COMAP: Co-Evolving World Models and Agent Policies for LLM Agents
Pith reviewed 2026-06-28 14:25 UTC · model grok-4.3
The pith
Co-evolving world models and agent policies improves LLM performance without external rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
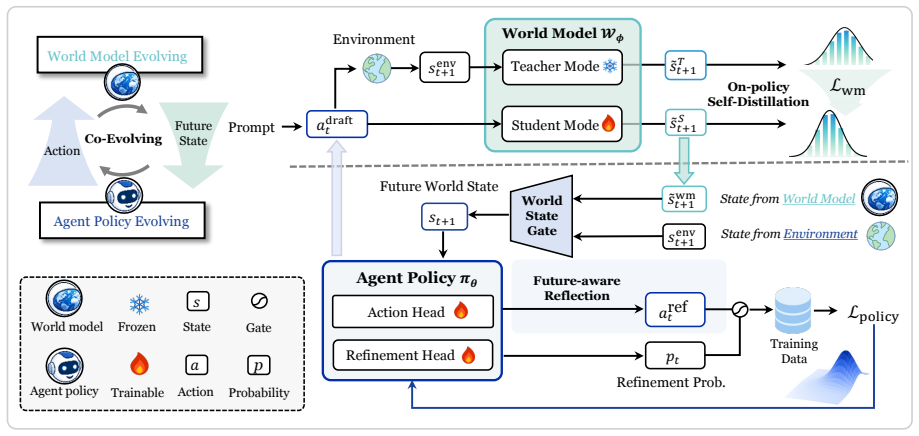
COMAP co-evolves textual world models and agent policies by letting the agent perform future-aware reflection on the world model's predicted state feedback and then using the resulting on-policy trajectories to update the world model via self-distillation, producing measurable gains in prediction accuracy and task success across multiple benchmarks.
What carries the argument
The closed-loop interaction in which the agent's reliability estimates of world-model feedback generate on-policy trajectories that are distilled back into the world model.
If this is right
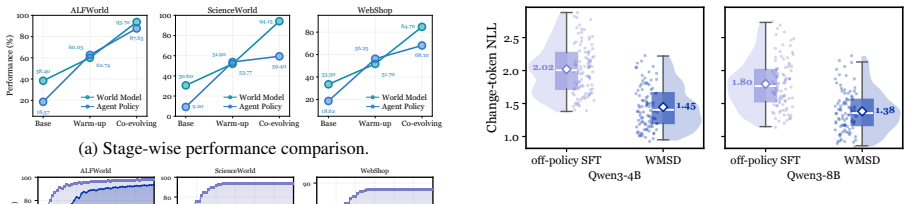
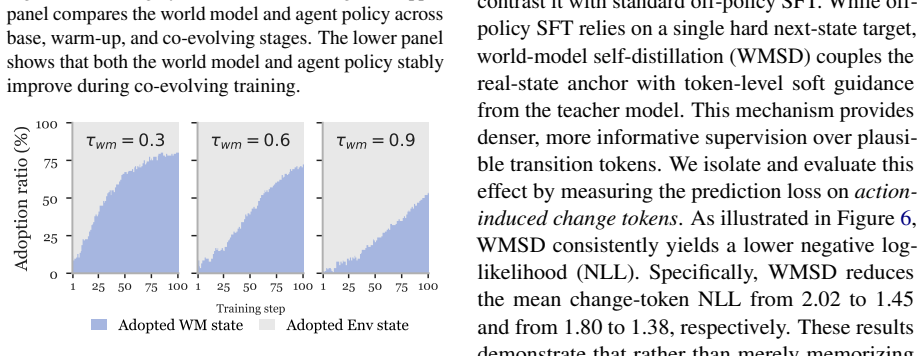
- World-model prediction accuracy increases steadily across co-evolution iterations.
- Agents produce more effective long-horizon decisions on embodied planning, web navigation, and tool-use tasks.
