SIRI: Self-Internalizing Reinforcement Learning with Intrinsic Skills for LLM Agent Training
Pith reviewed 2026-06-28 14:30 UTC · model grok-4.3
The pith
SIRI lets LLM agents discover and internalize useful skills from their own successful trajectories without external generators or retrieval at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
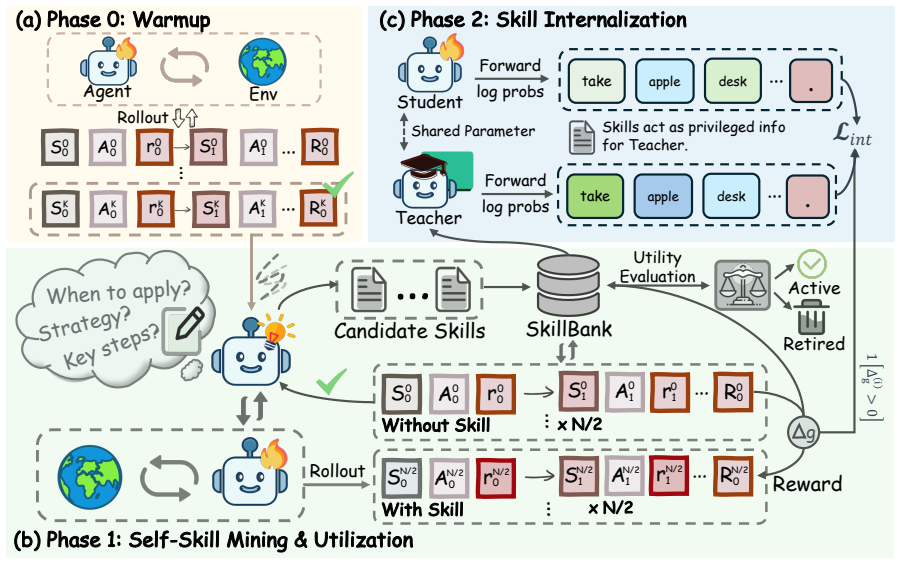
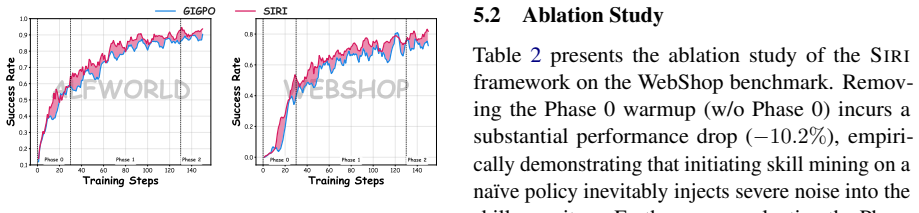
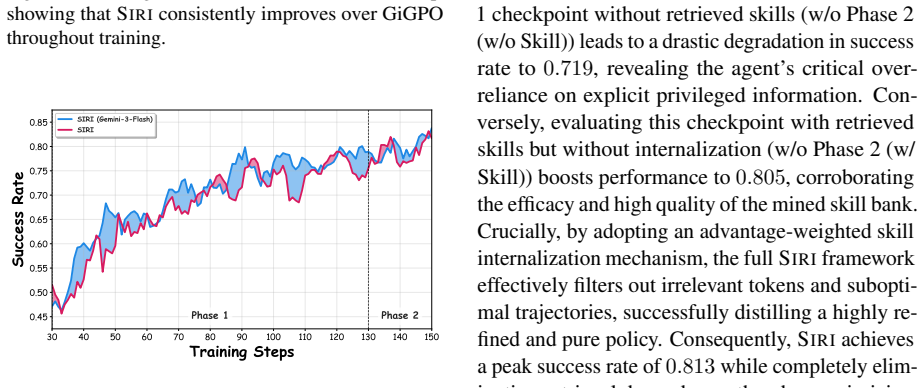
SIRI is a three-phase process: policy warmup with GiGPO to collect skill-free trajectories, self-skill mining via summarization and paired validation, and distillation of beneficial skills into the base policy. This internalization leads to improved task success rates compared to baselines without requiring skill banks at runtime.
