Dynamics Are Learned, Not Told: Semi-Supervised Discovery of Latent Dynamics Geometries For Zero-Shot Policy Adaptation
Pith reviewed 2026-06-28 14:34 UTC · model grok-4.3
The pith
Controlling latent dynamics geometry via contrastive learning enables zero-shot policy adaptation to severe shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a monotonic relationship exists between target-domain regret and the Lipschitz constant of a trajectory dynamics encoder; this constant can be upper-bounded through contrastive learning on outcomes alone, yielding a smooth task-relevant latent topology that supports zero-shot adaptation to severe dynamics shifts, including unmodeled and time-varying parameters.
What carries the argument
The trajectory dynamics encoder, whose Lipschitz constant is upper-bounded by contrastive learning to induce a smooth latent geometry for outcome-based adaptation.
If this is right
- The method outperforms parameter-centric baselines under severe dynamics shifts including unmodeled and time-varying parameters.
- In-distribution stability improves alongside out-of-distribution adaptation.
- The resulting latent space shows higher interpretability than parameter-encoded alternatives.
- Adaptation works without pre-specified axes of variation or explicit dynamics identification.
Where Pith is reading between the lines
- The geometry approach may transfer to domains where dynamics parameters are ill-defined, such as soft or deformable robots.
- The learned latent topology could be reused across tasks to accelerate multi-goal adaptation without retraining the encoder.
- Making the contrastive signal fully unsupervised would further reduce reliance on any outcome labels during deployment.
Load-bearing premise
Target-domain regret decreases monotonically when the Lipschitz constant of the trajectory dynamics encoder is reduced, and contrastive learning can achieve this reduction without any privileged dynamics information.
What would settle it
An experiment on a new MuJoCo variant where contrastive learning successfully lowers the encoder's Lipschitz constant yet target-domain regret stays high or shows no correlation with the constant.
Figures
read the original abstract
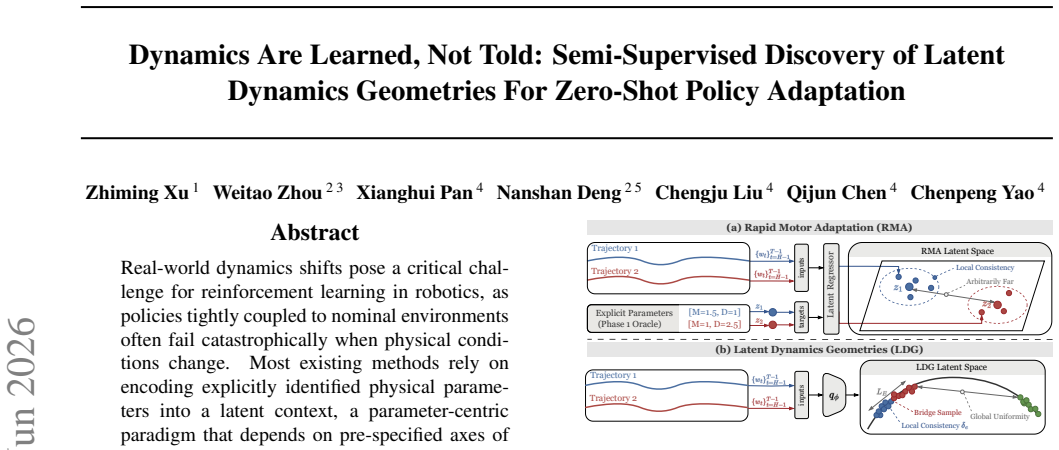
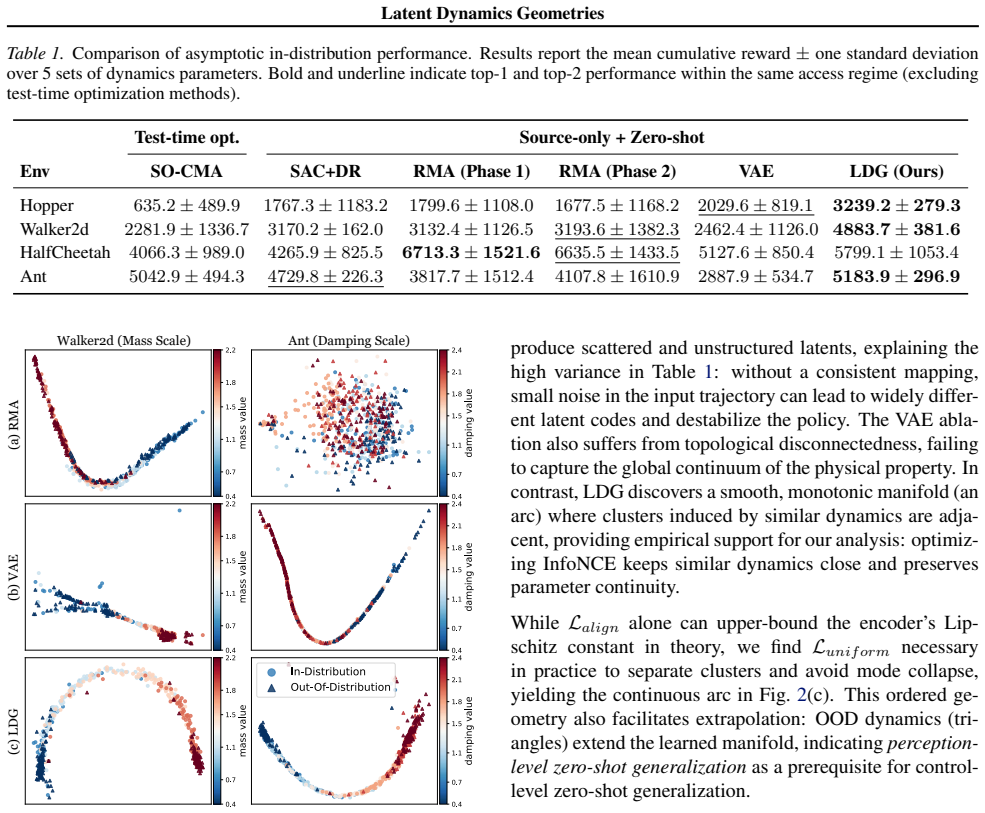
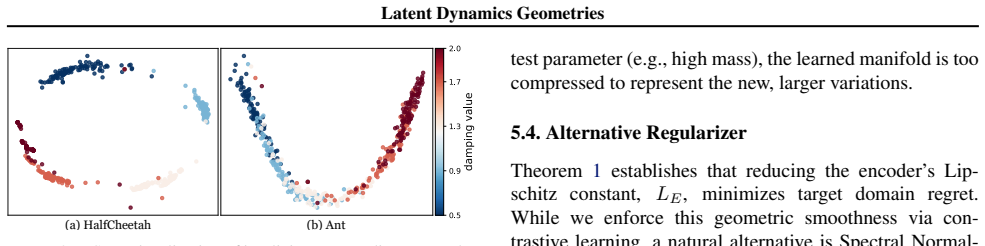
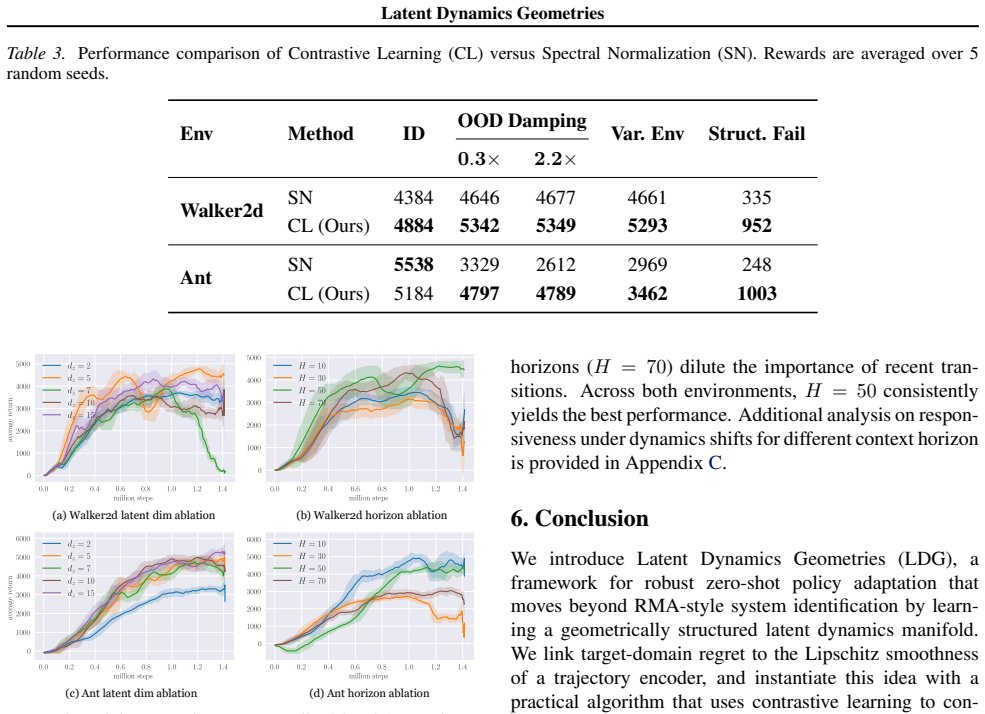