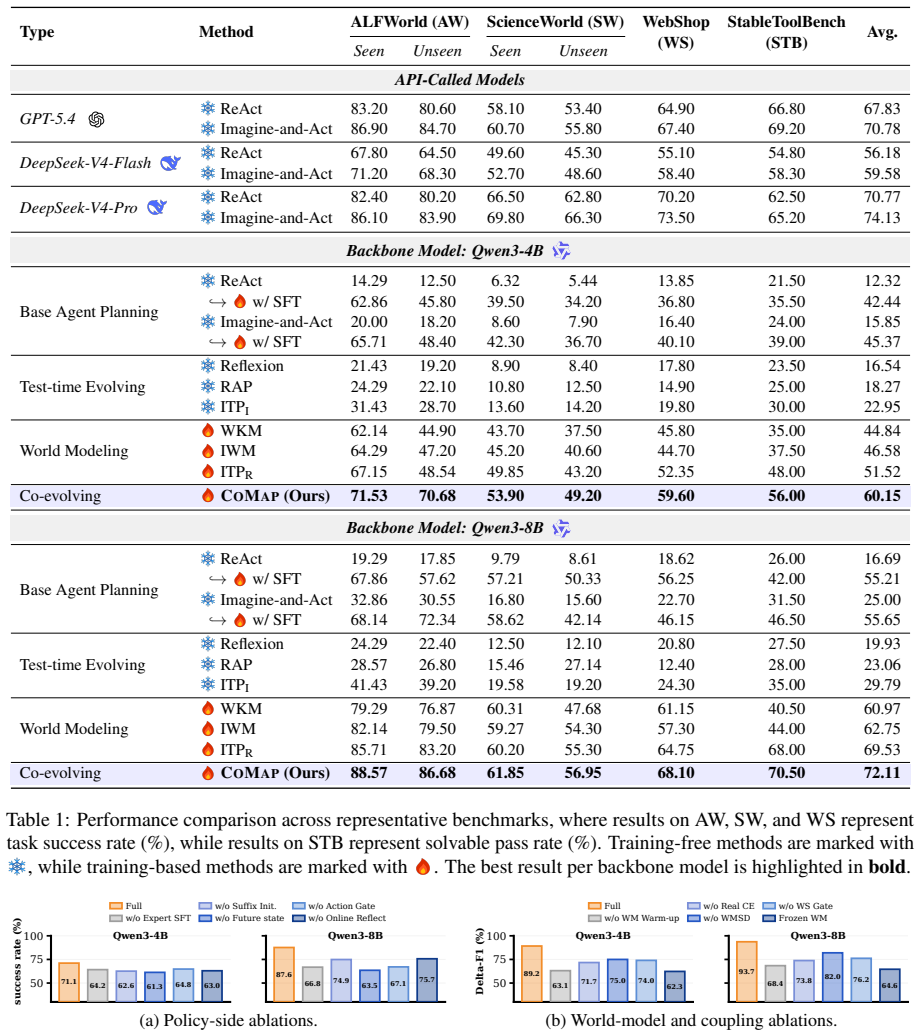
- The framework delivers consistent outperformance over fixed-world-model baselines, including a 16.75 percent relative gain with the Qwen3-4B model.
- No external reward signals or verifiers are required for the improvement cycle to operate.
Where Pith is reading between the lines
- The same loop could be tested in environments where ground-truth rewards are unavailable or expensive to obtain.
- Extending the self-distillation step to larger models might reduce reliance on human-curated data for agent training.
- The reliability-estimation component could be studied separately to see how its accuracy affects overall loop stability.
Load-bearing premise
The agent's own judgments about whether the world model's feedback is reliable are accurate enough to produce useful training data without any external verification.
What would settle it
Running multiple rounds of the co-evolution loop on one of the reported benchmarks and observing that world-model prediction accuracy does not rise while agent success rate stays flat or falls.