What carries the argument
Self-skill mining that validates summarized skills through paired skill-augmented and skill-free rollouts, then selectively distills beneficial action tokens using utility and advantage metrics.
If this is right
- The policy improves success rates on long-horizon tasks such as ALFWorld and WebShop.
- Inference runs with the original prompt only, leaving context length and latency unchanged.
- Self-mining produces skills whose performance matches distillation performed by a closed-source large model.
- The method outperforms prompt-based, standard RL, and memory-augmented baselines on the tested environments.
Where Pith is reading between the lines
- The validation step could be repeated iteratively so the agent continues to bootstrap new skills from its own improving trajectories.
- Because skill selection relies only on internal rollouts, the approach may transfer to environments where external skill libraries are unavailable or costly.
- If the paired-rollout test proves stable across domains, it offers a route to reduce reliance on ever-larger external models for agent supervision.
Load-bearing premise
The paired skill-augmented versus skill-free rollout comparison reliably identifies beneficial skills without selection bias or reward hacking.
What would settle it
Running the full SIRI pipeline but replacing the validated skills with randomly chosen summaries from the same trajectories would yield no performance gain or even degradation on the benchmark tasks.
Figures

read the original abstract
Long-horizon LLM agents can benefit from reusable skills, yet existing skill-based methods often rely on external skill generators during training or persistent skill retrieval at inference, increasing engineering complexity, context length, and deployment latency. We propose Self-Internalizing Reinforcement learning with Intrinsic skills (SIRI), a three-phase framework that enables agents to discover, validate, and internalize skills without external skill generators or inference-time skill banks. SIRI first warms up the policy with GiGPO to acquire basic interaction ability and collect successful skill-free trajectories. It then performs self-skill mining, where the current policy summarizes compact skills from its own successful plain rollouts and validates them through paired skill-augmented and skill-free rollouts. Finally, SIRI distills only beneficial skill-guided action tokens into the plain policy using trajectory-level utility and action-level advantage. At inference, the agent runs with the original prompt only. On ALFWorld and WebShop with Qwen2.5-7B-Instruct, SIRI improves GiGPO from 0.908 to 0.930 on ALFWorld and from 0.728 to 0.813 on WebShop, outperforming prompt-based, RL-based, and memory-augmented baselines. Further analysis shows that our self-mining strategy can achieve performance comparable to distillation with closed-source large model. Our code is available at https://github.com/kirito618/SIRI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SIRI, a three-phase framework for LLM agents that warms up a policy with GiGPO on successful trajectories, performs self-skill mining by summarizing and validating skills via paired skill-augmented vs. skill-free rollouts, then distills only beneficial skills into the base policy via trajectory utility and action advantage. At inference the agent uses only the original prompt. On ALFWorld and WebShop with Qwen2.5-7B-Instruct it reports gains over GiGPO (0.908→0.930 and 0.728→0.813) and outperforms prompt, RL, and memory baselines; self-mining is claimed comparable to closed-source distillation.
Significance. If the reported gains are robust to rollout variance and selection effects, the method would demonstrate a practical route to internalizing reusable skills without external generators or inference-time retrieval, lowering deployment cost while preserving or improving performance. The self-mining result being comparable to closed-source models is a notable strength if substantiated.
major comments (2)
- [Abstract / self-skill mining description] The skill-validation step (self-skill mining phase) is load-bearing for the central claim that gains come from internalized beneficial skills rather than continued RL or cherry-picked trajectories. The manuscript supplies no details on the number of paired rollouts per candidate skill, the exact decision rule for “beneficial,” statistical testing, or correction for multiple comparisons; without these the paired comparison cannot be shown to isolate net-positive skills amid LLM rollout variance.
