WAXAL-NET: Finetuned Edge ASR Across 19 African Languages
Pith reviewed 2026-06-28 14:40 UTC · model grok-4.3
The pith
Fine-tuned compact ASR models achieve 38% WER on 19 African languages, beating 65% for much larger zero-shot baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
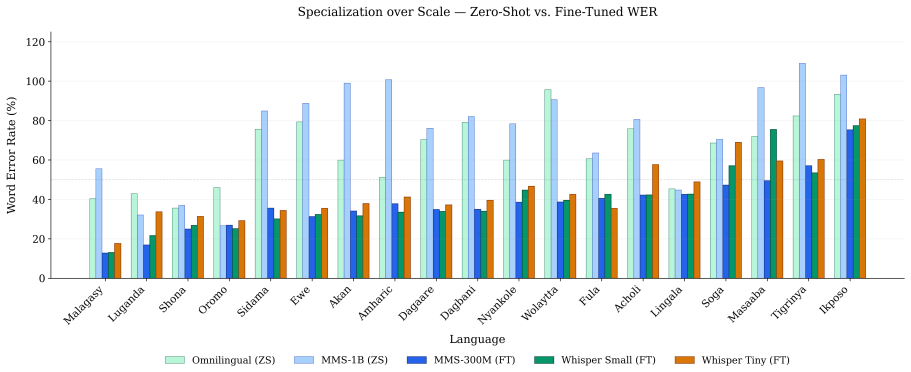
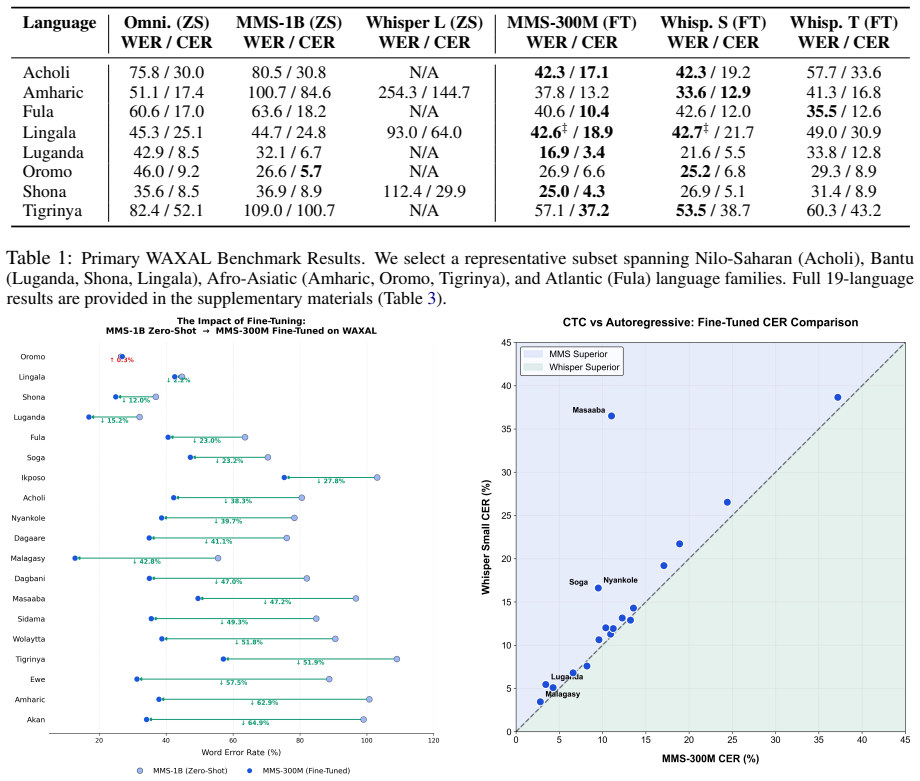
Fine-tuned edge models achieve a macro-averaged WER of 38.0% compared to 64.9% for the best zero-shot baseline, a 26.9 percentage-point reduction using models 3-40× smaller. Results confirm that domain specialization dominates scale for spontaneous African speech. Cross-domain evaluation shows that fine-tuned models recover usable performance on out-of-distribution speech, while zero-shot models regain an advantage when the test domain matches their pretraining distribution.
What carries the argument
Fine-tuning of compact edge ASR models on the WAXAL corpus for spontaneous conversational speech in 19 African languages.
If this is right
- Fine-tuned models recover usable performance on out-of-distribution speech.
- Zero-shot models regain an advantage when the test domain matches their pretraining distribution.
- CTC and autoregressive architectures behave differently across language families according to the native-speaker error taxonomy.
- WER alone misrepresents performance for syllabary-script languages, where CER/WER ratios show higher character-level accuracy.
Where Pith is reading between the lines
- The released model weights and scripts enable direct replication and incremental improvement by other researchers working on the same languages.
- The observed advantage of domain specialization may extend to other low-resource conversational speech settings beyond the 19 languages tested.
- Edge deployment of the smaller fine-tuned models becomes more practical in regions with limited compute infrastructure.
