Beyond Isolated Behaviors: Hierarchical User Modeling for LLM Personalization
Pith reviewed 2026-06-28 14:48 UTC · model grok-4.3
The pith
Hierarchical structures from practices, habitus, and fields improve LLM personalization over flat behavior aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
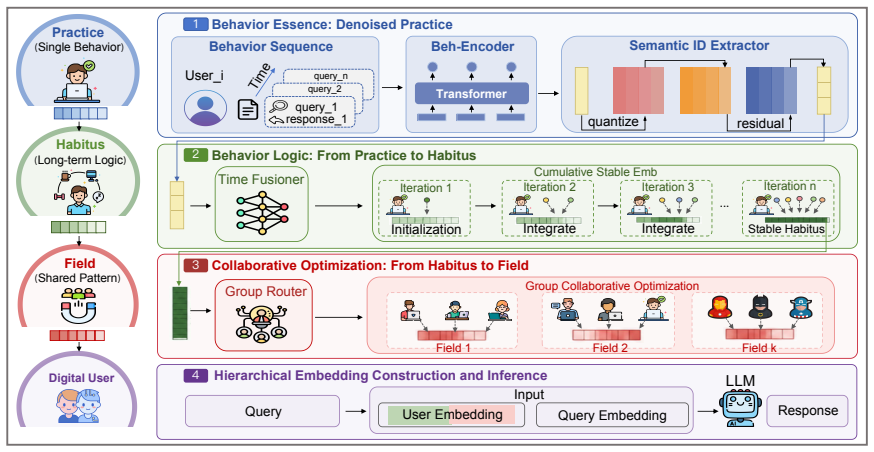
PHF reconceptualizes LLM personalization through three hierarchical levels: individual behaviors as practices, their temporal accumulation into stable dispositions as habitus, and shared regularities across similar users as fields. Instantiated via PHF_Compass on a frozen LLM, this yields consistent improvements on the LaMP benchmark and validates the interpretability and extensibility of the learned behavioral structures.
What carries the argument
The PHF framework, which maps Bourdieu's Theory of Practice onto user-LLM interaction sequences to produce the three levels of practices, habitus, and fields.
If this is right
- Personalization performance improves consistently across diverse tasks on the LaMP benchmark.
- The learned behavioral structures become more interpretable through the habitus and field levels.
- The approach extends to new tasks and users while remaining model-agnostic.
- A frozen LLM suffices for the implementation, avoiding the need for task-specific fine-tuning.
Where Pith is reading between the lines
- Long-term tracking of habitus evolution could support personalization that adapts as user tendencies change rather than resetting per session.
- Grouping users into fields might surface collaborative effects where similar users indirectly improve each other's models.
- The same three-level decomposition could be tested on sequential interaction logs from dialogue systems or recommendation platforms.
Load-bearing premise
Bourdieu's Theory of Practice can be directly mapped onto sequences of user-LLM interactions to produce stable, hierarchical behavioral structures that causally improve personalization performance.
What would settle it
If the PHF_Compass implementation produces no consistent gains over standard flat aggregation methods when evaluated on the LaMP benchmark tasks, or if the extracted habitus and field structures show no temporal stability, the central claim would be falsified.
Figures


read the original abstract
Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse domains, yet personalizing their outputs to individual users remains an open challenge. Existing approaches predominantly adopt a flat behavioral paradigm, aggregating user behaviors without an explicit account of how they are organized into deeper behavioral structures. In this work, we draw on Pierre Bourdieu's Theory of Practice to propose PHF (Practice-Habitus-Field), a sociologically grounded framework that reconceptualizes LLM personalization through three hierarchical levels: individual behaviors as practices, their temporal accumulation into stable dispositions as habitus, and shared regularities across similar users as fields. We instantiate PHF through $\mathrm{PHF}_{\text{Compass}}$, a lightweight and model-agnostic implementation based on a frozen LLM. Experiments on the Language Model Personalization (LaMP) benchmark demonstrate consistent improvements across diverse tasks, while further analyses validate the interpretability and extensibility of the learned behavioral structures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PHF (Practice-Habitus-Field), a hierarchical framework for LLM personalization grounded in Bourdieu's Theory of Practice. Individual user behaviors are modeled as practices, their temporal accumulation as habitus, and shared patterns across users as fields. The framework is instantiated in PHF_Compass, a lightweight implementation using a frozen LLM, and evaluated on the LaMP benchmark where it reports consistent improvements across tasks along with analyses supporting interpretability and extensibility of the learned structures.