Figures

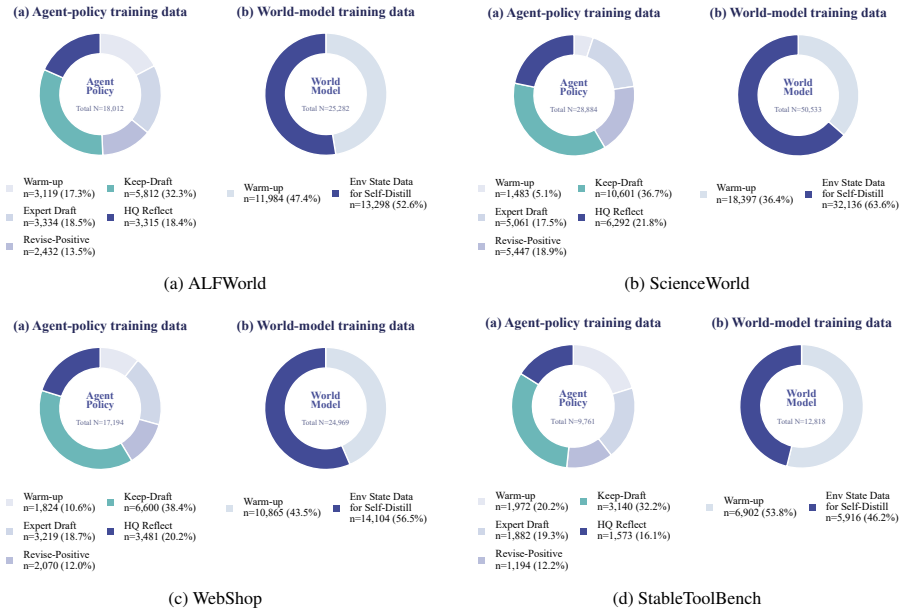
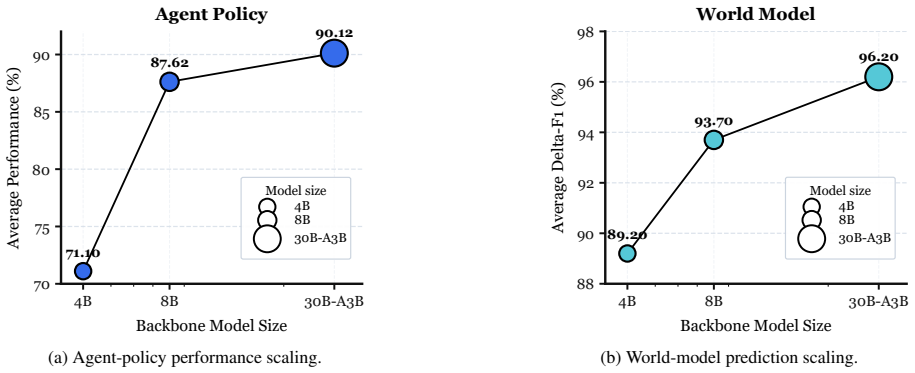

read the original abstract
Equipping language agents with world models enables them to anticipate environment dynamics and evaluate candidate actions before execution. However, existing textual world models are typically fixed after training, preventing them from adapting to the on-policy state-action distributions induced by an evolving agent. Meanwhile, agent-improvement methods often rely on external rewards or verifiers, limiting their applicability in realistic interactive environments. In this paper, we propose COMAP, a novel framework that co-evolves textual world models and agent policies through closed-loop interaction. At each decision step, the world model predicts future state feedback for candidate actions, and the agent performs future-aware reflection by estimating the reliability of this feedback and refining its action accordingly. The resulting on-policy trajectories are then used to update the world model via self-distillation, allowing it to better match the agent's evolving interaction distribution. Across embodied task planning, Web navigation, and tool-use benchmarks, COMAP consistently outperforms competitive baselines, e.g., +16.75% relative improvement with Qwen3-4B. Further analyses show that the co-evolutionary loop improves the world model's prediction accuracy over time and leads to more effective long-horizon decision-making. Our code is available at: https://github.com/loyiv/CoMAP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces COMAP, a framework for co-evolving textual world models (WMs) and LLM agent policies in closed-loop interaction without external rewards or verifiers. At each step the WM predicts future state feedback for candidate actions; the agent performs future-aware reflection by estimating the reliability of that feedback and refining its action; the resulting on-policy trajectories are then used to update the WM via self-distillation so that the WM better matches the agent's evolving distribution. Experiments on embodied task planning, web navigation, and tool-use benchmarks report consistent gains (e.g., +16.75% relative with Qwen3-4B) and show improving WM prediction accuracy and long-horizon decision-making over iterations.
