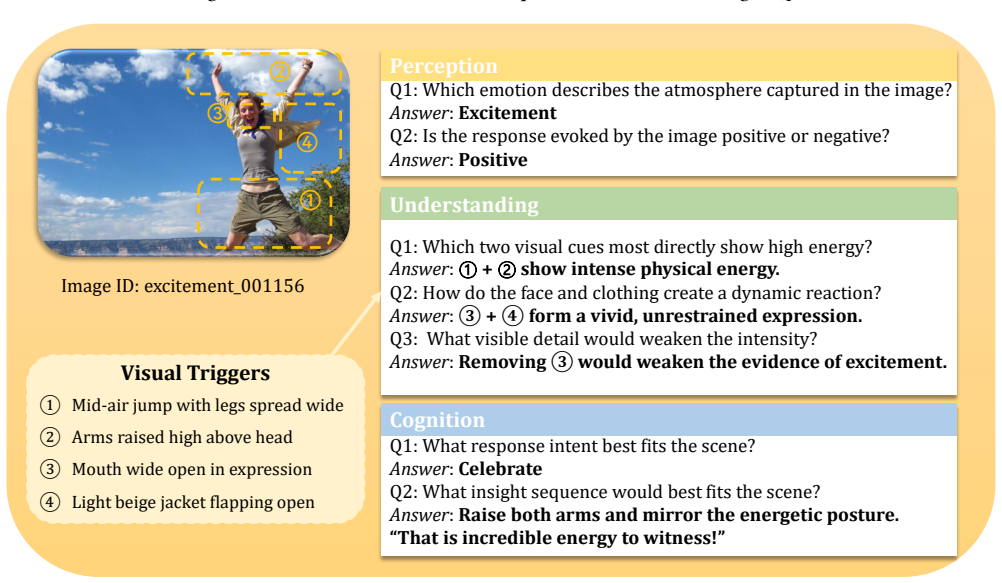
InsightVQA is a dataset of 725K QA pairs derived from 138K images through multi-stage filtering and constraint-guided generation, organized into perception QA for emotion and valence, grounded understanding QA from visual triggers, and cognition QA for response intent and sequential reasoning, accompanied by InsightVQA-Bench and InsightNet baseline.
What carries the argument
The three-level hierarchical annotation process that builds from basic emotion recognition to trigger extraction and then to intent prediction and insight reasoning.
Load-bearing premise
The multi-stage filtering and constraint-guided generation create annotations that accurately reflect the intended hierarchy without systematic errors or noise.
What would settle it
Human review of a random sample of the QA pairs revealing high rates of incorrect labels or levels that do not increase in reasoning demand as claimed.
Figures









read the original abstract
Visual emotion understanding requires models not only to recognize emotional states, but also to why they arise and perform higher-level cognitive reasoning. However, existing benchmarks mainly focus on emotion recognition, offering limited support for grounded understanding and response-oriented analysis. To address this gap, we introduce \textbf{InsightVQA}, a large-scale dataset for hierarchical visual question answering on emotion understanding and cognitive reasoning. Building from 351K images collected from six public sources, we apply a rigorous multi-stage filtering pipeline to curate 138K high-confidence images. Each image is annotated at three hierarchical levels: perception QA for emotion and valence recognition, grounded understanding QA constructed from visual trigger extraction through constraint-guided generation, and cognition QA centered on response intent prediction and sequential insight reasoning. In total, InsightVQA contains 725K QA pairs. We further present \textbf{InsightVQA-Bench}, a high-quality evaluation benchmark comprising 30K samples for fine-grained evaluation. To support evaluation, we introduce \textbf{InsightNet}, an emotion-tuned baseline for MLLMs. Results demonstrate that InsightVQA poses significant challenges for grounded emotion understanding and reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InsightVQA, a dataset of 725K QA pairs for hierarchical visual question answering on emotion understanding and cognitive reasoning. It is constructed from 138K images (filtered from 351K via multi-stage pipeline) drawn from six public sources, with annotations at three levels: perception QA (emotion/valence recognition), grounded understanding QA (via constraint-guided visual trigger extraction), and cognition QA (response intent and sequential insight reasoning). The work also releases InsightVQA-Bench (30K samples) for evaluation and InsightNet as an emotion-tuned MLLM baseline, claiming that existing benchmarks lack support for grounded and higher-level reasoning.