Significance. If the hierarchical structures can be shown to drive gains beyond standard user-history prompting, the work would provide a sociologically motivated alternative to flat aggregation methods in personalization, with potential benefits for interpretability. The use of a frozen LLM and model-agnostic design is a practical strength.
major comments (2)
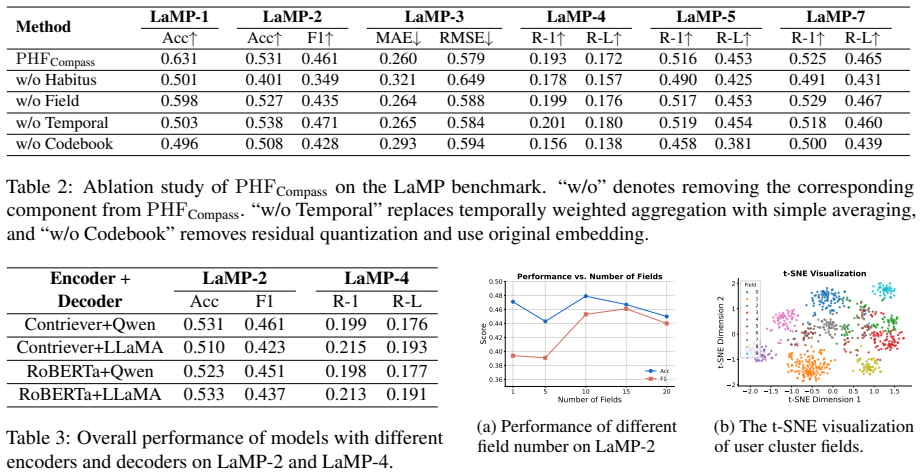
- [§4] §4 (Experiments): The reported consistent improvements on LaMP are not accompanied by an ablation that removes the habitus and field levels (e.g., a flat practice-only variant with identical LLM, history encoding, and input format). Without this isolation, the central claim that gains arise specifically from the Bourdieu-derived hierarchy rather than any structured prompting remains unsupported.
- [§3] §3 (PHF_Compass): The implementation details do not specify how the habitus level (temporal accumulation into stable dispositions) and field level (shared regularities across users) are explicitly constructed or enforced inside the frozen-LLM pipeline, as opposed to emerging implicitly from prompt formatting. This is load-bearing for validating the three-level hierarchy.
minor comments (2)
- [Abstract] The abstract refers to 'further analyses' validating interpretability; the corresponding section should explicitly state the quantitative or qualitative metrics used (e.g., human evaluation protocol or clustering coherence scores).
- [§2] Notation for the three levels (Practice, Habitus, Field) should be introduced with a clear diagram or pseudocode in §2 to aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and commit to revisions that directly strengthen the evidential basis for the hierarchical claims.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The reported consistent improvements on LaMP are not accompanied by an ablation that removes the habitus and field levels (e.g., a flat practice-only variant with identical LLM, history encoding, and input format). Without this isolation, the central claim that gains arise specifically from the Bourdieu-derived hierarchy rather than any structured prompting remains unsupported.
Authors: We agree that the current experiments do not isolate the contribution of the hierarchy. In the revised manuscript we will add a flat practice-only ablation that uses the identical frozen LLM, history encoding, and input format. Results from this comparison will be reported in §4 to test whether gains are attributable to the Bourdieu-derived levels rather than structured prompting alone. revision: yes
-
Referee: [§3] §3 (PHF_Compass): The implementation details do not specify how the habitus level (temporal accumulation into stable dispositions) and field level (shared regularities across users) are explicitly constructed or enforced inside the frozen-LLM pipeline, as opposed to emerging implicitly from prompt formatting. This is load-bearing for validating the three-level hierarchy.