- [Results section (ALFWorld / WebShop tables)] Table or figure reporting the headline numbers (ALFWorld 0.930, WebShop 0.813) must include number of independent runs, standard errors or confidence intervals, and the precise validation criteria used to select which skills were distilled; the current numeric gains cannot be assessed for post-hoc bias or statistical reliability.
minor comments (1)
- The abstract states “our code is available” but does not specify the commit or exact reproduction instructions for the GiGPO baseline and the paired-rollout validation pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the self-skill mining validation and statistical reporting. We address each major comment below and will revise the manuscript to provide the requested details and clarifications.
read point-by-point responses
-
Referee: [Abstract / self-skill mining description] The skill-validation step (self-skill mining phase) is load-bearing for the central claim that gains come from internalized beneficial skills rather than continued RL or cherry-picked trajectories. The manuscript supplies no details on the number of paired rollouts per candidate skill, the exact decision rule for “beneficial,” statistical testing, or correction for multiple comparisons; without these the paired comparison cannot be shown to isolate net-positive skills amid LLM rollout variance.
Authors: We agree that the manuscript would benefit from a more explicit description of the validation protocol. In the revised manuscript we will add a dedicated paragraph in the self-skill mining subsection that states the number of paired rollouts performed per candidate skill, the precise decision rule applied to classify a skill as beneficial (trajectory utility and action advantage thresholds), and any statistical considerations used. We will also clarify that the mining phase is exploratory and therefore does not apply formal multiple-comparison corrections, while noting the potential implications for variance in LLM rollouts. These additions will allow readers to evaluate the isolation of net-positive skills more rigorously. revision: yes
-
Referee: [Results section (ALFWorld / WebShop tables)] Table or figure reporting the headline numbers (ALFWorld 0.930, WebShop 0.813) must include number of independent runs, standard errors or confidence intervals, and the precise validation criteria used to select which skills were distilled; the current numeric gains cannot be assessed for post-hoc bias or statistical reliability.
Authors: We acknowledge that the current tables lack the requested statistical context. In the revision we will augment the ALFWorld and WebShop result tables with the number of independent runs performed, standard errors or confidence intervals, and an explicit statement of the validation criteria (trajectory utility and action advantage thresholds) used to select skills for distillation. This will enable a clearer assessment of the reported gains and reduce concerns about post-hoc selection effects. revision: yes
Circularity Check
No circularity detected; derivation is self-contained
full rationale
The paper describes a three-phase empirical pipeline (GiGPO warmup to collect trajectories, self-skill mining from successful rollouts, paired rollout validation, and distillation of beneficial skills) whose performance gains on ALFWorld and WebShop are reported as measured outcomes rather than derived quantities. No equations appear that equate a prediction to its own fitted input by construction, no self-citation is invoked as a uniqueness theorem or load-bearing premise, and no ansatz or renaming reduces the central claim to prior inputs. The method remains externally falsifiable via the reported benchmark comparisons.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
UCOB: Learning to Utilize and Evolve Agentic Skills via Credit-Aware On-Policy Bidirectional Self-Distillation
UCOB improves agentic RL by using return-to-go comparisons between skill-conditioned and no-skill prompts as local teachers for bidirectional self-distillation and skill memory updates.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
arXiv preprint arXiv:2602.08234 , year=
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning , author=. arXiv preprint arXiv:2602.08234 , year=
-
[9]
arXiv preprint arXiv:2603.28716 , year=
Dynamic Dual-Granularity Skill Bank for Agentic RL , author=. arXiv preprint arXiv:2603.28716 , year=
-
[10]
arXiv preprint arXiv:2604.10674 , year=
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents , author=. arXiv preprint arXiv:2604.10674 , year=
-
[11]
arXiv preprint arXiv:2603.16060 , year=
ARISE: Agent Reasoning with Intrinsic Skill Evolution in Hierarchical Reinforcement Learning , author=. arXiv preprint arXiv:2603.16060 , year=
-
[12]
arXiv preprint arXiv:2305.16291 , year=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. arXiv preprint arXiv:2305.16291 , year=
-
[13]