Significance. If the annotations are shown to be reliable, the dataset would address a clear gap by enabling evaluation of models on grounded emotion triggers and cognitive response reasoning rather than isolated recognition, potentially supporting more capable MLLMs in affective visual tasks.
major comments (1)
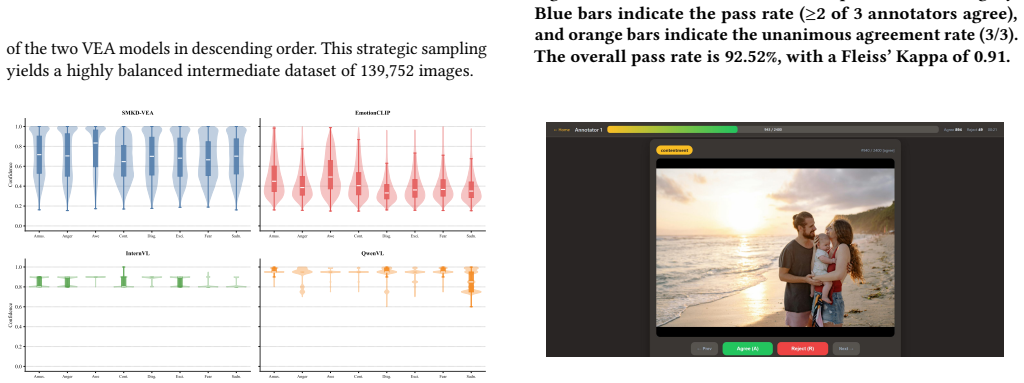
- [Abstract / curation pipeline] Abstract and curation description: the central claim that the multi-stage filtering (351K→138K) plus constraint-guided generation yields 'high-confidence' annotations at all three hierarchical levels is unsupported by any reported human verification rate, inter-annotator agreement, or post-generation error audit. Because the 725K QA pairs constitute the primary contribution, this omission directly affects the defensibility of downstream claims about model challenges and benchmark utility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit verification metrics. We agree this strengthens the defensibility of the dataset claims and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract / curation pipeline] Abstract and curation description: the central claim that the multi-stage filtering (351K→138K) plus constraint-guided generation yields 'high-confidence' annotations at all three hierarchical levels is unsupported by any reported human verification rate, inter-annotator agreement, or post-generation error audit. Because the 725K QA pairs constitute the primary contribution, this omission directly affects the defensibility of downstream claims about model challenges and benchmark utility.
Authors: We acknowledge that the manuscript does not currently report quantitative human verification rates, inter-annotator agreement (IAA), or a post-generation error audit. The multi-stage pipeline relies on automated filters (e.g., quality thresholds, constraint enforcement) and source curation, but these are not supplemented with the requested human metrics in the text. In the revised manuscript, we will add a new subsection (likely Section 3.3 or 4) providing: (1) human verification results on a stratified sample of 5,000 images/QA pairs across perception, grounded-understanding, and cognition levels, reporting agreement with pipeline outputs; (2) IAA scores from at least three annotators on a 1,000-sample subset per level; and (3) error audit findings with correction rates. This will directly support the 'high-confidence' claim for all three levels and the benchmark's utility. revision: yes
Circularity Check
No circularity: dataset paper with no derivations or fitted predictions
full rationale
The paper is a dataset introduction paper. It describes image collection from public sources, multi-stage filtering (351K to 138K images), and constraint-guided QA generation to produce 725K pairs across three hierarchical levels. No equations, parameters, or predictions appear anywhere in the manuscript. The central claims rest on the filtering and generation process producing accurate labels, but this is presented as a methodological assumption rather than a derived result from any input quantities. No self-citations, ansatzes, or renamings reduce any claim to its own inputs by construction. The derivation chain is empty; the work is self-contained as a resource contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ralph Adolphs. 2009. The social brain: neural basis of social knowledge.Annual review of psychology60, 1 (2009), 693–716
2009
-
[2]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al
-
[3]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems35 (2022), 23716–23736
2022
-
[4]
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Chunsheng Wu, Huajie Tan, Chunyuan Li, Jing Yang, Jie Yu, Xiyao Wang, Bin Qin, Yumeng Wang, Zizhen Yan, Ziyong Feng, Ziwei Liu, Bo Li, and Jiankang Deng. 2025. LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training.CoRR...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.23661 2025