Authors: We accept that §3 requires greater explicitness. The revised version will detail the explicit mechanisms: habitus is formed by a defined temporal aggregation operator over practice representations, and fields are instantiated via similarity-based clustering of habitus vectors whose centroids are injected as additional prompt context. Algorithmic pseudocode and input-construction examples will be added to demonstrate explicit enforcement within the frozen-LLM pipeline. revision: yes
Circularity Check
No significant circularity; framework is externally grounded
full rationale
The paper's core move is to import Bourdieu's Theory of Practice (an external sociological source) and map it onto user-LLM interaction sequences to define the three-level PHF hierarchy. This mapping is presented as a modeling choice rather than a derivation from prior equations or self-citations. PHF_Compass is described as a lightweight implementation on a frozen LLM, with performance evaluated on the independent LaMP benchmark. No equations, fitted parameters renamed as predictions, self-citation load-bearing steps, or uniqueness theorems from the same authors appear in the provided text. The central claim therefore rests on experimental outcomes and the external theory rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bourdieu's Theory of Practice applies to sequences of user interactions with LLMs and yields useful hierarchical behavioral structures
invented entities (1)
-
PHF_Compass
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2511.13593 , year=
O-Mem: Omni Memory System for Personalized, Long Horizon, Self-Evolving Agents , author=. arXiv preprint arXiv:2511.13593 , year=
-
[2]
SpeechMedAssist: Efficiently and Effectively Adapting Speech Language Models for Medical Consultation , author=. arXiv preprint arXiv:2601.04638 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
2013 , publisher=
Principles of topological psychology , author=. 2013 , publisher=
2013
-
[4]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Retrieval augmented generation with collaborative filtering for personalized text generation , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[5]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Proper: A progressive learning framework for personalized large language models with group-level adaptation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
CCF International Conference on Natural Language Processing and Chinese Computing , pages=
FinTeam: A Multi-agent Collaborative Intelligence System for Comprehensive Financial Scenarios , author=. CCF International Conference on Natural Language Processing and Chinese Computing , pages=. 2025 , organization=
2025
-
[7]
arXiv preprint arXiv:2507.04037 , year=
Ready Jurist One: Benchmarking Language Agents for Legal Intelligence in Dynamic Environments , author=. arXiv preprint arXiv:2507.04037 , year=
-
[8]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension , author=. arXiv preprint arXiv:1705.03551 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Electronics , volume=
A survey of recommendation systems: recommendation models, techniques, and application fields , author=. Electronics , volume=. 2022 , publisher=
2022
-
[10]
Available at SSRN 5453594 , year=
TiLLM-Rec: Temporal-Interval-Aware Large Language Model for Sequential Recommendation under Irregular User Interactions , author=. Available at SSRN 5453594 , year=
-
[11]
Data Science and Engineering , volume=
Spatio-temporal representation learning with social tie for personalized poi recommendation , author=. Data Science and Engineering , volume=. 2022 , publisher=
2022
-
[12]
2024 IEEE 40th International Conference on Data Engineering (ICDE) , pages=
Adapting large language models by integrating collaborative semantics for recommendation , author=. 2024 IEEE 40th International Conference on Data Engineering (ICDE) , pages=. 2024 , organization=
2024
-
[13]
Advances in Neural Information Processing Systems , volume=
Recommender systems with generative retrieval , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Ieee Access , volume=
A survey of recommender systems based on deep learning , author=. Ieee Access , volume=. 2018 , publisher=
2018
-
[15]
arXiv preprint arXiv:2510.12563 , year=
HardcoreLogic: Challenging Large Reasoning Models with Long-tail Logic Puzzle Games , author=. arXiv preprint arXiv:2510.12563 , year=
-
[16]
arXiv preprint arXiv:2509.25106 , year=
Towards personalized deep research: Benchmarks and evaluations , author=. arXiv preprint arXiv:2509.25106 , year=
-
[17]
arXiv preprint arXiv:2412.03563 , year=
From Individual to Society: A Survey on Social Simulation Driven by Large Language Model-based Agents , author=. arXiv preprint arXiv:2412.03563 , year=
-
[18]
Frontiers of Computer Science , volume=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[19]
Science China Information Sciences , volume=
The rise and potential of large language model based agents: A survey , author=. Science China Information Sciences , volume=. 2025 , publisher=
2025
-