Load-bearing premise
The WAXAL corpus and its test splits accurately represent spontaneous conversational speech across the 19 languages, and the zero-shot baselines represent the strongest possible performance without any fine-tuning on WAXAL data.
What would settle it
A new zero-shot model evaluated on the WAXAL test splits without exposure to any WAXAL training data achieving a macro-averaged WER below 38%.
Figures

read the original abstract
We evaluate whether compact domain-specialized ASR models can outperform massively multilingual foundation models for conversational African speech across 19 languages in the WAXAL corpus. Fine-tuned edge models achieve a macro-averaged WER of $38.0\%$ compared to $64.9\%$ for the best zero-shot baseline, a $26.9$ percentage-point reduction using models $3-40\times$ smaller. Results confirm that domain specialization dominates scale for spontaneous African speech. Cross-domain evaluation shows that fine-tuned models recover usable performance on out-of-distribution (OOD) speech, while zero-shot models regain an advantage when the test domain matches their pretraining distribution. A distributed native-speaker audit across all surveyed languages produces a linguistically-grounded error taxonomy, showing that CTC and autoregressive architectures behave differently across language families. We further show that WER alone misrepresents performance for syllabary-script languages where CER/WER ratios reveal substantially higher character-level accuracy than headline WER suggests. Finally, to contribute to future African ASR research, we release all model weights, fine-tuning and evaluation scripts, and a cleaned WAXAL subset covering all $19$ languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates whether compact, domain-specialized ASR models can outperform large multilingual foundation models on spontaneous conversational speech across 19 African languages in the WAXAL corpus. It reports that fine-tuned edge models achieve a macro-averaged WER of 38.0% versus 64.9% for the best zero-shot baseline (a 26.9-point reduction) while using models 3-40× smaller, concluding that domain specialization dominates scale. Additional results cover cross-domain OOD performance, a native-speaker error taxonomy distinguishing CTC and autoregressive behavior, and the observation that WER misrepresents accuracy for syllabary-script languages (via CER/WER ratios). The work releases all model weights, fine-tuning/evaluation scripts, and a cleaned WAXAL subset.
Significance. If the empirical comparisons hold, the results provide concrete evidence that targeted fine-tuning on domain-specific data can substantially outperform scale-driven zero-shot approaches for low-resource African languages. The explicit release of weights, scripts, and data subset, together with the distributed native-speaker audit, directly supports independent verification and future work, strengthening the contribution beyond typical empirical ASR papers.
minor comments (3)
- [Abstract] Abstract: the headline WER figures would be more immediately interpretable if the abstract briefly noted the model families or parameter counts of the fine-tuned edge models alongside the 3-40× size claim.
- The cross-domain evaluation section would benefit from an explicit statement of how the OOD test domains were selected relative to the pretraining distributions of the zero-shot baselines.
- Table or figure presenting the CER/WER ratios for syllabary-script languages should include the number of languages and utterances involved to allow readers to gauge the scope of the misrepresentation claim.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation to accept. The review accurately captures the core claims, empirical results, and release artifacts.
Circularity Check
No significant circularity
full rationale
The paper reports direct empirical measurements of WER from fine-tuning compact ASR models on the WAXAL corpus and evaluating on held-out splits, compared against zero-shot baselines. No equations, derivations, or predictions are present that reduce reported gains to quantities defined by fitted parameters or self-citations within the paper. The central claims rest on experimental results and released artifacts enabling external verification, with no load-bearing steps that collapse by construction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption WER is an appropriate primary metric for comparing ASR systems on the WAXAL corpus
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 40th International Conference on Machine Learning , year=
Robust Speech Recognition via Large-Scale Weak Supervision , author=. Proceedings of the 40th International Conference on Machine Learning , year=
-
[2]
Journal of Machine Learning Research , year=
Scaling Speech Technology to 1,000+ Languages , author=. Journal of Machine Learning Research , year=
-
[3]
2025 , eprint=
Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages , author=. 2025 , eprint=
2025
-
[4]
FLEURS: FEW-Shot Learning Evaluation of Universal Representations of Speech , year=