Real-world dynamics shifts pose a critical challenge for reinforcement learning in robotics, as policies tightly coupled to nominal environments often fail catastrophically when physical conditions change. Most existing methods rely on encoding explicitly identified physical parameters into a latent context, a parameter-centric paradigm that depends on pre-specified axes of variation and becomes brittle under unmodeled or compound dynamics changes. We revisit dynamics adaptation from an outcome-centric perspective: rather than telling policies what the dynamics are, we enable them to learn how dynamics affect interaction outcomes. Theoretically, this is grounded in a monotonic relationship between target-domain regret and the Lipschitz constant of a trajectory dynamics encoder. Practically, this constant can be upper-bounded through contrastive learning, yielding a smooth, task-relevant latent topology without privileged dynamics information. On MuJoCo benchmarks, our method consistently outperforms parameter-centric baselines under severe dynamics shifts, including unmodeled and time-varying parameters, while also improving in-distribution stability and latent interpretability. Overall, these results validate that controlling latent geometry is a principled mechanism for robust adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an outcome-centric method for zero-shot policy adaptation in robotics RL under dynamics shifts. Rather than encoding explicit physical parameters, it uses contrastive learning on trajectories to discover a smooth latent geometry that upper-bounds the Lipschitz constant of a trajectory dynamics encoder. This is theoretically grounded in a claimed monotonic relationship between target-domain regret and that Lipschitz constant. The approach is evaluated on MuJoCo benchmarks, where it reportedly outperforms parameter-centric baselines under unmodeled and time-varying shifts while also improving in-distribution performance and latent interpretability.
Significance. If the monotonic relationship and its contrastive bound hold with the stated scope, the work would supply a principled alternative to parameter-centric adaptation that does not require pre-specified axes of variation. This could be relevant for real-world robotics where shifts are compound or unmodeled. The empirical claims on standard benchmarks, if substantiated with full protocols and ablations, would provide concrete evidence of practical advantage.
