Policy and World Modeling Co-Training for Language Agents
Pith reviewed 2026-06-28 15:38 UTC · model grok-4.3
The pith
On-policy RL rollouts already contain the signals needed to train world models as auxiliary supervision for language agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
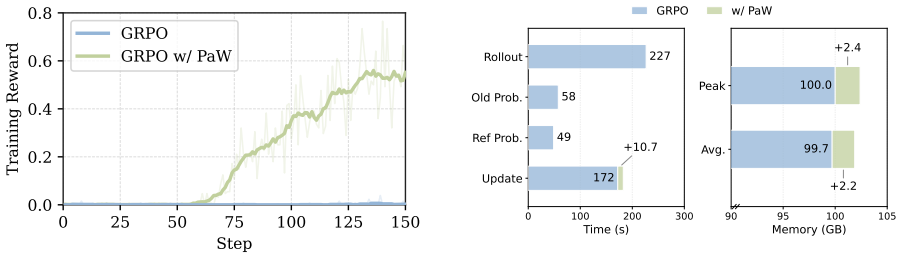
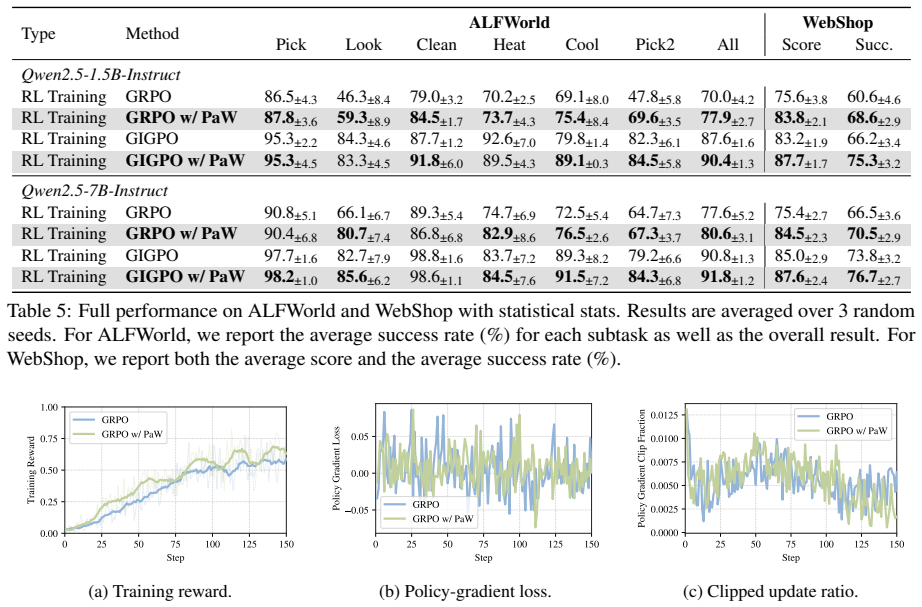
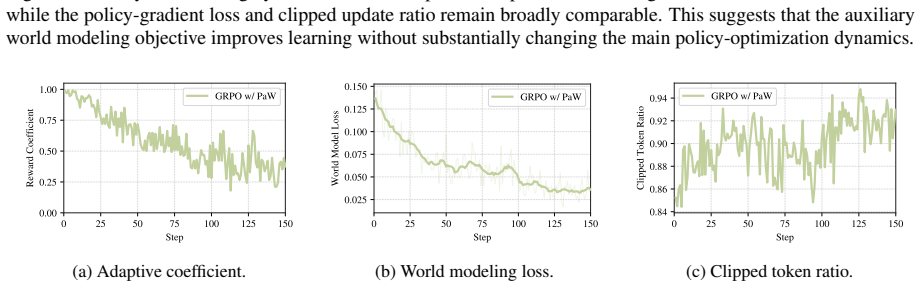
PaW co-trains the policy and a world model by treating each RL transition as a supervised WM example, using action-entropy-based data selection, a noise-tolerant WM loss, and reward-adaptive loss balancing; this yields consistent gains over strong RL baselines on three agentic benchmarks across models and algorithms while leaving the inference procedure unchanged.
What carries the argument
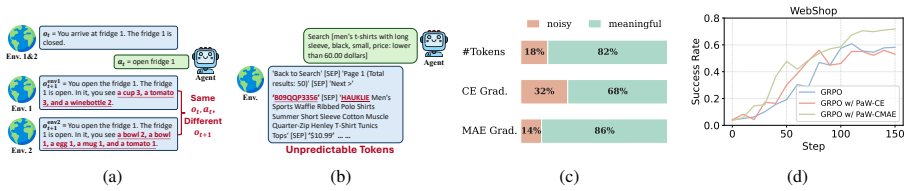
The PaW co-training loop that adds auxiliary world-model prediction to on-policy RL rollouts via the three listed stabilization components.