Significance. If the co-evolutionary loop can be shown to produce calibrated reliability estimates and genuine on-policy improvement without external signals, the result would be significant for autonomous agent training in realistic interactive environments where fixed WMs and external verifiers are impractical.
major comments (2)
- [Abstract / method] Abstract and method description: the central claim that the closed loop improves both WM accuracy and policy over iterations rests on the agent's internal reliability estimates being sufficiently calibrated to yield useful self-distillation targets. No analysis, calibration plots, or external verification of these estimates is provided, leaving open the possibility that early errors are amplified rather than corrected.
- [Abstract] Abstract: the reported gains (e.g., +16.75% relative) are attributed to the co-evolution loop, yet the manuscript supplies no ablations that isolate the contribution of the reliability-estimation + self-distillation step from other factors such as additional trajectory collection or prompt changes.
minor comments (2)
- [Abstract] The abstract states that code is available at a GitHub link, but no details on reproducibility (hyperparameters, exact prompts, or evaluation protocols) are given in the text.
- [Method] Notation for the reliability estimation step is introduced without a formal definition or pseudocode, making it difficult to assess how the estimate is computed from the WM output.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript's claims regarding calibration and component contributions.
read point-by-point responses
-
Referee: [Abstract / method] Abstract and method description: the central claim that the closed loop improves both WM accuracy and policy over iterations rests on the agent's internal reliability estimates being sufficiently calibrated to yield useful self-distillation targets. No analysis, calibration plots, or external verification of these estimates is provided, leaving open the possibility that early errors are amplified rather than corrected.
Authors: We agree that the manuscript would benefit from explicit analysis of the reliability estimates' calibration. While the current version reports that the co-evolutionary loop improves world model prediction accuracy over iterations (providing indirect support that self-distillation targets are useful), we do not include calibration plots or external verification. In the revision we will add these analyses, including plots of predicted vs. observed reliability and comparisons against external signals where available, to rule out error amplification. revision: yes
-
Referee: [Abstract] Abstract: the reported gains (e.g., +16.75% relative) are attributed to the co-evolution loop, yet the manuscript supplies no ablations that isolate the contribution of the reliability-estimation + self-distillation step from other factors such as additional trajectory collection or prompt changes.
Authors: We concur that dedicated ablations are needed to isolate the reliability-estimation and self-distillation components. The current experiments demonstrate overall gains and improving WM accuracy, but do not control for trajectory volume or prompt variations. We will add these ablations in the revised manuscript, comparing the full framework against controlled variants that disable the reliability step or self-distillation while matching other factors. revision: yes
Circularity Check
No circularity: standard iterative self-training loop with external benchmark validation
full rationale
The COMAP framework describes an iterative process of world-model prediction, agent reliability estimation for action refinement, trajectory collection, and self-distillation updates. This is a procedural training loop, not a derivation or prediction that reduces to fitted inputs by construction. No equations, uniqueness theorems, ansatzes, or self-citations are invoked in the abstract or description that would create self-definitional or load-bearing circularity. Performance gains are reported as empirical results on external benchmarks (embodied planning, web navigation, tool-use), which are independently falsifiable. The central claim therefore remains self-contained against external evaluation rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can produce sufficiently accurate estimates of the reliability of world-model feedback to generate useful training trajectories.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Language models meet world models: Embodied experiences enhance language models , author=. Advances in neural information processing systems , volume=
-
[2]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Advances in Neural Information Processing Systems , editor =. 2022 , url =
2022
-
[3]
Mohit Shridhar and Jesse Thomason and Daniel Gordon and Yonatan Bisk and Winson Han and Roozbeh Mottaghi and Luke Zettlemoyer and Dieter Fox , bibsource =. 2020. doi:10.1109/CVPR42600.2020.01075 , pages =
-
[4]
S cience W orld: Is your Agent Smarter than a 5th Grader?