-
[5]
SHIVAM Andotra. 2023. Enhancing human-computer interaction using emotion- aware chatbots for mental health support.Preprint10 (2023)
2023
-
[6]
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. 2015. Vqa: Visual question answering. In Proceedings of the IEEE international conference on computer vision. 2425–2433
2015
-
[7]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
Pith/arXiv arXiv 2023
-
[8]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
Pith/arXiv arXiv 2025
-
[9]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Ming- Hsuan Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[10]
theory of mind
Simon Baron-Cohen, Alan M Leslie, and Uta Frith. 1985. Does the autistic child have a “theory of mind”?Cognition21, 1 (1985), 37–46
1985
-
[11]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. 2024. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (C...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.14238 2024
-
[12]
Tristan Cladière, Olivier Alata, Christophe Ducottet, Hubert Konik, and Anne- Claire Legrand. 2025. Visual emotion analysis using skill-based multi-teacher knowledge distillation.Pattern Analysis and Applications28, 2 (2025), 49. doi:10. 1007/s10044-025-01426-9
2025
-
[13]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
Pith/arXiv arXiv 2025
-
[14]
Chris D Frith and Uta Frith. 2006. The neural basis of mentalizing.Neuron50, 4 (2006), 531–534
2006
-
[15]
Lancheng Gao, Ziheng Jia, Zixuan Xing, Wei Sun, Huiyu Duan, Guangtao Zhai, and Xiongkuo Min. 2026. EEmo-Logic: A Unified Dataset and Multi-Stage Frame- work for Comprehensive Image-Evoked Emotion Assessment.arXiv preprint arXiv:2602.01173(2026)
Pith/arXiv arXiv 2026
-
[16]
Lancheng Gao, Ziheng Jia, Yunhao Zeng, Wei Sun, Yiming Zhang, Wei Zhou, Guangtao Zhai, and Xiongkuo Min. 2025. Eemo-bench: a benchmark for multi- modal large language models on image evoked emotion assessment. InProceed- ings of the 33rd ACM International Conference on Multimedia. 7064–7073
2025
-
[17]
Google DeepMind. 2026. Gemini API:gemini-3.1-flash-lite-preview. https: //ai.google.dev/
2026
-
[18]
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh
-
[19]
InProceedings of the IEEE conference on computer vision and pattern recognition
Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition. 6904–6913
-
[20]
Kilichbek Haydarov, Xiaoqian Shen, Avinash Madasu, Mahmoud Salem, Li-Jia Li, Gamaleldin Elsayed, and Mohamed Elhoseiny. 2024. Affective visual dialog: A large-scale benchmark for emotional reasoning based on visually grounded conversations. InEuropean Conference on Computer Vision. Springer, 18–36
2024
-
[21]
Pengcheng He, Jianfeng Gao, and Weizhu Chen. 2021. Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing.arXiv preprint arXiv:2111.09543(2021)
Pith/arXiv arXiv 2021
-
[22]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[23]
He Hu, Yucheng Zhou, Lianzhong You, Hongbo Xu, Qianning Wang, Zheng Lian, Fei Richard Yu, Fei Ma, and Laizhong Cui. 2025. Emobench-m: Benchmarking emotional intelligence for multimodal large language models.arXiv preprint arXiv:2502.04424(2025)
Pith/arXiv arXiv 2025
-
[24]
Dawei Huang, Qing Li, Chuan Yan, Zebang Cheng, Yurong Huang, Xiang Li, Bin Li, Xiaohui Wang, Zheng Lian, and Xiaojiang Peng. 2025. Emotion-Qwen: Training Hybrid Experts for Unified Emotion and General Vision-Language Understanding.arXiv e-prints(2025), arXiv–2505
2025
-
[25]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
Pith/arXiv arXiv 2024
-
[26]
Sepideh Kalateh, Luis A Estrada-Jimenez, Sanaz Nikghadam-Hojjati, and Jose Barata. 2024. A systematic review on multimodal emotion recognition: building blocks, current state, applications, and challenges.IEEE Access12 (2024), 103976– 104019
2024
-
