A combination of noise and bilateral filters achieve supralinear and scalable adversarial robustness in CNNs
Pith reviewed 2026-06-28 15:21 UTC · model grok-4.3
The pith
Gaussian noise and bilateral filtering combine for supralinear adversarial robustness in CNNs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Gaussian noise and bilateral filtering enhance robustness against adversarial attacks through complementary mechanisms, resulting in supralinear robustness when combined; a simple preprocessor that applies both operations therefore yields larger gains than either operation alone, and the same preprocessor further improves adversarial training while remaining computationally cheap.
What carries the argument
A preprocessor that adds Gaussian noise and then applies bilateral filtering before the image enters the network.
If this is right
- The preprocessor can be inserted into any existing CNN pipeline with almost no extra compute.
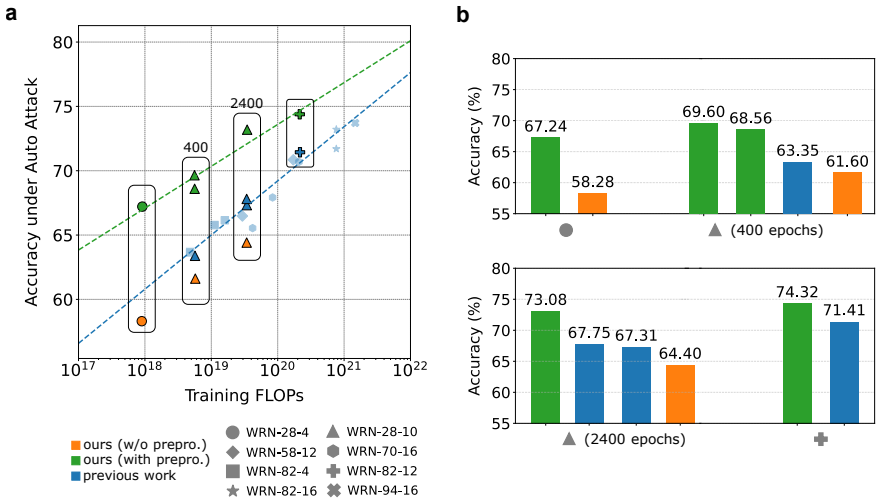
- When paired with adversarial training the combined defense reaches top rankings on RobustBench while using roughly one-third the training epochs and one-sixth the data of prior state-of-the-art entries.
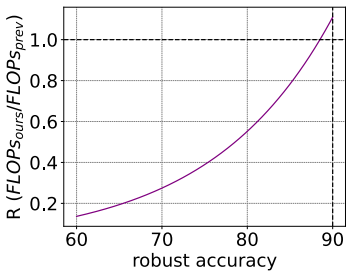
- The same method maintains accuracy parity with competing models across three orders of magnitude in total compute, using two to eight times less compute at every scale.
- Because the preprocessor is attack-agnostic it improves robustness to multiple attack types without retraining the defense for each type.
Where Pith is reading between the lines
- Similar pairs of cheap, complementary preprocessing steps might produce synergistic robustness in other vision models.
- The reduction in required training resources could make strong adversarial defenses practical on smaller hardware budgets.
- The approach might extend to sequential data or other modalities if analogous complementary filters can be identified.
Load-bearing premise
The two operations improve robustness by acting on different aspects of an adversarial perturbation so that their benefits add constructively rather than redundantly.
What would settle it
Measure the robust accuracy of the combined preprocessor against the sum of the robust accuracies obtained by noise alone and by bilateral filtering alone; if the combined accuracy is no larger than the sum, the supralinear claim does not hold.
Figures