Wang, Ruoyao and Jansen, Peter and C \^o t \'e , Marc-Alexandre and Ammanabrolu, Prithviraj. S cience W orld: Is your Agent Smarter than a 5th Grader?. EMNLP. 2022
2022
-
[5]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[6]
arXiv preprint arXiv:2412.15115 , year =
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
-
[7]
arXiv preprint arXiv:2407.10671 , year =
Qwen2 Technical Report , author =. arXiv preprint arXiv:2407.10671 , year =
-
[8]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[9]
2023 , html =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , html =
2023
-
[10]
ST e C a: Step-level Trajectory Calibration for LLM Agent Learning
Wang, Hanlin and Wang, Jian and Leong, Chak Tou and Li, Wenjie. ST e C a: Step-level Trajectory Calibration for LLM Agent Learning. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.604
-
[11]
Tianzhe Chu and Yuexiang Zhai and Jihan Yang and Shengbang Tong and Saining Xie and Dale Schuurmans and Quoc V Le and Sergey Levine and Yi Ma , booktitle=
-
[12]
Trial and Error: Exploration-Based Trajectory Optimization of LLM Agents
Song, Yifan and Yin, Da and Yue, Xiang and Huang, Jie and Li, Sujian and Lin, Bill Yuchen. Trial and Error: Exploration-Based Trajectory Optimization of LLM Agents. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.409
-
[13]
Watch Every Step! LLM Agent Learning via Iterative Step-level Process Refinement
Xiong, Weimin and Song, Yifan and Zhao, Xiutian and Wu, Wenhao and Wang, Xun and Wang, Ke and Li, Cheng and Peng, Wei and Li, Sujian. Watch Every Step! LLM Agent Learning via Iterative Step-level Process Refinement. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.93
-
[14]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Virtualhome: Simulating household activities via programs , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[15]
Advances in Neural Information Processing Systems , volume=
Camel: Communicative agents for" mind" exploration of large language model society , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Transactions on Machine Learning Research , year=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Transactions on Machine Learning Research , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Advances in Neural Information Processing Systems , volume=
On the planning abilities of large language models-a critical investigation , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
arXiv preprint arXiv:2301.04104 , year=
Mastering diverse domains through world models , author=. arXiv preprint arXiv:2301.04104 , year=
-
[20]
World Modeling Makes a Better Planner: Dual Preference Optimization for Embodied Task Planning
Wang, Siyin and Fei, Zhaoye and Cheng, Qinyuan and Zhang, Shiduo and Cai, Panpan and Fu, Jinlan and Qiu, Xipeng. World Modeling Makes a Better Planner: Dual Preference Optimization for Embodied Task Planning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1044
-
[21]
Reasoning with language model is planning with world model
Hao, Shibo and Gu, Yi and Ma, Haodi and Hong, Joshua and Wang, Zhen and Wang, Daisy and Hu, Zhiting. Reasoning with Language Model is Planning with World Model. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.507
-
[22]
2, 2022-06-27 , author=
A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27 , author=. Open Review , volume=
2022
-
[23]
arXiv preprint arXiv:2506.22355 , year=
Embodied AI Agents: Modeling the World , author=. arXiv preprint arXiv:2506.22355 , year=
-
[24]
W eb E volver: Enhancing Web Agent Self-Improvement with Co-evolving World Model