[20]
arXiv preprint arXiv:2406.01171 , year=
Two tales of persona in llms: A survey of role-playing and personalization , author=. arXiv preprint arXiv:2406.01171 , year=
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Simulation-free hierarchical latent policy planning for proactive dialogues , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[22]
arXiv preprint arXiv:2311.00262 , year=
Plug-and-play policy planner for large language model powered dialogue agents , author=. arXiv preprint arXiv:2311.00262 , year=
-
[23]
Companion Proceedings of the ACM on Web Conference 2025 , pages=
User-llm: Efficient llm contextualization with user embeddings , author=. Companion Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[24]
arXiv preprint arXiv:2408.00960 , year=
PERSOMA: PERsonalized SOft ProMpt Adapter Architecture for Personalized Language Prompting , author=. arXiv preprint arXiv:2408.00960 , year=
-
[25]
Agent hospital: A simulacrum of hospital with evolvable medical agents , author=. arXiv preprint arXiv:2405.02957 , year=
-
[26]
2025 , url=
Sicheng Yang and Zhaohu Xing and Lei Zhu , booktitle=. 2025 , url=
2025
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Regularized vector quantization for tokenized image synthesis , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[28]
arXiv preprint arXiv:2511.17467 , year=
PersonaAgent with GraphRAG: Community-Aware Knowledge Graphs for Personalized LLM , author=. arXiv preprint arXiv:2511.17467 , year=
-
[29]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author=. arXiv preprint arXiv:2101.00190 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
arXiv preprint arXiv:2411.13902 , year=
Piors: Personalized intelligent outpatient reception based on large language model with multi-agents medical scenario simulation , author=. arXiv preprint arXiv:2411.13902 , year=
-
[31]
arXiv preprint arXiv:2408.11779 , year=
Personality alignment of large language models , author=. arXiv preprint arXiv:2408.11779 , year=
-
[32]
arXiv preprint arXiv:2408.10075 , year=
Personalizing reinforcement learning from human feedback with variational preference learning , author=. arXiv preprint arXiv:2408.10075 , year=
-
[33]
arXiv preprint arXiv:2504.14439 , year=
LoRe: Personalizing LLMs via Low-Rank Reward Modeling , author=. arXiv preprint arXiv:2504.14439 , year=
-
[34]
Advances in Neural Information Processing Systems , volume=
Lima: Less is more for alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
arXiv preprint arXiv:2402.05133 , year=
Personalized language modeling from personalized human feedback , author=. arXiv preprint arXiv:2402.05133 , year=
-
[36]
arXiv preprint arXiv:2304.11406 , year=
Lamp: When large language models meet personalization , author=. arXiv preprint arXiv:2304.11406 , year=
-
[37]
arXiv preprint arXiv:2404.18231 , year=
From persona to personalization: A survey on role-playing language agents , author=. arXiv preprint arXiv:2404.18231 , year=
-
[38]
arXiv preprint arXiv:2503.02614 , year=
Personalized generation in large model era: A survey , author=. arXiv preprint arXiv:2503.02614 , year=
-
[39]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[40]
Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension , author=. arXiv preprint arXiv:1910.13461 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[41]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[42]
arXiv preprint arXiv:2401.04858 , year=
User embedding model for personalized language prompting , author=. arXiv preprint arXiv:2401.04858 , year=
-
[43]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[44]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[45]
IEEE Transactions on Knowledge and Data Engineering , year=
How to Bridge the Gap between Modalities: Survey on Multimodal Large Language Model , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[46]
Advances in neural information processing systems , volume=
Neural discrete representation learning , author=. Advances in neural information processing systems , volume=
-
[47]
European Conference on Computer Vision , pages=
Unicode: Learning a unified codebook for multimodal large language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[48]
arXiv preprint arXiv:2404.03565 , year=
Personalized llm response generation with parameterized memory injection , author=. arXiv preprint arXiv:2404.03565 , year=
-
[49]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[50]
arXiv preprint arXiv:2407.02345 , year=
Morpheus: Modeling role from personalized dialogue history by exploring and utilizing latent space , author=. arXiv preprint arXiv:2407.02345 , year=
-
[51]
First Conference on Language Modeling , year=
Factual and Tailored Recommendation Endorsements using Language Models and Reinforcement Learning , author=. First Conference on Language Modeling , year=
-
[52]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[53]
arXiv preprint arXiv:2503.15463 , year=
From 1,000,000 users to every user: Scaling up personalized preference for user-level alignment , author=. arXiv preprint arXiv:2503.15463 , year=