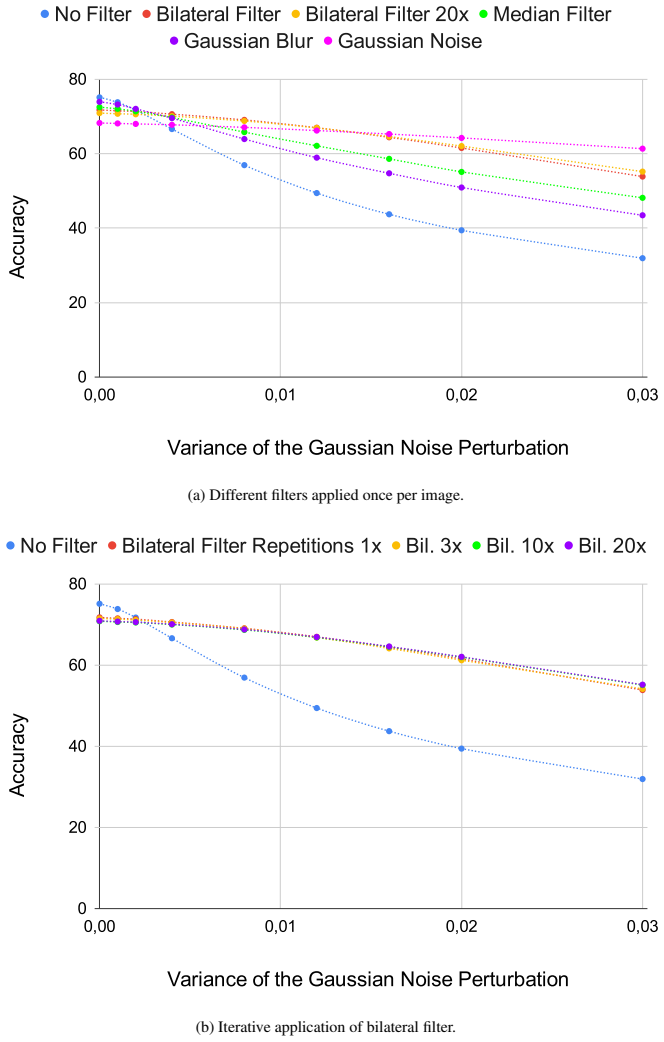
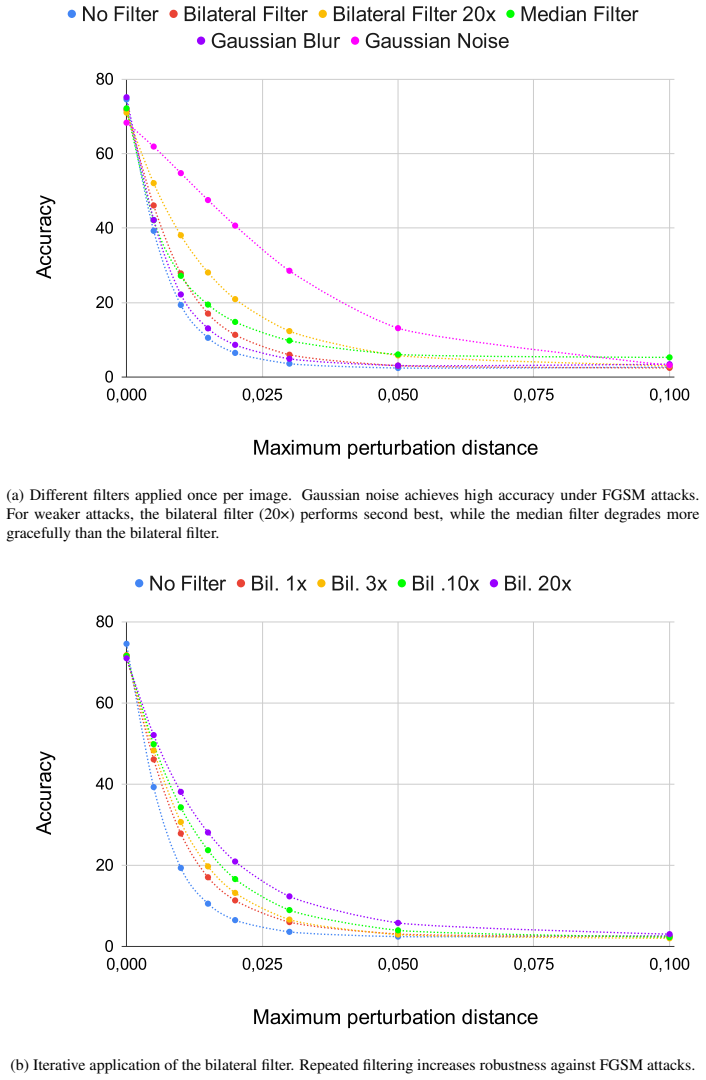
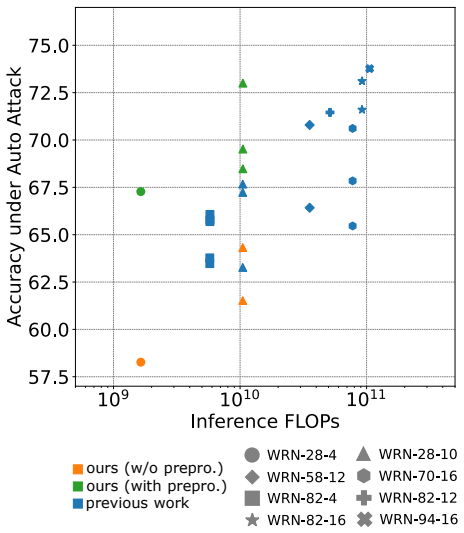
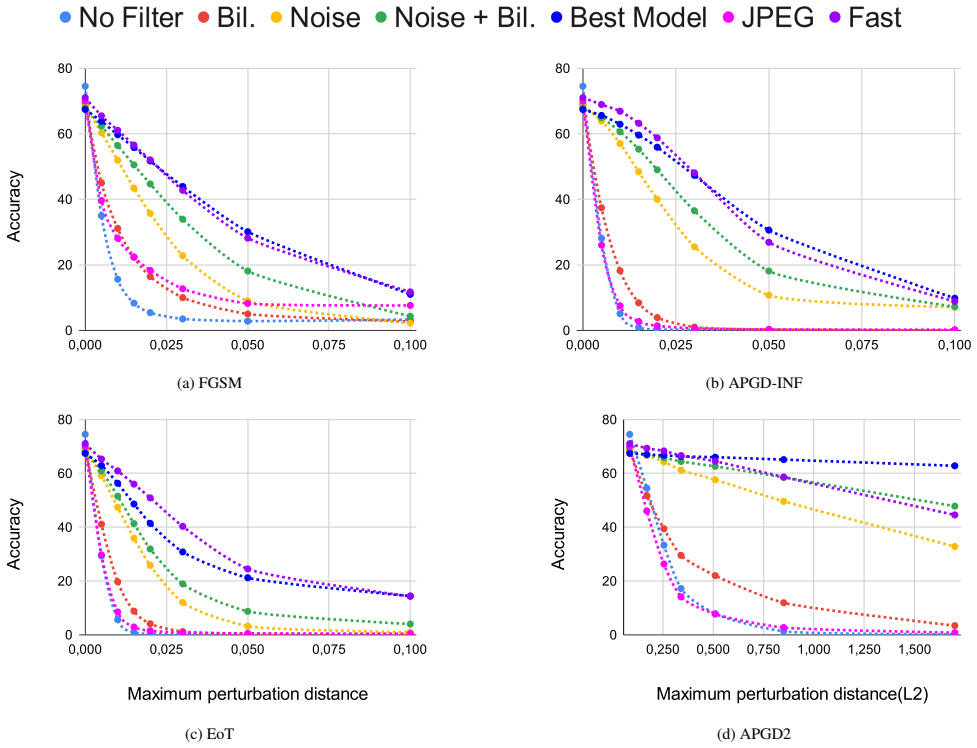

read the original abstract
The vulnerability of deep neural networks to adversarial examples poses a significant challenge for real-world deployment. Existing techniques to enhance deep network robustness rely on adversarial training, an approach that is powerful but computationally intensive and typically tailored to specific attack types. To address these limitations, existing works have explored techniques such as adding gaussian noise or filtering images, both of which can boost the network robustness to various adversarial attacks, albeit modestly. Here, we theoretically demonstrate that these two approaches enhance robustness against adversarial attacks through complementary mechanisms, resulting in supralinear robustness when combined. Building on this insight, we experimentally show that a simple preprocessor combining Gaussian noise and bilateral filtering yields supralinear improvements in adversarial robustness with minimal computational cost. Next, we combine our preprocessor with adversarial training and test on RobustBench to assess its supralinear improvement over state-of-the-art defenses. First, this combination ranks second on AutoAttack and third overall, while using only $\sim$35% of the training FLOPs, using a model with $\sim$50% less parametets, trained with $\sim$33% of the epochs and $\sim$15% the data compared to state-of-the-art defenses. Second, our method scales efficiently, matching the accuracy of competing models with roughly 2-8x less total compute across 3 orders of magnitude. Overall, our approach provides a principled and easily integrable framework for enhancing adversarial robustness, offering negligible computational overhead and a simple yet theoretically grounded design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Gaussian noise and bilateral filtering improve adversarial robustness in CNNs via complementary mechanisms, yielding supralinear gains when combined in a simple preprocessor. It further reports that this preprocessor, when added to adversarial training, achieves competitive rankings on RobustBench (2nd on AutoAttack, 3rd overall) while using ~35% of the training FLOPs, ~50% fewer parameters, ~33% of the epochs, and ~15% of the data relative to SOTA defenses, and scales with 2-8x less total compute.