If this is right
- Standard RL rollouts become a practical source of world-model supervision without new data collection.
- Language agents improve on task benchmarks while keeping the same inference-time computation.
- The method works across different model sizes and RL algorithms.
- No separate simulator or extra training stage is required.
Where Pith is reading between the lines
- The same rollout data could be reused to train additional auxiliary predictors beyond a basic world model.
- If the gains hold at larger scale, agent training pipelines might reduce reliance on external simulators.
- The stabilization techniques might transfer to other auxiliary objectives that use the same transition data.
Load-bearing premise
That the three proposed components can turn the raw action-observation pairs inside ordinary RL rollouts into informative and stable world-model supervision.
What would settle it
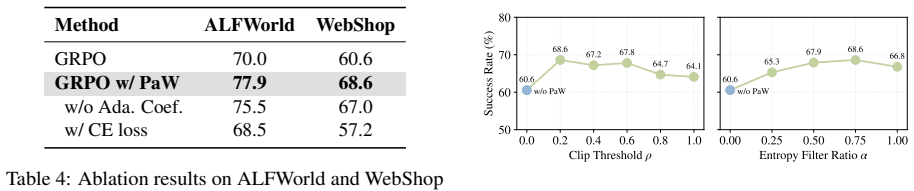
An ablation in which removing one or more of the three components (entropy selection, noise-tolerant loss, or adaptive balancing) eliminates the reported performance gains on the agent benchmarks.
Figures



read the original abstract
Reinforcement learning (RL) improves large language model (LLM) agents by teaching them which actions lead to high rewards, but provides little supervision on what those actions do to the environment. World modeling (WM) can fill this gap, yet existing approaches often require separate simulators, extra training stages, or additional inference-time computation. We observe that on-policy RL rollouts already contain the needed signal: each transition pairs an action with its resulting next observation. Based on this observation, we propose PaW, a Policy and World modeling co-training framework that adds auxiliary WM supervision to the same policy during RL, without changing the inference paradigm. To make auxiliary WM supervision informative and stable, PaW introduces three components: action-entropy-based WM data selection, noise-tolerant WM loss, and reward-adaptive loss balancing. Experiments on three agentic task benchmarks show consistent improvements over strong RL baselines across models and RL algorithms. These results suggest that standard RL rollouts are a practical source of WM supervision for language-agent training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that on-policy RL rollouts already contain (action, next-observation) pairs that can supply auxiliary world-modeling supervision for LLM agents. It introduces the PaW co-training framework, which adds this supervision to the policy during RL via three stabilizing components (action-entropy-based WM data selection, noise-tolerant WM loss, and reward-adaptive loss balancing) while leaving the inference paradigm unchanged. Experiments on three agentic task benchmarks are reported to show consistent improvements over strong RL baselines across models and algorithms.
Significance. If the empirical results hold with the reported magnitude and robustness, the work would be significant because it demonstrates a practical route to WM supervision that re-uses existing RL rollouts, avoids separate simulators, extra training stages, or inference-time overhead, and thereby addresses a recognized gap in RL-based agent training.
minor comments (1)
- The abstract states that the three components make WM supervision 'informative and stable,' but does not preview the quantitative contribution of each component; a short sentence or table reference in the abstract would help readers assess the central claim at first reading.
Simulated Author's Rebuttal
We thank the referee for the positive summary of the paper, the recognition of its potential significance, and the recommendation for minor revision. No specific major comments were listed in the report.