Advances in Neural Information Processing Systems , year=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
ExpeL: LLM Agents Are Experiential Learners , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[15]
International Conference on Learning Representations , year=
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning , author=. International Conference on Learning Representations , year=
-
[16]
Advances in Neural Information Processing Systems , year=
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author=. Advances in Neural Information Processing Systems , year=
-
[17]
arXiv preprint arXiv:2407.18901 , year=
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents , author=. arXiv preprint arXiv:2407.18901 , year=
-
[18]
International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. International Conference on Learning Representations , year=
-
[19]
arXiv preprint arXiv:2504.20073 , year=
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning , author=. arXiv preprint arXiv:2504.20073 , year=
-
[20]
arXiv preprint arXiv:2509.21240 , year=
Tree Search for LLM Agent Reinforcement Learning , author=. arXiv preprint arXiv:2509.21240 , year=
-
[21]
arXiv preprint arXiv:2505.10978 , year=
Group-in-Group Policy Optimization for LLM Agent Training , author=. arXiv preprint arXiv:2505.10978 , year=
-
[22]
arXiv preprint arXiv:2603.08754 , year=
Hindsight Credit Assignment for Long-Horizon LLM Agents , author=. arXiv preprint arXiv:2603.08754 , year=
-
[23]
arXiv preprint arXiv:2603.03078 , year=
RAPO: Expanding Exploration for LLM Agents via Retrieval-Augmented Policy Optimization , author=. arXiv preprint arXiv:2603.03078 , year=
-
[24]
arXiv preprint arXiv:2402.14740 , year=
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs , author=. arXiv preprint arXiv:2402.14740 , year=
-
[25]
arXiv preprint arXiv:2601.03192 , year=
MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory , author=. arXiv preprint arXiv:2601.03192 , year=
-
[26]
arXiv preprint arXiv:2510.16079 , year=
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle , author=. arXiv preprint arXiv:2510.16079 , year=
-
[27]
arXiv preprint arXiv:2601.02553 , year=
SimpleMem: Efficient Lifelong Memory for LLM Agents , author=. arXiv preprint arXiv:2601.02553 , year=
-
[28]
arXiv preprint arXiv:2504.19413 , year=
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
-
[29]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[30]
arXiv preprint arXiv:2204.05862 , year=
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
-
[31]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[32]
arXiv preprint arXiv:2112.09332 , year=
Webgpt: Browser-assisted question-answering with human feedback , author=. arXiv preprint arXiv:2112.09332 , year=
-
[33]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[34]
nature , volume=
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
2015
-
[35]
Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pages=
Language understanding for text-based games using deep reinforcement learning , author=. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pages=
2015
-
[36]
Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Deep reinforcement learning with a natural language action space , author=. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[37]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Interactive fiction games: A colossal adventure , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[38]
arXiv preprint arXiv:2402.19446 , year=
Archer: Training language model agents via hierarchical multi-turn rl , author=. arXiv preprint arXiv:2402.19446 , year=
-
[39]
arXiv preprint arXiv:2408.07199 , year=
Agent q: Advanced reasoning and learning for autonomous ai agents , author=. arXiv preprint arXiv:2408.07199 , year=
-
[40]
arXiv preprint arXiv:2505.03792 , year=
Towards efficient online tuning of vlm agents via counterfactual soft reinforcement learning , author=. arXiv preprint arXiv:2505.03792 , year=
-
[41]
arXiv preprint arXiv:2502.01600 , year=
Reinforcement learning for long-horizon interactive llm agents , author=. arXiv preprint arXiv:2502.01600 , year=
-
[42]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Webagent-r1: Training web agents via end-to-end multi-turn reinforcement learning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[43]
arXiv preprint arXiv:2604.09459 , year=
From reasoning to agentic: Credit assignment in reinforcement learning for large language models , author=. arXiv preprint arXiv:2604.09459 , year=
-
[44]
arXiv preprint arXiv:2312.01072 , year=
A survey of temporal credit assignment in deep reinforcement learning , author=. arXiv preprint arXiv:2312.01072 , year=
-
[45]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[46]
arXiv preprint arXiv:1512.07679 , year=
Deep reinforcement learning in large discrete action spaces , author=. arXiv preprint arXiv:1512.07679 , year=
-
[47]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[48]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.