Significance. If the theoretical claim of complementary mechanisms holds without circularity and the experimental controls are sound, the work would provide a low-overhead, scalable addition to existing defenses. The reported efficiency gains across compute scales would be a notable practical contribution if reproducible.
major comments (2)
- [Abstract / Theoretical demonstration] Abstract and theoretical section: the central claim of a theoretical demonstration that the two filters act through complementary mechanisms to produce supralinear robustness is asserted without derivation steps, equations, or explicit definitions of the mechanisms. This prevents evaluation of whether the result is parameter-free or reduces to normalization/fitting choices.
- [Experimental results / RobustBench evaluation] Experimental claims (RobustBench rankings and scaling): the supralinear improvement and reduced-compute assertions rest on the preprocessor being free of post-hoc data selection or parameter tuning that would make gains circular; no controls or ablation details are supplied in the available text to confirm this.
Simulated Author's Rebuttal
We thank the referee for their comments on our manuscript. We address each major comment below and commit to revisions that strengthen the presentation of the theoretical claims and experimental controls without altering the core results.
read point-by-point responses
-
Referee: [Abstract / Theoretical demonstration] Abstract and theoretical section: the central claim of a theoretical demonstration that the two filters act through complementary mechanisms to produce supralinear robustness is asserted without derivation steps, equations, or explicit definitions of the mechanisms. This prevents evaluation of whether the result is parameter-free or reduces to normalization/fitting choices.
Authors: We acknowledge that the theoretical section asserts the complementary mechanisms but does not include sufficient derivation steps or explicit equations in the main text. The argument is based on the distinct effects of Gaussian noise (isotropic perturbation of input distributions) and bilateral filtering (edge-preserving denoising that attenuates high-frequency adversarial perturbations differently), but these are described at a high level. In revision we will add the full mathematical derivations, precise definitions of each mechanism, and a proof sketch showing why their combination yields supralinear robustness that is independent of post-hoc fitting or normalization choices. revision: yes
-
Referee: [Experimental results / RobustBench evaluation] Experimental claims (RobustBench rankings and scaling): the supralinear improvement and reduced-compute assertions rest on the preprocessor being free of post-hoc data selection or parameter tuning that would make gains circular; no controls or ablation details are supplied in the available text to confirm this.