Fang, Tianqing and Zhang, Hongming and Zhang, Zhisong and Ma, Kaixin and Yu, Wenhao and Mi, Haitao and Yu, Dong. W eb E volver: Enhancing Web Agent Self-Improvement with Co-evolving World Model. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.454
-
[25]
arXiv preprint arXiv:2510.08558 , year=
Agent learning via early experience , author=. arXiv preprint arXiv:2510.08558 , year=
-
[26]
Advances in Neural Information Processing Systems , volume=
Agent planning with world knowledge model , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
E ^2 CL : Exploration-based Error Correction Learning for Embodied Agents
Wang, Hanlin and Leong, Chak Tou and Wang, Jian and Li, Wenjie. E ^2 CL : Exploration-based Error Correction Learning for Embodied Agents. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.448
-
[28]
Advances in Neural Information Processing Systems , volume=
Leveraging pre-trained large language models to construct and utilize world models for model-based task planning , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
VAGEN: Reinforcing World Model Reasoning for Multi-Turn VLM Agents , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[30]
arXiv preprint arXiv:2510.15047 , year=
Internalizing World Models via Self-Play Finetuning for Agentic RL , author=. arXiv preprint arXiv:2510.15047 , year=
-
[31]
arXiv preprint arXiv:2510.18135 , year=
World-in-world: World models in a closed-loop world , author=. arXiv preprint arXiv:2510.18135 , year=
-
[32]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
DMWM: Dual-Mind World Model with Long-Term Imagination , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[33]
Journal of Mathematical Analysis and Applications , volume=
Optimal control of Markov processes with incomplete state information I , author=. Journal of Mathematical Analysis and Applications , volume=. 1965 , publisher=
1965
-
[34]
arXiv preprint arXiv:2501.11425 , year=
Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training , author=. arXiv preprint arXiv:2501.11425 , year=
-
[35]
The Thirteenth International Conference on Learning Representations (ICLR) , year=
AgentRefine: Enhancing Agent Generalization through Refinement Tuning , author=. The Thirteenth International Conference on Learning Representations (ICLR) , year=
-
[36]
arXiv preprint arXiv:2512.02556 , year =
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author =. arXiv preprint arXiv:2512.02556 , year =
-
[37]
arXiv preprint arXiv:2512.18832 , year=
From Word to World: Can Large Language Models be Implicit Text-based World Models? , author=. arXiv preprint arXiv:2512.18832 , year=
-
[38]
Advances in Neural Information Processing Systems , volume =
Shunyu Yao and Howard Chen and John Yang and Karthik Narasimhan , title =. Advances in Neural Information Processing Systems , volume =
-
[39]
arXiv preprint arXiv:2505.10978 , year=
Group-in-group policy optimization for llm agent training , author=. arXiv preprint arXiv:2505.10978 , year=
-
[40]
arXiv preprint arXiv:2505.20732 , year=
SPA-RL: Reinforcing LLM Agents via Stepwise Progress Attribution , author=. arXiv preprint arXiv:2505.20732 , year=
-
[41]
International conference on machine learning , pages=
Asynchronous methods for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[42]
arXiv preprint arXiv:2310.05915 , year=
Fireact: Toward language agent fine-tuning , author=. arXiv preprint arXiv:2310.05915 , year=
-
[43]
Guo, Zhicheng and Cheng, Sijie and Wang, Hao and Liang, Shihao and Qin, Yujia and Li, Peng and Liu, Zhiyuan and Sun, Maosong and Liu, Yang. S table T ool B ench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.664
-
[44]
Griffiths and Yuan Cao and Karthik Narasimhan , title =