[27]
Ellen Kasireddy, Cuthbert Chow, Jun Collet, Mir-Masoud Pourrahmat, and Mir So- hail Fazeli. 2026. Evaluating the Performance of Claude 3.7 Sonnet in Data Ex- traction Automation for Systematic Literature Reviews.Value in Health Regional Issues53 (2026), 101539
2026
-
[28]
Ronak Kosti, Jose M Alvarez, Adria Recasens, and Agata Lapedriza. 2017. Emotion recognition in context. InProceedings of the IEEE conference on computer vision and pattern recognition. 1667–1675
2017
-
[29]
Ronak Kosti, Jose M Alvarez, Adria Recasens, and Agata Lapedriza. 2019. Context based emotion recognition using emotic dataset.IEEE transactions on pattern analysis and machine intelligence42, 11 (2019), 2755–2766
2019
-
[30]
Ananya Kumar, Aditi Raghunathan, Robbie Matthew Jones, Tengyu Ma, and Percy Liang. 2022. Fine-Tuning can Distort Pretrained Features and Underper- form Out-of-Distribution. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=UYneFzXSJWh
2022
-
[31]
Filip Lievens, Helga Peeters, and Eveline Schollaert. 2008. Situational judgment tests: A review of recent research.Personnel Review37, 4 (2008), 426–441
2008
-
[32]
Yuxiang Lin, Jingdong Sun, Zhi-Qi Cheng, Jue Wang, Haomin Liang, Zebang Cheng, Yifei Dong, Jun-Yan He, Xiaojiang Peng, and Xian-Sheng Hua. 2025. Why we feel: Breaking boundaries in emotional reasoning with multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference. 5196–5206
2025
-
[33]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
Pith/arXiv arXiv 2024
-
[34]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
Pith/arXiv arXiv 2025
-
[35]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[36]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. 2024. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision. Springer, 38–55
2024
-
[37]
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. 2024. Deepseek-vl: towards real- world vision-language understanding.arXiv preprint arXiv:2403.05525(2024)
Pith/arXiv arXiv 2024
-
[38]
Meng Luo, Bobo Li, Shanqing Xu, Shize Zhang, Qiuchan Chen, Menglu Han, Wenhao Chen, Yanxiang Huang, Hao Fei, Mong-Li Lee, et al. 2026. Unveiling the Cognitive Compass: Theory-of-Mind-Guided Multimodal Emotion Reasoning. arXiv preprint arXiv:2602.00971(2026)
arXiv 2026
-
[39]
Jana Machajdik and Allan Hanbury. 2010. Affective image classification using features inspired by psychology and art theory. InProceedings of the 18th ACM international conference on Multimedia. 83–92
2010
-
[40]
Ali Mollahosseini, Behzad Hasani, and Mohammad H Mahoor. 2017. Affectnet: A database for facial expression, valence, and arousal computing in the wild.IEEE transactions on affective computing10, 1 (2017), 18–31
2017
-
[41]
Kuan-Chuan Peng, Tsuhan Chen, Amir Sadovnik, and Andrew C Gallagher. 2015. A mixed bag of emotions: Model, predict, and transfer emotion distributions. InProceedings of the IEEE conference on computer vision and pattern recognition. 860–868
2015
-
[42]
Kuan-Chuan Peng, Amir Sadovnik, Andrew Gallagher, and Tsuhan Chen. 2016. Where do emotions come from? predicting the emotion stimuli map. In2016 IEEE international conference on image processing (ICIP). IEEE, 614–618
2016
-
[43]
Soujanya Poria, Erik Cambria, Rajiv Bajpai, and Amir Hussain. 2017. A review of affective computing: From unimodal analysis to multimodal fusion.Information fusion37 (2017), 98–125
2017
-
[44]
David Premack and Guy Woodruff. 1978. Does the chimpanzee have a theory of mind?Behavioral and brain sciences1, 4 (1978), 515–526
1978
-
[45]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[46]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763. Shiyu Wang, Ziyu Liu, Chaoyi Yu, Yujie Yin, Zhongqian Mao, Jing Chen, Jiaqi Song, Yunshi Lan, and Yan Wang
-
[47]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th International Con- ference on Machine Learning (ICML) (Proceedings o...