Authors: The preprocessor parameters were chosen from the theoretical analysis and standard bilateral-filter defaults rather than test-set tuning, and RobustBench evaluations follow the benchmark protocol. However, the manuscript does not supply explicit ablation tables or controls documenting this process. We will add these details in revision, including parameter-selection ablations, confirmation that no post-hoc data selection occurred, and expanded scaling plots with compute breakdowns to substantiate the efficiency claims. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract asserts a theoretical demonstration of complementary mechanisms between Gaussian noise and bilateral filtering yielding supralinear robustness, yet supplies no equations, derivation steps, fitted parameters, or self-citations. No load-bearing claim reduces by construction to its inputs, and the full manuscript text is not inspectable here. The central claim therefore cannot be shown to be circular from the given material; the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sajjad Amini, Mohammadreza Teymoorianfard, Shiqing Ma, and Amir Houmansadr. MeanSparse: Post-Training Robust- ness Enhancement Through Mean-Centered Feature Sparsi- fication, 2024. arXiv:2406.05927 [cs]. 6
-
[2]
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples, 2018. arXiv:1802.00420 [cs]. 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Synthesizing robust adversarial examples
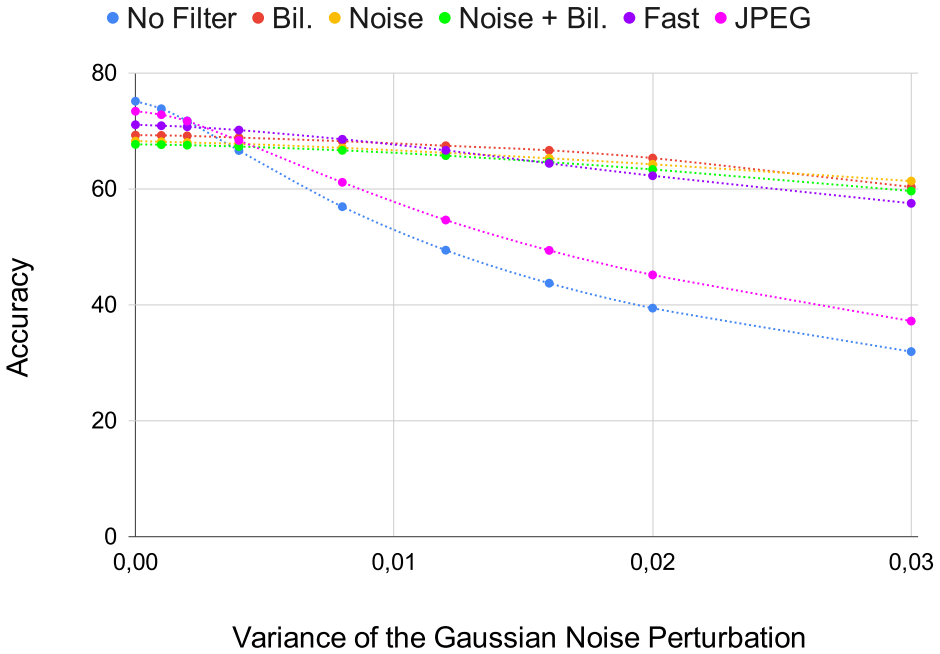
Anish Athalye, Logan Engstrom, Andrew Ilyas, and Kevin Kwok. Synthesizing robust adversarial examples. InPro- ceedings of the 35th International Conference on Machine Learning, pages 284–293. PMLR, 2018. 6
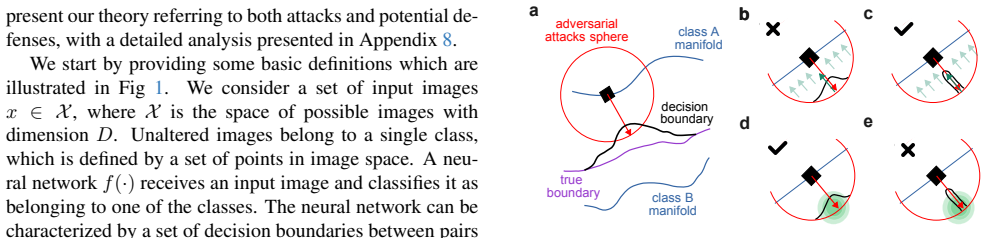
2018
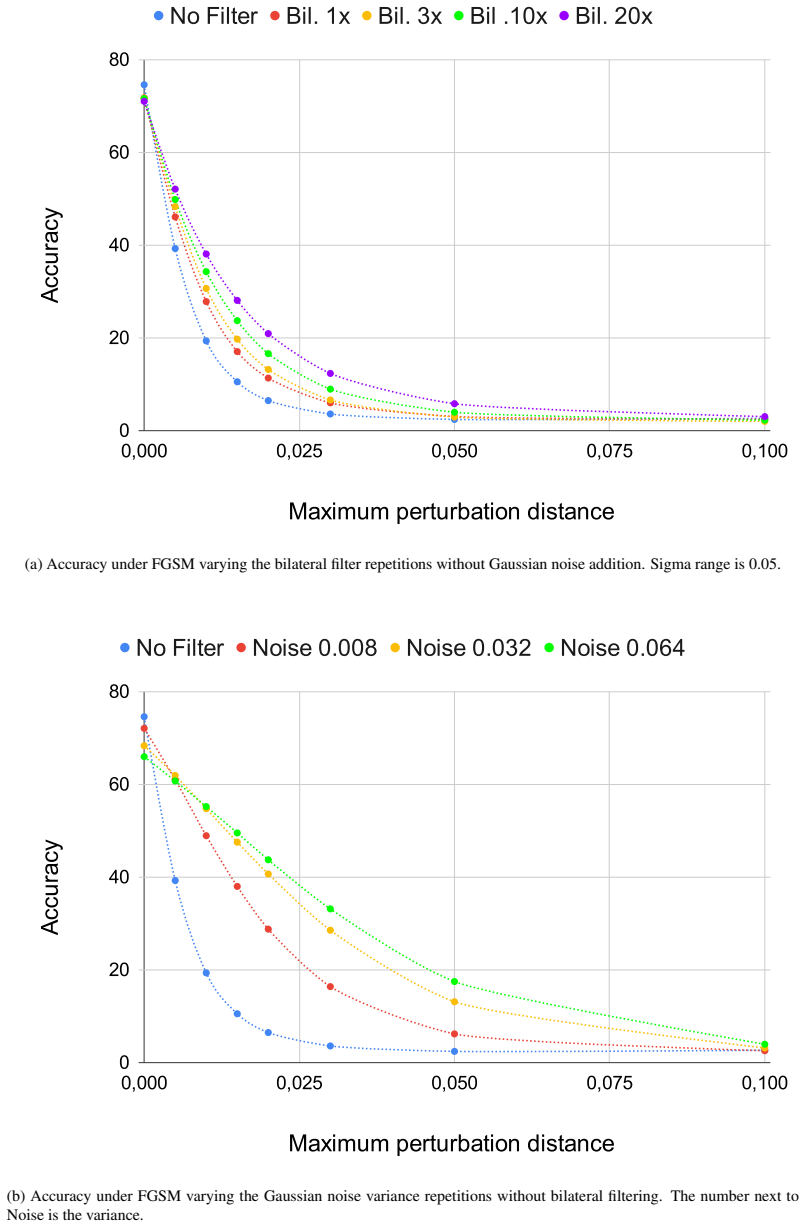
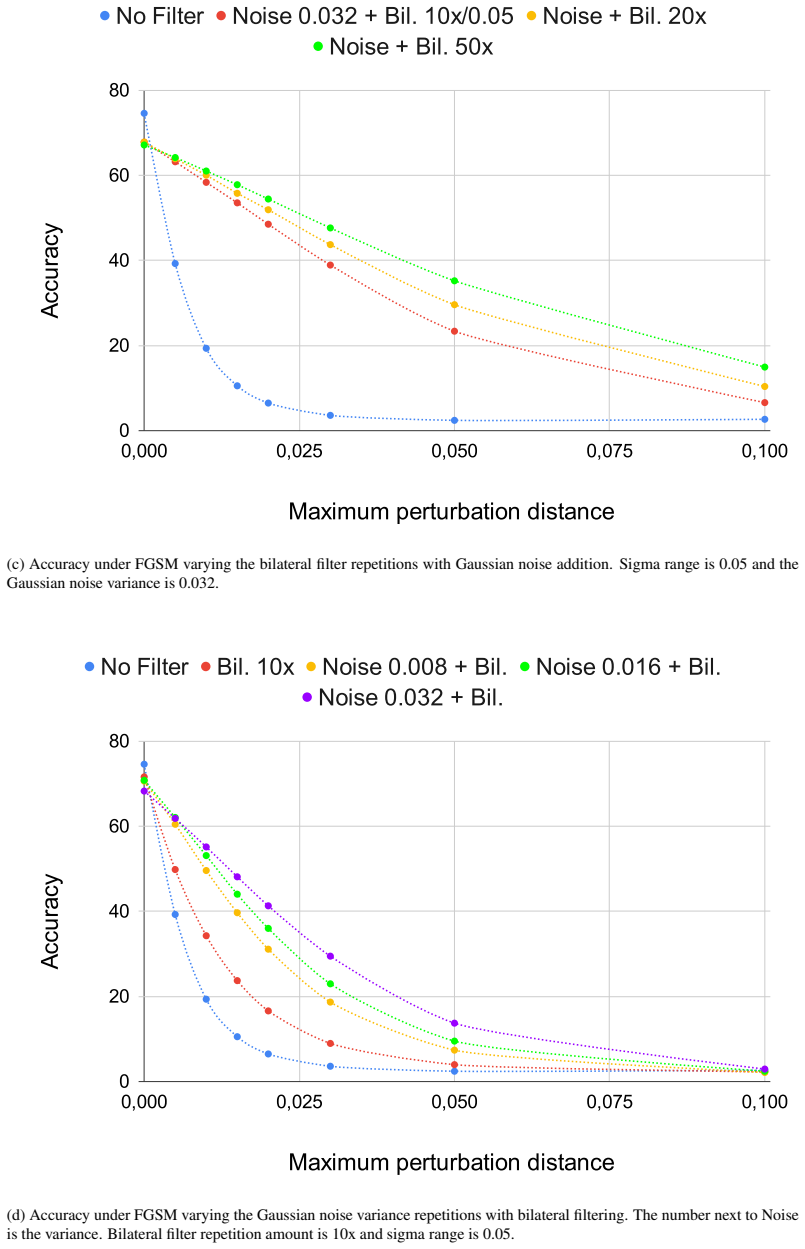
-
[4]
Bartoldson, James Diffenderfer, Konstantinos Parasyris, and Bhavya Kailkhura
Brian R. Bartoldson, James Diffenderfer, Konstantinos Parasyris, and Bhavya Kailkhura. Adversarial Robust- ness Limits via Scaling-Law and Human-Alignment Studies,
-
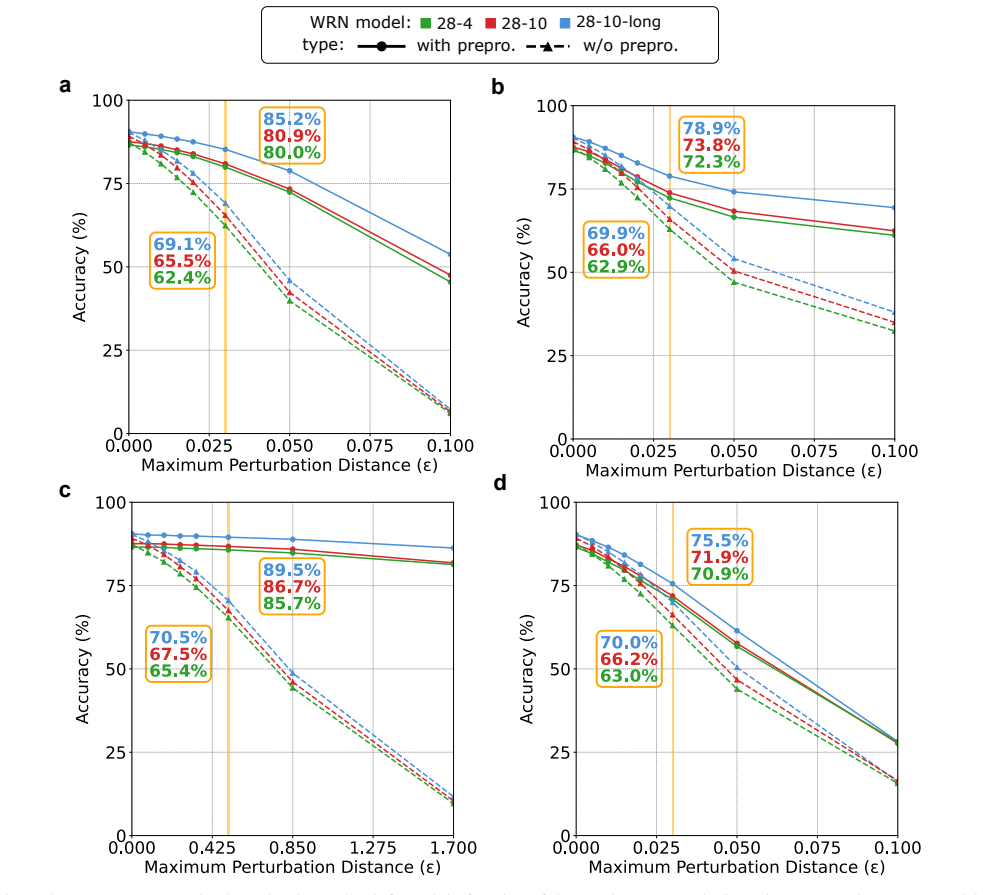
[5]
1, 2, 5, 6, 8, 10, 15
-
[6]
Loss of sensitivity in an analog neural circuit.Journal of Neuro- science, 29(10):3045–3058, 2009
Bart G Borghuis, Peter Sterling, and Robert G Smith. Loss of sensitivity in an analog neural circuit.Journal of Neuro- science, 29(10):3045–3058, 2009. 8
2009
-
[7]
Intriguing properties of neural networks
Joan Bruna, Dumitru Erhan, Ian Goodfellow, Rob Fer- gus, Christian Szegedy, Wojciech Zaremba, and Ilya Sutskever. Intriguing properties of neural networks, 2014. arXiv:1312.6199 [cs]. 1