Circularity Check
No significant circularity identified
full rationale
The paper presents PaW as an empirical co-training method that augments standard on-policy RL rollouts with auxiliary WM supervision through three explicitly described components (action-entropy data selection, noise-tolerant loss, reward-adaptive balancing). The central claim—that these rollouts supply usable (action, next-observation) pairs without altering inference—is validated by benchmark experiments rather than any derivation, equation, or prediction that reduces to fitted parameters or self-citations by construction. No self-definitional steps, fitted-input-as-prediction patterns, or load-bearing self-citation chains appear in the abstract or stated approach. The work is self-contained as a practical engineering proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption on-policy RL rollouts contain usable next-observation signal for world modeling
Reference graph
Works this paper leans on
-
[1]
2018 , publisher=
Reinforcement Learning: An Introduction , author=. 2018 , publisher=
2018
-
[2]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[3]
arXiv preprint arXiv:2602.15763 , year=
GLM-5: from Vibe Coding to Agentic Engineering , author=. arXiv preprint arXiv:2602.15763 , year=
-
[4]
Cognitive science , year=
Mental models , author=. Cognitive science , year=
-
[5]
2012 , publisher=
Action, perception and the brain: Adaptation and cephalic expression , author=. 2012 , publisher=
2012
-
[6]
2, 2022-06-27 , author=
A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27 , author=. Open Review , volume=
2022
-
[7]
Conference on Empirical Methods in Natural Language Processing , year =
Shibo Hao and Yi Gu and Haodi Ma and Joshua Jiahua Hong and Zhen Wang and Daisy Zhe Wang and Zhiting Hu , title =. Conference on Empirical Methods in Natural Language Processing , year =
-
[8]
Transactions on Machine Learning Research , year =
Yu Gu and Kai Zhang and Yuting Ning and Boyuan Zheng and Boyu Gou and Tianci Xue and Cheng Chang and Sanjari Srivastava and Yanan Xie and Peng Qi and Huan Sun and Yu Su , title =. Transactions on Machine Learning Research , year =
-
[9]
arXiv preprint arXiv:2512.18832 , year=
From Word to World: Can Large Language Models be Implicit Text-based World Models? , author=. arXiv preprint arXiv:2512.18832 , year=
-
[10]
W eb E volver: Enhancing Web Agent Self-Improvement with Co-evolving World Model
Fang, Tianqing and Zhang, Hongming and Zhang, Zhisong and Ma, Kaixin and Yu, Wenhao and Mi, Haitao and Yu, Dong. W eb E volver: Enhancing Web Agent Self-Improvement with Co-evolving World Model. Conference on Empirical Methods in Natural Language Processing. 2025
2025
-
[11]
Xiao, Zikai and Tu, Jianhong and Zou, Chuhang and Zuo, Yuxin and Li, Zhi and Wang, Peng and Yu, Bowen and Huang, Fei and Lin, Junyang and Liu, Zuozhu , journal=
-
[12]
arXiv preprint arXiv:2601.08955 , year=
Imagine-then-Plan: Agent Learning from Adaptive Lookahead with World Models , author=. arXiv preprint arXiv:2601.08955 , year=
-
[13]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and others , journal=
-
[14]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, YK and Wu, Y and others , journal=
-
[15]
Group-in-group policy optimization for
Feng, Lang and Xue, Zhenghai and Liu, Tingcong and An, Bo , booktitle=. Group-in-group policy optimization for
-
[16]
arXiv preprint arXiv:2308.11432 , year=
A Survey on Large Language Model based Autonomous Agents , author=. arXiv preprint arXiv:2308.11432 , year=
-
[17]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle=
-
[18]
Conference on Neural Information Processing Systems , year=
Chain-of-thought prompting elicits reasoning in large language models , author=. Conference on Neural Information Processing Systems , year=
-
[19]
Conference on Neural Information Processing Systems , year=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Conference on Neural Information Processing Systems , year=
-
[20]
Transactions on Machine Learning Research , year=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Transactions on Machine Learning Research , year=
-
[21]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle=
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle=
-
[22]
John Yang and Carlos E Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik R Narasimhan and Ofir Press , booktitle=
-
[23]
Xie, Tianbao and Zhang, Danyang and Chen, Jixuan and Li, Xiaochuan and Zhao, Siheng and Cao, Ruisheng and others , booktitle=
-
[24]
Christopher Rawles and Sarah Clinckemaillie and Yifan Chang and Jonathan Waltz and Gabrielle Lau and Marybeth Fair and Alice Li and William E Bishop and Wei Li and Folawiyo Campbell-Ajala and Daniel Kenji Toyama and Robert James Berry and Divya Tyamagundlu and Timothy P Lillicrap and Oriana Riva , booktitle=
-
[25]
Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , booktitle=
Shuyan Zhou and Frank F. Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , booktitle=
-
[26]
Qin, Yujia and Ye, Yining and Fang, Junjie and Wang, Haoming and Liang, Shihao and Tian, Shizuo and Zhang, Junda and others , journal=
-
[27]
Deng, Xiang and Gu, Yu and Zheng, Boyuan and Chen, Shijie and Stevens, Samuel and Wang, Boshi and Sun, Huan and Su, Yu , booktitle=
-
[28]
A gent T uning: Enabling Generalized Agent Abilities for LLM s
Zeng, Aohan and Liu, Mingdao and Lu, Rui and Wang, Bowen and Liu, Xiao and Dong, Yuxiao and Tang, Jie. A gent T uning: Enabling Generalized Agent Abilities for LLM s. Findings of the Annual Meeting of the Association for Computational Linguistics. 2024