Conneau, Alexis and Ma, Min and Khanuja, Simran and Zhang, Yu and Axelrod, Vera and Dalmia, Siddharth and Riesa, Jason and Rivera, Clara and Bapna, Ankur , booktitle=. FLEURS: FEW-Shot Learning Evaluation of Universal Representations of Speech , year=
-
[5]
Proceedings of Interspeech , year=
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale , author=. Proceedings of Interspeech , year=
-
[6]
Proceedings of the Twelfth Language Resources and Evaluation Conference , pages=
Common Voice: A Massively-Multilingual Speech Corpus , author=. Proceedings of the Twelfth Language Resources and Evaluation Conference , pages=
-
[7]
Transactions of the Association for Computational Linguistics , year=
AfriSpeech-200: Pan-African Accented Speech Dataset for Clinical and General Domain ASR , author=. Transactions of the Association for Computational Linguistics , year=
-
[8]
2022 , url =
Vaessen, Nik , title =. 2022 , url =
2022
-
[9]
2025 , eprint=
Hallucination Benchmark for Speech Foundation Models , author=. 2025 , eprint=
2025
-
[10]
doi:10.21437/Interspeech.2004-668 , issn =
Andrew Cameron Morris and Viktoria Maier and Phil Green , year =. doi:10.21437/Interspeech.2004-668 , issn =
-
[11]
Investigation of Whisper ASR Hallucinations Induced by Non-Speech Audio , year=
Barański, Mateusz and Jasiński, Jan and Bartolewska, Julitta and Kacprzak, Stanisław and Witkowski, Marcin and Kowalczyk, Konrad , booktitle=. Investigation of Whisper ASR Hallucinations Induced by Non-Speech Audio , year=
-
[12]
Findings of the Association for Computational Linguistics: ACL 2025 , year =
Lost in Transcription, Found in Distribution Shift: Demystifying Hallucination in Speech Foundation Models , author =. Findings of the Association for Computational Linguistics: ACL 2025 , year =. doi:10.18653/v1/2025.findings-acl.1190 , pages =
-
[13]
Advocating Character Error Rate for Multilingual ASR Evaluation
K, Thennal D and James, Jesin and Gopinath, Deepa Padmini and K, Muhammed Ashraf. Advocating Character Error Rate for Multilingual ASR Evaluation. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.277
-
[14]
Imam, Sukairaj Hafiz and Bello, Muhammad Yahuza and Umar, Hadiza Ali and Belay, Tadesse Destaw and Abdulmumin, Idris and Yimam, Seid Muhie and Muhammad, Shamsuddeen Hassan. Full Fine-Tuning vs. Parameter-Efficient Adaptation for Low-Resource A frican ASR : A Controlled Study with Whisper-Small. Proceedings of the 7th Workshop on A frican Natural Language ...
-
[15]
EURASIP Journal on Audio, Speech, and Music Processing , author =
Exploration of. EURASIP Journal on Audio, Speech, and Music Processing , author =. 2024 , pages =. doi:10.1186/s13636-024-00349-3 , abstract =
-
[16]
Pillai, Leena G and Manohar, Kavya and Raju, Basil and Sherly, Elizabeth , title =. ACM Trans. Asian Low-Resour. Lang. Inf. Process. , month = may, keywords =. 2026 , publisher =. doi:10.1145/3813800 , abstract =
-
[17]
2026 , eprint=
Ethio-ASR: Joint Multilingual Speech Recognition and Language Identification for Ethiopian Languages , author=. 2026 , eprint=
2026
-
[18]
Experiment Tracking with Weights and Biases , year =
-
[19]
Biometrika , volume=
Tests for rank correlation coefficients, I , author=. Biometrika , volume=. 1957 , publisher=
1957
-
[20]
Proceedings of the 40th International Conference on Machine Learning , year =
Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya , title =. Proceedings of the 40th International Conference on Machine Learning , year =
-
[21]
A literature review , author=
Hey ASR system! Why aren’t you more inclusive? Automatic speech recognition systems’ bias and proposed bias mitigation techniques. A literature review , author=. International conference on human-computer interaction , pages=. 2022 , organization=
2022
-
[22]
Journal of Machine Learning Research , year =
Pratap, Vineel and Tjandra, Andros and Shi, Bowen and Tomasello, Paden and Babu, Arun and Kundu, Sayani and Elkahky, Ali and Ni, Zhaoheng and Vyas, Apoorv and Fazel-Zarandi, Maryam and Baevski, Alexei and Adi, Yossi and Zhang, Xiaohui and Hsu, Wei-Ning and Conneau, Alexis and Auli, Michael , title =. Journal of Machine Learning Research , year =
-
[23]
Neural Text Normalization for L uxembourgish Using Real-Life Variation Data
Lutgen, Anne-Marie and Plum, Alistair and Purschke, Christoph and Plank, Barbara. Neural Text Normalization for L uxembourgish Using Real-Life Variation Data. Proceedings of the 12th Workshop on NLP for Similar Languages, Varieties and Dialects. 2025
2025
-
[24]
arXiv preprint arXiv:2602.02734 , year =
Diack, Abdoulaye and Nelson, Perry and Agbesi, Kwaku and Nakalembe, Angela and MohamedKhair, MohamedElfatih and Dube, Vusumuzi and Siyavora, Tavonga and Venugopalan, Subhashini and Hickey, Jason and Okonkwo, Uche and Bapna, Abhishek and Wiafe, Isaac and Helegah, Raynard Dodzi and Atsakpo, Elikem Doe and Nutrokpor, Charles and Winful, Fiifi Baffoe Payin an...
-
[25]
Transactions of the Association for Computational Linguistics , volume=
Afrispeech-200: Pan-african accented speech dataset for clinical and general domain asr , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
-
[26]
Chris Emezue and. 2025 , booktitle =. doi:10.21437/Interspeech.2025-1104 , issn =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.