2021
-
[48]
Shezheng Song, Chengxiang He, Shan Zhao, Chengyu Wang, Qian Wan, Tian- wei Yan, and Meng Wang. 2024. Mosabench: Multi-object sentiment analysis benchmark for evaluating multimodal large language models understanding of complex image.arXiv preprint arXiv:2412.00060(2024)
arXiv 2024
-
[49]
2020.Natural language processing with Python and spaCy: A practical introduction
Yuli Vasiliev. 2020.Natural language processing with Python and spaCy: A practical introduction. No Starch Press
2020
-
[50]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. 2025. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265(2025)
Pith/arXiv arXiv 2025
-
[51]
Xiaoqin Wang, Xusen Ma, Xianxu Hou, Meidan Ding, Yudong Li, Junliang Chen, Wenting Chen, Xiaoyang Peng, and Linlin Shen. 2025. Facebench: A multi- view multi-level facial attribute vqa dataset for benchmarking face perception mllms. InProceedings of the Computer Vision and Pattern Recognition Conference. 9154–9164
2025
-
[52]
Daiqing Wu, Dongbao Yang, Can Ma, and Yu Zhou. 2025. EmoCaliber: Advanc- ing Reliable Visual Emotion Comprehension via Confidence Verbalization and Calibration.CoRRabs/2512.15528 (2025). arXiv:2512.15528 doi:10.48550/ARXIV. 2512.15528
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[53]
You Wu, Qingwei Mi, and Tianhan Gao. 2025. A comprehensive review of multimodal emotion recognition: Techniques, challenges, and future directions. Biomimetics10, 7 (2025), 418
2025
-
[54]
Hongxia Xie, Chu-Jun Peng, Yu-Wen Tseng, Hung-Jen Chen, Chan-Feng Hsu, Hong-Han Shuai, and Wen-Huang Cheng. 2024. Emovit: Revolutionizing emotion insights with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 26596–26605
2024
-
[55]