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[8]
Towards Evaluating the Robustness of Neural Networks
Nicholas Carlini and David Wagner. Towards Evaluating the Robustness of Neural Networks. In2017 IEEE Symposium on Security and Privacy (SP), pages 39–57, 2017. ISSN: 2375-1207. 4, 6
2017
-
[9]
Zico Kolter
Nicholas Carlini, Florian Tramer, Krishnamurthy Dj Dvi- jotham, Leslie Rice, Mingjie Sun, and J. Zico Kolter. (certi- fied!!) adversarial robustness for free!, 2023. 2
2023
-
[10]
Diffusion models for imperceptible and transferable adversarial attack, 2023
Jianqi Chen, Hao Chen, Keyan Chen, Yilan Zhang, Zhengxia Zou, and Zhenwei Shi. Diffusion models for imperceptible and transferable adversarial attack, 2023. 1
2023
-
[11]
High-Performance Neural Networks for Visual Object Classification
Dan C. Cires ¸an, Ueli Meier, Jonathan Masci, Luca M. Gambardella, and J ¨urgen Schmidhuber. High-Performance Neural Networks for Visual Object Classification, 2011. arXiv:1102.0183 [cs]. 1
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[12]
Cohen, Elan Rosenfeld, and J
Jeremy M. Cohen, Elan Rosenfeld, and J. Zico Kolter. Cer- tified Adversarial Robustness via Randomized Smoothing,
-
[13]
Francesco Croce and Matthias Hein. Reliable evalua- tion of adversarial robustness with an ensemble of diverse parameter-free attacks, 2020. arXiv:2003.01690 [cs, stat]. 6
-
[14]
Robustbench: a standardized adversarial robustness benchmark.arXiv preprint arXiv:2010.09670, 2020
Francesco Croce, Maksym Andriushchenko, Vikash Se- hwag, Edoardo Debenedetti, Nicolas Flammarion, Mung Chiang, Prateek Mittal, and Matthias Hein. Robustbench: a standardized adversarial robustness benchmark.arXiv preprint arXiv:2010.09670, 2020. 2, 5, 6, 7
-
[15]
Decoupled kullback-leibler divergence loss, 2024
Jiequan Cui, Zhuotao Tian, Zhisheng Zhong, Xiaojuan Qi, Bei Yu, and Hanwang Zhang. Decoupled kullback-leibler divergence loss, 2024. 6, 15
2024
-
[16]
Keeping the Bad Guys Out: Protecting and Vaccinating Deep Learning with JPEG Compression
Nilaksh Das, Madhuri Shanbhogue, Shang-Tse Chen, Fred Hohman, Li Chen, Michael E. Kounavis, and Duen Horng Chau. Keeping the Bad Guys Out: Protecting and Vac- cinating Deep Learning with JPEG Compression, 2017. arXiv:1705.02900 [cs]. 2, 4, 5, 7, 12
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 6
2009
-
[18]
Gintare Karolina Dziugaite, Zoubin Ghahramani, and Daniel M. Roy. A study of the effect of JPG compression on adversarial images, 2016. arXiv:1608.00853 [cs]. 2, 4, 5, 7, 12
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Empirical study of the topol- ogy and geometry of deep networks