major comments (2)
- [Abstract] Abstract: The central theoretical claim—a monotonic relationship between target-domain regret and the Lipschitz constant of the trajectory dynamics encoder that can be upper-bounded by contrastive learning without privileged dynamics information—is stated without any theorem statement, derivation, equation, or proof sketch. This relationship is load-bearing for attributing performance gains to latent-geometry control rather than to other aspects of the method.
- [Abstract] Abstract: The empirical claim of consistent outperformance on MuJoCo benchmarks under severe dynamics shifts supplies no metrics, ablation tables, exact experimental protocols, or statistical details, preventing verification that the data support the superiority attributed to the proposed mechanism.
minor comments (1)
- The abstract refers to 'semi-supervised discovery' but does not specify the form of supervision or how the contrastive objective differs from standard unsupervised contrastive losses.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the abstract to improve clarity on both the theoretical claim and empirical results while preserving its length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central theoretical claim—a monotonic relationship between target-domain regret and the Lipschitz constant of the trajectory dynamics encoder that can be upper-bounded by contrastive learning without privileged dynamics information—is stated without any theorem statement, derivation, equation, or proof sketch. This relationship is load-bearing for attributing performance gains to latent-geometry control rather than to other aspects of the method.
Authors: The full manuscript presents the theorem, monotonic relationship, and proof sketch in Section 3 (including the contrastive bound derivation). The abstract condenses this for brevity. We agree the abstract would benefit from a short reference to the key equation and bound to make the grounding explicit. We will revise the abstract to include one sentence summarizing the theorem without exceeding length limits. revision: yes
-
Referee: [Abstract] Abstract: The empirical claim of consistent outperformance on MuJoCo benchmarks under severe dynamics shifts supplies no metrics, ablation tables, exact experimental protocols, or statistical details, preventing verification that the data support the superiority attributed to the proposed mechanism.