Jingyuan Yang, Qirui Huang, Tingting Ding, Dani Lischinski, Danny Cohen-Or, and Hui Huang. 2023. Emoset: A large-scale visual emotion dataset with rich attributes. InProceedings of the IEEE/CVF International Conference on Computer Vision. 20383–20394
2023
-
[56]
Qu Yang, Mang Ye, and Bo Du. 2024. Emollm: Multimodal emotional understand- ing meets large language models.arXiv preprint arXiv:2406.16442(2024)
arXiv 2024
-
[57]
Quanzeng You, Jiebo Luo, Hailin Jin, and Jianchao Yang. 2016. Building a large scale dataset for image emotion recognition: The fine print and the benchmark. InProceedings of the AAAI conference on artificial intelligence, Vol. 30
2016
-
[58]
Fan Zhang, Haoxuan Li, Shengju Qian, Xin Wang, Zheng Lian, Hao Wu, Zhihong Zhu, Yuan Gao, Qiankun Li, Yefeng Zheng, et al. 2025. Rethinking facial expres- sion recognition in the era of multimodal large language models: Benchmark, datasets, and beyond.arXiv preprint arXiv:2511.00389(2025)
arXiv 2025
-
[59]
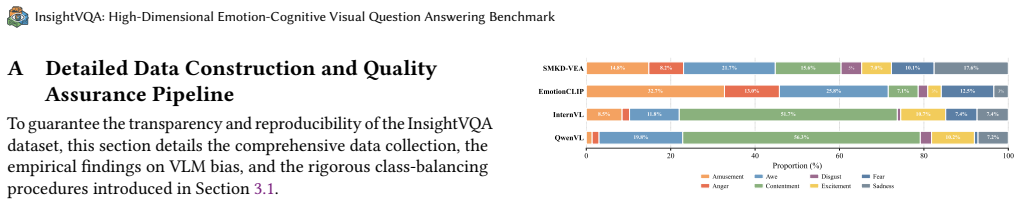
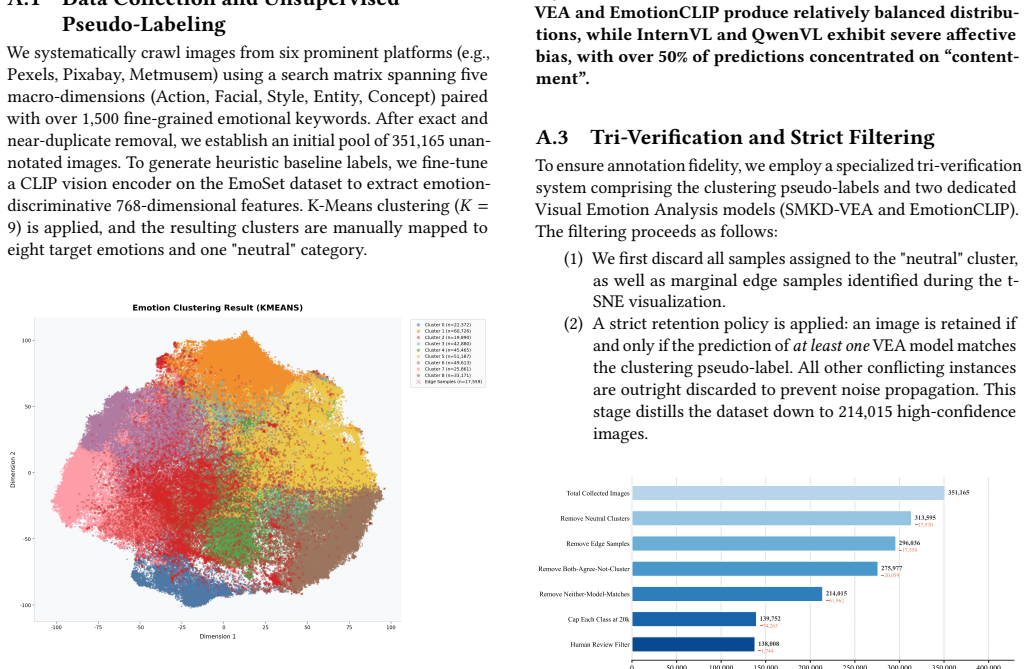
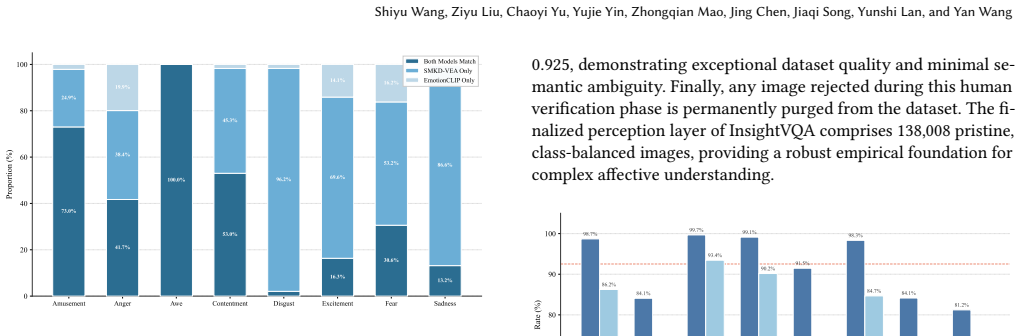
Sitao Zhang, Yimu Pan, and James Z. Wang. 2023. Learning Emotion Representa- tions from Verbal and Nonverbal Communication. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 18993–19004. doi:10.1109/CVPR52729.2023.01821 InsightVQA: High-Dimensional Emotion-Cognitive Visual Question Answering Benchmark A Detailed D...
-
[60]
contentment
is applied, and the resulting clusters are manually mapped to eight target emotions and one "neutral" category. Figure 5: t-SNE Visualization of Unsupervised Emotion Clus- tering. We apply K-Means (𝐾=9) on fine-tuned CLIP features extracted from 351,165 images. Each point represents an im- age, colored by its assigned cluster. Edge samples (marked with×) ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.