Alhussein Fawzi, Seyed-Mohsen Moosavi-Dezfooli, Pascal Frossard, and Stefano Soatto. Empirical study of the topol- ogy and geometry of deep networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 3762–3770, 2018. 1
2018
-
[20]
Adversarial examples are a natural consequence of test error in noise, 2019
Nic Ford, Justin Gilmer, Nicolas Carlini, and Dogus Cubuk. Adversarial examples are a natural consequence of test error in noise, 2019. 2
2019
-
[21]
Synaptic noise is an information bottleneck in the inner retina during dynamic visual stimulation.The Journal of physiology, 592(4):635– 651, 2014
Michael A Freed and Zhiyin Liang. Synaptic noise is an information bottleneck in the inner retina during dynamic visual stimulation.The Journal of physiology, 592(4):635– 651, 2014. 8
2014
- [22]
-
[23]
How many dimensions are required to find an adversarial exam- ple? InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 2353–2360,
Charles Godfrey, Henry Kvinge, Elise Bishoff, Myles Mckay, Davis Brown, Tim Doster, and Eleanor Byler. How many dimensions are required to find an adversarial exam- ple? InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 2353–2360,
-
[24]
Explaining and Harnessing Adversarial Examples
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and Harnessing Adversarial Examples, 2015. arXiv:1412.6572 [cs, stat]. 1, 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
Towards Deep Neural Network Architectures Robust to Adversarial Examples
Shixiang Gu and Luca Rigazio. Towards Deep Neural Net- work Architectures Robust to Adversarial Examples, 2015. arXiv:1412.5068 [cs]. 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
Countering Adversarial Images using Input Transformations, 2017
Chuan Guo, Mayank Rana, Moustapha Cisse, and Laurens van der Maaten. Countering Adversarial Images using Input Transformations, 2017. 2, 4, 12
2017
-
[27]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition, 2015. arXiv:1512.03385 [cs]. 1
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[28]
Gaussian error linear units (GELUs), 2023
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (GELUs), 2023. 4, 6
2023
-
[29]
Hermann, Ting Chen, and Simon Kornblith
Katherine L. Hermann, Ting Chen, and Simon Kornblith. The Origins and Prevalence of Texture Bias in Convolutional Neural Networks, 2020. arXiv:1911.09071. 5
-
[30]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InProc. NeurIPS, 2022. 4, 6
2022
-
[31]
Hammad Javed, Ehtasham Ahmed, Syed A A Shah, and Syed Umaid Ali
Suleman Khan, M. Hammad Javed, Ehtasham Ahmed, Syed A A Shah, and Syed Umaid Ali. Facial Recogni- tion using Convolutional Neural Networks and Implemen- tation on Smart Glasses.2019 International Conference on Information Science and Communication Technology 9 (ICISCT), pages 1–6, 2019. Conference Name: 2019 Inter- national Conference on Information Scien...