2024
-
[29]
Chen, Baian and Shu, Chang and Shareghi, Ehsan and Collier, Nigel and Narasimhan, Karthik and Yao, Shunyu , journal=
-
[30]
Annual Meeting of the Association for Computational Linguistics
Xi, Zhiheng and Ding, Yiwen and Chen, Wenxiang and Hong, Boyang and Guo, Honglin and Wang, Junzhe and others , booktitle = "Annual Meeting of the Association for Computational Linguistics", year=
-
[31]
ACM SIGART Bulletin , year=
Dyna, an Integrated Architecture for Learning, Planning, and Reacting , author=. ACM SIGART Bulletin , year=
-
[32]
arXiv preprint arXiv:1803.10122 , year=
World Models , author=. arXiv preprint arXiv:1803.10122 , year=
-
[33]
International Conference on Learning Representations , year=
Dream to Control: Learning Behaviors by Latent Imagination , author=. International Conference on Learning Representations , year=
-
[34]
International Conference on Learning Representations , year=
Mastering Atari with Discrete World Models , author=. International Conference on Learning Representations , year=
-
[35]
Conference on Empirical Methods in Natural Language Processing , year=
Reasoning with Language Model is Planning with World Model , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[36]
International Conference on Learning Representations , year=
Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation , author=. International Conference on Learning Representations , year=
-
[37]
arXiv preprint arXiv:2506.02918 , year=
World Modelling Improves Language Model Agents , author=. arXiv preprint arXiv:2506.02918 , year=
-
[38]
Reinforcement World Model Learning for
Yu, Xiao and Peng, Baolin and Xu, Ruize and Shen, Yelong and He, Pengcheng and Nath, Suman and Singh, Nikhil and Gao, Jiangfeng and Yu, Zhou , journal=. Reinforcement World Model Learning for
-
[39]
International Conference on Machine Learning , year=
Learning to Model the World With Language , author=. International Conference on Machine Learning , year=
-
[40]
Bowen Jin and Hansi Zeng and Zhenrui Yue and Jinsung Yoon and Sercan O Arik and Dong Wang and Hamed Zamani and Jiawei Han , booktitle=
-
[41]
Proximity-Based Multi-Turn Optimization: Practical Credit Assignment for
Fang, Yangyi and Lin, Jiaye and Fu, Xiaoliang and Qin, Cong and Shi, Haolin and Liu, Chang and Zhao, Peilin , journal=. Proximity-Based Multi-Turn Optimization: Practical Credit Assignment for
-
[42]
arXiv preprint arXiv:2605.15155 , year=
Self-Distilled Agentic Reinforcement Learning , author=. arXiv preprint arXiv:2605.15155 , year=
-
[43]
ZeroSearch: Incentivize the Search Capability of
Sun, Hao and Qiao, Zile and Guo, Jiayan and Fan, Xuanbo and Hou, Yingyan and Jiang, Yong and Xie, Pengjun and Huang, Fei and Zhang, Yan , journal=. ZeroSearch: Incentivize the Search Capability of
-
[44]
arXiv preprint arXiv:2510.08558 , year=
Agent Learning via Early Experience , author=. arXiv preprint arXiv:2510.08558 , year=
-
[45]
Yao, Shunyu and Chen, Howard and Yang, John and Narasimhan, Karthik , booktitle=
-
[46]
Mohit Shridhar and Xingdi Yuan and Marc-Alexandre Cote and Yonatan Bisk and Adam Trischler and Matthew Hausknecht , booktitle=
-
[47]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=
-
[48]
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William W and Salakhutdinov, Ruslan and Manning, Christopher D , journal=
-
[49]
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish , journal=
-
[50]
arXiv preprint arXiv:2210.03350 , year=
Measuring and narrowing the compositionality gap in language models , author=. arXiv preprint arXiv:2210.03350 , year=
-
[51]
arXiv preprint arXiv:2212.10511 , year=
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories , author=. arXiv preprint arXiv:2212.10511 , year=
-
[52]
arXiv preprint arXiv:2011.01060 , year=
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. arXiv preprint arXiv:2011.01060 , year=
Pith/arXiv arXiv 2011
-
[53]
Joshi, Mandar and Choi, Eunsol and Weld, Daniel S and Zettlemoyer, Luke , journal=
-
[54]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and others , journal=
-
[55]
arXiv preprint arXiv:2312.11805 , year=
Gemini: A family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[56]
Conference on Neural Information Processing Systems , year=
Reflexion: Language agents with verbal reinforcement learning , author=. Conference on Neural Information Processing Systems , year=
-
[57]
Qwen2. 5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[58]
arXiv preprint arXiv:2212.03533 , year=
Text embeddings by weakly-supervised contrastive pre-training , author=. arXiv preprint arXiv:2212.03533 , year=
-
[59]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[60]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in
Ahmadian, Arash and Cremer, Chris and Gall. Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in. Annual Meeting of the Association for Computational Linguistics , year=
-
[61]
International Conference on Learning Representations Workshop , year=
Buy 4 reinforce samples, get a baseline for free! , author=. International Conference on Learning Representations Workshop , year=
-
[62]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[63]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[64]
Aritra Ghosh and Himanshu Kumar and P. S. Sastry , title =. Proceedings of the Thirty-First
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.