-
[54]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[55]
Qwen2 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
international semantic web conference , pages=
Dbpedia: A nucleus for a web of open data , author=. international semantic web conference , pages=. 2007 , organization=
2007
-
[57]
Kim, Byeongchang and Kim, Hyunwoo and Kim, Gunhee , title = "
-
[58]
PersonaFeedback: A Large-scale Human-annotated Benchmark For Personalization , author=. arXiv preprint arXiv:2506.12915 , year=
-
[59]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation , author=. arXiv preprint arXiv:2410.13848 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Democratizing Large Language Models via Personalized Parameter-Efficient Fine-tuning
Tan, Zhaoxuan and Zeng, Qingkai and Tian, Yijun and Liu, Zheyuan and Yin, Bing and Jiang, Meng. Democratizing Large Language Models via Personalized Parameter-Efficient Fine-tuning. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024
2024
-
[62]
arXiv preprint arXiv:2407.19412 , year=
Identity-driven hierarchical role-playing agents , author=. arXiv preprint arXiv:2407.19412 , year=
-
[63]
arXiv preprint arXiv:2210.01240 , year=
Language models are greedy reasoners: A systematic formal analysis of chain-of-thought , author=. arXiv preprint arXiv:2210.01240 , year=
-
[64]
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
Min, Sewon and Lyu, Xinxi and Holtzman, Ari and Artetxe, Mikel and Lewis, Mike and Hajishirzi, Hannaneh and Zettlemoyer, Luke. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022
2022
-
[65]
and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 2024
2024
-
[66]
arXiv preprint arXiv:2402.16333 , year=
Unveiling the truth and facilitating change: Towards agent-based large-scale social movement simulation , author=. arXiv preprint arXiv:2402.16333 , year=
-
[67]
2024 , eprint=
OASIS: Open Agent Social Interaction Simulations with One Million Agents , author=. 2024 , eprint=
2024
-
[68]
arXiv preprint arXiv:2504.10157 , year=
Socioverse: A world model for social simulation powered by llm agents and a pool of 10 million real-world users , author=. arXiv preprint arXiv:2504.10157 , year=
-
[69]
Proceedings of the 47th international ACM SIGIR conference on research and development in Information Retrieval , pages=
On generative agents in recommendation , author=. Proceedings of the 47th international ACM SIGIR conference on research and development in Information Retrieval , pages=
-
[70]
Faithful Persona-based Conversational Dataset Generation with Large Language Models
Jandaghi, Pegah and Sheng, Xianghai and Bai, Xinyi and Pujara, Jay and Sidahmed, Hakim. Faithful Persona-based Conversational Dataset Generation with Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024
2024
-
[71]
arXiv preprint arXiv:2402.09660 , year=
User modeling and user profiling: A comprehensive survey , author=. arXiv preprint arXiv:2402.09660 , year=
-
[72]
arXiv preprint arXiv:2302.11087 , year=
A survey on user behavior modeling in recommender systems , author=. arXiv preprint arXiv:2302.11087 , year=
-
[73]
AI That Keeps Up: NeurIPS 2025 Workshop on Continual and Compatible Foundation Model Updates , year=
Embedding-to-Prefix: Continual Personalization with Large Language Models , author=. AI That Keeps Up: NeurIPS 2025 Workshop on Continual and Compatible Foundation Model Updates , year=
2025
-
[74]
LLM s + Persona-Plug = Personalized LLM s
Liu, Jiongnan and Zhu, Yutao and Wang, Shuting and Wei, Xiaochi and Min, Erxue and Lu, Yu and Wang, Shuaiqiang and Yin, Dawei and Dou, Zhicheng. LLM s + Persona-Plug = Personalized LLM s. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
2025
-
[75]
arXiv preprint arXiv:2405.20985 , year=
Deco: Decoupling token compression from semantic abstraction in multimodal large language models , author=. arXiv preprint arXiv:2405.20985 , year=
-
[76]
Proceedings of the 26th annual international ACM SIGIR conference on Research and development in informaion retrieval , pages=
Building and applying a concept hierarchy representation of a user profile , author=. Proceedings of the 26th annual international ACM SIGIR conference on Research and development in informaion retrieval , pages=
-
[77]
Proceedings of the 24th international conference on world wide web , pages=
A multi-view deep learning approach for cross domain user modeling in recommendation systems , author=. Proceedings of the 24th international conference on world wide web , pages=
-
[78]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Neural news recommendation with long-and short-term user representations , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[79]
Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining , pages=
Variational user modeling with slow and fast features , author=. Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining , pages=
-
[80]
arXiv preprint arXiv:2304.03516 , year=
Generative recommendation: Towards next-generation recommender paradigm , author=. arXiv preprint arXiv:2304.03516 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.