2019
-
[32]
Torchattacks: A pytorch repository for adversar- ial attacks.arXiv preprint arXiv:2010.01950, 2020
Hoki Kim. Torchattacks: A pytorch repository for adversar- ial attacks.arXiv preprint arXiv:2010.01950, 2020. 7
-
[33]
Cifar-10 (canadian institute for advanced research)
Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. Cifar-10 (canadian institute for advanced research). 4, 6
-
[34]
Im- ageNet Classification with Deep Convolutional Neural Net- works
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Im- ageNet Classification with Deep Convolutional Neural Net- works. InAdvances in Neural Information Processing Sys- tems. Curran Associates, Inc., 2012. 1
2012
-
[35]
Certified robustness to ad- versarial examples with differential privacy
Mathias Lecuyer, Vaggelis Atlidakis, Roxana Geambasu, Daniel Hsu, and Suman Jana. Certified robustness to ad- versarial examples with differential privacy. In2019 IEEE Symposium on Security and Privacy (SP), pages 656–672,
-
[36]
Certified Adversarial Robustness with Additive Noise, 2019
Bai Li, Changyou Chen, Wenlin Wang, and Lawrence Carin. Certified Adversarial Robustness with Additive Noise, 2019. arXiv:1809.03113. 2
-
[37]
Defense against Adversarial At- tacks Using High-Level Representation Guided Denoiser,
Fangzhou Liao, Ming Liang, Yinpeng Dong, Tianyu Pang, Xiaolin Hu, and Jun Zhu. Defense against Adversarial At- tacks Using High-Level Representation Guided Denoiser,
-
[38]
arXiv:1712.02976 [cs]. 2
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Convolutional neural networks as a model of the visual system: Past, present, and future.Journal of cognitive neuroscience, 33(10):2017–2031, 2021
Grace W Lindsay. Convolutional neural networks as a model of the visual system: Past, present, and future.Journal of cognitive neuroscience, 33(10):2017–2031, 2021. 8
2017
-
[40]
Imagenet10.https://www.kaggle.com/ datasets / liusha249 / imagenet10, 2020
Sha Liu. Imagenet10.https://www.kaggle.com/ datasets / liusha249 / imagenet10, 2020. Ac- cessed: 2026-01-27. 4, 1, 6
2020
-
[41]
Towards Deep Learning Models Resistant to Adversarial Attacks, 2017
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards Deep Learning Models Resistant to Adversarial Attacks, 2017. 2
2017
-
[42]
Adversarial attacks on traffic sign recognition: A sur- vey
Svetlana Pavlitska, Nico Lambing, and J Marius Z ¨ollner. Adversarial attacks on traffic sign recognition: A sur- vey. In2023 3rd International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), pages 1–6. IEEE, 2023. 1
2023
-
[43]
Barrage of random transforms for adversarially ro- bust defense
Edward Raff, Jared Sylvester, Steven Forsyth, and Mark McLean. Barrage of random transforms for adversarially ro- bust defense. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 2
2019
-
[44]
Unifying Bilateral Filtering and Adversarial Training for Robust Neural Networks
Neale Ratzlaff and Li Fuxin. Unifying Bilateral Filtering and Adversarial Training for Robust Neural Networks, 2018. arXiv:1804.01635 [cs]. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[45]
Kornia: an Open Source Differ- entiable Computer Vision Library for PyTorch, 2019
Edgar Riba, Dmytro Mishkin, Daniel Ponsa, Ethan Rublee, and Gary Bradski. Kornia: an Open Source Differ- entiable Computer Vision Library for PyTorch, 2019. arXiv:1910.02190 [cs]. 6
-
[46]
A deep learning framework for neuroscience.Nature neuroscience, 22(11):1761–1770, 2019
Blake A Richards, Timothy P Lillicrap, Philippe Beaudoin, Yoshua Bengio, Rafal Bogacz, Amelia Christensen, Claudia Clopath, Rui Ponte Costa, Archy de Berker, Surya Ganguli, et al. A deep learning framework for neuroscience.Nature neuroscience, 22(11):1761–1770, 2019. 8
2019
-
[47]
Adi Shamir, Odelia Melamed, and Oriel BenShmuel. The dimpled manifold model of adversarial examples in machine learning.arXiv preprint arXiv:2106.10151, 2021. 3, 4
-
[48]
Defending Adver- sarial Attacks against DNN Image Classification Models by a Noise-Fusion Method.Electronics, 11(12):1814, 2022
Lin Shi, Teyi Liao, and Jianfeng He. Defending Adver- sarial Attacks against DNN Image Classification Models by a Noise-Fusion Method.Electronics, 11(12):1814, 2022. Number: 12 Publisher: Multidisciplinary Digital Publishing Institute. 2, 8
2022
-
[49]
Mingxing Tan and Quoc V . Le. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, 2020. arXiv:1905.11946 [cs, stat]. 4, 5, 2, 6, 12, 16, 17
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[50]
Tomasi and R
C. Tomasi and R. Manduchi. Bilateral filtering for gray and color images. InSixth International Conference on Com- puter Vision (IEEE Cat. No.98CH36271), pages 839–846,
-
[51]
Adversarial training and robustness for multiple perturbations, 2019
Florian Tram `er and Dan Boneh. Adversarial training and robustness for multiple perturbations, 2019. 1, 2
2019
-
[52]
Adversarial attacks against face recogni- tion: A comprehensive study.IEEE Access, 9:92735–92756,
Fatemeh Vakhshiteh, Ahmad Nickabadi, and Raghavendra Ramachandra. Adversarial attacks against face recogni- tion: A comprehensive study.IEEE Access, 9:92735–92756,
-
[53]
Better diffusion models further improve adversarial training, 2023