Authors: The full paper reports these details in Sections 4–5 with tables, protocols, ablations, and statistics. The abstract summarizes the outcomes. We agree that adding 1–2 quantitative highlights (e.g., average regret reduction ranges) would strengthen verifiability. We will revise the abstract to incorporate key metrics from the experiments. revision: yes
Circularity Check
No significant circularity detected; derivation remains self-contained.
full rationale
The paper asserts a monotonic relationship between target-domain regret and the Lipschitz constant of a trajectory dynamics encoder as theoretical grounding for using contrastive learning to upper-bound that constant. No equations, theorems, or derivations are supplied in the provided text that reduce this relationship or the contrastive objective to fitted parameters on target data, self-citations, or inputs by construction. The method is described as learning latent geometries from interaction outcomes without privileged dynamics information, and the central claims do not exhibit self-definitional, fitted-input, or self-citation load-bearing patterns. The approach is presented as an empirical outcome-centric alternative validated on MuJoCo benchmarks, keeping the derivation chain independent of its own fitted results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption monotonic relationship between target-domain regret and the Lipschitz constant of a trajectory dynamics encoder
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Policy Transfer with Strategy Optimization , author=. International Conference on Learning Representations , year=
-
[2]
RMA: Rapid Motor Adaptation for Legged Robots , booktitle =
Kumar, Ashish and Fu, Zipeng and Pathak, Deepak and Malik, Jitendra , year =. RMA: Rapid Motor Adaptation for Legged Robots , booktitle =
-
[3]
IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
Adapting rapid motor adaptation for bipedal robots , author=. IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
-
[4]
Conference on Robot Learning , pages=
In-hand object rotation via rapid motor adaptation , author=. Conference on Robot Learning , pages=
-
[5]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rapid motor adaptation for robotic manipulator arms , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[6]
arXiv preprint arXiv:2508.12252 , year=
Robot Trains Robot: Automatic Real-World Policy Adaptation and Learning for Humanoids , author=. arXiv preprint arXiv:2508.12252 , year=
-
[7]
Learning Fast Adaptation With Meta Strategy Optimization , year=
Yu, Wenhao and Tan, Jie and Bai, Yunfei and Coumans, Erwin and Ha, Sehoon , journal=. Learning Fast Adaptation With Meta Strategy Optimization , year=
-
[8]
Machine learning , volume=
Near-optimal reinforcement learning in polynomial time , author=. Machine learning , volume=
-
[9]
International Conference on Machine Learning , pages=
Approximately optimal approximate reinforcement learning , author=. International Conference on Machine Learning , pages=
-
[10]
International Conference on Machine Learning , pages=
Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere , author=. International Conference on Machine Learning , pages=
-
[11]
2020 , booktitle =
Chen, Ting and Kornblith, Simon and Norouzi, Mohammad and Hinton, Geoffrey , title =. 2020 , booktitle =
2020
-
[12]
International Conference on Learning Representations , year=
beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework , author=. International Conference on Learning Representations , year=
-
[13]
International Conference on Learning Representations , year=
Auto-encoding variational bayes , author=. International Conference on Learning Representations , year=
-
[14]
IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
Mujoco: A physics engine for model-based control , author=. IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
-
[15]
Conference on Robot Learning , pages=
Learning latent representations to influence multi-agent interaction , author=. Conference on Robot Learning , pages=
-
[16]
Conference on Robot Learning , pages=
Learning representations that enable generalization in assistive tasks , author=. Conference on Robot Learning , pages=
-
[17]
IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
RILI: Robustly influencing latent intent , author=. IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
-
[18]
Advances in Neural Information Processing Systems , volume=
Supervised contrastive learning , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
International Conference on Learning Representations , year=
Off-Dynamics Reinforcement Learning: Training for Transfer with Domain Classifiers , author=. International Conference on Learning Representations , year=
-
[20]
Advances in Neural Information Processing Systems , volume=
Off-dynamics reinforcement learning via domain adaptation and reward augmented imitation , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Domain randomization for transferring deep neural networks from simulation to the real world , year=
Tobin, Josh and Fong, Rachel and Ray, Alex and Schneider, Jonas and Zaremba, Wojciech and Abbeel, Pieter , booktitle=. Domain randomization for transferring deep neural networks from simulation to the real world , year=
-
[22]
Sim-to-Real Transfer of Robotic Control with Dynamics Randomization , year=
Peng, Xue Bin and Andrychowicz, Marcin and Zaremba, Wojciech and Abbeel, Pieter , booktitle=. Sim-to-Real Transfer of Robotic Control with Dynamics Randomization , year=
-
[23]
International conference on machine learning , pages=