Shunyu Yao and Dian Yu and Jeffrey Zhao and Izhak Shafran and Thomas L. Griffiths and Yuan Cao and Karthik Narasimhan , title =. Advances in Neural Information Processing Systems , editor =
-
[45]
Bandit Based Monte-Carlo Planning
Levente Kocsis and Csaba Szepesv. Bandit Based Monte-Carlo Planning , booktitle =. doi:10.1007/11871842_29 , year =
-
[46]
arXiv preprint arXiv:2601.08955 , year =
Imagine-then-Plan: Agent Learning from Adaptive Lookahead with World Models , author =. arXiv preprint arXiv:2601.08955 , year =
-
[47]
2025 , eprint=
From Word to World: Can Large Language Models be Implicit Text-based World Models? , author=. 2025 , eprint=
2025
-
[48]
Frontiers of Computer Science , volume=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[49]
Advances in Neural Information Processing Systems , volume=
Embodied agent interface: Benchmarking llms for embodied decision making , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
International Conference on Learning Representations , volume=
Web agents with world models: Learning and leveraging environment dynamics in web navigation , author=. International Conference on Learning Representations , volume=
-
[51]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Enhancing agent learning through world dynamics modeling , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[52]
2026 , month = mar, day =
Introducing GPT-5.4 , author =. 2026 , month = mar, day =
2026
-
[53]
arXiv preprint arXiv:2604.00626 , year=
A Survey of On-Policy Distillation for Large Language Models , author=. arXiv preprint arXiv:2604.00626 , year=
-
[54]
arXiv preprint arXiv:2602.10885 , year =
Reinforcing Chain-of-Thought Reasoning with Self-Evolving Rubrics , author =. arXiv preprint arXiv:2602.10885 , year =
-
[55]
2026 , howpublished =
DeepSeek-V4 Preview Release , author =. 2026 , howpublished =
2026
-
[56]
Majumder, Bodhisattwa Prasad and Mishra, Bhavana Dalvi and Jansen, Peter and Tafjord, Oyvind and Tandon, Niket and Zhang, Li and Callison-Burch, Chris and Clark, Peter , year =. 2310.10134 , archivePrefix =
-
[57]
2024 , eprint =
Investigate-Consolidate-Exploit: A General Strategy for Inter-Task Agent Self-Evolution , author =. 2024 , eprint =
2024
-
[58]
Xi, Zhiheng and Ding, Yiwen and Chen, Wenxiang and Hong, Boyang and Guo, Honglin and Wang, Junzhe and Yang, Dingwen and Liao, Chenyang and Guo, Xin and He, Wei and Gao, Songyang and Chen, Lu and Zheng, Rui and Zou, Yicheng and Gui, Tao and Zhang, Qi and Qiu, Xipeng and Huang, Xuanjing and Wu, Zuxuan and Jiang, Yu-Gang , year =. 2406.04151 , archivePrefix =
-
[59]
Lu, Jianqiao and Zhong, Wanjun and Huang, Wenyong and Wang, Yufei and Zhu, Qi and Mi, Fei and Wang, Baojun and Wang, Weichao and Zeng, Xingshan and Shang, Lifeng and Jiang, Xin and Liu, Qun , year =. 2310.00533 , archivePrefix =
-
[60]
2024 , eprint =
Symbolic Learning Enables Self-Evolving Agents , author =. 2024 , eprint =
2024
-
[61]
2024 , eprint =
Automated Design of Agentic Systems , author =. 2024 , eprint =
2024
-
[62]
2025 , url =
Yuan, Siyu and Song, Kaitao and Chen, Jiangjie and Tan, Xu and Li, Dongsheng and Yang, Deqing , booktitle =. 2025 , url =
2025
-
[63]
Wu, Xiyang and Li, Zongxia and Shi, Guangyao and Duffy, Alexander and Marques, Tyler and Olson, Matthew Lyle and Zhou, Tianyi and Manocha, Dinesh , year =. Co-Evolving. 2604.20987 , archivePrefix =
-
[64]
Xu, Wujiang and Han, Jiaojiao and Guo, Minghao and Mei, Kai and Zhu, Xi and Zhang, Han and Metaxas, Dimitris N. , year =. 2604.21725 , archivePrefix =
-
[65]
2021 , url =
Mohit Shridhar and Xingdi Yuan and Marc-Alexandre C\^ot\'e and Yonatan Bisk and Adam Trischler and Matthew Hausknecht , booktitle =. 2021 , url =
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.