Zekai Wang, Tianyu Pang, Chao Du, Min Lin, Weiwei Liu, and Shuicheng Yan. Better diffusion models further improve adversarial training, 2023. 1, 2, 4, 6, 8, 15
2023
-
[54]
Eric Wong, Leslie Rice, and J. Zico Kolter. Fast is better than free: Revisiting adversarial training, 2020. arXiv:2001.03994 [cs, stat]. 2, 4, 6, 12
-
[55]
Mitigating adversarial effects through random- ization, 2018
Cihang Xie, Jianyu Wang, Zhishuai Zhang, Zhou Ren, and Alan Yuille. Mitigating adversarial effects through random- ization, 2018. 2
2018
-
[56]
Sergey Zagoruyko and Nikos Komodakis. Wide Residual Networks, 2017. arXiv:1605.07146. 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[57]
Theoretically Principled Trade-off between Robustness and Accuracy
Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric P. Xing, Laurent El Ghaoui, and Michael I. Jordan. Theoreti- cally Principled Trade-off between Robustness and Accu- racy, 2019. arXiv:1901.08573. 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[58]
Comment on "Adv-BNN: Improved Adversarial Defense through Robust Bayesian Neural Network"
Roland S. Zimmermann. Comment on ”Adv-BNN: Im- proved Adversarial Defense through Robust Bayesian Neural Network”, 2019. arXiv:1907.00895 [cs, stat]. 4
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[59]
Low-Pass Image Filtering to Achieve Adversarial Robustness.Sensors (Basel, Switzerland), 23(22):9032, 2023
Vadim Ziyadinov and Maxim Tereshonok. Low-Pass Image Filtering to Achieve Adversarial Robustness.Sensors (Basel, Switzerland), 23(22):9032, 2023. 1, 2 10 A combination of noise and bilateral filters achieve supralinear and scalable adversarial robustness in CNNs Supplementary Material
2023
-
[60]
First we clearly see that our preprocessor largely increases the accuracy for all adversarial attacks tested
Imagenet10 We also did a short ablation study on imagenet10 [38] to see if our preprocessor also works with other datasets see table 3. First we clearly see that our preprocessor largely increases the accuracy for all adversarial attacks tested. Fur- ther, bilateral filtering seems to be much more effective on Imagnet10 then on CIFAR-10. However, we no lo...
-
[61]
Theory and derivations In this section we present our theory suggesting that gaus- sian noise and filters have distinct mechanisms to enhance robustness against adversarial attacks, which result in them being useful against different types of attacks. We will first present our basic definitions and the conceptual framework that we will use, and then proce...
-
[62]
Mostly we first add zero-mean Gaussian noise independently to each color channel of every pixel, and then apply multiple bilateral filters to the resulting image
Detailed description of the preprocessor components In this section, we provide a detailed description of the im- age processing methods used in our preprocessor. Mostly we first add zero-mean Gaussian noise independently to each color channel of every pixel, and then apply multiple bilateral filters to the resulting image. We also test changing the order...
-
[63]
We use adapted functions from the Kornia library [43], a computer vision toolkit built on PyTorch, to imple- ment the preprocessing steps
Experimental details In our implementation, the preprocessor is integrated as an additional layer that can used during both training and in- ference. We use adapted functions from the Kornia library [43], a computer vision toolkit built on PyTorch, to imple- ment the preprocessing steps. These include the optional addition of pixel-wise Gaussian noise and...
-
[64]
We conduct all experiments using NVIDIA GeForce RTX 3090 or NVIDIA Quadro RTX 6000 GPUs
The hyperparameters for the preprocessor can be found in Table 7. We conduct all experiments using NVIDIA GeForce RTX 3090 or NVIDIA Quadro RTX 6000 GPUs. For all these experiments, expect for those using the WRN- 82-12, we use 4 RTX 3090 together. For all experiments using the WRN-82-12 we use 8 RTX 6000 together. The WRN-28-4 take around 7 hours to trai...
-
[65]
The training as well as the testing runs are all done on a single NVIDIA GeForce RTX 3090
we use in this experiments, we use the Adam optimizer with a learning rate of 1e-3 and a weight decay of 1e-6, a batch size of 128 and train over 60 epochs. The training as well as the testing runs are all done on a single NVIDIA GeForce RTX 3090. 10.3. Adversarial attacks and noise robustness In this section, we describe the types of adversarial attacks ...
-
[66]
Test accuracy (in %) on the clean CIFAR10 dataset and under different adversarial attacks
Supplementary figures 11 Table 10. Test accuracy (in %) on the clean CIFAR10 dataset and under different adversarial attacks. We test standard CNN models
-
[67]
The best results are highlighted in bold
trained without (first row) and with different defense methods. The best results are highlighted in bold. For L∞ attacks, we set ϵ= 0.03≈8/255 , and for L2 attacks, we set ϵ= 0.51 , which are standard values in the literature [15, 17]. For the C&W attack, we set c= 1.8 for the standard CNN as the strongest tested attacks. The variance of the Gaussian nois...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.