Model-agnostic meta-learning for fast adaptation of deep networks , author=. International conference on machine learning , pages=
-
[24]
International Conference on Learning Representations , year=
Learning to Adapt in Dynamic, Real-World Environments through Meta-Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[25]
International Conference on Machine Learning , pages=
Efficient off-policy meta-reinforcement learning via probabilistic context variables , author=. International Conference on Machine Learning , pages=
-
[26]
International Conference on Learning Representations , year=
VariBAD: A Very Good Method for Bayes-Adaptive Deep RL via Meta-Learning , author=. International Conference on Learning Representations , year=
-
[27]
International Conference on Machine Learning , pages=
Context-aware dynamics model for generalization in model-based reinforcement learning , author=. International Conference on Machine Learning , pages=
-
[28]
arXiv preprint arXiv:2506.07876 , year=
Versatile loco-manipulation through flexible interlimb coordination , author=. arXiv preprint arXiv:2506.07876 , year=
-
[29]
International Conference on Machine Learning , pages=
Learning latent dynamics for planning from pixels , author=. International Conference on Machine Learning , pages=
-
[30]
Advances in Neural Information Processing Systems , volume=
Embed to control: A locally linear latent dynamics model for control from raw images , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
International Conference on Learning Representations , year=
Diversity is All You Need: Learning Skills without a Reward Function , author=. International Conference on Learning Representations , year=
-
[32]
International Conference on Learning Representations , year=
Dynamics-Aware Unsupervised Discovery of Skills , author=. International Conference on Learning Representations , year=
-
[33]
Advances in Neural Information Processing Systems , volume=
Unsupervised domain adaptation with dynamics-aware rewards in reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Learning Latent and Changing Dynamics in Real Non-Stationary Environments , year=
Liu, Zihe and Lu, Jie and Xuan, Junyu and Zhang, Guangquan , journal=. Learning Latent and Changing Dynamics in Real Non-Stationary Environments , year=
-
[35]
International Conference on Learning Representations , year=
Learning Invariant Representations for Reinforcement Learning without Reconstruction , author=. International Conference on Learning Representations , year=
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Robust representation learning by clustering with bisimulation metrics for visual reinforcement learning with distractions , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[37]
International Conference on Learning Representations , year=
Contrastive Learning of Structured World Models , author=. International Conference on Learning Representations , year=
-
[38]
International Conference on Machine Learning , pages=
Darla: Improving zero-shot transfer in reinforcement learning , author=. International Conference on Machine Learning , pages=
-
[39]
Advances in Neural Information Processing Systems , volume=
Mdp homomorphic networks: Group symmetries in reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
International Conference on Machine Learning , pages=
Curl: Contrastive unsupervised representations for reinforcement learning , author=. International Conference on Machine Learning , pages=
-
[41]
International Conference on Learning Representations , year=
Data-Efficient Reinforcement Learning with Self-Predictive Representations , author=. International Conference on Learning Representations , year=
-
[42]
International Conference on Machine Learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International Conference on Machine Learning , pages=
-
[43]
Evolutionary computation , volume=
Reducing the time complexity of the derandomized evolution strategy with covariance matrix adaptation (CMA-ES) , author=. Evolutionary computation , volume=
-
[44]
Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning , pages=
Generating sentences from a continuous space , author=. Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning , pages=
-
[45]
Policy distillation , author=. arXiv preprint arXiv:1511.06295 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Science Robotics , volume=
Learning quadrupedal locomotion over challenging terrain , author=. Science Robotics , volume=. 2020 , publisher=
2020
-
[47]
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
An empirical evaluation of generic convolutional and recurrent networks for sequence modeling , author=. arXiv preprint arXiv:1803.01271 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Spectral Norm Regularization for Improving the Generalizability of Deep Learning
Spectral norm regularization for improving the generalizability of deep learning , author=. arXiv preprint arXiv:1705.10941 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
International Conference on Learning Representations , year=
Spectral Normalization for Generative Adversarial Networks , author=. International Conference on Learning Representations , year=
-
[51]
International Conference on Learning Representations , year=
Large Scale GAN Training for High Fidelity Natural Image Synthesis , author=. International Conference on Learning Representations , year=
-
[52]
International Conference on Machine Learning , pages=
Consistency Models , author=. International Conference on Machine Learning , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.